 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust Invisible Hyperlinks in Physical Photographs Based on 3D Rendering Attacks
Dec 03, 2019
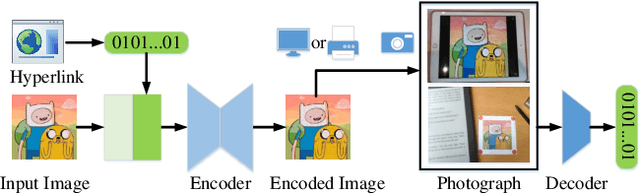
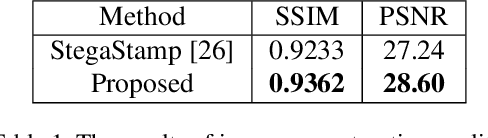
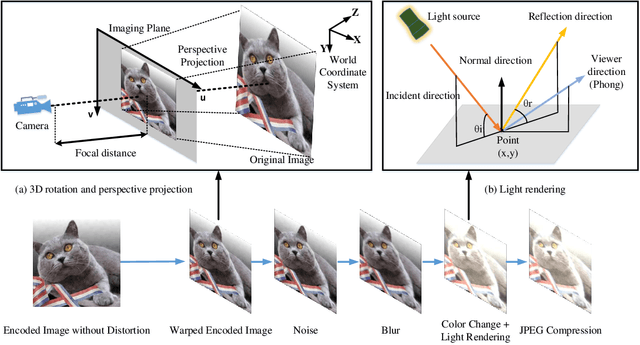
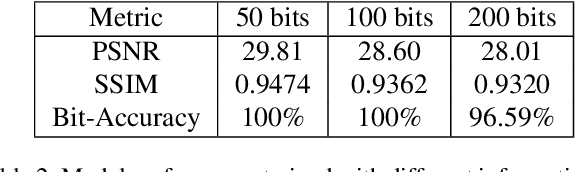
In the era of multimedia and Internet, people are eager to obtain information from offline to online. Quick Response (QR) codes and digital watermarks help us access information quickly. However, QR codes look ugly and invisible watermarks can be easily broken in physical photographs. Therefore, this paper proposes a novel method to embed hyperlinks into natural images, making the hyperlinks invisible for human eyes but detectable for mobile devices. Our method is an end-to-end neural network with an encoder to hide information and a decoder to recover information. From original images to physical photographs, camera imaging process will introduce a series of distortion such as noise, blur, and light. To train a robust decoder against the physical distortion from the real world, a distortion network based on 3D rendering is inserted between the encoder and the decoder to simulate the camera imaging process. Besides, in order to maintain the visual attraction of the image with hyperlinks, we propose a loss function based on just noticeable difference (JND) to supervise the training of encoder. Experimental results show that our approach outperforms the previous method in both simulated and real situations.
Blood Vessel Detection using Modified Multiscale MF-FDOG Filters for Diabetic Retinopathy
Oct 26, 2019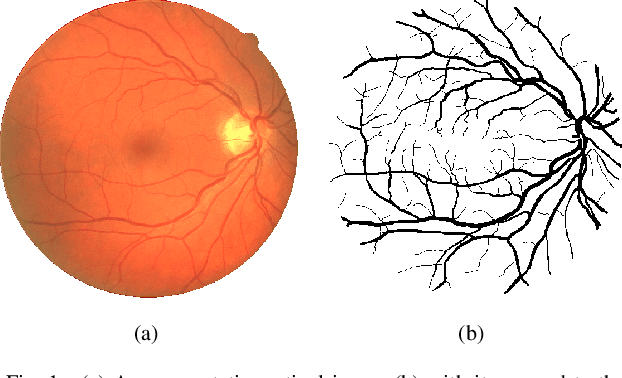
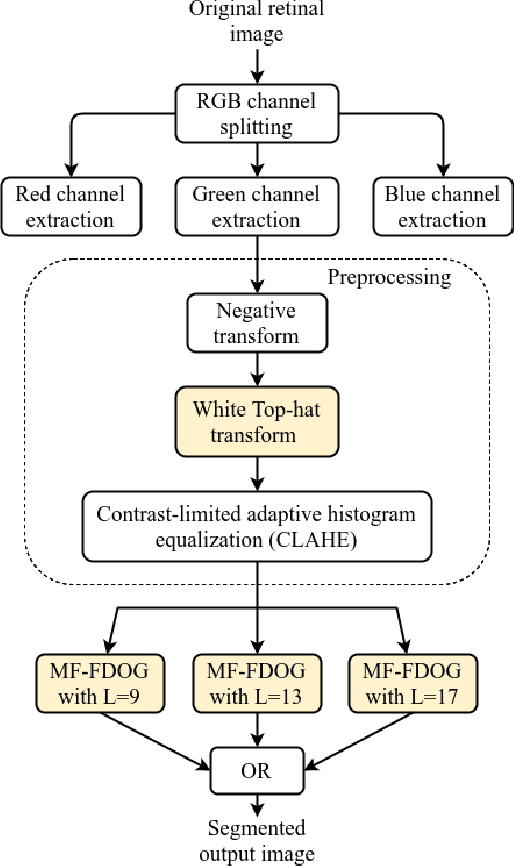
Blindness in diabetic patients caused by retinopathy (characterized by an increase in the diameter and new branches of the blood vessels inside the retina) is a grave concern. Many efforts have been made for the early detection of the disease using various image processing techniques on retinal images. However, most of the methods are plagued with the false detection of the blood vessel pixels. Given that, here, we propose a modified matched filter with the first derivative of Gaussian. The method uses the top-hat transform and contrast limited histogram equalization. Further, we segment the modified multiscale matched filter response by using a binary threshold obtained from the first derivative of Gaussian. The method was assessed on a publicly available database (DRIVE database). As anticipated, the proposed method provides a higher accuracy compared to the literature. Moreover, a lesser false detection from the existing matched filters and its variants have been observed.
Image segmentation based on histogram of depth and an application in driver distraction detection
Sep 01, 2016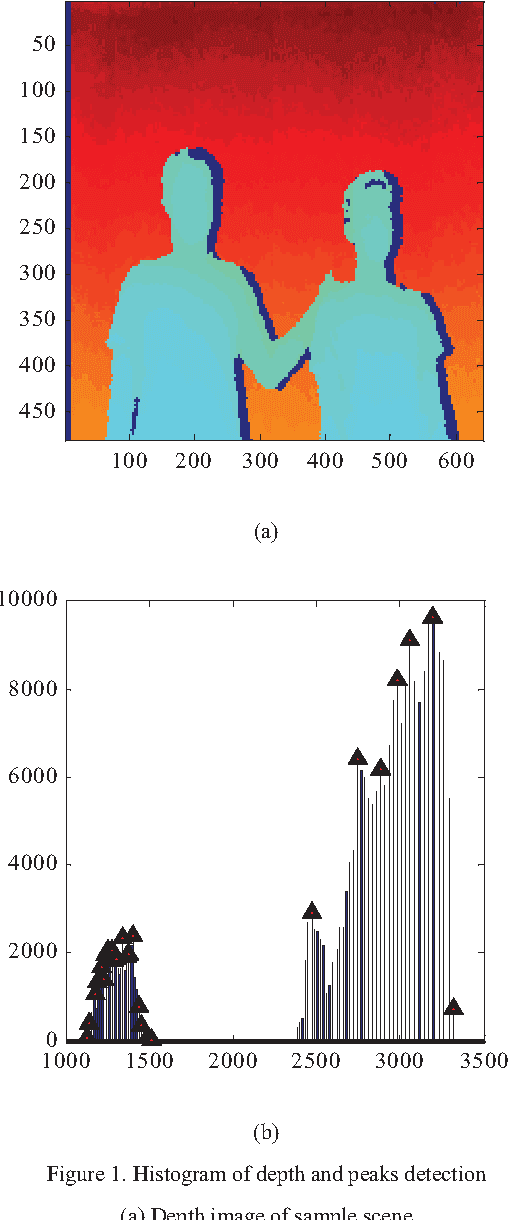
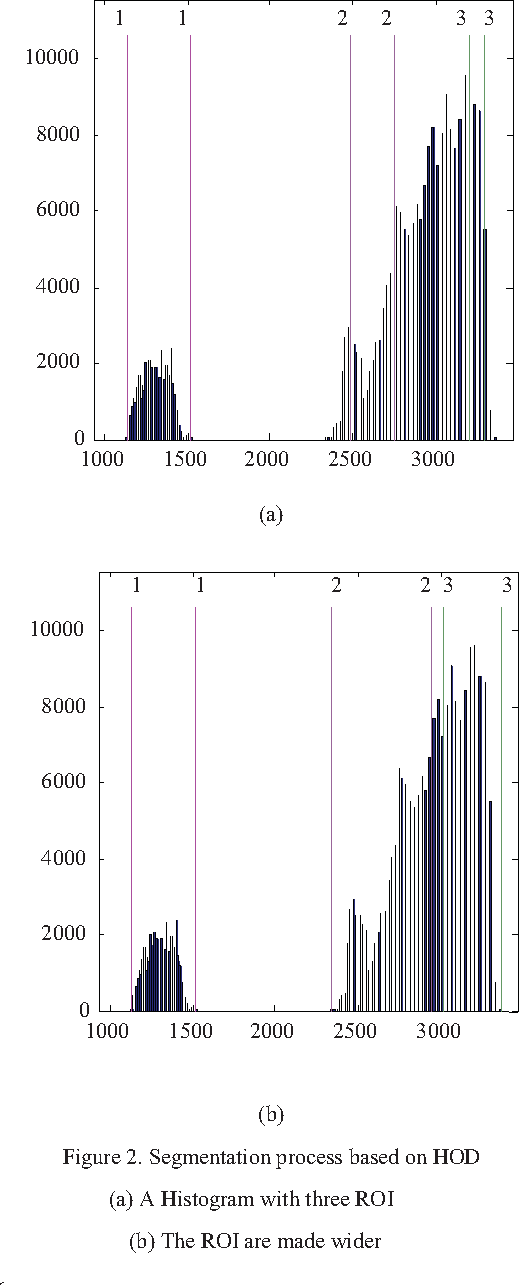
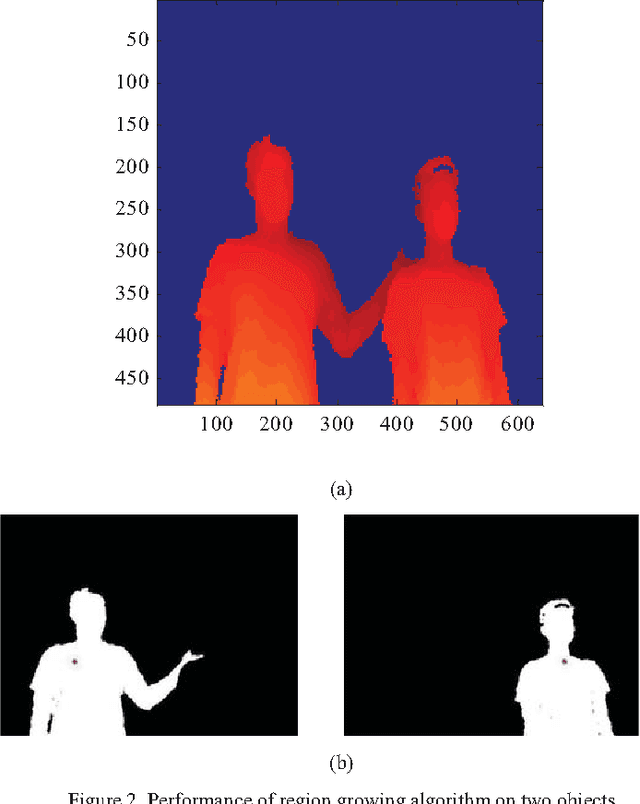
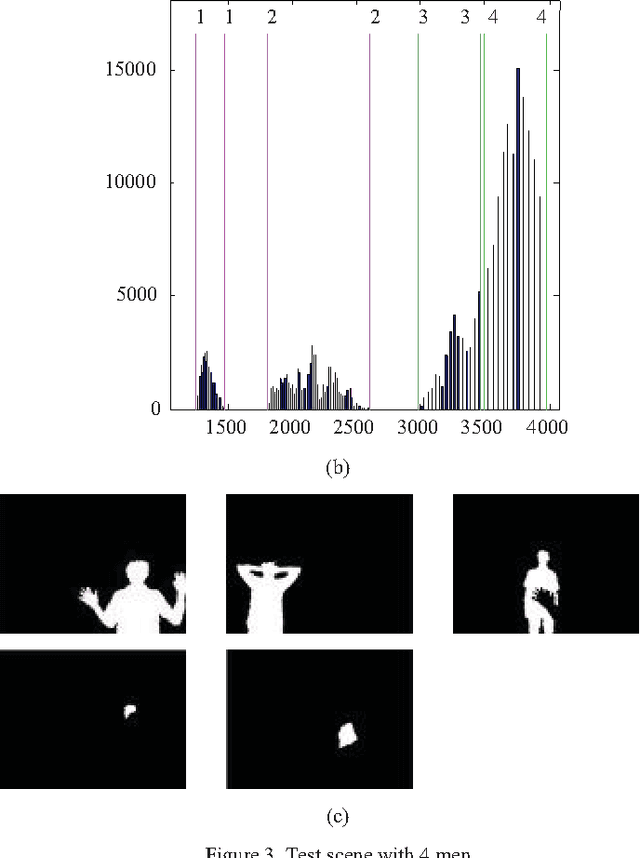
This study proposes an approach to segment human object from a depth image based on histogram of depth values. The region of interest is first extracted based on a predefined threshold for histogram regions. A region growing process is then employed to separate multiple human bodies with the same depth interval. Our contribution is the identification of an adaptive growth threshold based on the detected histogram region. To demonstrate the effectiveness of the proposed method, an application in driver distraction detection was introduced. After successfully extracting the driver's position inside the car, we came up with a simple solution to track the driver motion. With the analysis of the difference between initial and current frame, a change of cluster position or depth value in the interested region, which cross the preset threshold, is considered as a distracted activity. The experiment results demonstrated the success of the algorithm in detecting typical distracted driving activities such as using phone for calling or texting, adjusting internal devices and drinking in real time.
Consistency Regularization for Generative Adversarial Networks
Oct 26, 2019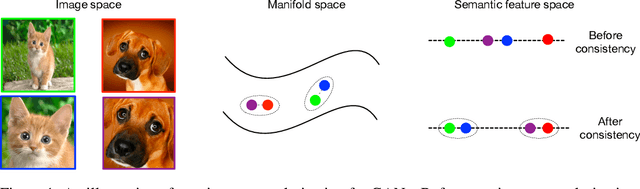

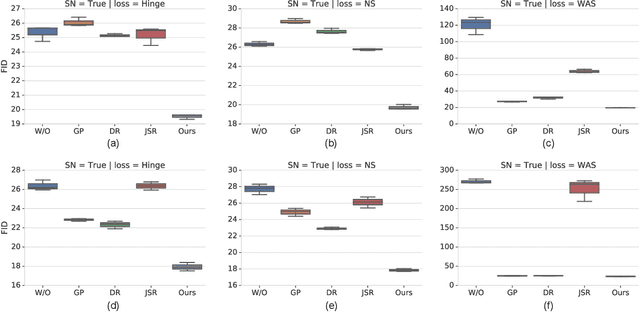

Generative Adversarial Networks (GANs) are known to be difficult to train, despite considerable research effort. Several regularization techniques for stabilizing training have been proposed, but they introduce non-trivial computational overheads and interact poorly with existing techniques like spectral normalization. In this work, we propose a simple, effective training stabilizer based on the notion of consistency regularization---a popular technique in the semi-supervised learning literature. In particular, we augment data passing into the GAN discriminator and penalize the sensitivity of the discriminator to these augmentations. We conduct a series of experiments to demonstrate that consistency regularization works effectively with spectral normalization and various GAN architectures, loss functions and optimizer settings. Our method achieves the best FID scores for unconditional image generation compared to other regularization methods on CIFAR-10 and CelebA. Moreover, Our consistency regularized GAN (CR-GAN) improves state-of-the-art FID scores for conditional generation from 14.73 to 11.67 on CIFAR-10 and from 8.73 to 6.66 on ImageNet-2012.
Multiple Linear Regression Haze-removal Model Based on Dark Channel Prior
Apr 25, 2019



Dark Channel Prior (DCP) is a widely recognized traditional dehazing algorithm. However, it may fail in bright region and the brightness of the restored image is darker than hazy image. In this paper, we propose an effective method to optimize DCP. We build a multiple linear regression haze-removal model based on DCP atmospheric scattering model and train this model with RESIDE dataset, which aims to reduce the unexpected errors caused by the rough estimations of transmission map t(x) and atmospheric light A. The RESIDE dataset provides enough synthetic hazy images and their corresponding groundtruth images to train and test. We compare the performances of different dehazing algorithms in terms of two important full-reference metrics, the peak-signal-to-noise ratio (PSNR) as well as the structural similarity index measure (SSIM). The experiment results show that our model gets highest SSIM value and its PSNR value is also higher than most of state-of-the-art dehazing algorithms. Our results also overcome the weakness of DCP on real-world hazy images
Fair Generative Modeling via Weak Supervision
Oct 26, 2019
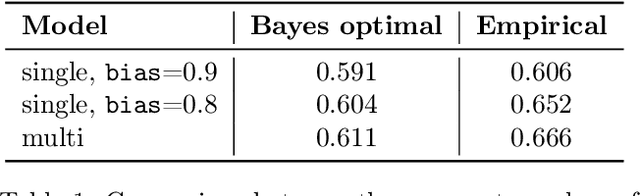

Real-world datasets are often biased with respect to key demographic factors such as race and gender. Due to the latent nature of the underlying factors, detecting and mitigating bias is especially challenging for unsupervised machine learning. We present a weakly supervised algorithm for overcoming dataset bias for deep generative models. Our approach requires access to an additional small, unlabeled but unbiased dataset as the supervision signal, thus sidestepping the need for explicit labels on the underlying bias factors. Using this supplementary dataset, we detect the bias in existing datasets via a density ratio technique and learn generative models which efficiently achieve the twin goals of: 1) data efficiency by using training examples from both biased and unbiased datasets for learning, 2) unbiased data generation at test time. Empirically, we demonstrate the efficacy of our approach which reduces bias w.r.t. latent factors by 57.1% on average over baselines for comparable image generation using generative adversarial networks.
Human Annotations Improve GAN Performances
Nov 15, 2019

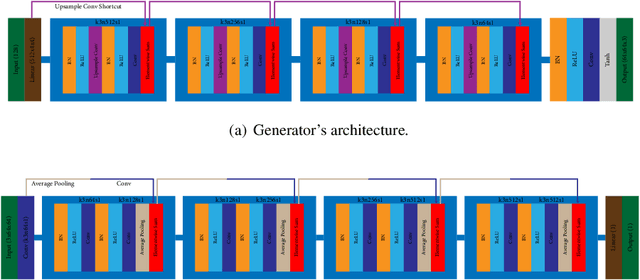
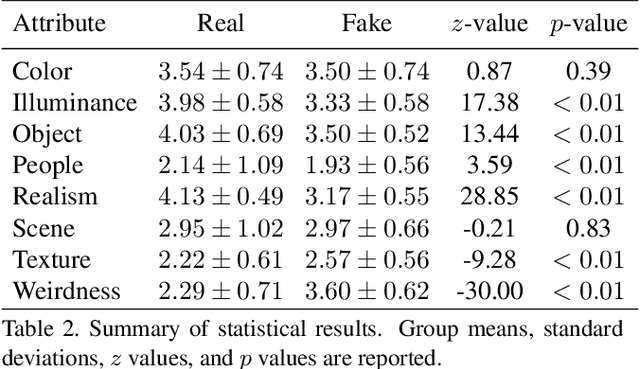
Generative Adversarial Networks (GANs) have shown great success in many applications. In this work, we present a novel method that leverages human annotations to improve the quality of generated images. Unlike previous paradigms that directly ask annotators to distinguish between real and fake data in a straightforward way, we propose and annotate a set of carefully designed attributes that encode important image information at various levels, to understand the differences between fake and real images. Specifically, we have collected an annotated dataset that contains 600 fake images and 400 real images. These images are evaluated by 10 workers from the Amazon Mechanical Turk (AMT) based on eight carefully defined attributes. Statistical analyses have revealed different distributions of the proposed attributes between real and fake images. These attributes are shown to be useful in discriminating fake images from real ones, and deep neural networks are developed to automatically predict the attributes. We further utilize the information by integrating the attributes into GANs to generate better images. Experimental results evaluated by multiple metrics show performance improvement of the proposed model.
Convolutional Neural Network on Semi-Regular Triangulated Meshes and its Application to Brain Image Data
Apr 15, 2019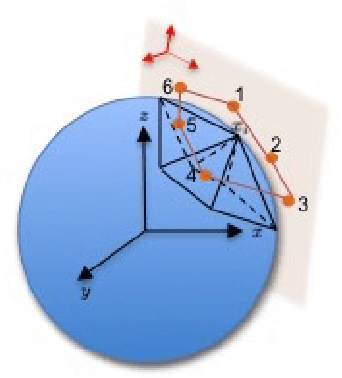
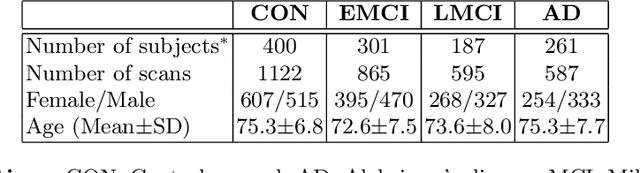
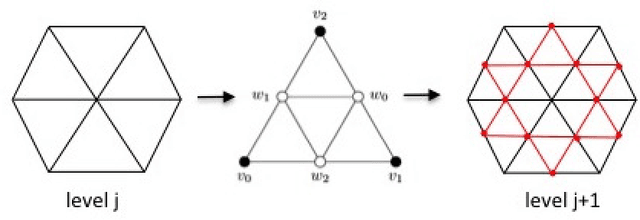
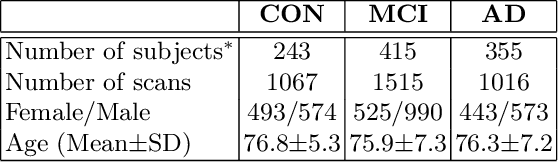
We developed a convolution neural network (CNN) on semi-regular triangulated meshes whose vertices have 6 neighbours. The key blocks of the proposed CNN, including convolution and down-sampling, are directly defined in a vertex domain. By exploiting the ordering property of semi-regular meshes, the convolution is defined on a vertex domain with strong motivation from the spatial definition of classic convolution. Moreover, the down-sampling of a semi-regular mesh embedded in a 3D Euclidean space can achieve a down-sampling rate of 4, 16, 64, etc. We demonstrated the use of this vertex-based graph CNN for the classification of mild cognitive impairment (MCI) and Alzheimer's disease (AD) based on 3169 MRI scans of the Alzheimer's Disease Neuroimaging Initiative (ADNI). We compared the performance of the vertex-based graph CNN with that of the spectral graph CNN.
Hierarchical LSTMs with Adaptive Attention for Visual Captioning
Dec 26, 2018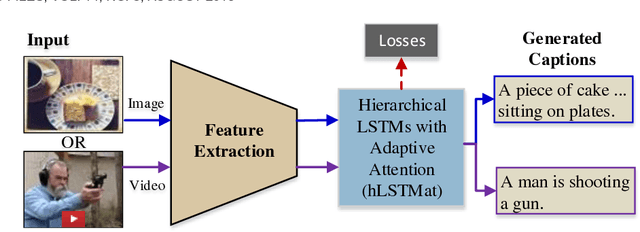

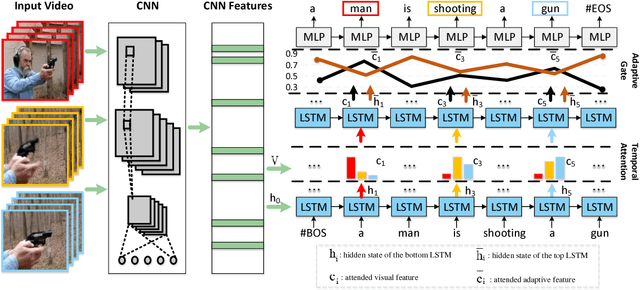
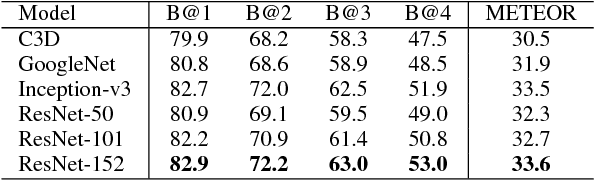
Recent progress has been made in using attention based encoder-decoder framework for image and video captioning. Most existing decoders apply the attention mechanism to every generated word including both visual words (e.g., "gun" and "shooting") and non-visual words (e.g. "the", "a"). However, these non-visual words can be easily predicted using natural language model without considering visual signals or attention. Imposing attention mechanism on non-visual words could mislead and decrease the overall performance of visual captioning. Furthermore, the hierarchy of LSTMs enables more complex representation of visual data, capturing information at different scales. To address these issues, we propose a hierarchical LSTM with adaptive attention (hLSTMat) approach for image and video captioning. Specifically, the proposed framework utilizes the spatial or temporal attention for selecting specific regions or frames to predict the related words, while the adaptive attention is for deciding whether to depend on the visual information or the language context information. Also, a hierarchical LSTMs is designed to simultaneously consider both low-level visual information and high-level language context information to support the caption generation. We initially design our hLSTMat for video captioning task. Then, we further refine it and apply it to image captioning task. To demonstrate the effectiveness of our proposed framework, we test our method on both video and image captioning tasks. Experimental results show that our approach achieves the state-of-the-art performance for most of the evaluation metrics on both tasks. The effect of important components is also well exploited in the ablation study.
Making Convolutional Networks Shift-Invariant Again
Apr 25, 2019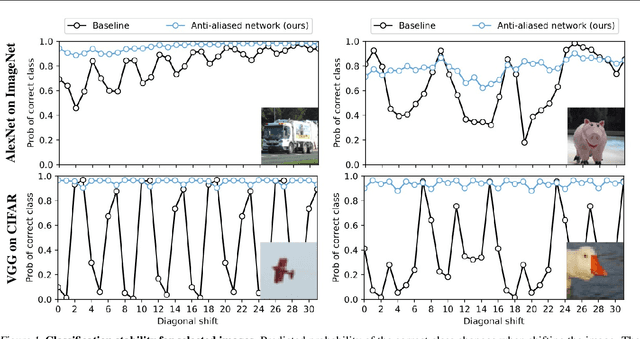
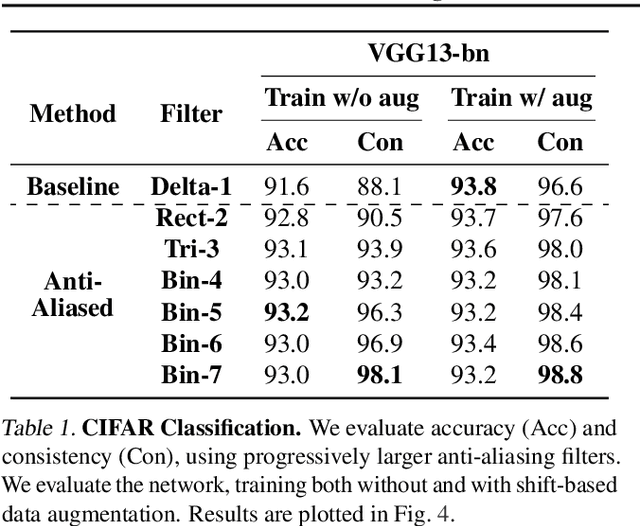
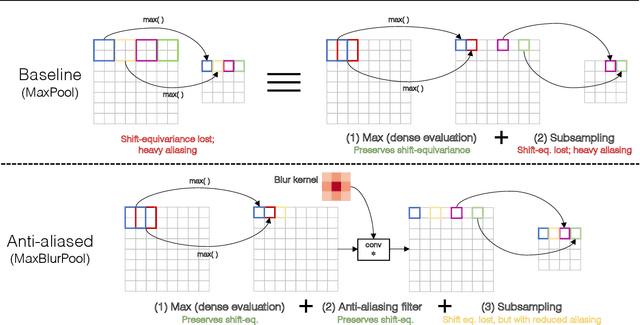
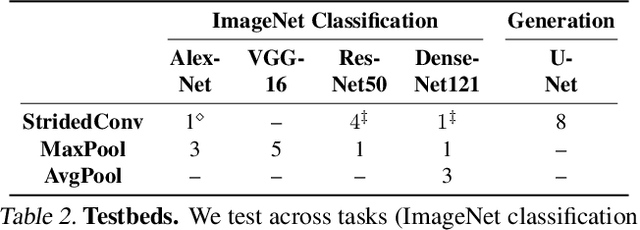
Modern convolutional networks are not shift-invariant, as small input shifts or translations can cause drastic changes in the output. Commonly used downsampling methods, such as max-pooling, strided-convolution, and average-pooling, ignore the sampling theorem. The well-known signal processing fix is anti-aliasing by low-pass filtering before downsampling. However, simply inserting this module into deep networks leads to performance degradation; as a result, it is seldomly used today. We show that when integrated correctly, it is compatible with existing architectural components, such as max-pooling. The technique is general and can be incorporated across layer types and applications, such as image classification and conditional image generation. In addition to increased shift-invariance, we also observe, surprisingly, that anti-aliasing boosts accuracy in ImageNet classification, across several commonly-used architectures. This indicates that anti-aliasing serves as effective regularization. Our results demonstrate that this classical signal processing technique has been undeservingly overlooked in modern deep networks. Code and anti-aliased versions of popular networks will be made available at \url{https://richzhang.github.io/antialiased-cnns/} .