 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robustness and Imperceptibility Enhancement in Watermarked Images by Color Transformation
Nov 02, 2019
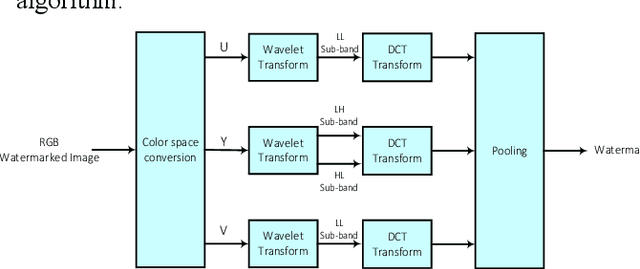
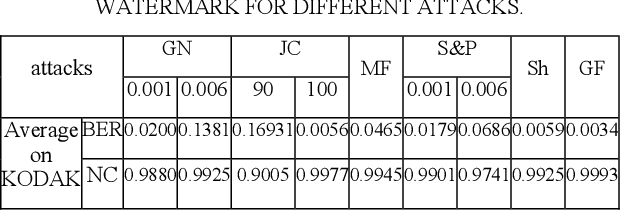
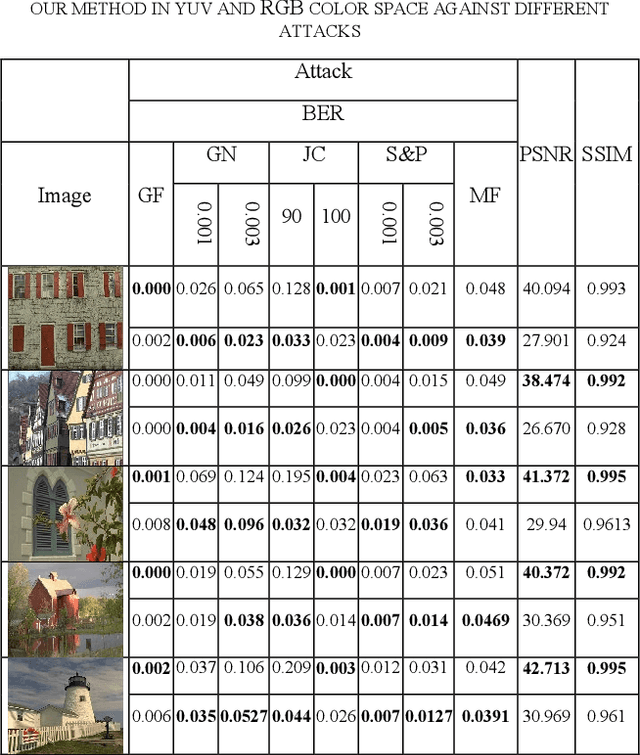
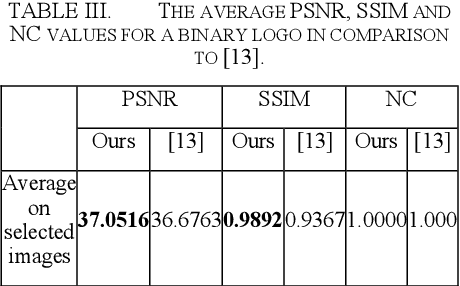
One of the effective methods for the preservation of copyright ownership of digital media is watermarking. Different watermarking techniques try to set a tradeoff between robustness and transparency of the process. In this research work, we have used color space conversion and frequency transform to achieve high robustness and transparency. Due to the distribution of image information in the RGB domain, we use the YUV color space, which concentrates the visual information in the Y channel. Embedding of the watermark is performed in the DCT coefficients of the specific wavelet subbands. Experimental results show high transparency and robustness of the proposed method.
Convolutional Neural Network Pruning Using Filter Attenuation
Feb 09, 2020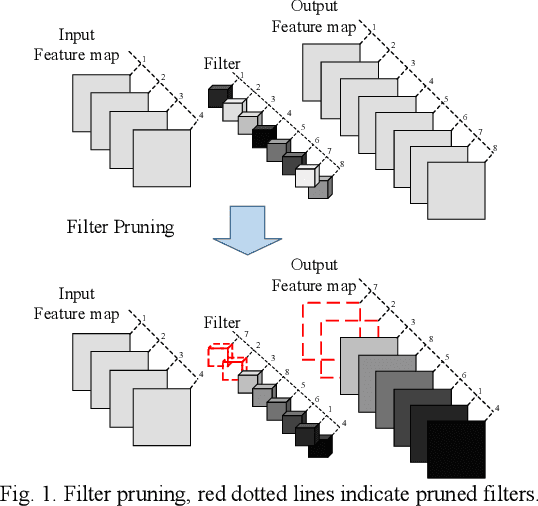
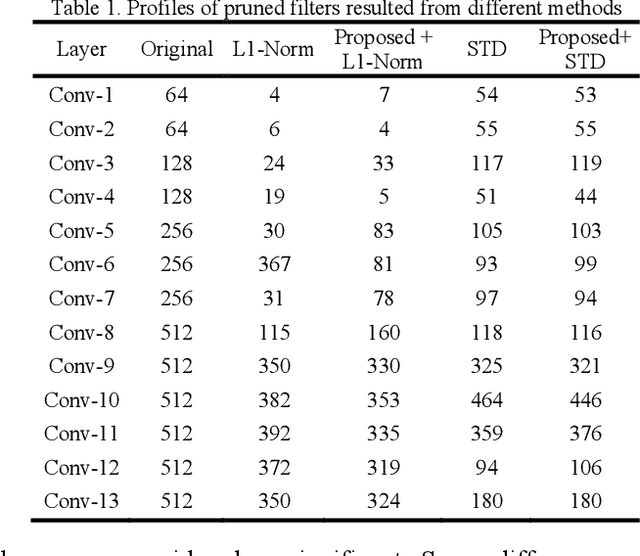
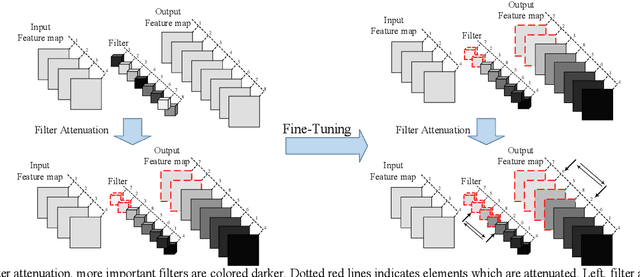

Filters are the essential elements in convolutional neural networks (CNNs). Filters are corresponded to the feature maps and form the main part of the computational and memory requirement for the CNN processing. In filter pruning methods, a filter with all of its components, including channels and connections, are removed. The removal of a filter can cause a drastic change in the network's performance. Also, the removed filters cannot come back to the network structure. We want to address these problems in this paper. We propose a CNN pruning method based on filter attenuation in which weak filters are not directly removed. Instead, weak filters are attenuated and gradually removed. In the proposed attenuation approach, weak filters are not abruptly removed, and there is a chance for these filters to return to the network. The filter attenuation method is assessed using the VGG model for the Cifar10 image classification task. Simulation results show that the filter attenuation works with different pruning criteria, and better results are obtained in comparison with the conventional pruning methods.
Finding Significant Subregions in Large Image Databases
Jun 19, 2009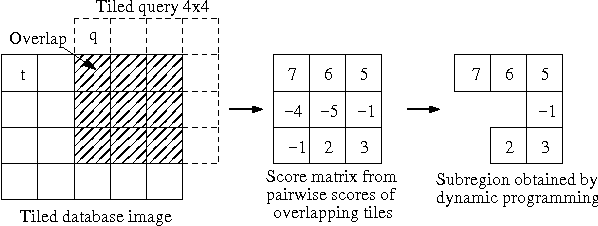

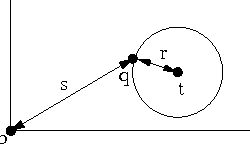
Images have become an important data source in many scientific and commercial domains. Analysis and exploration of image collections often requires the retrieval of the best subregions matching a given query. The support of such content-based retrieval requires not only the formulation of an appropriate scoring function for defining relevant subregions but also the design of new access methods that can scale to large databases. In this paper, we propose a solution to this problem of querying significant image subregions. We design a scoring scheme to measure the similarity of subregions. Our similarity measure extends to any image descriptor. All the images are tiled and each alignment of the query and a database image produces a tile score matrix. We show that the problem of finding the best connected subregion from this matrix is NP-hard and develop a dynamic programming heuristic. With this heuristic, we develop two index based scalable search strategies, TARS and SPARS, to query patterns in a large image repository. These strategies are general enough to work with other scoring schemes and heuristics. Experimental results on real image datasets show that TARS saves more than 87% query time on small queries, and SPARS saves up to 52% query time on large queries as compared to linear search. Qualitative tests on synthetic and real datasets achieve precision of more than 80%.
* 16 pages, 48 figures
Coupled-Projection Residual Network for MRI Super-Resolution
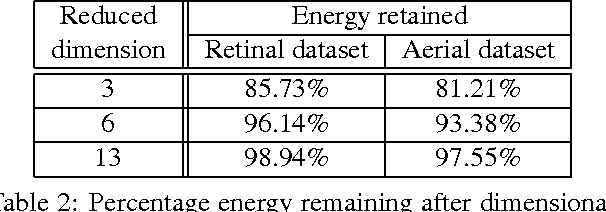
Jul 12, 2019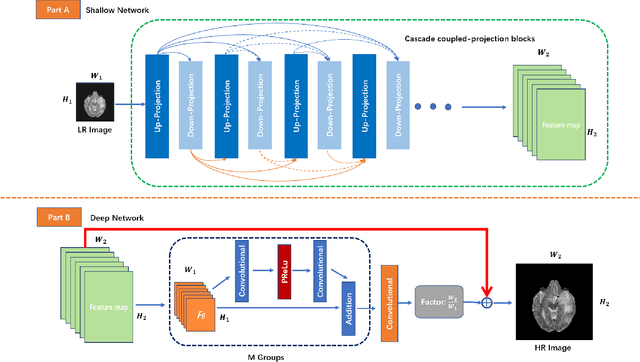
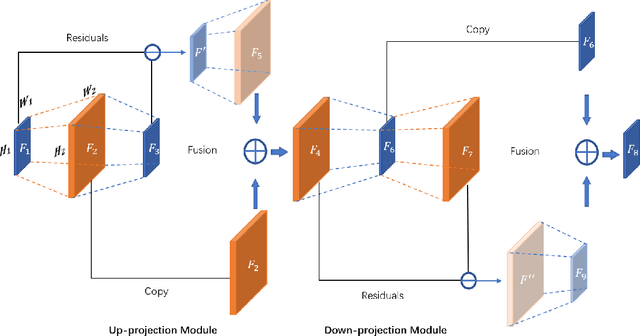
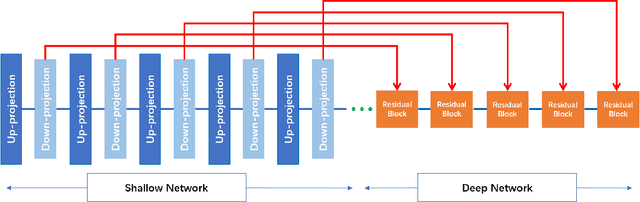
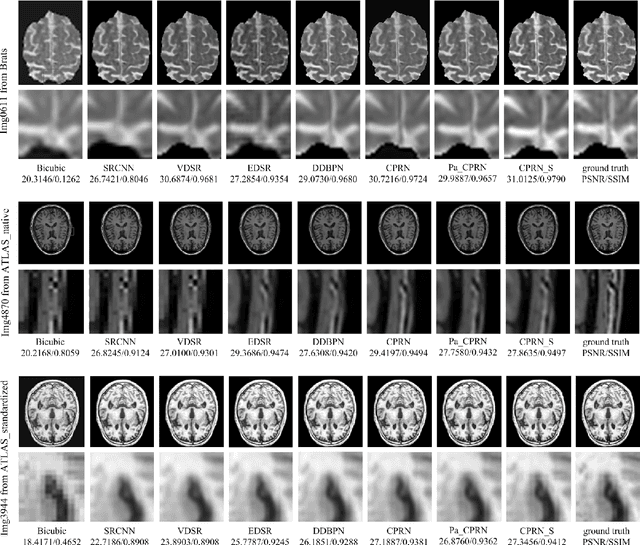
Magnetic Resonance Imaging(MRI) has been widely used in clinical application and pathology research by helping doctors make more accurate diagnoses. On the other hand, accurate diagnosis by MRI remains a great challenge as images obtained via present MRI techniques usually have low resolutions. Improving MRI image quality and resolution thus becomes a critically important task. This paper presents an innovative Coupled-Projection Residual Network (CPRN) for MRI super-resolution. The CPRN consists of two complementary sub-networks: a shallow network and a deep network that keep the content consistency while learning high frequency differences between low-resolution and high-resolution images. The shallow sub-network employs coupled-projection for better retaining the MRI image details, where a novel feedback mechanism is introduced to guide the reconstruction of high-resolution images. The deep sub-network learns from the residuals of the high-frequency image information, where multiple residual blocks are cascaded to magnify the MRI images at the last network layer. Finally, the features from the shallow and deep sub-networks are fused for the reconstruction of high-resolution MRI images. For effective fusion of features from the deep and shallow sub-networks, a step-wise connection (CPRN S) is designed as inspired by the human cognitive processes (from simple to complex). Experiments over three public MRI datasets show that our proposed CPRN achieves superior MRI super-resolution performance as compared with the state-of-the-art. Our source code will be publicly available at http://www.yongxu.org/lunwen.html.
Evaluating the Communication Efficiency in Federated Learning Algorithms
Apr 06, 2020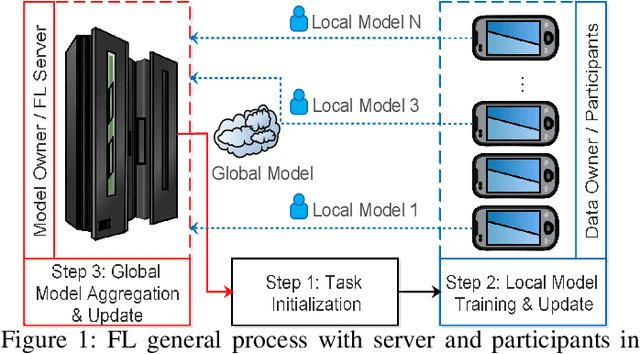
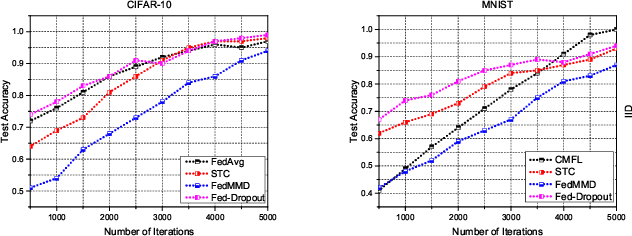
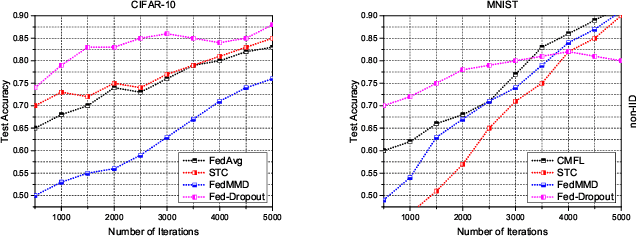
In the era of advanced technologies, mobile devices are equipped with computing and sensing capabilities that gather excessive amounts of data. These amounts of data are suitable for training different learning models. Cooperated with advancements in Deep Learning (DL), these learning models empower numerous useful applications, e.g., image processing, speech recognition, healthcare, vehicular network and many more. Traditionally, Machine Learning (ML) approaches require data to be centralised in cloud-based data-centres. However, this data is often large in quantity and privacy-sensitive which prevents logging into these data-centres for training the learning models. In turn, this results in critical issues of high latency and communication inefficiency. Recently, in light of new privacy legislations in many countries, the concept of Federated Learning (FL) has been introduced. In FL, mobile users are empowered to learn a global model by aggregating their local models, without sharing the privacy-sensitive data. Usually, these mobile users have slow network connections to the data-centre where the global model is maintained. Moreover, in a complex and large scale network, heterogeneous devices that have various energy constraints are involved. This raises the challenge of communication cost when implementing FL at large scale. To this end, in this research, we begin with the fundamentals of FL, and then, we highlight the recent FL algorithms and evaluate their communication efficiency with detailed comparisons. Furthermore, we propose a set of solutions to alleviate the existing FL problems both from communication perspective and privacy perspective.
Deep Adaptive Wavelet Network
Dec 10, 2019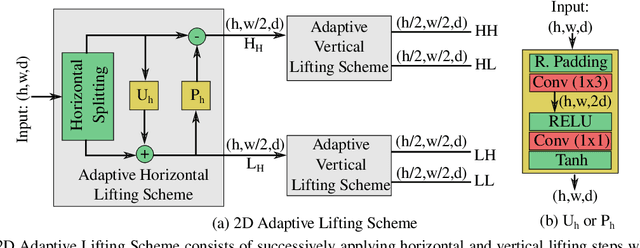
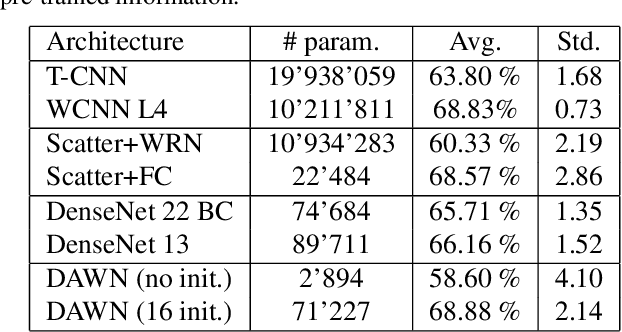
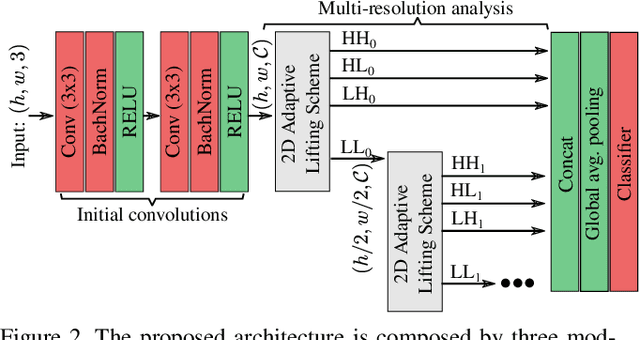
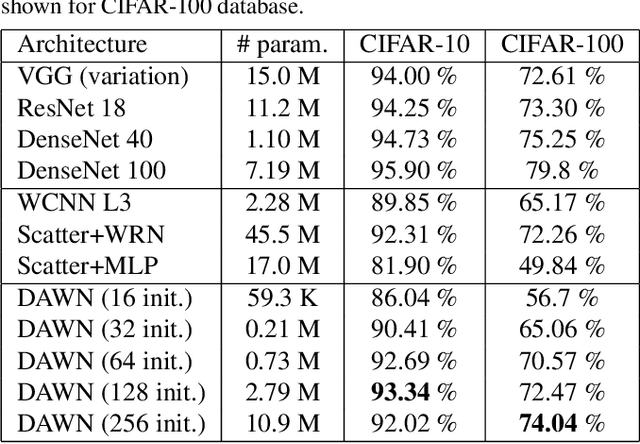
Even though convolutional neural networks have become the method of choice in many fields of computer vision, they still lack interpretability and are usually designed manually in a cumbersome trial-and-error process. This paper aims at overcoming those limitations by proposing a deep neural network, which is designed in a systematic fashion and is interpretable, by integrating multiresolution analysis at the core of the deep neural network design. By using the lifting scheme, it is possible to generate a wavelet representation and design a network capable of learning wavelet coefficients in an end-to-end form. Compared to state-of-the-art architectures, the proposed model requires less hyper-parameter tuning and achieves competitive accuracy in image classification tasks
Semantic Granularity Metric Learning for Visual Search
Nov 14, 2019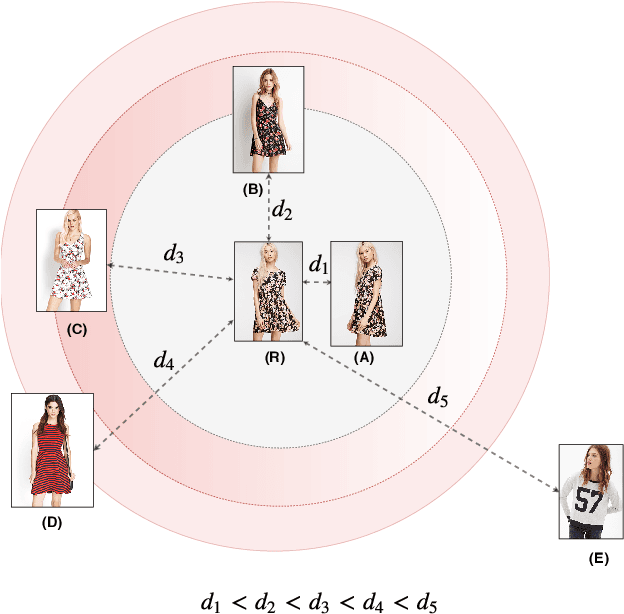

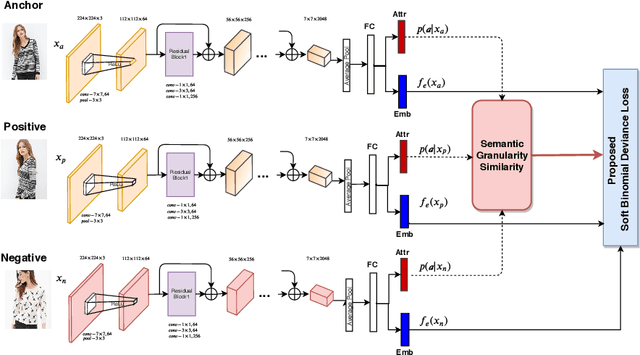
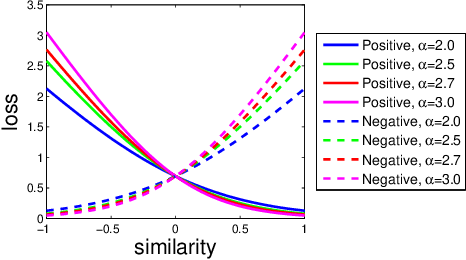
Deep metric learning applied to various applications has shown promising results in identification, retrieval and recognition. Existing methods often do not consider different granularity in visual similarity. However, in many domain applications, images exhibit similarity at multiple granularities with visual semantic concepts, e.g. fashion demonstrates similarity ranging from clothing of the exact same instance to similar looks/design or a common category. Therefore, training image triplets/pairs used for metric learning inherently possess different degree of information. However, the existing methods often treats them with equal importance during training. This hinders capturing the underlying granularities in feature similarity required for effective visual search. In view of this, we propose a new deep semantic granularity metric learning (SGML) that develops a novel idea of leveraging attribute semantic space to capture different granularity of similarity, and then integrate this information into deep metric learning. The proposed method simultaneously learns image attributes and embeddings using multitask CNNs. The two tasks are not only jointly optimized but are further linked by the semantic granularity similarity mappings to leverage the correlations between the tasks. To this end, we propose a new soft-binomial deviance loss that effectively integrates the degree of information in training samples, which helps to capture visual similarity at multiple granularities. Compared to recent ensemble-based methods, our framework is conceptually elegant, computationally simple and provides better performance. We perform extensive experiments on benchmark metric learning datasets and demonstrate that our method outperforms recent state-of-the-art methods, e.g., 1-4.5\% improvement in Recall@1 over the previous state-of-the-arts [1],[2] on DeepFashion In-Shop dataset.
RF-Net: An End-to-End Image Matching Network based on Receptive Field
Jun 03, 2019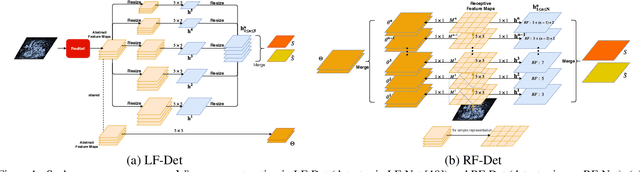
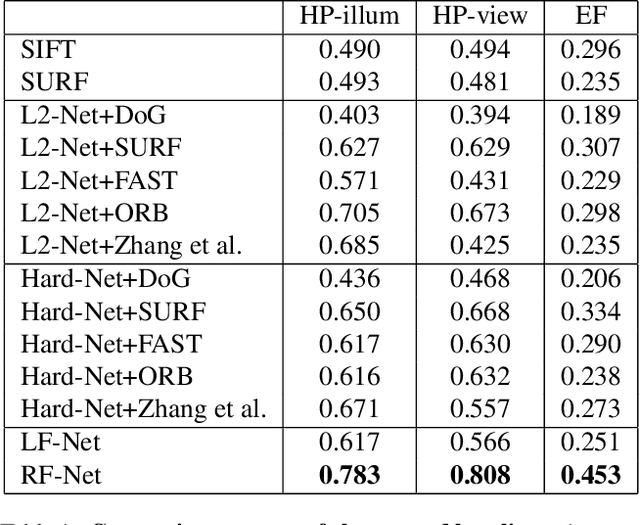
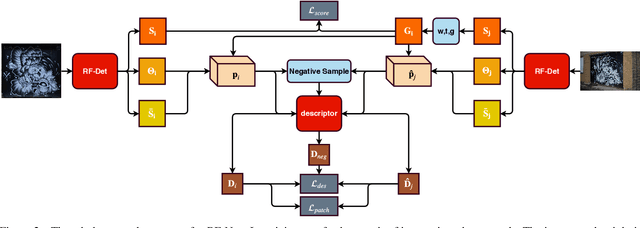
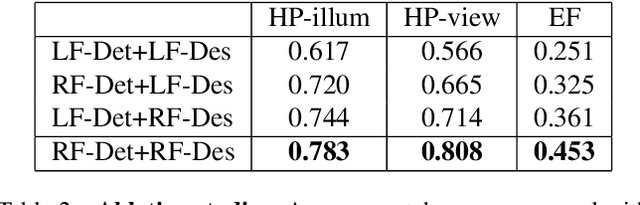
This paper proposes a new end-to-end trainable matching network based on receptive field, RF-Net, to compute sparse correspondence between images. Building end-to-end trainable matching framework is desirable and challenging. The very recent approach, LF-Net, successfully embeds the entire feature extraction pipeline into a jointly trainable pipeline, and produces the state-of-the-art matching results. This paper introduces two modifications to the structure of LF-Net. First, we propose to construct receptive feature maps, which lead to more effective keypoint detection. Second, we introduce a general loss function term, neighbor mask, to facilitate training patch selection. This results in improved stability in descriptor training. We trained RF-Net on the open dataset HPatches, and compared it with other methods on multiple benchmark datasets. Experiments show that RF-Net outperforms existing state-of-the-art methods.
Depth-Based Selective Blurring in Stereo Images Using Accelerated Framework
Jan 21, 2020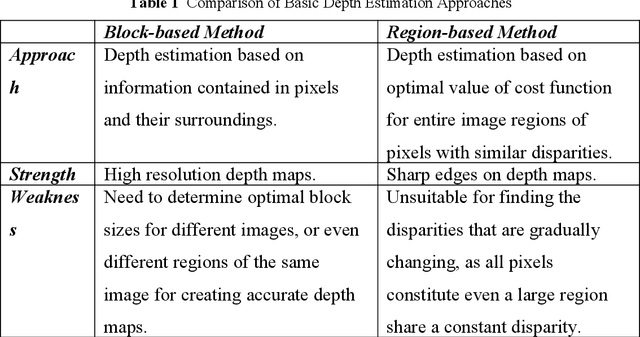


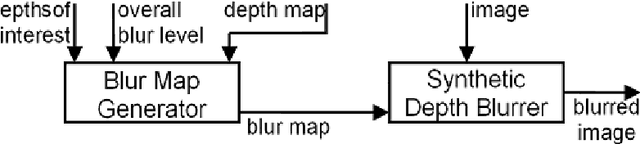
We propose a hybrid method for stereo disparity estimation by combining block and region-based stereo matching approaches. It generates dense depth maps from disparity measurements of only 18 % image pixels (left or right). The methodology involves segmenting pixel lightness values using fast K-Means implementation, refining segment boundaries using morphological filtering and connected components analysis; then determining boundaries' disparities using sum of absolute differences (SAD) cost function. Complete disparity maps are reconstructed from boundaries' disparities. We consider an application of our method for depth-based selective blurring of non-interest regions of stereo images, using Gaussian blur to de-focus users' non-interest regions. Experiments on Middlebury dataset demonstrate that our method outperforms traditional disparity estimation approaches using SAD and normalized cross correlation by up to 33.6 % and some recent methods by up to 6.1 %. Further, our method is highly parallelizable using CPU and GPU framework based on Java Thread Pool and APARAPI with speed-up of 5.8 for 250 stereo video frames (4,096 x 2,304).
* arXiv admin note: text overlap with arXiv:2001.06967
Equivariant neural networks and equivarification
Jun 19, 2019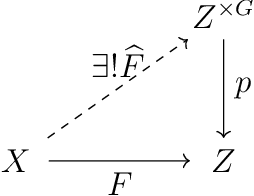
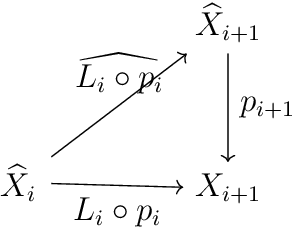
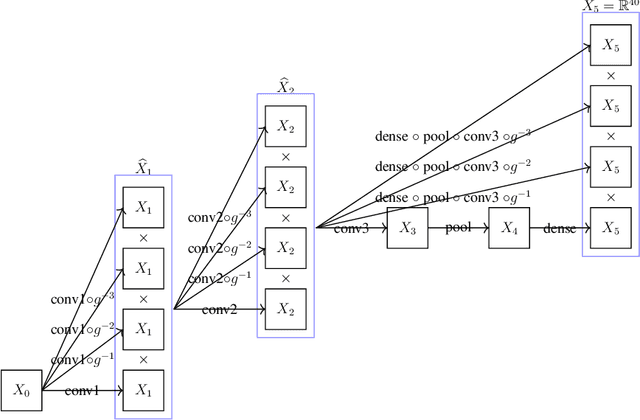

We provide a process to modify a neural network to an equivariant one, which we call {\em equivarification}. As an illustration, we build an equivariant neural network for image classification by equivarifying a convolutional neural network.