 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Empirical Study on Leveraging Scene Graphs for Visual Question Answering
Jul 28, 2019

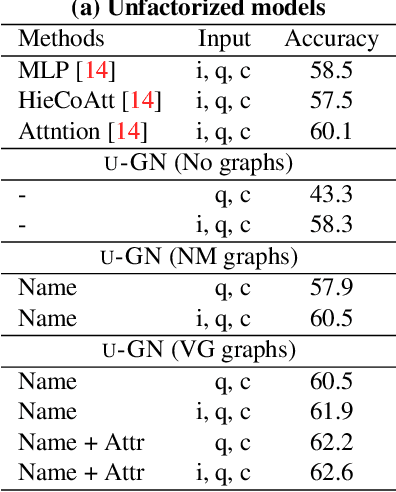
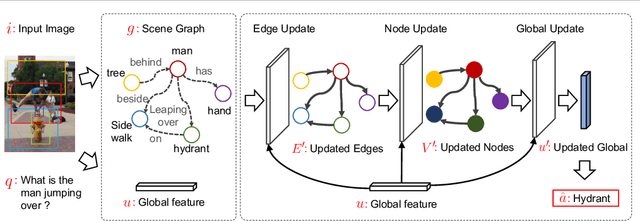
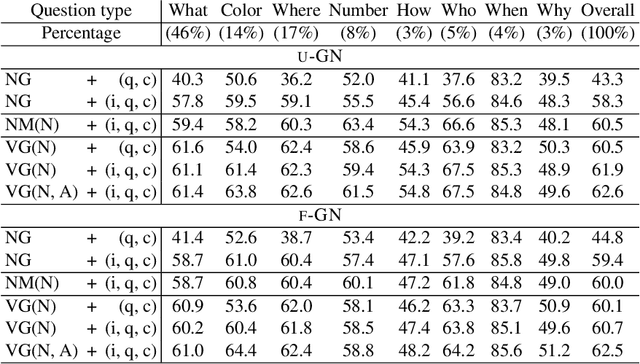
Visual question answering (Visual QA) has attracted significant attention these years. While a variety of algorithms have been proposed, most of them are built upon different combinations of image and language features as well as multi-modal attention and fusion. In this paper, we investigate an alternative approach inspired by conventional QA systems that operate on knowledge graphs. Specifically, we investigate the use of scene graphs derived from images for Visual QA: an image is abstractly represented by a graph with nodes corresponding to object entities and edges to object relationships. We adapt the recently proposed graph network (GN) to encode the scene graph and perform structured reasoning according to the input question. Our empirical studies demonstrate that scene graphs can already capture essential information of images and graph networks have the potential to outperform state-of-the-art Visual QA algorithms but with a much cleaner architecture. By analyzing the features generated by GNs we can further interpret the reasoning process, suggesting a promising direction towards explainable Visual QA.
Encoder-Decoder Based Convolutional Neural Networks with Multi-Scale-Aware Modules for Crowd Counting
Mar 28, 2020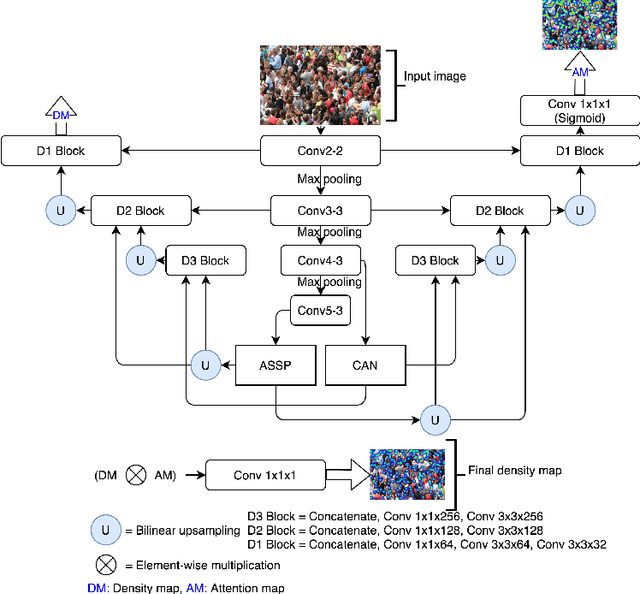
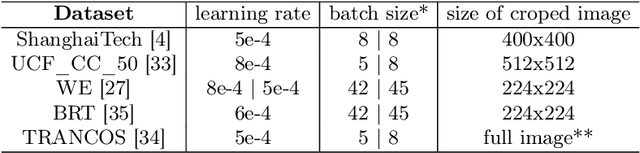
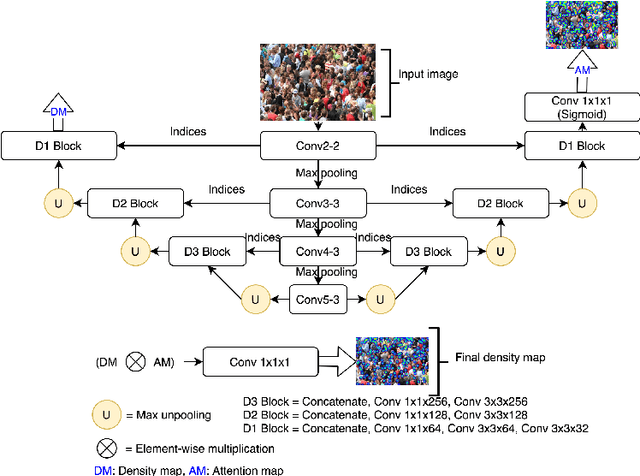
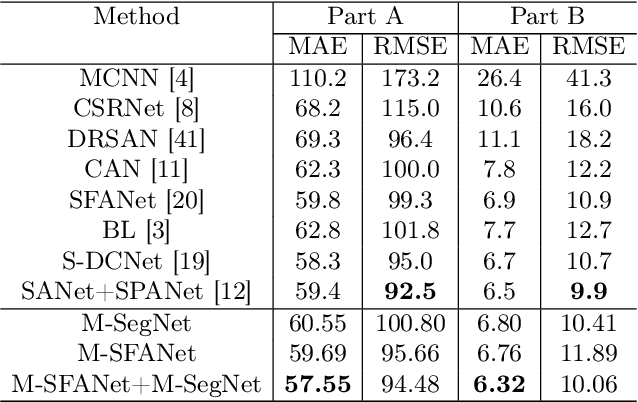
In this paper, we proposed two modified neural network architectures based on SFANet and SegNet respectively for accurate and efficient crowd counting. Inspired by SFANet, the first model is attached with two novel multi-scale-aware modules, called ASSP and CAN. This model is called M-SFANet. The encoder of M-SFANet is enhanced with ASSP containing parallel atrous convolution with different sampling rates and hence able to extract multi-scale features of the target object and incorporate larger context. To further deal with scale variation throughout an input image, we leverage contextual module called CAN which adaptively encodes the scales of the contextual information. The combination yields an effective model for counting in both dense and sparse crowd scenes. Based on the SFANet's decoder structure, M-SFANet's decoder has dual paths, for density map generation and attention map generation. The second model is called M-SegNet. For M-SegNet, we simply change bilinear upsampling used in SFANet to max unpooling originally from SegNet and propose the faster model while providing competitive counting performance. Designed for high-speed surveillance applications, M-SegNet has no additional multi-scale-aware module in order to not increase the complexity. Both models are encoder-decoder based architectures and end-to-end trainable. We also conduct extensive experiments on four crowd counting datasets and one vehicle counting dataset to show that these modifications yield algorithms that could outperform some state-of-the-art crowd counting methods.
Uncertainty Quantification with Generative Models
Oct 22, 2019

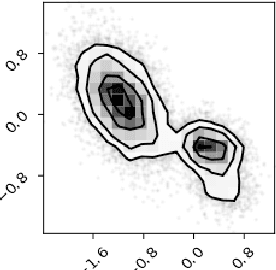
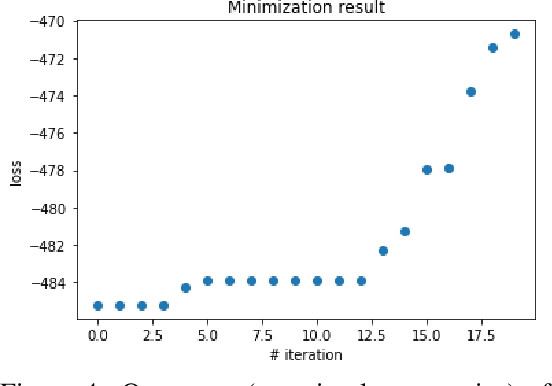
We develop a generative model-based approach to Bayesian inverse problems, such as image reconstruction from noisy and incomplete images. Our framework addresses two common challenges of Bayesian reconstructions: 1) It makes use of complex, data-driven priors that comprise all available information about the uncorrupted data distribution. 2) It enables computationally tractable uncertainty quantification in the form of posterior analysis in latent and data space. The method is very efficient in that the generative model only has to be trained once on an uncorrupted data set, after that, the procedure can be used for arbitrary corruption types.
Collaging on Internal Representations: An Intuitive Approach for Semantic Transfiguration
Nov 26, 2018


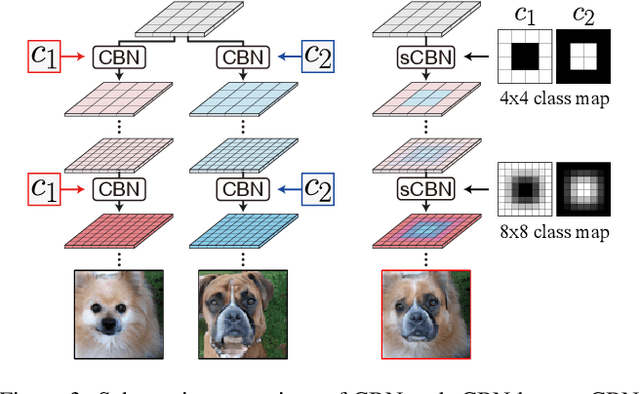
We present a novel CNN-based image editing method that allows the user to change the semantic information of an image over a user-specified region. Our method makes this possible by combining the idea of manifold projection with spatial conditional batch normalization (sCBN), a version of conditional batch normalization with user-specifiable spatial weight maps. With sCBN and manifold projection, our method lets the user perform (1) spatial class translation that changes the class of an object over an arbitrary region of user's choice, and (2) semantic transplantation that transplants semantic information contained in an arbitrary region of the reference image to an arbitrary region in the target image. These two transformations can be used simultaneously, and can realize a complex composite image-editing task like "change the nose of a beagle to that of a bulldog, and open her mouth." The user can also use our method with intuitive copy-paste-style manipulations. We demonstrate the power of our method on various images. Code will be available at https://github.com/pfnet-research/neural-collage.
Metrics and methods for robustness evaluation of neural networks with generative models
Mar 15, 2020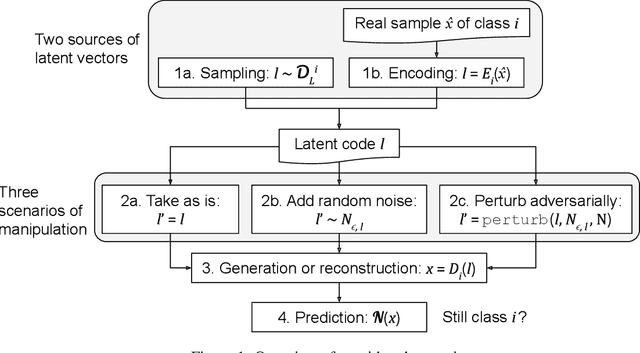
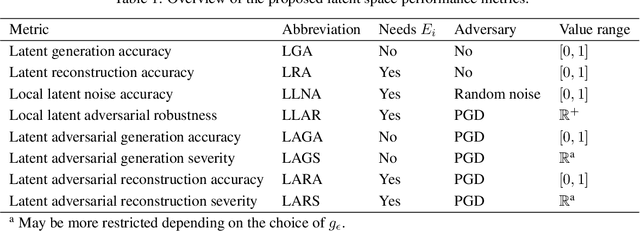
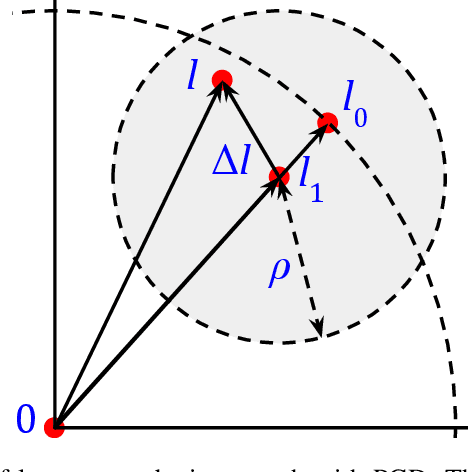
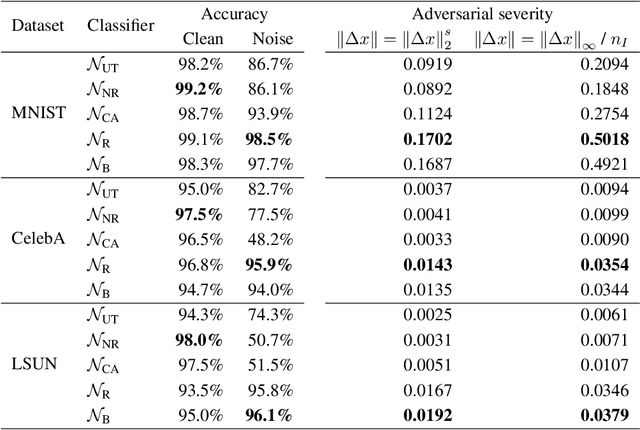
Recent studies have shown that modern deep neural network classifiers are easy to fool, assuming that an adversary is able to slightly modify their inputs. Many papers have proposed adversarial attacks, defenses and methods to measure robustness to such adversarial perturbations. However, most commonly considered adversarial examples are based on $\ell_p$-bounded perturbations in the input space of the neural network, which are unlikely to arise naturally. Recently, especially in computer vision, researchers discovered "natural" or "semantic" perturbations, such as rotations, changes of brightness, or more high-level changes, but these perturbations have not yet been systematically utilized to measure the performance of classifiers. In this paper, we propose several metrics to measure robustness of classifiers to natural adversarial examples, and methods to evaluate them. These metrics, called latent space performance metrics, are based on the ability of generative models to capture probability distributions, and are defined in their latent spaces. On three image classification case studies, we evaluate the proposed metrics for several classifiers, including ones trained in conventional and robust ways. We find that the latent counterparts of adversarial robustness are associated with the accuracy of the classifier rather than its conventional adversarial robustness, but the latter is still reflected on the properties of found latent perturbations. In addition, our novel method of finding latent adversarial perturbations demonstrates that these perturbations are often perceptually small.
S$^\mathbf{4}$L: Self-Supervised Semi-Supervised Learning
May 09, 2019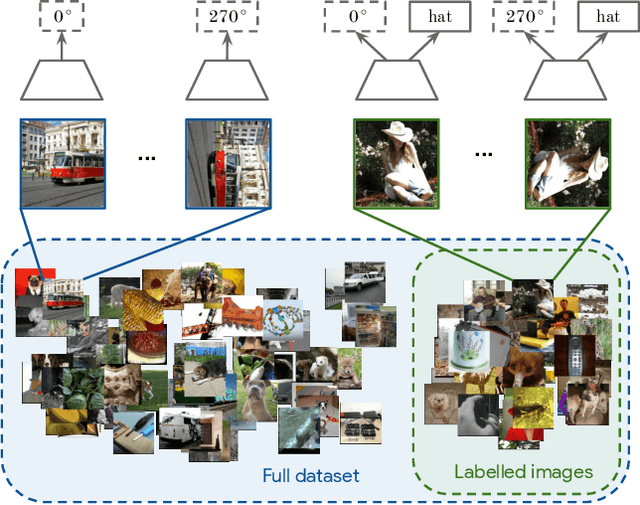
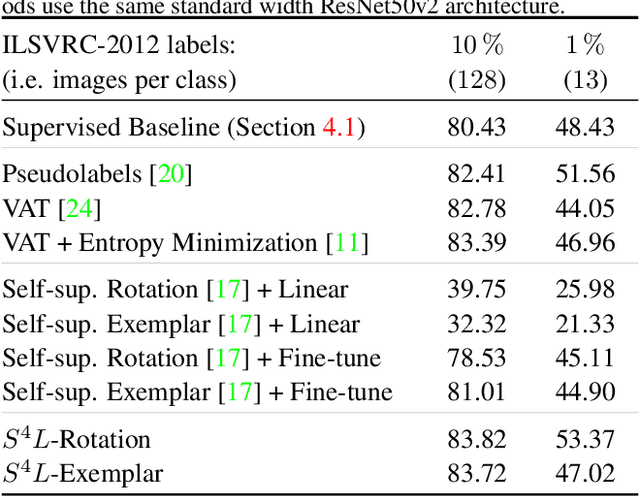
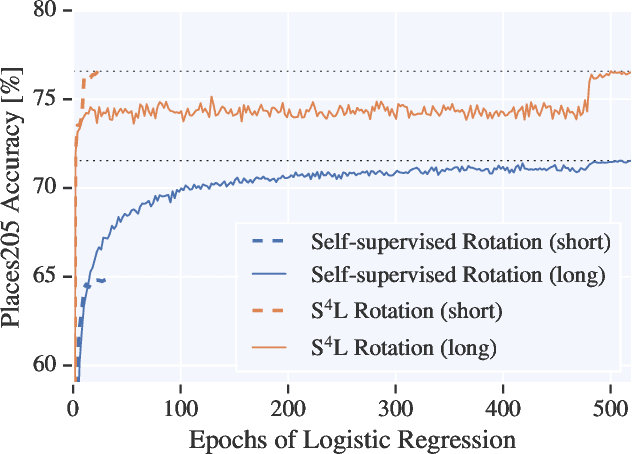
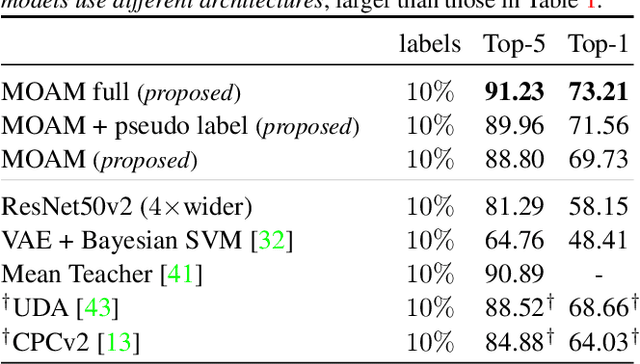
This work tackles the problem of semi-supervised learning of image classifiers. Our main insight is that the field of semi-supervised learning can benefit from the quickly advancing field of self-supervised visual representation learning. Unifying these two approaches, we propose the framework of self-supervised semi-supervised learning ($S^4L$) and use it to derive two novel semi-supervised image classification methods. We demonstrate the effectiveness of these methods in comparison to both carefully tuned baselines, and existing semi-supervised learning methods. We then show that $S^4L$ and existing semi-supervised methods can be jointly trained, yielding a new state-of-the-art result on semi-supervised ILSVRC-2012 with 10% of labels.
Deep Hyperspectral Prior: Denoising, Inpainting, Super-Resolution
Feb 01, 2019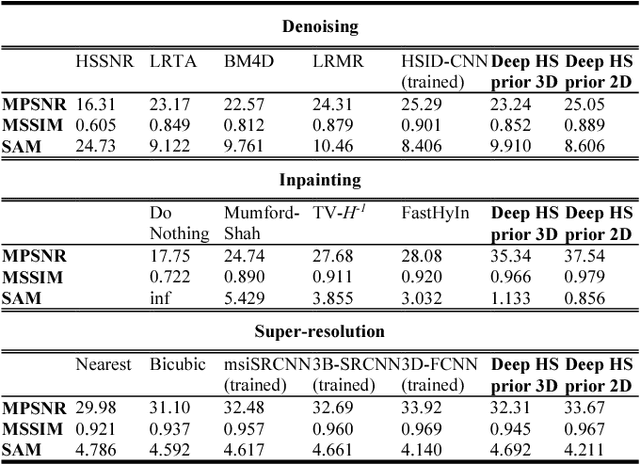
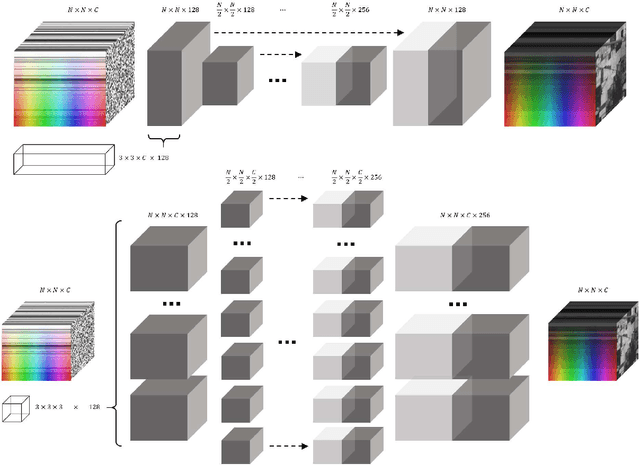


Deep learning algorithms have demonstrated state-of-the-art performance in various tasks of image restoration. This was made possible through the ability of CNNs to learn from large exemplar sets. However, the latter becomes an issue for hyperspectral image processing where datasets commonly consist of just a few images. In this work, we propose a new approach to denoising, inpainting, and super-resolution of hyperspectral image data using intrinsic properties of a CNN without any training. The performance of the given algorithm is shown to be comparable to the performance of trained networks, while its application is not restricted by the availability of training data. This work is an extension of original "deep prior" algorithm to HSI domain and 3D-convolutional networks.
Class Specific or Shared? A Hybrid Dictionary Learning Network for Image Classification
Apr 17, 2019
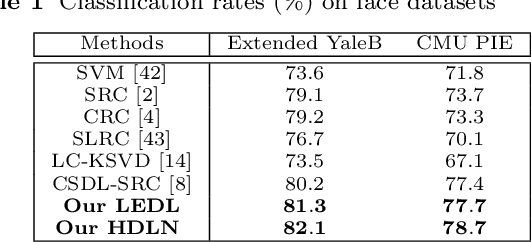
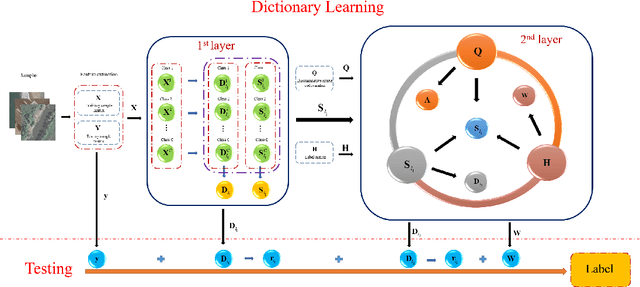
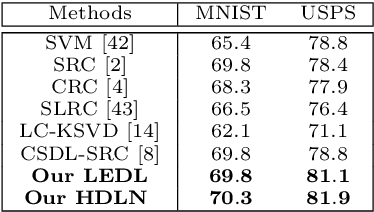
Dictionary learning methods can be split into two categories: i) class specific dictionary learning ii) class shared dictionary learning. The difference between the two categories is how to use the discriminative information. With the first category, samples of different classes are mapped to different subspaces which leads to some redundancy in the base vectors. For the second category, the samples in each specific class can not be described well. Moreover, most class shared dictionary learning methods use the L0-norm regularization term as the sparse constraint. In this paper, we first propose a novel class shared dictionary learning method named label embedded dictionary learning (LEDL) by introducing the L1-norm sparse constraint to replace the conventional L0-norm regularization term in LC-KSVD method. Then we propose a novel network named hybrid dictionary learning network (HDLN) to combine the class specific dictionary learning with class shared dictionary learning together to fully describe the feature to boost the performance of classification. Extensive experimental results on six benchmark datasets illustrate that our methods are capable of achieving superior performance compared to several conventional classification algorithms.
Bilateral Cyclic Constraint and Adaptive Regularization for Unsupervised Monocular Depth Prediction
Apr 06, 2019

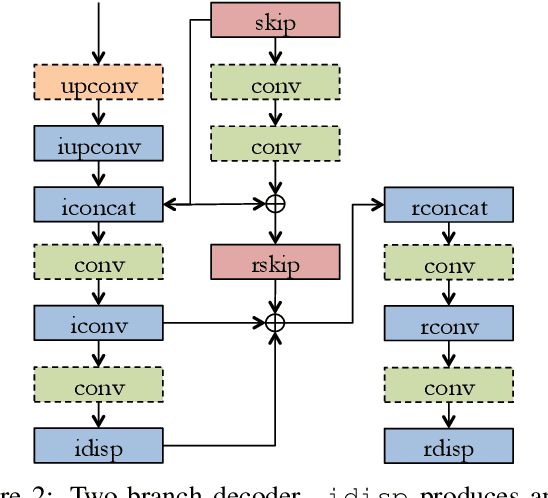
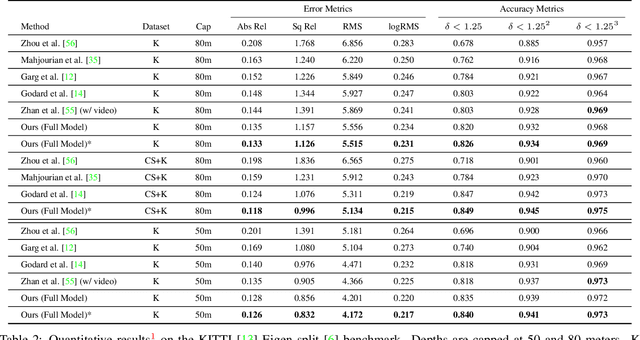
Supervised learning methods to infer (hypothesize) depth of a scene from a single image require costly per-pixel ground-truth. We follow a geometric approach that exploits abundant stereo imagery to learn a model to hypothesize scene structure without direct supervision. Although we train a network with stereo pairs, we only require a single image at test time to hypothesize disparity or depth. We propose a novel objective function that exploits the bilateral cyclic relationship between the left and right disparities and we introduce an adaptive regularization scheme that allows the network to handle both the co-visible and occluded regions in a stereo pair. This process ultimately produces a model to generate hypotheses for the 3-dimensional structure of the scene as viewed in a single image. When used to generate a single (most probable) estimate of depth, our method outperforms state-of-the-art unsupervised monocular depth prediction methods on the KITTI benchmarks. We show that our method generalizes well by applying our models trained on KITTI to the Make3d dataset.
Image Subset Selection Using Gabor Filters and Neural Networks
Apr 08, 2015


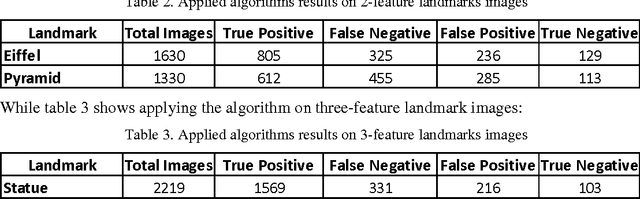
An automatic method for the selection of subsets of images, both modern and historic, out of a set of landmark large images collected from the Internet is presented in this paper. This selection depends on the extraction of dominant features using Gabor filtering. Features are selected carefully from a preliminary image set and fed into a neural network as a training data. The method collects a large set of raw landmark images containing modern and historic landmark images and non-landmark images. The method then processes these images to classify them as landmark and non-landmark images. The classification performance highly depends on the number of candidate features of the landmark.