 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProperty-Level Flood Risk Assessment Using AI-Enabled Street-View Lowest Floor Elevation Extraction and ML Imputation Across Texas
Apr 02, 2026This paper argues that AI-enabled analysis of street-view imagery, complemented by performance-gated machine-learning imputation, provides a viable pathway for generating building-specific elevation data at regional scale for flood risk assessment. We develop and apply a three-stage pipeline across 18 areas of interest (AOIs) in Texas that (1) extracts LFE and the height difference between street grade and the lowest floor (HDSL) from Google Street View imagery using the Elev-Vision framework, (2) imputes missing HDSL values with Random Forest and Gradient Boosting models trained on 16 terrain, hydrologic, geographic, and flood-exposure features, and (3) integrates the resulting elevation dataset with Fathom 1-in-100 year inundation surfaces and USACE depth-damage functions to estimate property-specific interior flood depth and expected loss. Across 12,241 residential structures, street-view imagery was available for 73.4% of parcels and direct LFE/HDSL extraction was successful for 49.0% (5,992 structures). Imputation was retained for 13 AOIs where cross-validated performance was defensible, with selected models achieving R suqre values from 0.159 to 0.974; five AOIs were explicitly excluded from prediction because performance was insufficient. The results show that street-view-based elevation mapping is not universally available for every property, but it is sufficiently scalable to materially improve regional flood-risk characterization by moving beyond hazard exposure to structure-level estimates of interior inundation and expected damage. Scientifically, the study advances LFE estimation from a pilot-scale proof of concept to a regional, end-to-end workflow. Practically, it offers a replicable framework for jurisdictions that lack comprehensive Elevation Certificates but need parcel-level information to support mitigation, planning, and flood-risk management.
Affective Flow Language Model for Emotional Support Conversation
Feb 09, 2026Large language models (LLMs) have been widely applied to emotional support conversation (ESC). However, complex multi-turn support remains challenging.This is because existing alignment schemes rely on sparse outcome-level signals, thus offering limited supervision for intermediate strategy decisions. To fill this gap, this paper proposes affective flow language model for emotional support conversation (AFlow), a framework that introduces fine-grained supervision on dialogue prefixes by modeling a continuous affective flow along multi-turn trajectories. AFlow can estimate intermediate utility over searched trajectories and learn preference-consistent strategy transitions. To improve strategy coherence and empathetic response quality, a subpath-level flow-balance objective is presented to propagate preference signals to intermediate states. Experiment results show consistent and significant improvements over competitive baselines in diverse emotional contexts. Remarkably, AFlow with a compact open-source backbone outperforms proprietary LMMs such as GPT-4o and Claude-3.5 on major ESC metrics. Our code is available at https://github.com/chzou25-lgtm/AffectiveFlow.
DisastQA: A Comprehensive Benchmark for Evaluating Question Answering in Disaster Management
Jan 07, 2026Accurate question answering (QA) in disaster management requires reasoning over uncertain and conflicting information, a setting poorly captured by existing benchmarks built on clean evidence. We introduce DisastQA, a large-scale benchmark of 3,000 rigorously verified questions (2,000 multiple-choice and 1,000 open-ended) spanning eight disaster types. The benchmark is constructed via a human-LLM collaboration pipeline with stratified sampling to ensure balanced coverage. Models are evaluated under varying evidence conditions, from closed-book to noisy evidence integration, enabling separation of internal knowledge from reasoning under imperfect information. For open-ended QA, we propose a human-verified keypoint-based evaluation protocol emphasizing factual completeness over verbosity. Experiments with 20 models reveal substantial divergences from general-purpose leaderboards such as MMLU-Pro. While recent open-weight models approach proprietary systems in clean settings, performance degrades sharply under realistic noise, exposing critical reliability gaps for disaster response. All code, data, and evaluation resources are available at https://github.com/TamuChen18/DisastQA_open.
Visual Commonsense-aware Representation Network for Video Captioning
Nov 17, 2022



Generating consecutive descriptions for videos, i.e., Video Captioning, requires taking full advantage of visual representation along with the generation process. Existing video captioning methods focus on making an exploration of spatial-temporal representations and their relationships to produce inferences. However, such methods only exploit the superficial association contained in the video itself without considering the intrinsic visual commonsense knowledge that existed in a video dataset, which may hinder their capabilities of knowledge cognitive to reason accurate descriptions. To address this problem, we propose a simple yet effective method, called Visual Commonsense-aware Representation Network (VCRN), for video captioning. Specifically, we construct a Video Dictionary, a plug-and-play component, obtained by clustering all video features from the total dataset into multiple clustered centers without additional annotation. Each center implicitly represents a visual commonsense concept in the video domain, which is utilized in our proposed Visual Concept Selection (VCS) to obtain a video-related concept feature. Next, a Conceptual Integration Generation (CIG) is proposed to enhance the caption generation. Extensive experiments on three publicly video captioning benchmarks: MSVD, MSR-VTT, and VATEX, demonstrate that our method reaches state-of-the-art performance, indicating the effectiveness of our method. In addition, our approach is integrated into the existing method of video question answering and improves this performance, further showing the generalization of our method. Source code has been released at https://github.com/zchoi/VCRN.
Hierarchical LSTMs with Adaptive Attention for Visual Captioning
Dec 26, 2018

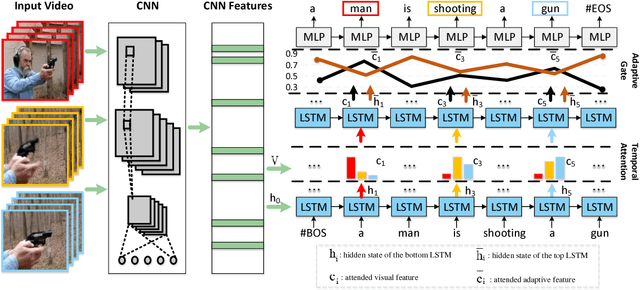
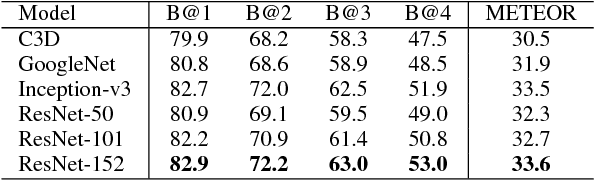
Recent progress has been made in using attention based encoder-decoder framework for image and video captioning. Most existing decoders apply the attention mechanism to every generated word including both visual words (e.g., "gun" and "shooting") and non-visual words (e.g. "the", "a"). However, these non-visual words can be easily predicted using natural language model without considering visual signals or attention. Imposing attention mechanism on non-visual words could mislead and decrease the overall performance of visual captioning. Furthermore, the hierarchy of LSTMs enables more complex representation of visual data, capturing information at different scales. To address these issues, we propose a hierarchical LSTM with adaptive attention (hLSTMat) approach for image and video captioning. Specifically, the proposed framework utilizes the spatial or temporal attention for selecting specific regions or frames to predict the related words, while the adaptive attention is for deciding whether to depend on the visual information or the language context information. Also, a hierarchical LSTMs is designed to simultaneously consider both low-level visual information and high-level language context information to support the caption generation. We initially design our hLSTMat for video captioning task. Then, we further refine it and apply it to image captioning task. To demonstrate the effectiveness of our proposed framework, we test our method on both video and image captioning tasks. Experimental results show that our approach achieves the state-of-the-art performance for most of the evaluation metrics on both tasks. The effect of important components is also well exploited in the ablation study.
Self-Supervised Video Hashing with Hierarchical Binary Auto-encoder
Feb 07, 2018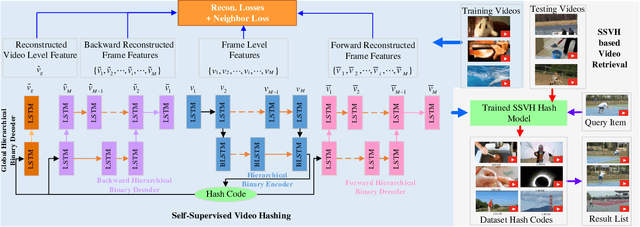
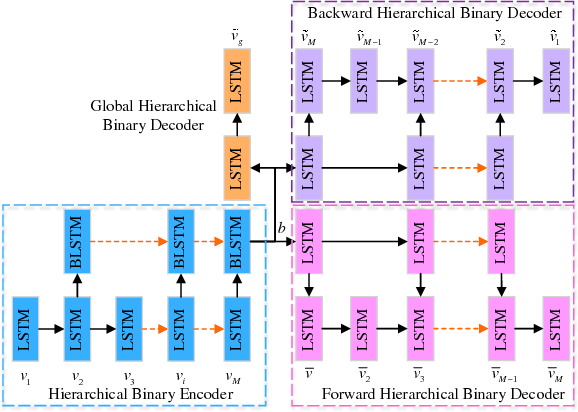
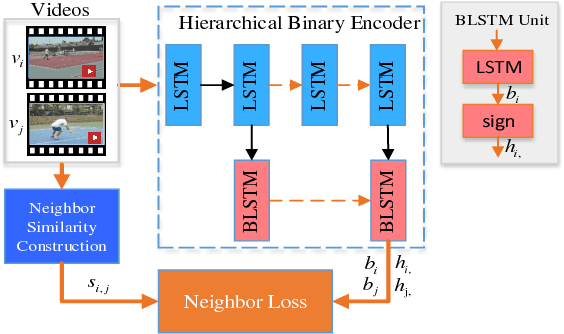
Existing video hash functions are built on three isolated stages: frame pooling, relaxed learning, and binarization, which have not adequately explored the temporal order of video frames in a joint binary optimization model, resulting in severe information loss. In this paper, we propose a novel unsupervised video hashing framework dubbed Self-Supervised Video Hashing (SSVH), that is able to capture the temporal nature of videos in an end-to-end learning-to-hash fashion. We specifically address two central problems: 1) how to design an encoder-decoder architecture to generate binary codes for videos; and 2) how to equip the binary codes with the ability of accurate video retrieval. We design a hierarchical binary autoencoder to model the temporal dependencies in videos with multiple granularities, and embed the videos into binary codes with less computations than the stacked architecture. Then, we encourage the binary codes to simultaneously reconstruct the visual content and neighborhood structure of the videos. Experiments on two real-world datasets (FCVID and YFCC) show that our SSVH method can significantly outperform the state-of-the-art methods and achieve the currently best performance on the task of unsupervised video retrieval.