 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Next Token Prediction: A Multilingual Benchmark for Personalized Response Generation
Oct 16, 2025



Large language models (LLMs) excel at general next-token prediction but still struggle to generate responses that reflect how individuals truly communicate, such as replying to emails or social messages in their own style. However, real SNS or email histories are difficult to collect due to privacy concerns. To address this, we propose the task of "Your Next Token Prediction (YNTP)", which models a user's precise word choices through controlled human-agent conversations. We build a multilingual benchmark of 100 dialogue sessions across English, Japanese, and Chinese, where users interact for five days with psychologically grounded NPCs based on MBTI dimensions. This setup captures natural, daily-life communication patterns and enables analysis of users' internal models. We evaluate prompt-based and fine-tuning-based personalization methods, establishing the first benchmark for YNTP and a foundation for user-aligned language modeling. The dataset is available at: https://github.com/AnonymousHub4Submissions/your-next-token-prediction-dataset-100
LLM-Based Social Simulations Require a Boundary
Jun 24, 2025This position paper argues that large language model (LLM)-based social simulations should establish clear boundaries to meaningfully contribute to social science research. While LLMs offer promising capabilities for modeling human-like agents compared to traditional agent-based modeling, they face fundamental limitations that constrain their reliability for social pattern discovery. The core issue lies in LLMs' tendency towards an ``average persona'' that lacks sufficient behavioral heterogeneity, a critical requirement for simulating complex social dynamics. We examine three key boundary problems: alignment (simulated behaviors matching real-world patterns), consistency (maintaining coherent agent behavior over time), and robustness (reproducibility under varying conditions). We propose heuristic boundaries for determining when LLM-based simulations can reliably advance social science understanding. We believe that these simulations are more valuable when focusing on (1) collective patterns rather than individual trajectories, (2) agent behaviors aligning with real population averages despite limited variance, and (3) proper validation methods available for testing simulation robustness. We provide a practical checklist to guide researchers in determining the appropriate scope and claims for LLM-based social simulations.
The Hidden Strength of Disagreement: Unraveling the Consensus-Diversity Tradeoff in Adaptive Multi-Agent Systems
Feb 23, 2025



Consensus formation is pivotal in multi-agent systems (MAS), balancing collective coherence with individual diversity. Conventional LLM-based MAS primarily rely on explicit coordination, e.g., prompts or voting, risking premature homogenization. We argue that implicit consensus, where agents exchange information yet independently form decisions via in-context learning, can be more effective in dynamic environments that require long-horizon adaptability. By retaining partial diversity, systems can better explore novel strategies and cope with external shocks. We formalize a consensus-diversity tradeoff, showing conditions where implicit methods outperform explicit ones. Experiments on three scenarios -- Dynamic Disaster Response, Information Spread and Manipulation, and Dynamic Public-Goods Provision -- confirm partial deviation from group norms boosts exploration, robustness, and performance. We highlight emergent coordination via in-context learning, underscoring the value of preserving diversity for resilient decision-making.
Self-Agreement: A Framework for Fine-tuning Language Models to Find Agreement among Diverse Opinions
May 19, 2023



Finding an agreement among diverse opinions is a challenging topic in multiagent systems. Recently, large language models (LLMs) have shown great potential in addressing this challenge due to their remarkable capabilities in comprehending human opinions and generating human-like text. However, they typically rely on extensive human-annotated data. In this paper, we propose Self-Agreement, a novel framework for fine-tuning LLMs to autonomously find agreement using data generated by LLM itself. Specifically, our approach employs the generative pre-trained transformer-3 (GPT-3) to generate multiple opinions for each question in a question dataset and create several agreement candidates among these opinions. Then, a bidirectional encoder representations from transformers (BERT)-based model evaluates the agreement score of each agreement candidate and selects the one with the highest agreement score. This process yields a dataset of question-opinion-agreements, which we use to fine-tune a pre-trained LLM for discovering agreements among diverse opinions. Remarkably, a pre-trained LLM fine-tuned by our Self-Agreement framework achieves comparable performance to GPT-3 with only 1/25 of its parameters, showcasing its ability to identify agreement among various opinions without the need for human-annotated data.
Best-Answer Prediction in Q&A Sites Using User Information
Dec 15, 2022



Community Question Answering (CQA) sites have spread and multiplied significantly in recent years. Sites like Reddit, Quora, and Stack Exchange are becoming popular amongst people interested in finding answers to diverse questions. One practical way of finding such answers is automatically predicting the best candidate given existing answers and comments. Many studies were conducted on answer prediction in CQA but with limited focus on using the background information of the questionnaires. We address this limitation using a novel method for predicting the best answers using the questioner's background information and other features, such as the textual content or the relationships with other participants. Our answer classification model was trained using the Stack Exchange dataset and validated using the Area Under the Curve (AUC) metric. The experimental results show that the proposed method complements previous methods by pointing out the importance of the relationships between users, particularly throughout the level of involvement in different communities on Stack Exchange. Furthermore, we point out that there is little overlap between user-relation information and the information represented by the shallow text features and the meta-features, such as time differences.
Fairness based Multi-Preference Resource Allocation in Decentralised Open Markets
Sep 01, 2021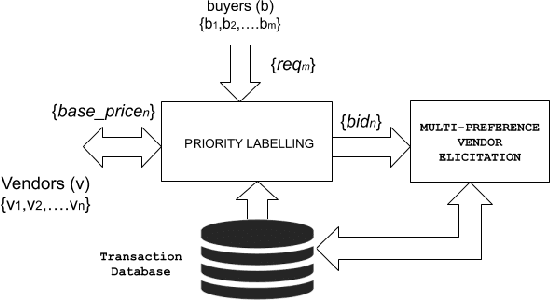
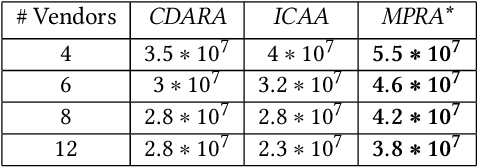

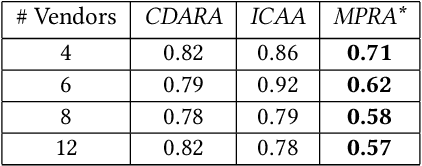
In this work, we focus on resource allocation in a decentralised open market. In decentralised open markets consists of multiple vendors and multiple dynamically-arriving buyers, thus makes the market complex and dynamic. Because, in these markets, negotiations among vendors and buyers take place over multiple conflicting issues such as price, scalability, robustness, delay, etc. As a result, optimising the resource allocation in such open markets becomes directly dependent on two key decisions, which are; incorporating a different kind of buyers' preferences, and fairness based vendor elicitation strategy. Towards this end, in this work, we propose a three-step resource allocation approach that employs a reverse-auction paradigm. At the first step, priority label is attached to each bidding vendor based on the proposed priority mechanism. Then, at the second step, the preference score is calculated for all the different kinds of preferences of the buyers. Finally, at the third step, based on the priority label of the vendor and the preference score winner is determined. Finally, we compare the proposed approach with two state-of-the-art resource pricing and allocation strategies. The experimental results show that the proposed approach outperforms the other two resource allocation approaches in terms of the independent utilities of buyers and the overall utility of the open market.
Federated Learning Versus Classical Machine Learning: A Convergence Comparison
Jul 22, 2021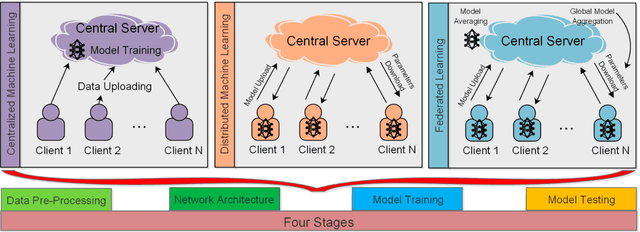
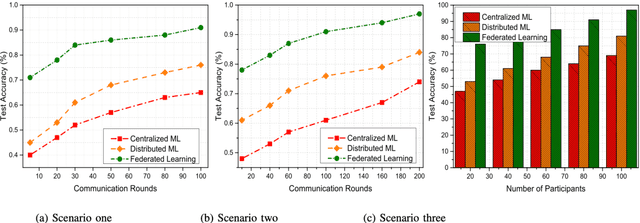
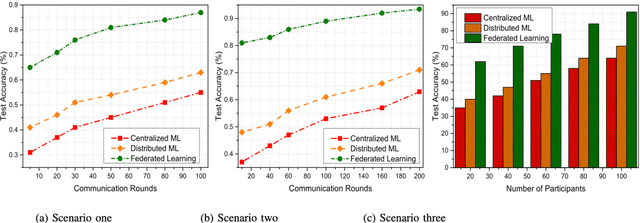
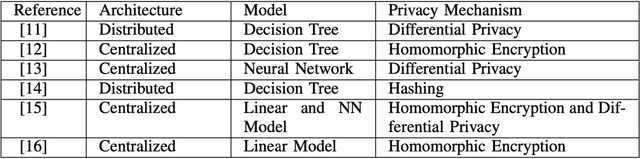
In the past few decades, machine learning has revolutionized data processing for large scale applications. Simultaneously, increasing privacy threats in trending applications led to the redesign of classical data training models. In particular, classical machine learning involves centralized data training, where the data is gathered, and the entire training process executes at the central server. Despite significant convergence, this training involves several privacy threats on participants' data when shared with the central cloud server. To this end, federated learning has achieved significant importance over distributed data training. In particular, the federated learning allows participants to collaboratively train the local models on local data without revealing their sensitive information to the central cloud server. In this paper, we perform a convergence comparison between classical machine learning and federated learning on two publicly available datasets, namely, logistic-regression-MNIST dataset and image-classification-CIFAR-10 dataset. The simulation results demonstrate that federated learning achieves higher convergence within limited communication rounds while maintaining participants' anonymity. We hope that this research will show the benefits and help federated learning to be implemented widely.
Relational Argumentation Semantics
Apr 26, 2021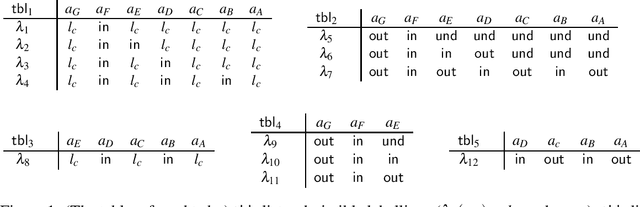
In this paper, we propose a fresh perspective on argumentation semantics, to view them as a relational database. It offers encapsulation of the underlying argumentation graph, and allows us to understand argumentation semantics under a single, relational perspective, leading to the concept of relational argumentation semantics. This is a direction to understand argumentation semantics through a common formal language. We show that many existing semantics such as explanation semantics, multi-agent semantics, and more typical semantics, that have been proposed for specific purposes, are understood in the relational perspective.
A Robust Model for Trust Evaluation during Interactions between Agents in a Sociable Environment
Apr 17, 2021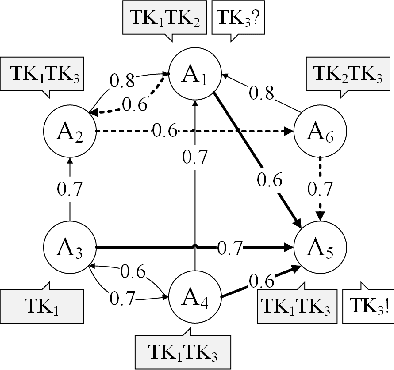
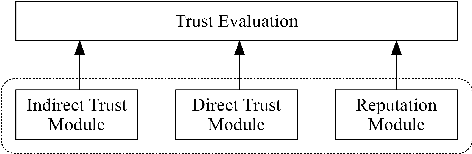
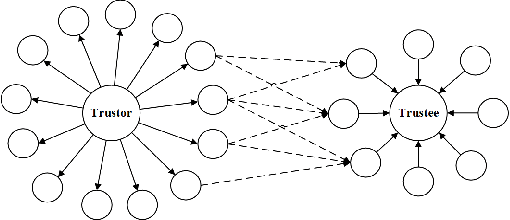
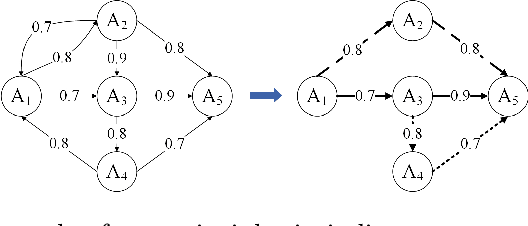
Trust evaluation is an important topic in both research and applications in sociable environments. This paper presents a model for trust evaluation between agents by the combination of direct trust, indirect trust through neighbouring links and the reputation of an agent in the environment (i.e. social network) to provide the robust evaluation. Our approach is typology independent from social network structures and in a decentralized manner without a central controller, so it can be used in broad domains.
Privacy Information Classification: A Hybrid Approach
Jan 27, 2021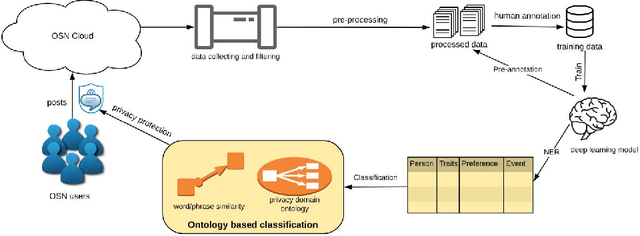
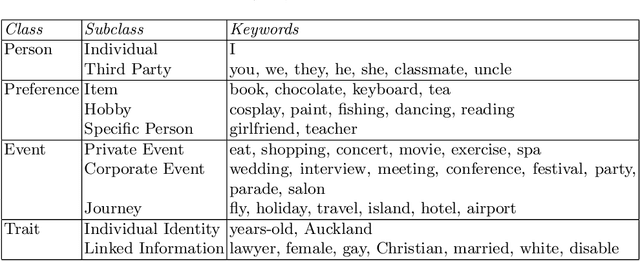
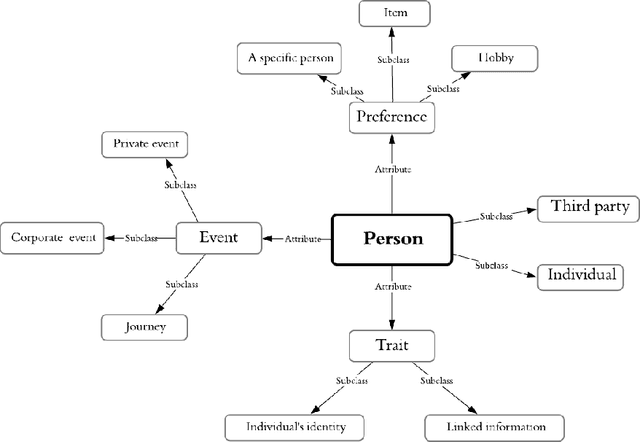
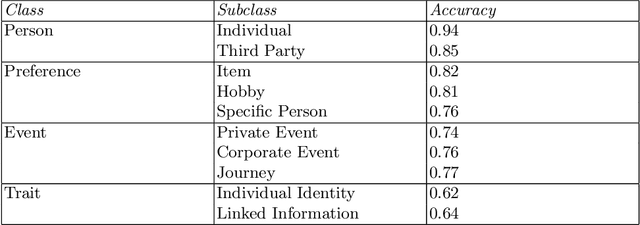
A large amount of information has been published to online social networks every day. Individual privacy-related information is also possibly disclosed unconsciously by the end-users. Identifying privacy-related data and protecting the online social network users from privacy leakage turn out to be significant. Under such a motivation, this study aims to propose and develop a hybrid privacy classification approach to detect and classify privacy information from OSNs. The proposed hybrid approach employs both deep learning models and ontology-based models for privacy-related information extraction. Extensive experiments are conducted to validate the proposed hybrid approach, and the empirical results demonstrate its superiority in assisting online social network users against privacy leakage.