 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
KeystoneDepth: Visualizing History in 3D
Aug 21, 2019



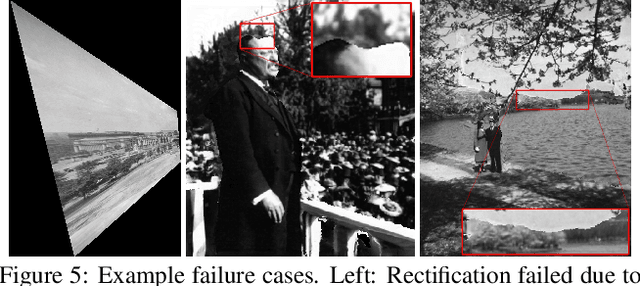
This paper introduces the largest and most diverse collection of rectified stereo image pairs to the research community, KeystoneDepth, consisting of tens of thousands of stereographs of historical people, events, objects, and scenes between 1860 and 1963. Leveraging the Keystone-Mast raw scans from the California Museum of Photography, we apply multiple processing steps to produce clean stereo image pairs, complete with calibration data, rectification transforms, and depthmaps. A second contribution is a novel approach for view synthesis that runs at real-time rates on a mobile device, simulating the experience of looking through an open window into these historical scenes. We produce results for thousands of antique stereographs, capturing many important historical moments.
ERNet Family: Hardware-Oriented CNN Models for Computational Imaging Using Block-Based Inference
Oct 13, 2019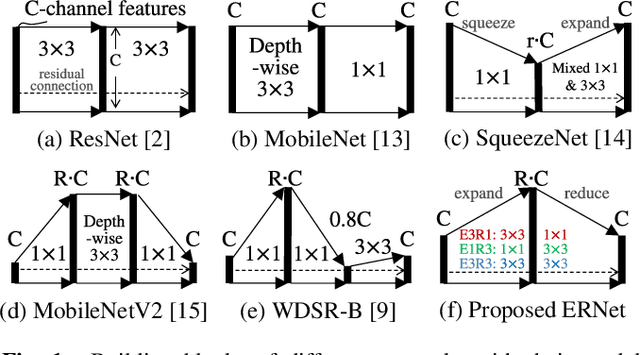
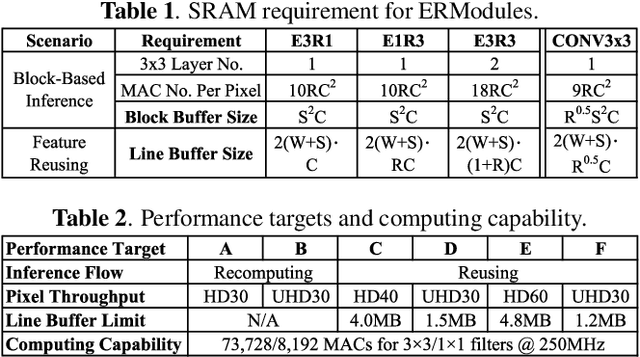
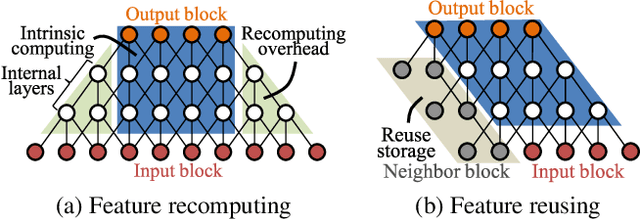
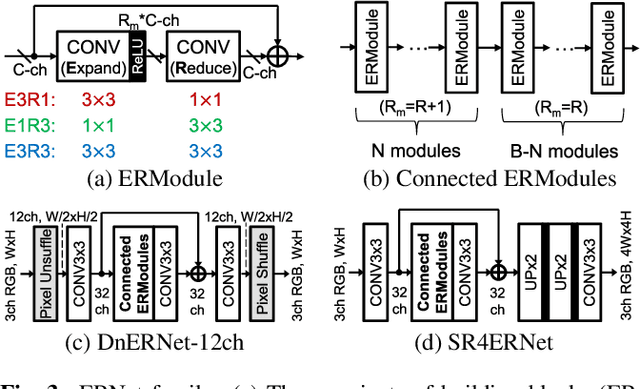
Convolutional neural networks (CNNs) demand huge DRAM bandwidth for computational imaging tasks, and block-based processing has recently been applied to greatly reduce the bandwidth. However, the induced additional computation for feature recomputing or the large SRAM for feature reusing will degrade the performance or even forbid the usage of state-of-the-art models. In this paper, we address these issues by considering the overheads and hardware constraints in advance when constructing CNNs. We investigate a novel model family---ERNet---which includes temporary layer expansion as another means for increasing model capacity. We analyze three ERNet variants in terms of hardware requirement and introduce a hardware-aware model optimization procedure. Evaluations on Full HD and 4K UHD applications will be given to show the effectiveness in terms of image quality, pixel throughput, and SRAM usage. The results also show that, for block-based inference, ERNet can outperform the state-of-the-art FFDNet and EDSR-baseline models for image denoising and super-resolution respectively.
Fetal Ultrasound Image Segmentation for Measuring Biometric Parameters Using Multi-Task Deep Learning
Aug 31, 2019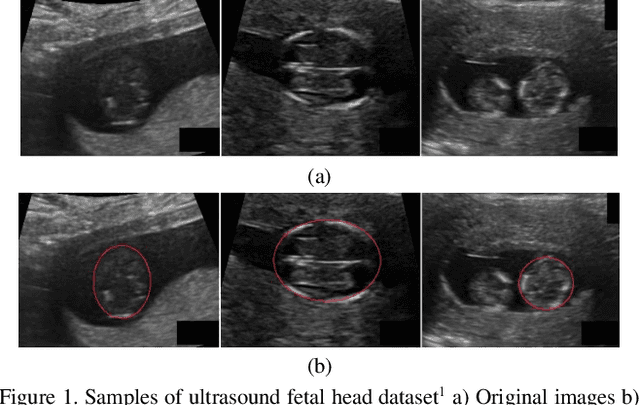
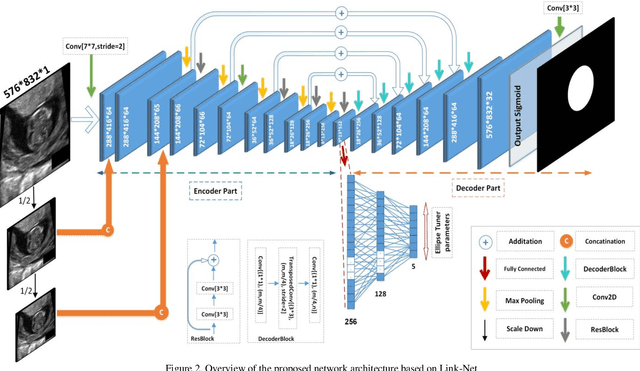
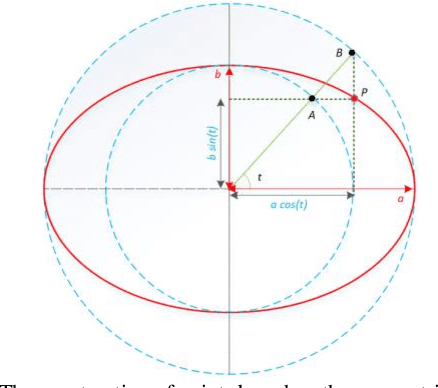

Ultrasound imaging is a standard examination during pregnancy that can be used for measuring specific biometric parameters towards prenatal diagnosis and estimating gestational age. Fetal head circumference (HC) is one of the significant factors to determine the fetus growth and health. In this paper, a multi-task deep convolutional neural network is proposed for automatic segmentation and estimation of HC ellipse by minimizing a compound cost function composed of segmentation dice score and MSE of ellipse parameters. Experimental results on fetus ultrasound dataset in different trimesters of pregnancy show that the segmentation results and the extracted HC match well with the radiologist annotations. The obtained dice scores of the fetal head segmentation and the accuracy of HC evaluations are comparable to the state-of-the-art.
Robust binary classification with the 01 loss
Feb 09, 2020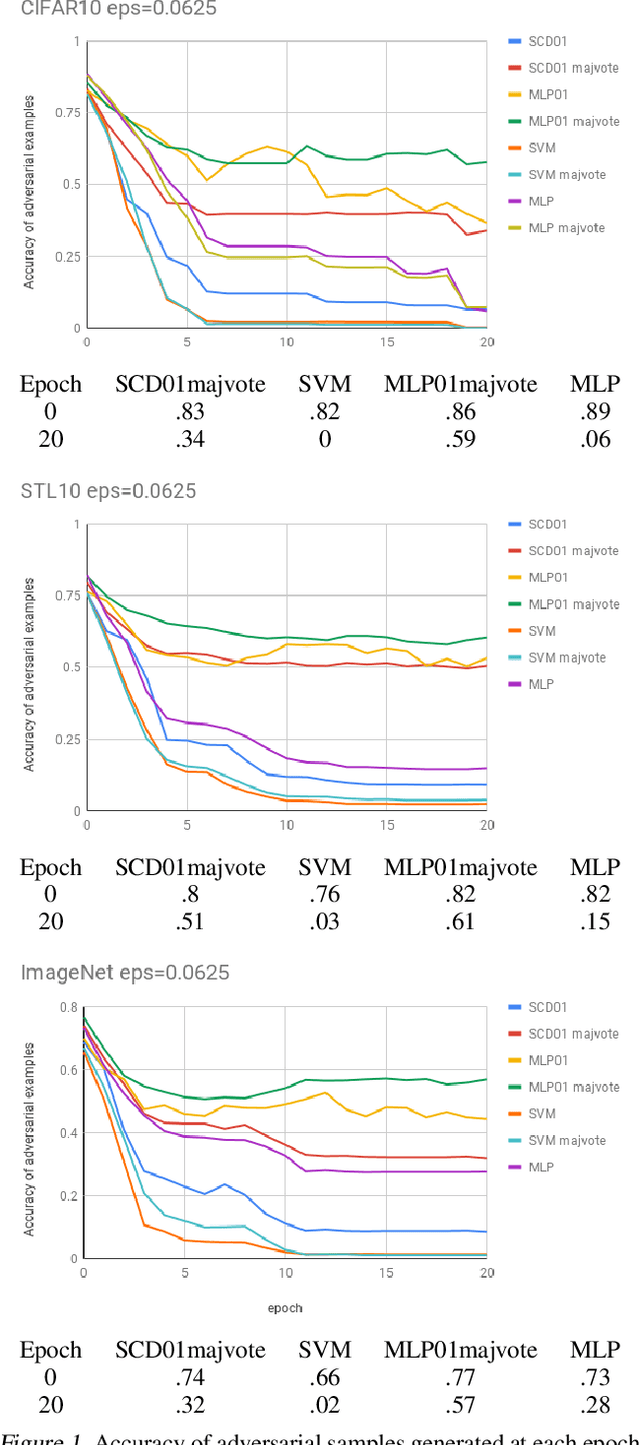
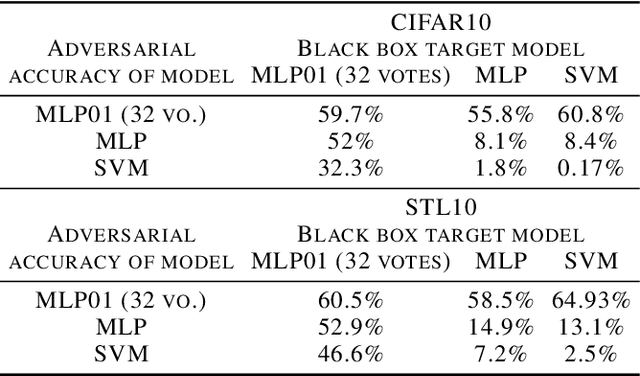

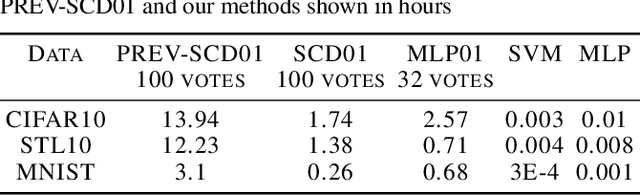
The 01 loss is robust to outliers and tolerant to noisy data compared to convex loss functions. We conjecture that the 01 loss may also be more robust to adversarial attacks. To study this empirically we have developed a stochastic coordinate descent algorithm for a linear 01 loss classifier and a single hidden layer 01 loss neural network. Due to the absence of the gradient we iteratively update coordinates on random subsets of the data for fixed epochs. We show our algorithms to be fast and comparable in accuracy to the linear support vector machine and logistic loss single hidden layer network for binary classification on several image benchmarks, thus establishing that our method is on-par in test accuracy with convex losses. We then subject them to accurately trained substitute model black box attacks on the same image benchmarks and find them to be more robust than convex counterparts. On CIFAR10 binary classification task between classes 0 and 1 with adversarial perturbation of 0.0625 we see that the MLP01 network loses 27\% in accuracy whereas the MLP-logistic counterpart loses 83\%. Similarly on STL10 and ImageNet binary classification between classes 0 and 1 the MLP01 network loses 21\% and 20\% while MLP-logistic loses 67\% and 45\% respectively. On MNIST that is a well-separable dataset we find MLP01 comparable to MLP-logistic and show under simulation how and why our 01 loss solver is less robust there. We then propose adversarial training for our linear 01 loss solver that significantly improves its robustness on MNIST and all other datasets and retains clean test accuracy. Finally we show practical applications of our method to deter traffic sign and facial recognition adversarial attacks. We discuss attacks with 01 loss, substitute model accuracy, and several future avenues like multiclass, 01 loss convolutions, and further adversarial training.
Inverse Graphics: Unsupervised Learning of 3D Shapes from Single Images
Oct 31, 2019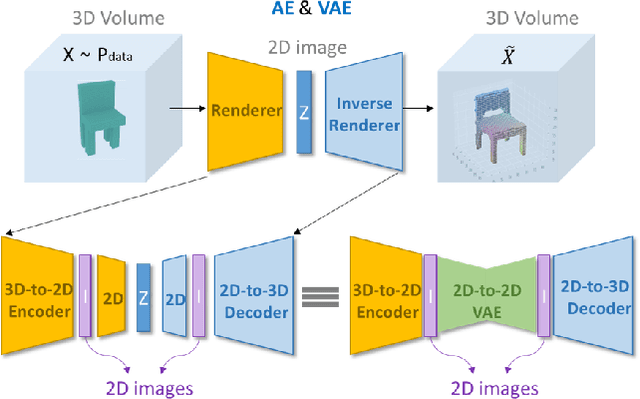

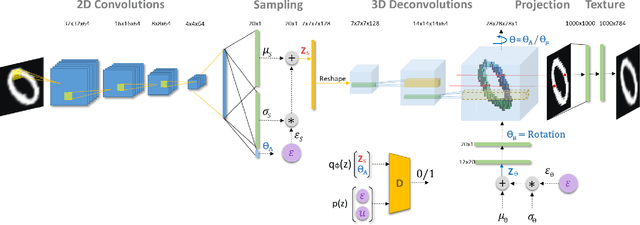
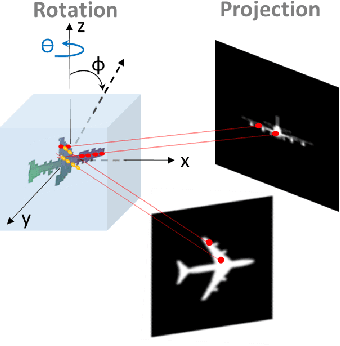
Using generative models for Inverse Graphics is an active area of research. However, most works focus on developing models for supervised and semi-supervised methods. In this paper, we study the problem of unsupervised learning of 3D geometry from single images. Our approach is to use a generative model that produces 2-D images as projections of a latent 3D voxel grid, which we train either as a variational auto-encoder or using adversarial methods. Our contributions are as follows: First, we show how to recover 3D shape and pose from general datasets such as MNIST, and MNIST Fashion in good quality. Second, we compare the shapes learned using adversarial and variational methods. Adversarial approach gives denser 3D shapes. Third, we explore the idea of modelling the pose of an object as uniform distribution to recover 3D shape from a single image. Our experiment with the CelebA dataset \cite{liu2015faceattributes} proves that we can recover complete 3D shape from a single image when the object is symmetric along one, or more axis whilst results obtained using ModelNet40 \cite{wu20153d} show the potential side-effects, in which the model learns 3D shapes such that it can render the same image from any viewpoint. Forth, we present a general end-to-end approach to learning 3D shapes from single images in a completely unsupervised fashion by modelling the factors of variation such as azimuth as independent latent variables. Our method makes no assumptions about the dataset, and can work with synthetic as well as real images (i.e. unsupervised in true sense). We present our results, by training the model using the $\mu$-VAE objective \cite{ucar2019bridging} and a dataset combining all images from MNIST, MNIST Fashion, CelebA and six categories of ModelNet40. The model is able to learn 3D shapes and the pose in qood quality and leverages information learned across all datasets.
What Information Does a ResNet Compress?
Mar 13, 2020
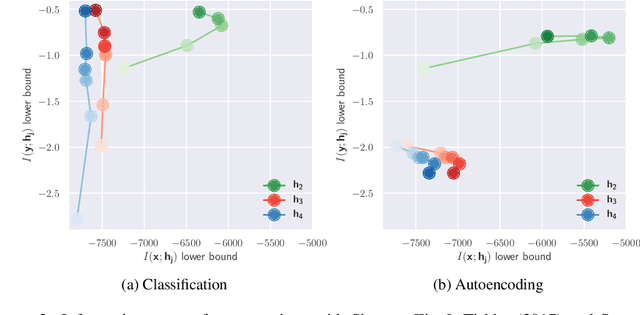
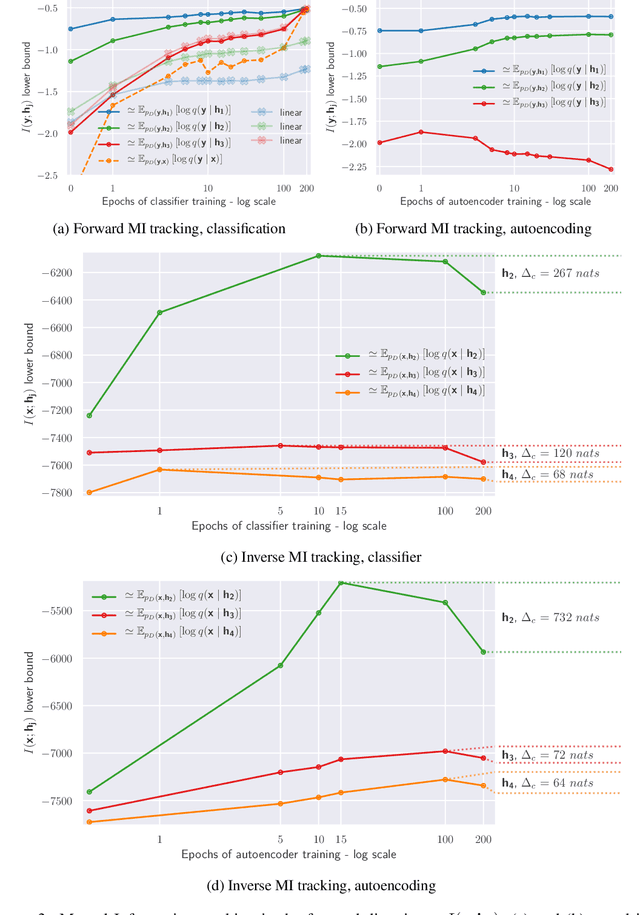
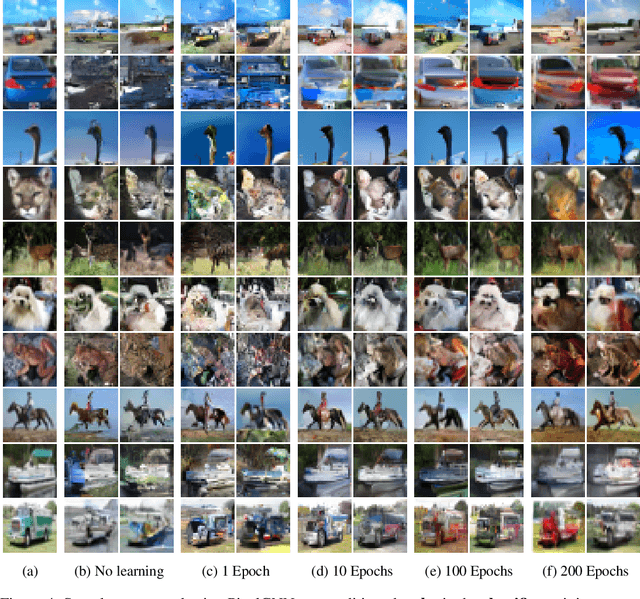
The information bottleneck principle (Shwartz-Ziv & Tishby, 2017) suggests that SGD-based training of deep neural networks results in optimally compressed hidden layers, from an information theoretic perspective. However, this claim was established on toy data. The goal of the work we present here is to test whether the information bottleneck principle is applicable to a realistic setting using a larger and deeper convolutional architecture, a ResNet model. We trained PixelCNN++ models as inverse representation decoders to measure the mutual information between hidden layers of a ResNet and input image data, when trained for (1) classification and (2) autoencoding. We find that two stages of learning happen for both training regimes, and that compression does occur, even for an autoencoder. Sampling images by conditioning on hidden layers' activations offers an intuitive visualisation to understand what a ResNets learns to forget.
StyleRig: Rigging StyleGAN for 3D Control over Portrait Images
Mar 31, 2020
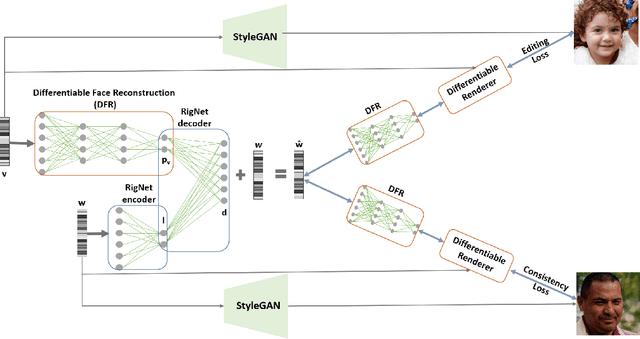
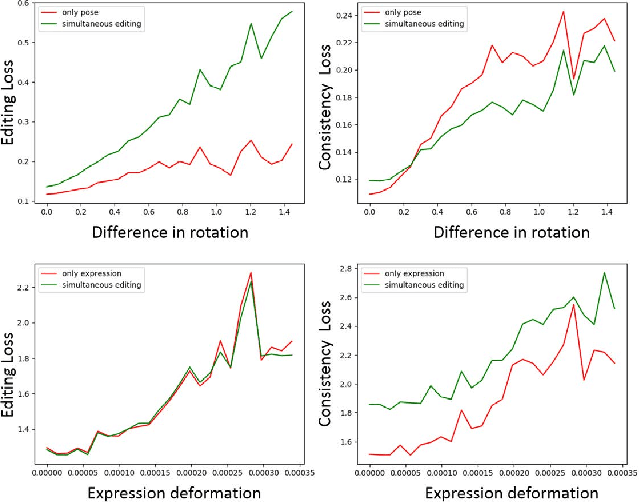

StyleGAN generates photorealistic portrait images of faces with eyes, teeth, hair and context (neck, shoulders, background), but lacks a rig-like control over semantic face parameters that are interpretable in 3D, such as face pose, expressions, and scene illumination. Three-dimensional morphable face models (3DMMs) on the other hand offer control over the semantic parameters, but lack photorealism when rendered and only model the face interior, not other parts of a portrait image (hair, mouth interior, background). We present the first method to provide a face rig-like control over a pretrained and fixed StyleGAN via a 3DMM. A new rigging network, RigNet is trained between the 3DMM's semantic parameters and StyleGAN's input. The network is trained in a self-supervised manner, without the need for manual annotations. At test time, our method generates portrait images with the photorealism of StyleGAN and provides explicit control over the 3D semantic parameters of the face.
Training with Quantization Noise for Extreme Model Compression
Apr 17, 2020
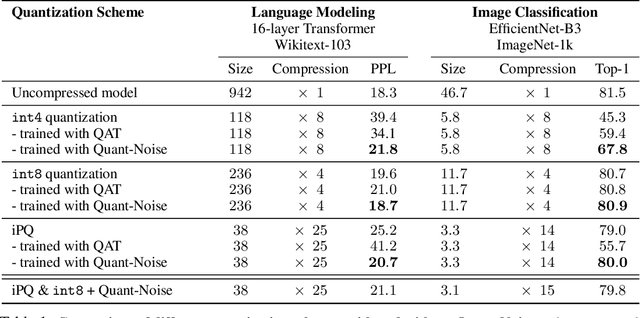
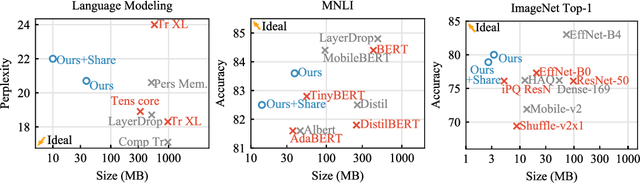
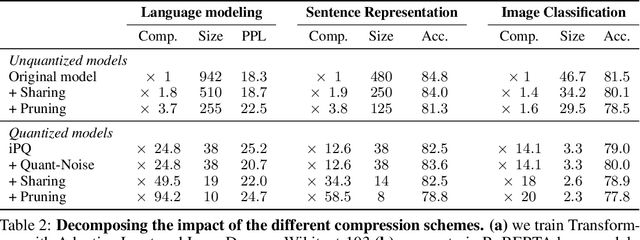
We tackle the problem of producing compact models, maximizing their accuracy for a given model size. A standard solution is to train networks with Quantization Aware Training, where the weights are quantized during training and the gradients approximated with the Straight-Through Estimator. In this paper, we extend this approach to work beyond int8 fixed-point quantization with extreme compression methods where the approximations introduced by STE are severe, such as Product Quantization. Our proposal is to only quantize a different random subset of weights during each forward, allowing for unbiased gradients to flow through the other weights. Controlling the amount of noise and its form allows for extreme compression rates while maintaining the performance of the original model. As a result we establish new state-of-the-art compromises between accuracy and model size both in natural language processing and image classification. For example, applying our method to state-of-the-art Transformer and ConvNet architectures, we can achieve 82.5% accuracy on MNLI by compressing RoBERTa to 14MB and 80.0 top-1 accuracy on ImageNet by compressing an EfficientNet-B3 to 3.3MB.
Towards Deep Learning Methods for Quality Assessment of Computer-Generated Imagery
May 02, 2020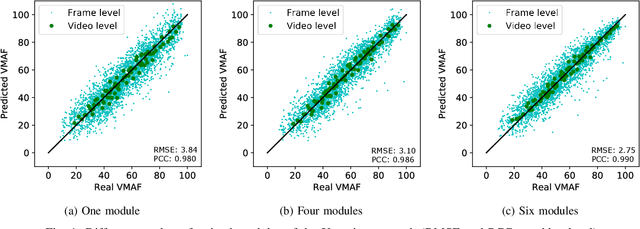
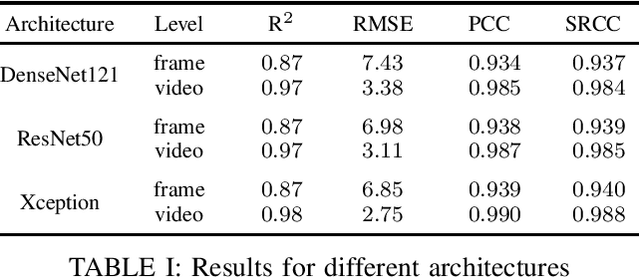
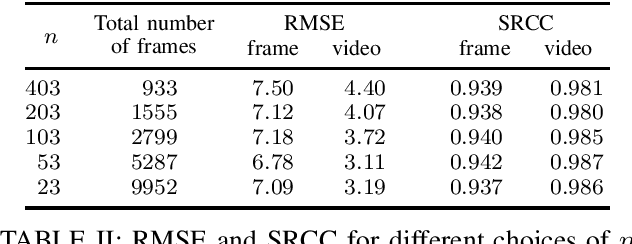
Video gaming streaming services are growing rapidly due to new services such as passive video streaming, e.g. Twitch.tv, and cloud gaming, e.g. Nvidia Geforce Now. In contrast to traditional video content, gaming content has special characteristics such as extremely high motion for some games, special motion patterns, synthetic content and repetitive content, which makes the state-of-the-art video and image quality metrics perform weaker for this special computer generated content. In this paper, we outline our plan to build a deep learningbased quality metric for video gaming quality assessment. In addition, we present initial results by training the network based on VMAF values as a ground truth to give some insights on how to build a metric in future. The paper describes the method that is used to choose an appropriate Convolutional Neural Network architecture. Furthermore, we estimate the size of the required subjective quality dataset which achieves a sufficiently high performance. The results show that by taking around 5k images for training of the last six modules of Xception, we can obtain a relatively high performance metric to assess the quality of distorted video games.
Near real-time map building with multi-class image set labelling and classification of road conditions using convolutional neural networks
Jan 27, 2020
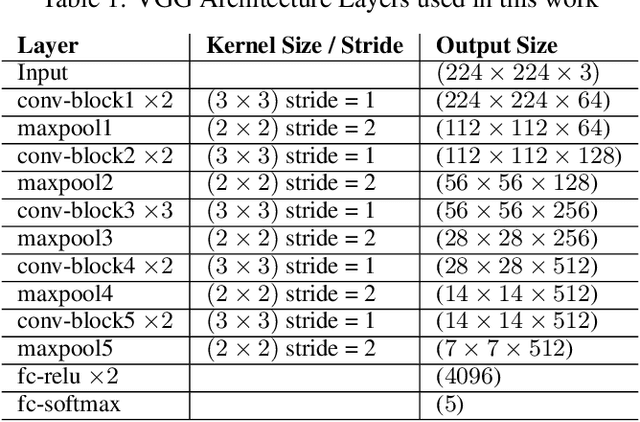
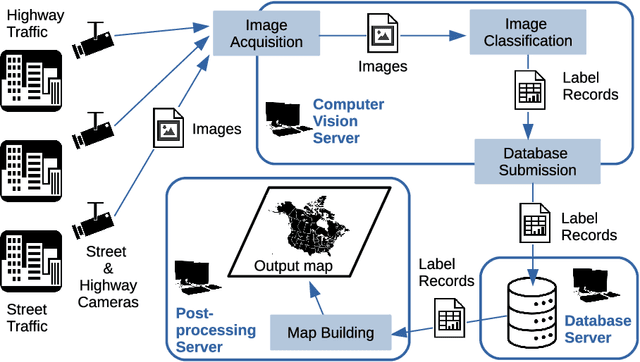
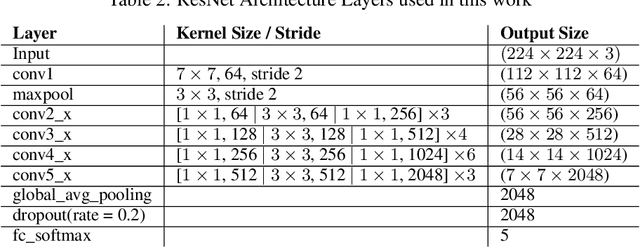
Weather is an important factor affecting transportation and road safety. In this paper, we leverage state-of-the-art convolutional neural networks in labelling images taken by street and highway cameras located across across North America. Road camera snapshots were used in experiments with multiple deep learning frameworks to classify images by road condition. The training data for these experiments used images labelled as dry, wet, snow/ice, poor, and offline. The experiments tested different configurations of six convolutional neural networks (VGG-16, ResNet50, Xception, InceptionResNetV2, EfficientNet-B0 and EfficientNet-B4) to assess their suitability to this problem. The precision, accuracy, and recall were measured for each framework configuration. In addition, the training sets were varied both in overall size and by size of individual classes. The final training set included 47,000 images labelled using the five aforementioned classes. The EfficientNet-B4 framework was found to be most suitable to this problem, achieving validation accuracy of 90.6%, although EfficientNet-B0 achieved an accuracy of 90.3% with half the execution time. It was observed that VGG-16 with transfer learning proved to be very useful for data acquisition and pseudo-labelling with limited hardware resources, throughout this project. The EfficientNet-B4 framework was then placed into a real-time production environment, where images could be classified in real-time on an ongoing basis. The classified images were then used to construct a map showing real-time road conditions at various camera locations across North America. The choice of these frameworks and our analysis take into account unique requirements of real-time map building functions. A detailed analysis of the process of semi-automated dataset labelling using these frameworks is also presented in this paper.