 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDHOG: Deep Hierarchical Object Grouping
Mar 13, 2020Recently, a number of competitive methods have tackled unsupervised representation learning by maximising the mutual information between the representations produced from augmentations. The resulting representations are then invariant to stochastic augmentation strategies, and can be used for downstream tasks such as clustering or classification. Yet data augmentations preserve many properties of an image and so there is potential for a suboptimal choice of representation that relies on matching easy-to-find features in the data. We demonstrate that greedy or local methods of maximising mutual information (such as stochastic gradient optimisation) discover local optima of the mutual information criterion; the resulting representations are also less-ideally suited to complex downstream tasks. Earlier work has not specifically identified or addressed this issue. We introduce deep hierarchical object grouping (DHOG) that computes a number of distinct discrete representations of images in a hierarchical order, eventually generating representations that better optimise the mutual information objective. We also find that these representations align better with the downstream task of grouping into underlying object classes. We tested DHOG on unsupervised clustering, which is a natural downstream test as the target representation is a discrete labelling of the data. We achieved new state-of-the-art results on the three main benchmarks without any prefiltering or Sobel-edge detection that proved necessary for many previous methods to work. We obtain accuracy improvements of: 4.3% on CIFAR-10, 1.5% on CIFAR-100-20, and 7.2% on SVHN.
What Information Does a ResNet Compress?
Mar 13, 2020
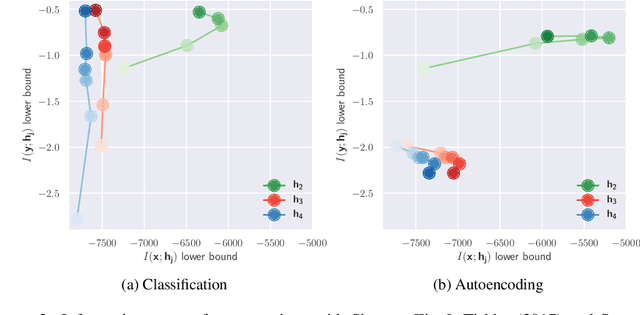
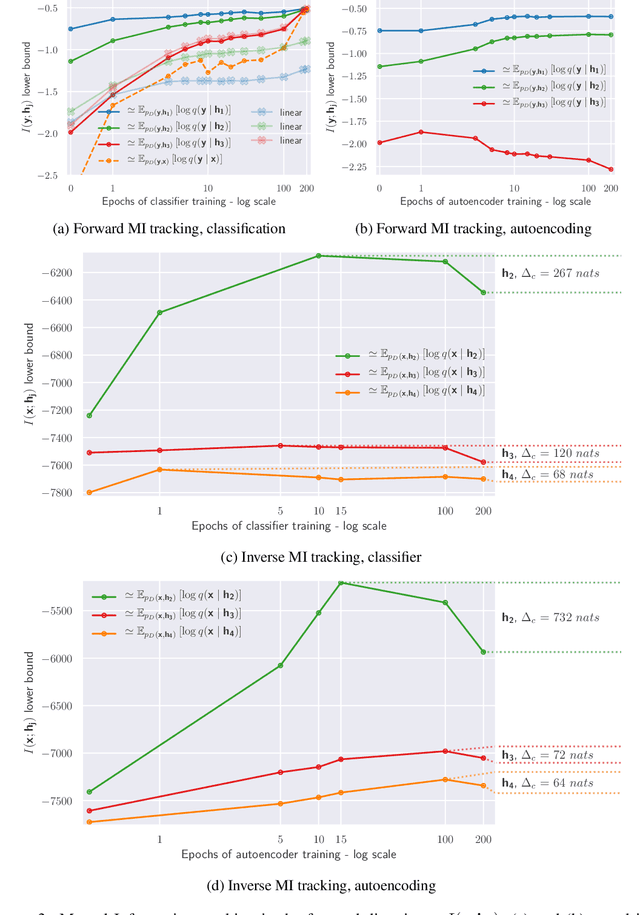
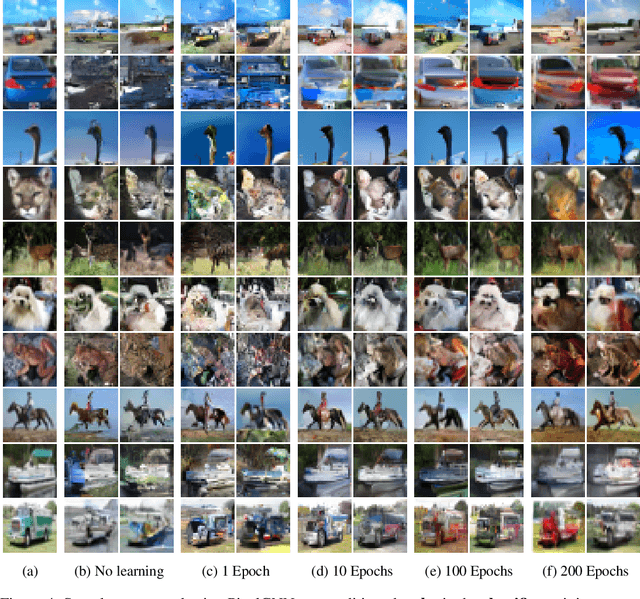
The information bottleneck principle (Shwartz-Ziv & Tishby, 2017) suggests that SGD-based training of deep neural networks results in optimally compressed hidden layers, from an information theoretic perspective. However, this claim was established on toy data. The goal of the work we present here is to test whether the information bottleneck principle is applicable to a realistic setting using a larger and deeper convolutional architecture, a ResNet model. We trained PixelCNN++ models as inverse representation decoders to measure the mutual information between hidden layers of a ResNet and input image data, when trained for (1) classification and (2) autoencoding. We find that two stages of learning happen for both training regimes, and that compression does occur, even for an autoencoder. Sampling images by conditioning on hidden layers' activations offers an intuitive visualisation to understand what a ResNets learns to forget.