 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Disp R-CNN: Stereo 3D Object Detection via Shape Prior Guided Instance Disparity Estimation
Apr 07, 2020
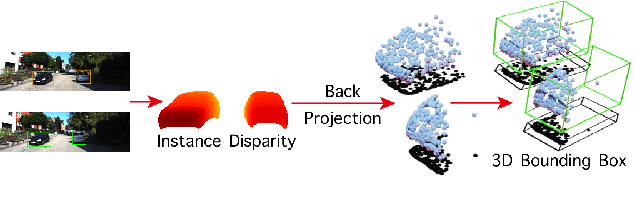
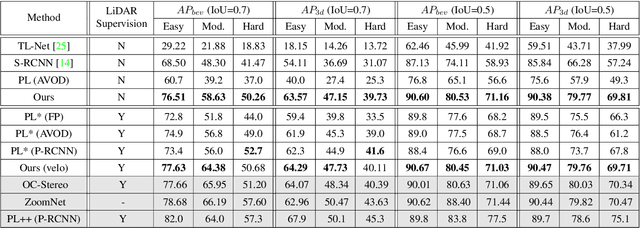
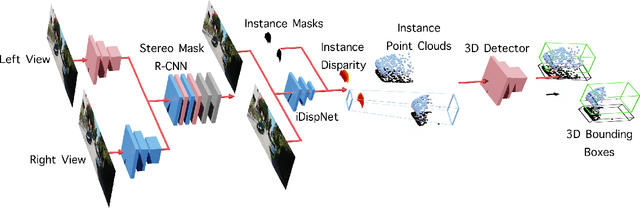
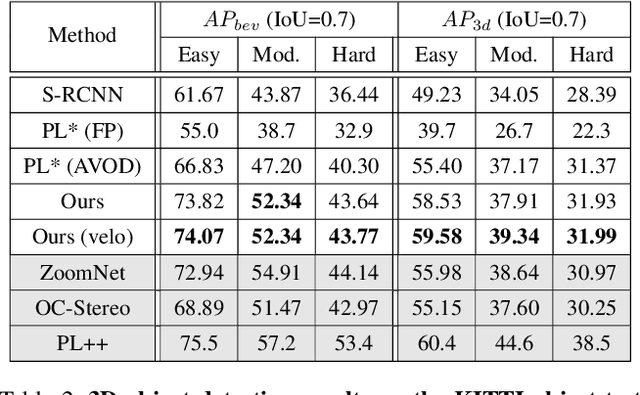
In this paper, we propose a novel system named Disp R-CNN for 3D object detection from stereo images. Many recent works solve this problem by first recovering a point cloud with disparity estimation and then apply a 3D detector. The disparity map is computed for the entire image, which is costly and fails to leverage category-specific prior. In contrast, we design an instance disparity estimation network (iDispNet) that predicts disparity only for pixels on objects of interest and learns a category-specific shape prior for more accurate disparity estimation. To address the challenge from scarcity of disparity annotation in training, we propose to use a statistical shape model to generate dense disparity pseudo-ground-truth without the need of LiDAR point clouds, which makes our system more widely applicable. Experiments on the KITTI dataset show that, even when LiDAR ground-truth is not available at training time, Disp R-CNN achieves competitive performance and outperforms previous state-of-the-art methods by 20% in terms of average precision.
Background Matting
Feb 11, 2020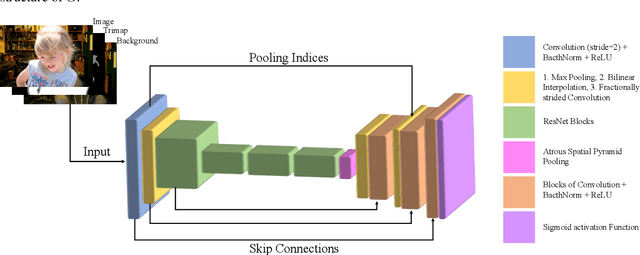
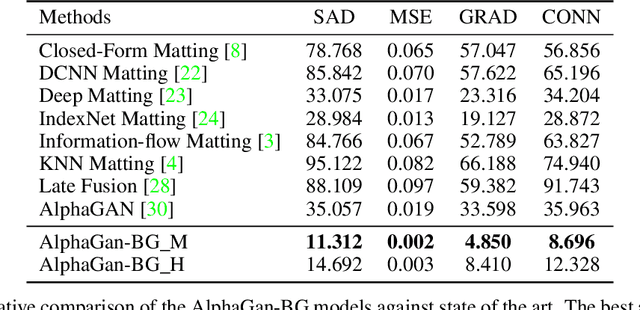


The current state of the art alpha matting methods mainly rely on the trimap as the secondary and only guidance to estimate alpha. This paper investigates the effects of utilising the background information as well as trimap in the process of alpha calculation. To achieve this goal, a state of the art method, AlphaGan is adopted and modified to process the background information as an extra input channel. Extensive experiments are performed to analyse the effect of the background information in image and video matting such as training with mildly and heavily distorted backgrounds. Based on the quantitative evaluations performed on Adobe Composition-1k dataset, the proposed pipeline significantly outperforms the state of the art methods using AlphaMatting benchmark metrics.
Image Labeling and Segmentation using Hierarchical Conditional Random Field Model
Jan 16, 2012The use of hierarchical Conditional Random Field model deal with the problem of labeling images . At the time of labeling a new image, selection of the nearest cluster and using the related CRF model to label this image. When one give input image, one first use the CRF model to get initial pixel labels then finding the cluster with most similar images. Then at last relabeling the input image by the CRF model associated with this cluster. This paper presents a approach to label and segment specific image having correct information.
Dense Crowds Detection and Surveillance with Drones using Density Maps
Mar 03, 2020



Detecting and Counting people in a human crowd from a moving drone present challenging problems that arisefrom the constant changing in the image perspective andcamera angle. In this paper, we test two different state-of-the-art approaches, density map generation with VGG19 trainedwith the Bayes loss function and detect-then-count with FasterRCNN with ResNet50-FPN as backbone, in order to comparetheir precision for counting and detecting people in differentreal scenarios taken from a drone flight. We show empiricallythat both proposed methodologies perform especially well fordetecting and counting people in sparse crowds when thedrone is near the ground. Nevertheless, VGG19 provides betterprecision on both tasks while also being lighter than FasterRCNN. Furthermore, VGG19 outperforms Faster RCNN whendealing with dense crowds, proving to be more robust toscale variations and strong occlusions, being more suitable forsurveillance applications using drones
Deep Bayesian Active Learning for Multiple Correct Outputs
Dec 08, 2019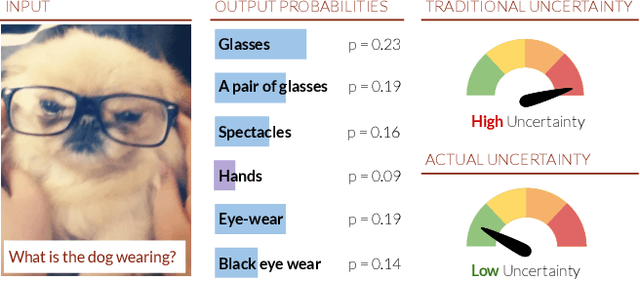
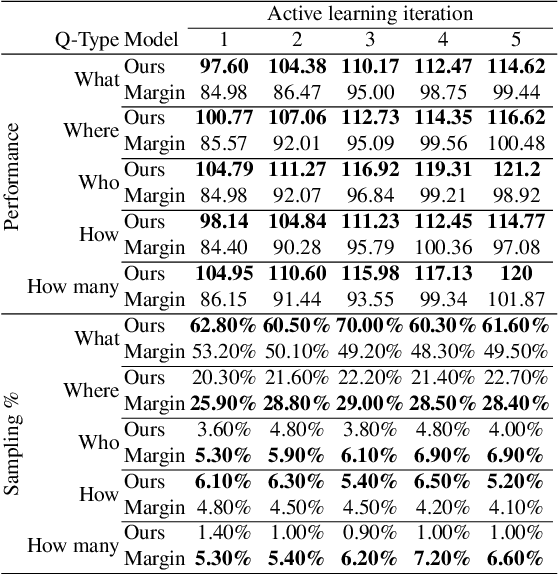
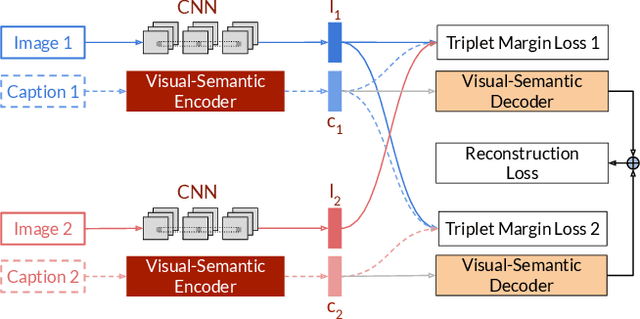
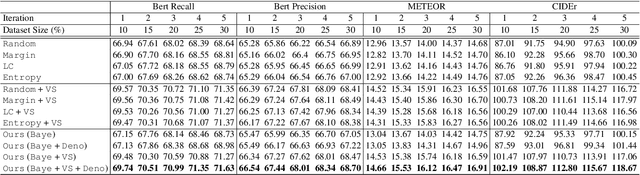
Typical active learning strategies are designed for tasks, such as classification, with the assumption that the output space is mutually exclusive. The assumption that these tasks always have exactly one correct answer has resulted in the creation of numerous uncertainty-based measurements, such as entropy and least confidence, which operate over a model's outputs. Unfortunately, many real-world vision tasks, like visual question answering and image captioning, have multiple correct answers, causing these measurements to overestimate uncertainty and sometimes perform worse than a random sampling baseline. In this paper, we propose a new paradigm that estimates uncertainty in the model's internal hidden space instead of the model's output space. We specifically study a manifestation of this problem for visual question answer generation (VQA), where the aim is not to classify the correct answer but to produce a natural language answer, given an image and a question. Our method overcomes the paraphrastic nature of language. It requires a semantic space that structures the model's output concepts and that enables the usage of techniques like dropout-based Bayesian uncertainty. We build a visual-semantic space that embeds paraphrases close together for any existing VQA model. We empirically show state-of-art active learning results on the task of VQA on two datasets, being 5 times more cost-efficient on Visual Genome and 3 times more cost-efficient on VQA 2.0.
From text saliency to linguistic objects: learning linguistic interpretable markers with a multi-channels convolutional architecture
Apr 07, 2020
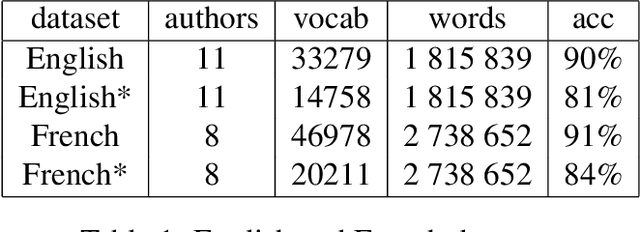
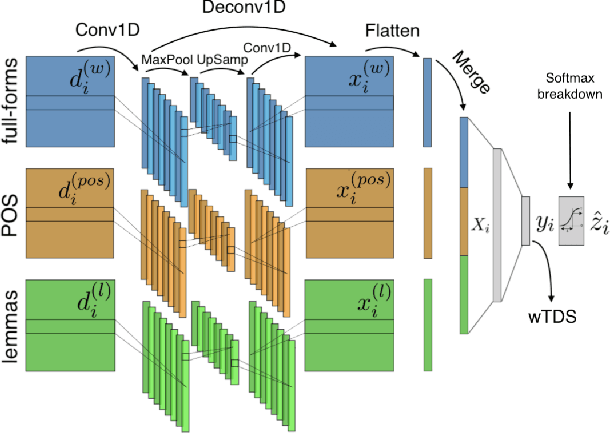
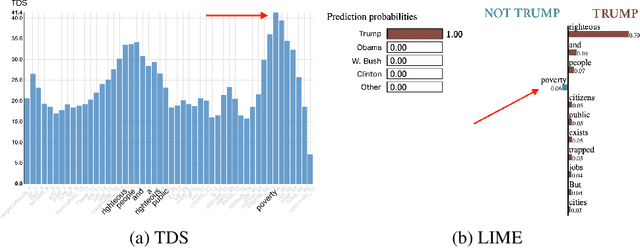
A lot of effort is currently made to provide methods to analyze and understand deep neural network impressive performances for tasks such as image or text classification. These methods are mainly based on visualizing the important input features taken into account by the network to build a decision. However these techniques, let us cite LIME, SHAP, Grad-CAM, or TDS, require extra effort to interpret the visualization with respect to expert knowledge. In this paper, we propose a novel approach to inspect the hidden layers of a fitted CNN in order to extract interpretable linguistic objects from texts exploiting classification process. In particular, we detail a weighted extension of the Text Deconvolution Saliency (wTDS) measure which can be used to highlight the relevant features used by the CNN to perform the classification task. We empirically demonstrate the efficiency of our approach on corpora from two different languages: English and French. On all datasets, wTDS automatically encodes complex linguistic objects based on co-occurrences and possibly on grammatical and syntax analysis.
DyNet: Dynamic Convolution for Accelerating Convolutional Neural Networks
Apr 22, 2020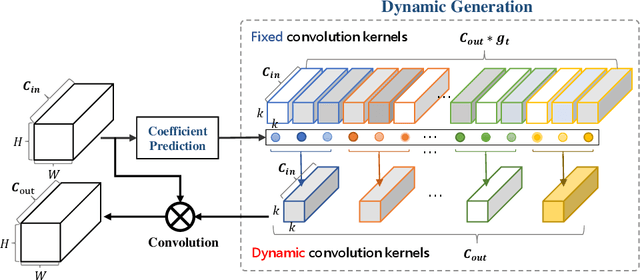
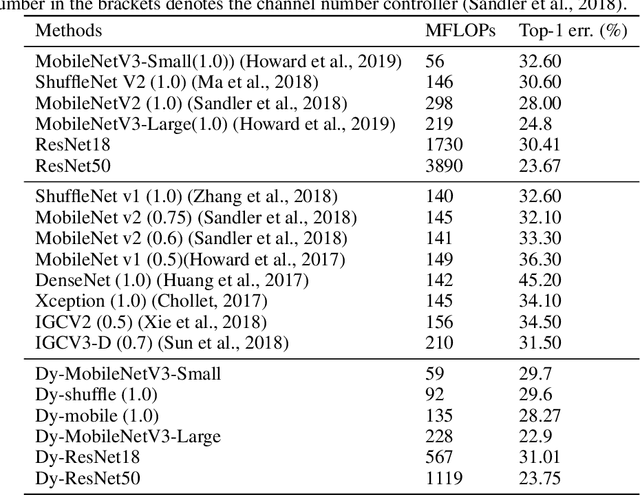
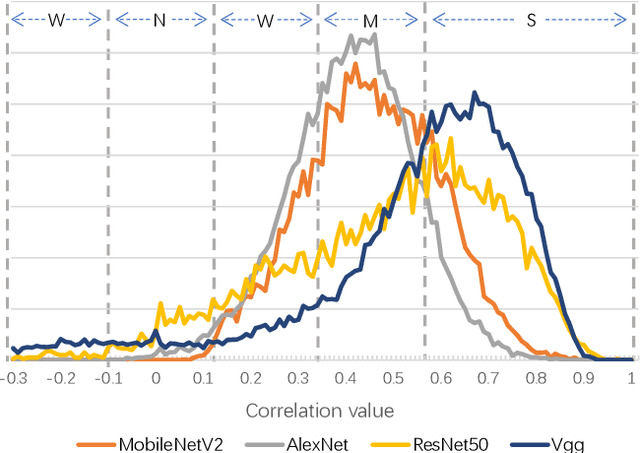
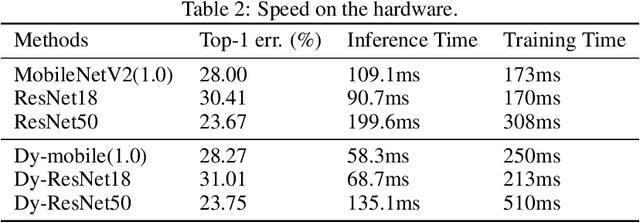
Convolution operator is the core of convolutional neural networks (CNNs) and occupies the most computation cost. To make CNNs more efficient, many methods have been proposed to either design lightweight networks or compress models. Although some efficient network structures have been proposed, such as MobileNet or ShuffleNet, we find that there still exists redundant information between convolution kernels. To address this issue, we propose a novel dynamic convolution method to adaptively generate convolution kernels based on image contents. To demonstrate the effectiveness, we apply dynamic convolution on multiple state-of-the-art CNNs. On one hand, we can reduce the computation cost remarkably while maintaining the performance. For ShuffleNetV2/MobileNetV2/ResNet18/ResNet50, DyNet can reduce 37.0/54.7/67.2/71.3% FLOPs without loss of accuracy. On the other hand, the performance can be largely boosted if the computation cost is maintained. Based on the architecture MobileNetV3-Small/Large, DyNet achieves 70.3/77.1% Top-1 accuracy on ImageNet with an improvement of 2.9/1.9%. To verify the scalability, we also apply DyNet on segmentation task, the results show that DyNet can reduce 69.3% FLOPs while maintaining Mean IoU on segmentation task.
End-to-End Lane Marker Detection via Row-wise Classification
May 06, 2020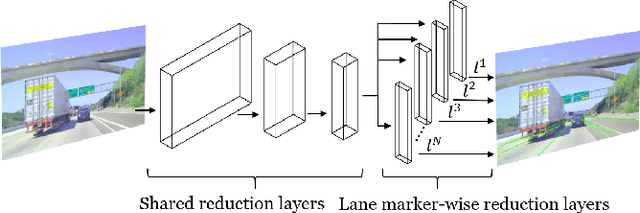
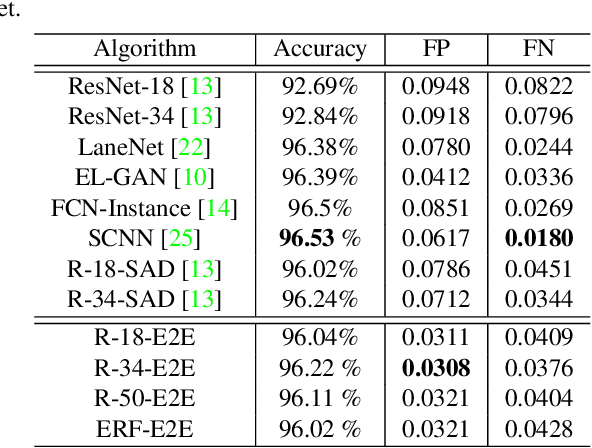
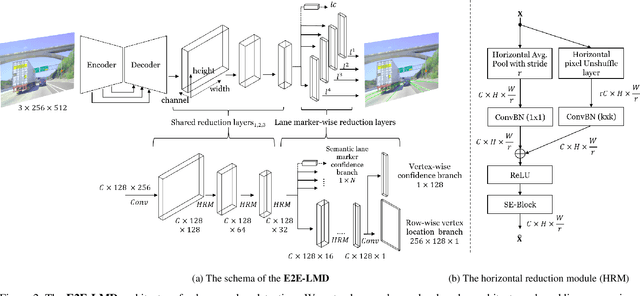
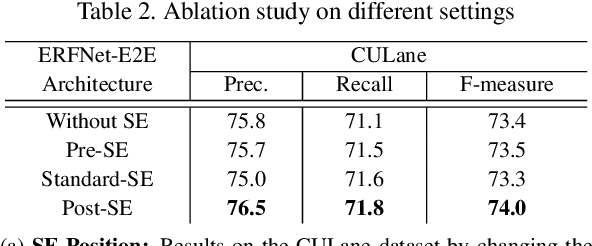
In autonomous driving, detecting reliable and accurate lane marker positions is a crucial yet challenging task. The conventional approaches for the lane marker detection problem perform a pixel-level dense prediction task followed by sophisticated post-processing that is inevitable since lane markers are typically represented by a collection of line segments without thickness. In this paper, we propose a method performing direct lane marker vertex prediction in an end-to-end manner, i.e., without any post-processing step that is required in the pixel-level dense prediction task. Specifically, we translate the lane marker detection problem into a row-wise classification task, which takes advantage of the innate shape of lane markers but, surprisingly, has not been explored well. In order to compactly extract sufficient information about lane markers which spread from the left to the right in an image, we devise a novel layer, which is utilized to successively compress horizontal components so enables an end-to-end lane marker detection system where the final lane marker positions are simply obtained via argmax operations in testing time. Experimental results demonstrate the effectiveness of the proposed method, which is on par or outperforms the state-of-the-art methods on two popular lane marker detection benchmarks, i.e., TuSimple and CULane.
Plug-and-play ISTA converges with kernel denoisers
Apr 07, 2020
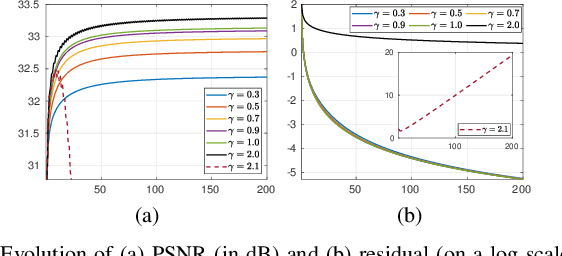
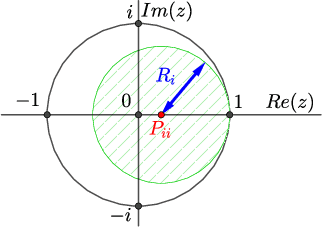
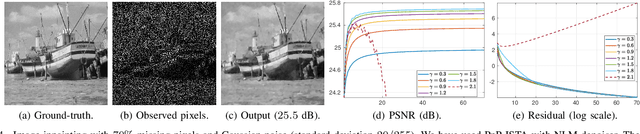
Plug-and-play (PnP) method is a recent paradigm for image regularization, where the proximal operator (associated with some given regularizer) in an iterative algorithm is replaced with a powerful denoiser. Algorithmically, this involves repeated inversion (of the forward model) and denoising until convergence. Remarkably, PnP regularization produces promising results for several restoration applications. However, a fundamental question in this regard is the theoretical convergence of the PnP iterations, since the algorithm is not strictly derived from an optimization framework. This question has been investigated in recent works, but there are still many unresolved problems. For example, it is not known if convergence can be guaranteed if we use generic kernel denoisers (e.g. nonlocal means) within the ISTA framework (PnP-ISTA). We prove that, under reasonable assumptions, fixed-point convergence of PnP-ISTA is indeed guaranteed for linear inverse problems such as deblurring, inpainting and superresolution (the assumptions are verifiable for inpainting). We compare our theoretical findings with existing results, validate them numerically, and explain their practical relevance.
Image Resolution and Contrast Enhancement of Satellite Geographical Images with Removal of Noise using Wavelet Transforms
May 08, 2014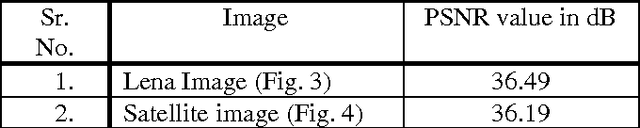
In this paper the technique for resolution and contrast enhancement of satellite geographical images based on discrete wavelet transform (DWT), stationary wavelet transform (SWT) and singular value decomposition (SVD) has been proposed. In this, the noise is added in the input low resolution and low contrast image. The median filter is used remove noise from the input image. This low resolution, low contrast image without noise is decomposed into four sub-bands by using DWT and SWT. The resolution enhancement technique is based on the interpolation of high frequency components obtained by DWT and input image. SWT is used to enhance input image. DWT is used to decompose an image into four frequency sub bands and these four sub-bands are interpolated using bicubic interpolation technique. All these sub-bands are reconstructed as high resolution image by using inverse DWT (IDWT). To increase the contrast the proposed technique uses DWT and SVD. GHE is used to equalize an image. The equalized image is decomposed into four sub-bands using DWT and new LL sub-band is reconstructed using SVD. All sub-bands are reconstructed using IDWT to generate high resolution and contrast image over conventional techniques. The experimental result shows superiority of the proposed technique over conventional techniques. Key words: Discrete wavelet transform (DWT), General histogram equalization (GHE), Median filter, Singular value decomposition (SVD), Stationary wavelet transform (SWT).
* 5 pages, 10 figures