 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Using panoramic videos for multi-person localization and tracking in a 3D panoramic coordinate
Dec 05, 2019
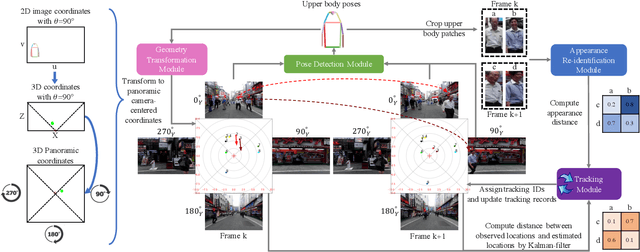
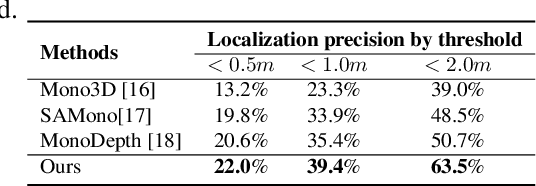
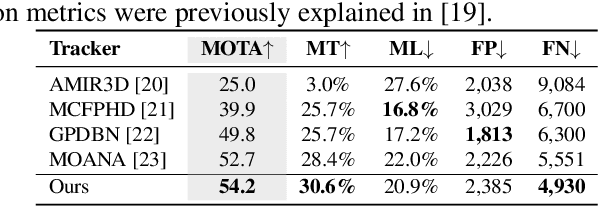
This work proposes a new human-related video processing task named 3D panoramic multi-person localization and tracking. With a benchmark dataset and a simple yet effective solution, it establishes a new paradigm for multi-person tracking systems and related applications. Unlike existing methods that can only work on a 2D coordinate or a narrow-angle-view 3D coordinate, our proposal can maximally explore the 3D trajectory information of tracking targets. This is approached by applying camera geometry to transform human locations from 2D panoramic image coordinates to a 3D panoramic camera coordinate, and then by applying a tracking algorithm that associates human appearance and 3D trajectory together.
Computational Mirrors: Blind Inverse Light Transport by Deep Matrix Factorization
Dec 05, 2019

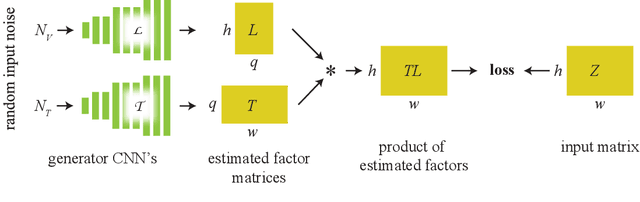

We recover a video of the motion taking place in a hidden scene by observing changes in indirect illumination in a nearby uncalibrated visible region. We solve this problem by factoring the observed video into a matrix product between the unknown hidden scene video and an unknown light transport matrix. This task is extremely ill-posed, as any non-negative factorization will satisfy the data. Inspired by recent work on the Deep Image Prior, we parameterize the factor matrices using randomly initialized convolutional neural networks trained in a one-off manner, and show that this results in decompositions that reflect the true motion in the hidden scene.
* 14 pages, 5 figures, Advances in Neural Information Processing Systems 2019
Adversarial Ranking Attack and Defense
Feb 26, 2020
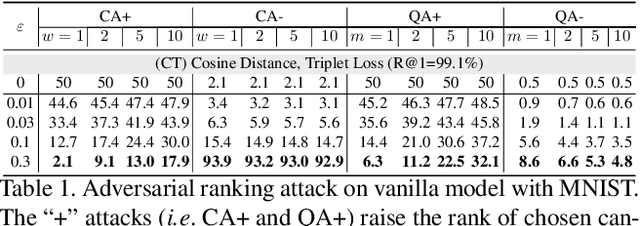
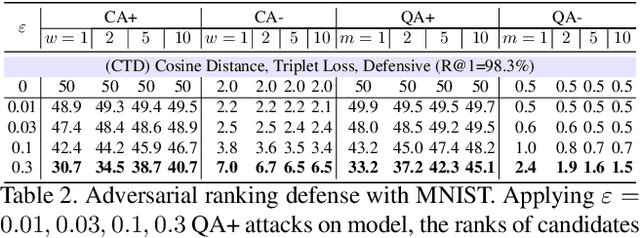
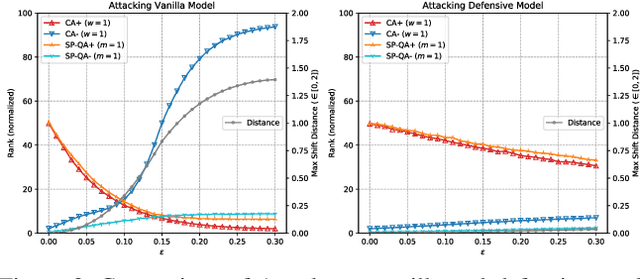
Deep Neural Network (DNN) classifiers are vulnerable to adversarial attack, where an imperceptible perturbation could result in misclassification. However, the vulnerability of DNN-based image ranking systems remains under-explored. In this paper, we propose two attacks against deep ranking systems, i.e., Candidate Attack and Query Attack, that can raise or lower the rank of chosen candidates by adversarial perturbations. Specifically, the expected ranking order is first represented as a set of inequalities, and then a triplet-like objective function is designed to obtain the optimal perturbation. Conversely, a defense method is also proposed to improve the ranking system robustness, which can mitigate all the proposed attacks simultaneously. Our adversarial ranking attacks and defense are evaluated on datasets including MNIST, Fashion-MNIST, and Stanford-Online-Products. Experimental results demonstrate that a typical deep ranking system can be effectively compromised by our attacks. Meanwhile, the system robustness can be moderately improved with our defense. Furthermore, the transferable and universal properties of our adversary illustrate the possibility of realistic black-box attack.
Generation of Consistent Sets of Multi-Label Classification Rules with a Multi-Objective Evolutionary Algorithm
Mar 27, 2020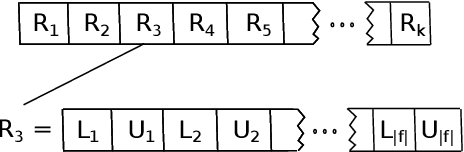
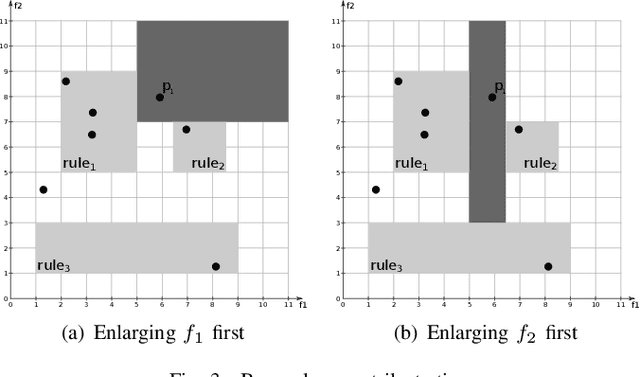
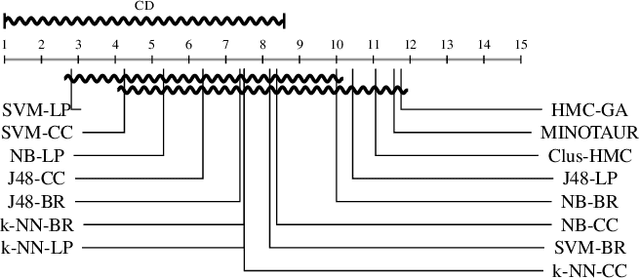
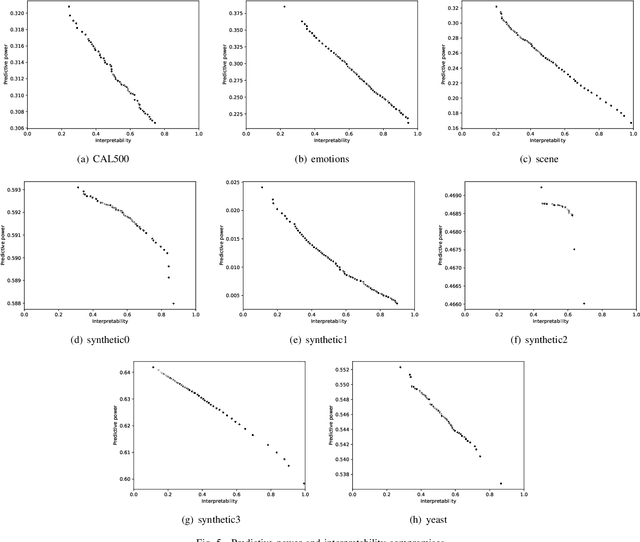
Multi-label classification consists in classifying an instance into two or more classes simultaneously. It is a very challenging task present in many real-world applications, such as classification of biology, image, video, audio, and text. Recently, the interest in interpretable classification models has grown, partially as a consequence of regulations such as the General Data Protection Regulation. In this context, we propose a multi-objective evolutionary algorithm that generates multiple rule-based multi-label classification models, allowing users to choose among models that offer different compromises between predictive power and interpretability. An important contribution of this work is that different from most algorithms, which usually generate models based on lists (ordered collections) of rules, our algorithm generates models based on sets (unordered collections) of rules, increasing interpretability. Also, by employing a conflict avoidance algorithm during the rule-creation, every rule within a given model is guaranteed to be consistent with every other rule in the same model. Thus, no conflict resolution strategy is required, evolving simpler models. We conducted experiments on synthetic and real-world datasets and compared our results with state-of-the-art algorithms in terms of predictive performance (F-Score) and interpretability (model size), and demonstrate that our best models had comparable F-Score and smaller model sizes.
MVStylizer: An Efficient Edge-Assisted Video Photorealistic Style Transfer System for Mobile Phones
May 24, 2020



Recent research has made great progress in realizing neural style transfer of images, which denotes transforming an image to a desired style. Many users start to use their mobile phones to record their daily life, and then edit and share the captured images and videos with other users. However, directly applying existing style transfer approaches on videos, i.e., transferring the style of a video frame by frame, requires an extremely large amount of computation resources. It is still technically unaffordable to perform style transfer of videos on mobile phones. To address this challenge, we propose MVStylizer, an efficient edge-assisted photorealistic video style transfer system for mobile phones. Instead of performing stylization frame by frame, only key frames in the original video are processed by a pre-trained deep neural network (DNN) on edge servers, while the rest of stylized intermediate frames are generated by our designed optical-flow-based frame interpolation algorithm on mobile phones. A meta-smoothing module is also proposed to simultaneously upscale a stylized frame to arbitrary resolution and remove style transfer related distortions in these upscaled frames. In addition, for the sake of continuously enhancing the performance of the DNN model on the edge server, we adopt a federated learning scheme to keep retraining each DNN model on the edge server with collected data from mobile clients and syncing with a global DNN model on the cloud server. Such a scheme effectively leverages the diversity of collected data from various mobile clients and efficiently improves the system performance. Our experiments demonstrate that MVStylizer can generate stylized videos with an even better visual quality compared to the state-of-the-art method while achieving 75.5$\times$ speedup for 1920$\times$1080 videos.
Robustness properties of Facebook's ResNeXt WSL models
Aug 02, 2019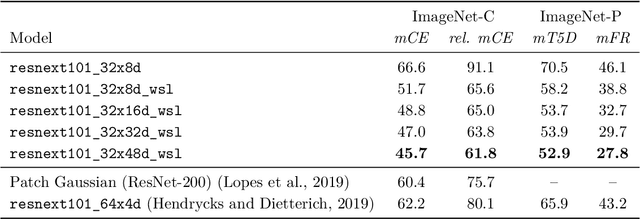
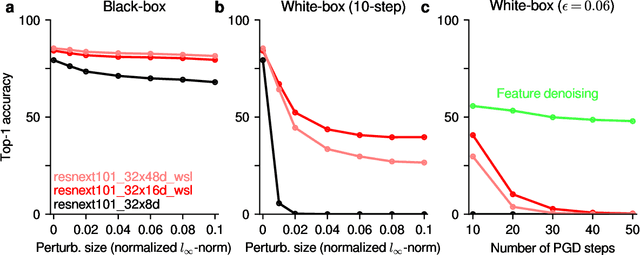
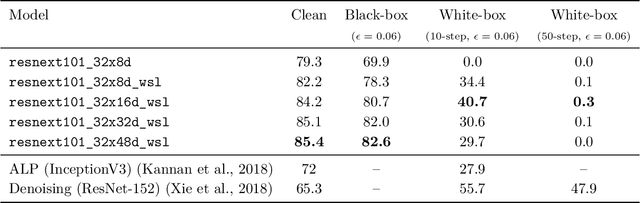

We investigate the robustness properties of ResNeXt image recognition models trained with billion scale weakly-supervised data (ResNeXt WSL models). These models, recently made public by Facebook AI, were trained on ~1B images from Instagram and fine-tuned on ImageNet. We show that these models display an unprecedented degree of robustness against common image corruptions and perturbations, as measured by the ImageNet-C and ImageNet-P benchmarks. The largest of the released models, in particular, achieves state-of-the-art results on both ImageNet-C and ImageNet-P by a large margin. The gains on ImageNet-C and ImageNet-P far outpace the gains on ImageNet validation accuracy, suggesting the former as more useful benchmarks to measure further progress in image recognition. Remarkably, the ResNeXt WSL models even achieve a limited degree of adversarial robustness against state-of-the-art white-box attacks (10-step PGD attacks). However, in contrast to adversarially trained models, the robustness of the ResNeXt WSL models rapidly declines with the number of PGD steps, suggesting that these models do not achieve genuine adversarial robustness. Visualization of the learned features also confirms this conclusion. Finally, we show that although the ResNeXt WSL models are more shape-biased than comparable ImageNet-trained models in a shape-texture cue conflict experiment, they still remain much more texture-biased than humans and their accuracy on the recently introduced "natural adversarial examples" (ImageNet-A) also remains low, suggesting that they share many of the underlying characteristics of ImageNet-trained models that make these benchmarks challenging.
Stereoscopic Dark Flash for Low-light Photography
Jan 09, 2019
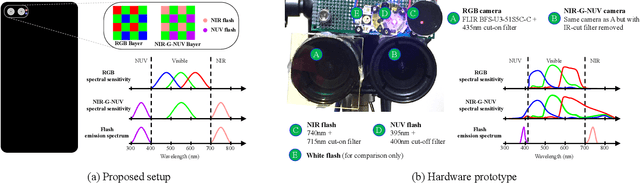
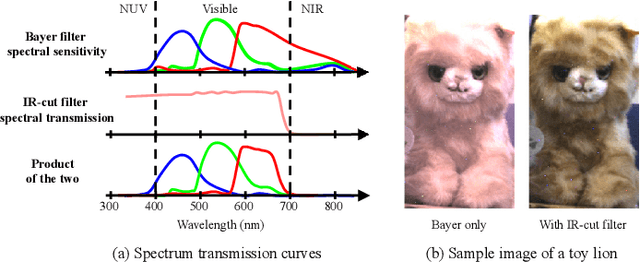
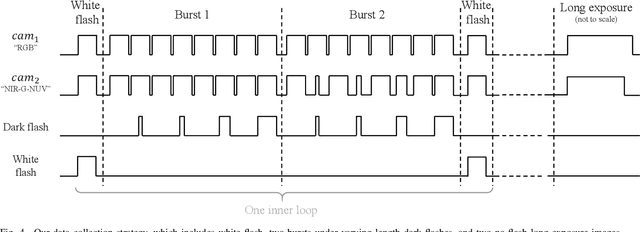
In this work, we present a camera configuration for acquiring "stereoscopic dark flash" images: a simultaneous stereo pair in which one camera is a conventional RGB sensor, but the other camera is sensitive to near-infrared and near-ultraviolet instead of R and B. When paired with a "dark" flash (i.e., one having near-infrared and near-ultraviolet light, but no visible light) this camera allows us to capture the two images in a flash/no-flash image pair at the same time, all while not disturbing any human subjects or onlookers with a dazzling visible flash. We present a hardware prototype of this camera that approximates an idealized camera, and we present an imaging procedure that let us acquire dark flash stereo pairs that closely resemble those we would get from that idealized camera. We then present a technique for fusing these stereo pairs, first by performing registration and warping, and then by using recent advances in hyperspectral image fusion and deep learning to produce a final image. Because our camera configuration and our data acquisition process allow us to capture true low-noise long exposure RGB images alongside our dark flash stereo pairs, our learned model can be trained end-to-end to produce a fused image that retains the color and tone of a real RGB image while having the low-noise properties of a flash image.
Active Learning in Video Tracking
Dec 29, 2019
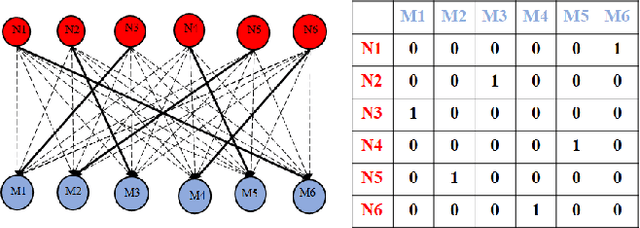
Active learning methods, like uncertainty sampling, combined with probabilistic prediction techniques have achieved success in various problems like image classification and text classification. For more complex multivariate prediction tasks, the relationships between labels play an important role in designing structured classifiers with better performance. However, computational time complexity limits prevalent probabilistic methods from effectively supporting active learning. Specifically, while non-probabilistic methods based on structured support vector machines can be tractably applied to predicting bipartite matchings, conditional random fields are intractable for these structures. We propose an adversarial approach for active learning with structured prediction domains that is tractable for matching. We evaluate this approach algorithmically in an important structured prediction problems: object tracking in videos. We demonstrate better accuracy and computational efficiency for our proposed method.
Recovering Localized Adversarial Attacks
Oct 21, 2019
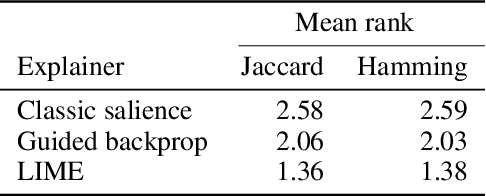

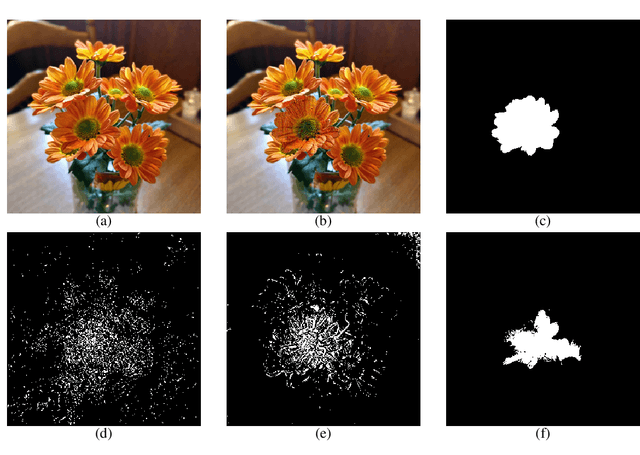
Deep convolutional neural networks have achieved great successes over recent years, particularly in the domain of computer vision. They are fast, convenient, and -- thanks to mature frameworks -- relatively easy to implement and deploy. However, their reasoning is hidden inside a black box, in spite of a number of proposed approaches that try to provide human-understandable explanations for the predictions of neural networks. It is still a matter of debate which of these explainers are best suited for which situations, and how to quantitatively evaluate and compare them. In this contribution, we focus on the capabilities of explainers for convolutional deep neural networks in an extreme situation: a setting in which humans and networks fundamentally disagree. Deep neural networks are susceptible to adversarial attacks that deliberately modify input samples to mislead a neural network's classification, without affecting how a human observer interprets the input. Our goal with this contribution is to evaluate explainers by investigating whether they can identify adversarially attacked regions of an image. In particular, we quantitatively and qualitatively investigate the capability of three popular explainers of classifications -- classic salience, guided backpropagation, and LIME -- with respect to their ability to identify regions of attack as the explanatory regions for the (incorrect) prediction in representative examples from image classification. We find that LIME outperforms the other explainers.
Multi-scale GANs for Memory-efficient Generation of High Resolution Medical Images
Jul 08, 2019
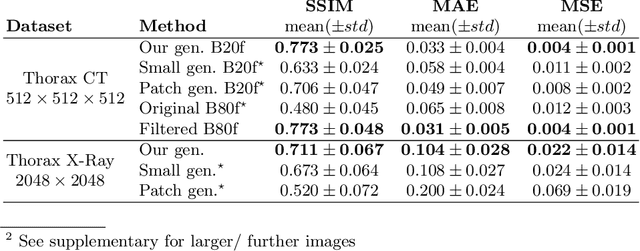
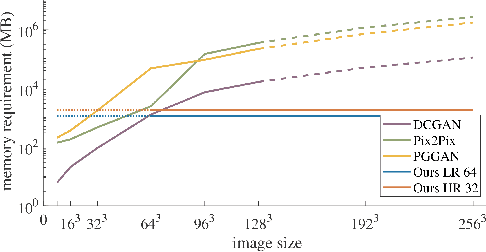
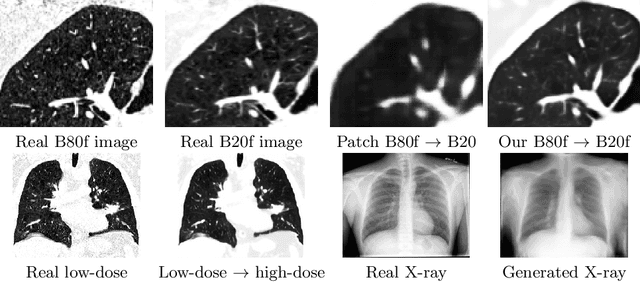
Currently generative adversarial networks (GANs) are rarely applied to medical images of large sizes, especially 3D volumes, due to their large computational demand. We propose a novel multi-scale patch-based GAN approach to generate large high resolution 2D and 3D images. Our key idea is to first learn a low-resolution version of the image and then generate patches of successively growing resolutions conditioned on previous scales. In a domain translation use-case scenario, 3D thorax CTs of size 512x512x512 and thorax X-rays of size 2048x2048 are generated and we show that, due to the constant GPU memory demand of our method, arbitrarily large images of high resolution can be generated. Moreover, compared to common patch-based approaches, our multi-resolution scheme enables better image quality and prevents patch artifacts.