 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generating Memorable Images Based on Human Visual Memory Schemas
May 06, 2020

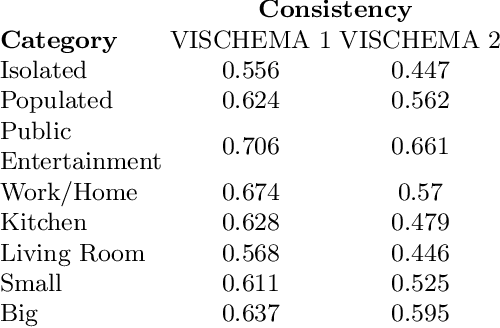
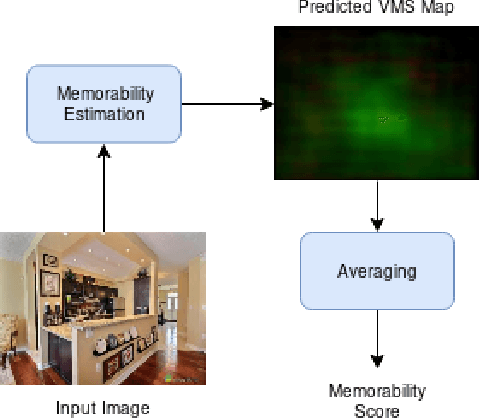
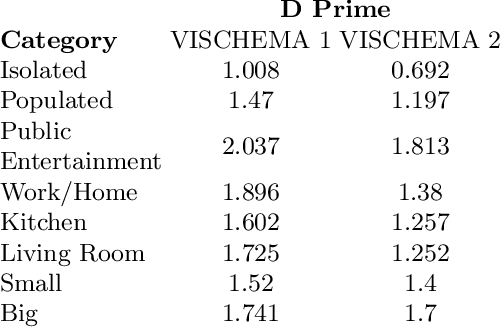
This research study proposes using Generative Adversarial Networks (GAN) that incorporate a two-dimensional measure of human memorability to generate memorable or non-memorable images of scenes. The memorability of the generated images is evaluated by modelling Visual Memory Schemas (VMS), which correspond to mental representations that human observers use to encode an image into memory. The VMS model is based upon the results of memory experiments conducted on human observers, and provides a 2D map of memorability. We impose a memorability constraint upon the latent space of a GAN by employing a VMS map prediction model as an auxiliary loss. We assess the difference in memorability between images generated to be memorable or non-memorable through an independent computational measure of memorability, and additionally assess the effect of memorability on the realness of the generated images.
Knowing Depth Quality In Advance: A Depth Quality Assessment Method For RGB-D Salient Object Detection
Aug 07, 2020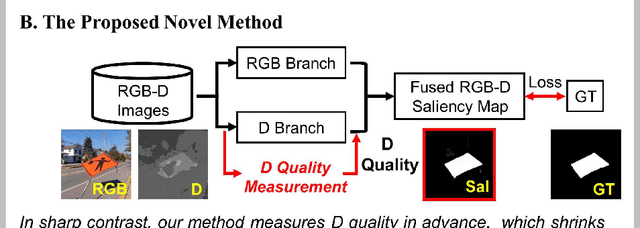
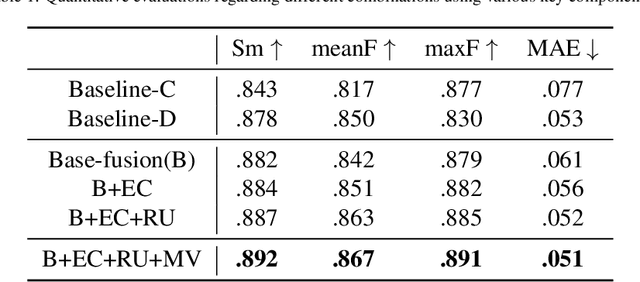
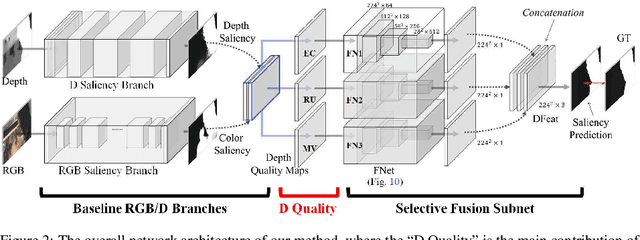
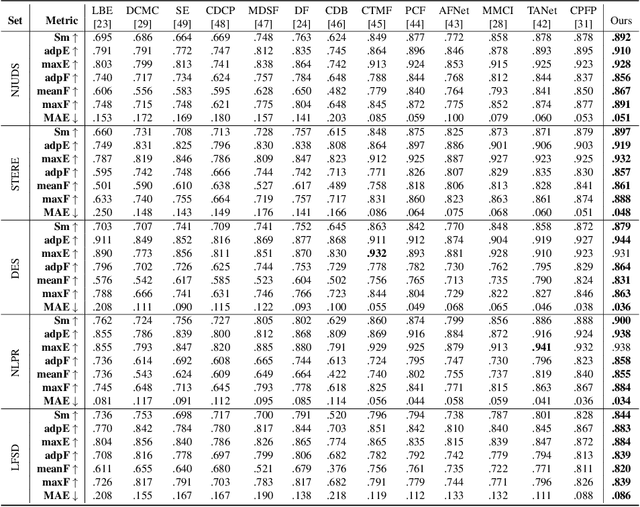
Previous RGB-D salient object detection (SOD) methods have widely adopted deep learning tools to automatically strike a trade-off between RGB and D (depth), whose key rationale is to take full advantage of their complementary nature, aiming for a much-improved SOD performance than that of using either of them solely. However, such fully automatic fusions may not always be helpful for the SOD task because the D quality itself usually varies from scene to scene. It may easily lead to a suboptimal fusion result if the D quality is not considered beforehand. Moreover, as an objective factor, the D quality has long been overlooked by previous work. As a result, it is becoming a clear performance bottleneck. Thus, we propose a simple yet effective scheme to measure D quality in advance, the key idea of which is to devise a series of features in accordance with the common attributes of high-quality D regions. To be more concrete, we conduct D quality assessments for each image region, following a multi-scale methodology that includes low-level edge consistency, mid-level regional uncertainty and high-level model variance. All these components will be computed independently and then be assembled with RGB and D features, applied as implicit indicators, to guide the selective fusion. Compared with the state-of-the-art fusion schemes, our method can achieve a more reasonable fusion status between RGB and D. Specifically, the proposed D quality measurement method achieves steady performance improvements for almost 2.0\% in general.
Super-resolution of multispectral satellite images using convolutional neural networks
Feb 03, 2020
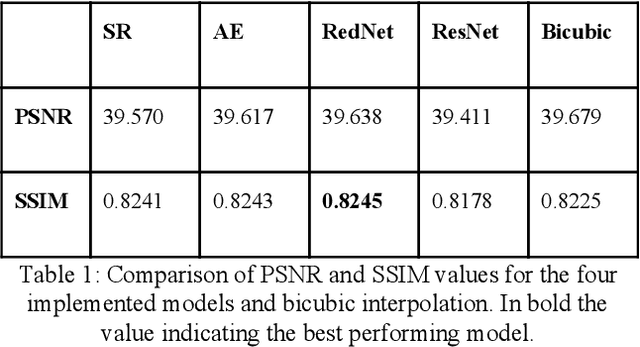
Super-resolution aims at increasing image resolution by algorithmic means and has progressed over the recent years due to advances in the fields of computer vision and deep learning. Convolutional Neural Networks based on a variety of architectures have been applied to the problem, e.g. autoencoders and residual networks. While most research focuses on the processing of photographs consisting only of RGB color channels, little work can be found concentrating on multi-band, analytic satellite imagery. Satellite images often include a panchromatic band, which has higher spatial resolution but lower spectral resolution than the other bands. In the field of remote sensing, there is a long tradition of applying pan-sharpening to satellite images, i.e. bringing the multispectral bands to the higher spatial resolution by merging them with the panchromatic band. To our knowledge there are so far no approaches to super-resolution which take advantage of the panchromatic band. In this paper we propose a method to train state-of-the-art CNNs using pairs of lower-resolution multispectral and high-resolution pan-sharpened image tiles in order to create super-resolved analytic images. The derived quality metrics show that the method improves information content of the processed images. We compare the results created by four CNN architectures, with RedNet30 performing best.
Matching Images and Text with Multi-modal Tensor Fusion and Re-ranking
Aug 12, 2019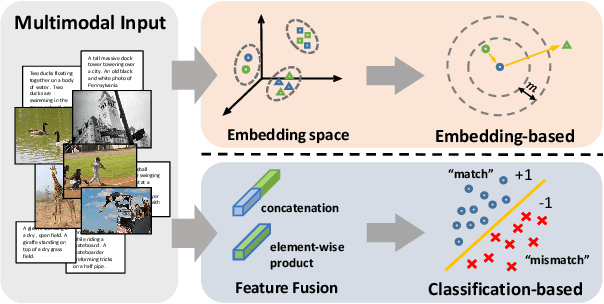
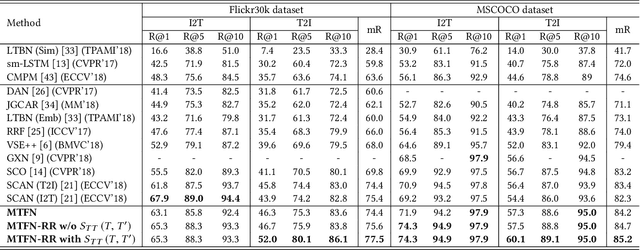
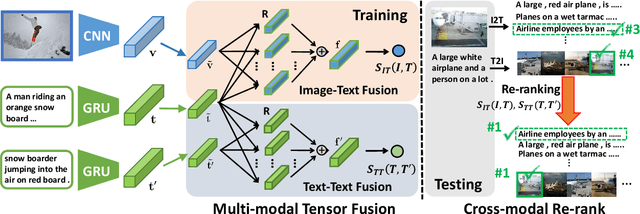
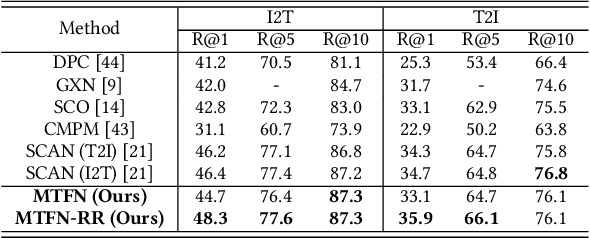
A major challenge in matching images and text is that they have intrinsically different data distributions and feature representations. Most existing approaches are based either on embedding or classification, the first one mapping image and text instances into a common embedding space for distance measuring, and the second one regarding image-text matching as a binary classification problem. Neither of these approaches can, however, balance the matching accuracy and model complexity well. We propose a novel framework that achieves remarkable matching performance with acceptable model complexity. Specifically, in the training stage, we propose a novel Multi-modal Tensor Fusion Network (MTFN) to explicitly learn an accurate image-text similarity function with rank-based tensor fusion rather than seeking a common embedding space for each image-text instance. Then, during testing, we deploy a generic Cross-modal Re-ranking (RR) scheme for refinement without requiring additional training procedure. Extensive experiments on two datasets demonstrate that our MTFN-RR consistently achieves the state-of-the-art matching performance with much less time complexity. The implementation code is available at https://github.com/Wangt-CN/MTFN-RR-PyTorch-Code.
Pix2Vox++: Multi-scale Context-aware 3D Object Reconstruction from Single and Multiple Images
Jun 22, 2020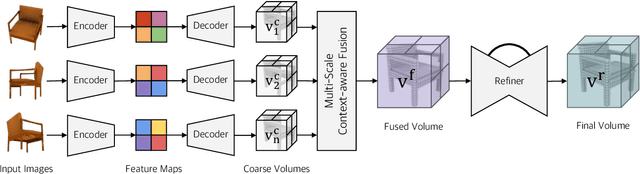
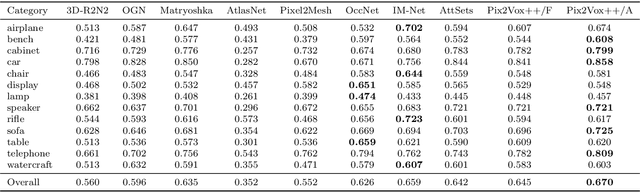
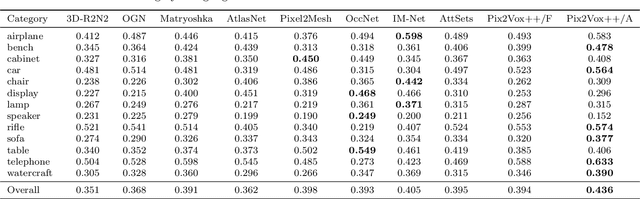
Recovering the 3D shape of an object from single or multiple images with deep neural networks has been attracting increasing attention in the past few years. Mainstream works (e.g. 3D-R2N2) use recurrent neural networks (RNNs) to sequentially fuse feature maps of input images. However, RNN-based approaches are unable to produce consistent reconstruction results when given the same input images with different orders. Moreover, RNNs may forget important features from early input images due to long-term memory loss. To address these issues, we propose a novel framework for single-view and multi-view 3D object reconstruction, named Pix2Vox++. By using a well-designed encoder-decoder, it generates a coarse 3D volume from each input image. A multi-scale context-aware fusion module is then introduced to adaptively select high-quality reconstructions for different parts from all coarse 3D volumes to obtain a fused 3D volume. To further correct the wrongly recovered parts in the fused 3D volume, a refiner is adopted to generate the final output. Experimental results on the ShapeNet, Pix3D, and Things3D benchmarks show that Pix2Vox++ performs favorably against state-of-the-art methods in terms of both accuracy and efficiency.
Adaptive Weighting Depth-variant Deconvolution of Fluorescence Microscopy Images with Convolutional Neural Network
Jul 07, 2019

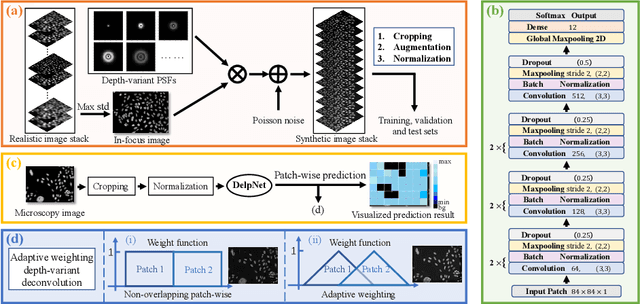
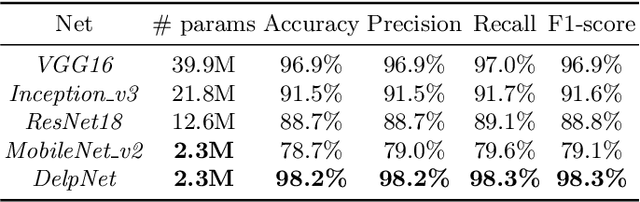
Fluorescence microscopy plays an important role in biomedical research. The depth-variant point spread function (PSF) of a fluorescence microscope produces low-quality images especially in the out-of-focus regions of thick specimens. Traditional deconvolution to restore the out-of-focus images is usually insufficient since a depth-invariant PSF is assumed. This article aims at handling fluorescence microscopy images by learning-based depth-variant PSF and reducing artifacts. We propose adaptive weighting depth-variant deconvolution (AWDVD) with defocus level prediction convolutional neural network (DelpNet) to restore the out-of-focus images. Depth-variant PSFs of image patches can be obtained by DelpNet and applied in the afterward deconvolution. AWDVD is adopted for a whole image which is patch-wise deconvolved and appropriately cropped before deconvolution. DelpNet achieves the accuracy of 98.2%, which outperforms the best-ever one using the same microscopy dataset. Image patches of 11 defocus levels after deconvolution are validated with maximum improvement in the peak signal-to-noise ratio and structural similarity index of 6.6 dB and 11%, respectively. The adaptive weighting of the patch-wise deconvolved image can eliminate patch boundary artifacts and improve deconvolved image quality. The proposed method can accurately estimate depth-variant PSF and effectively recover out-of-focus microscopy images. To our acknowledge, this is the first study of handling out-of-focus microscopy images using learning-based depth-variant PSF. Facing one of the most common blurs in fluorescence microscopy, the novel method provides a practical technology to improve the image quality.
An Estimation Method of Measuring Image Quality for Compressed Images of Human Face
Feb 06, 2014Nowadays digital image compression and decompression techniques are very much important. So our aim is to calculate the quality of face and other regions of the compressed image with respect to the original image. Image segmentation is typically used to locate objects and boundaries (lines, curves etc.)in images. After segmentation the image is changed into something which is more meaningful to analyze. Using Universal Image Quality Index(Q),Structural Similarity Index(SSIM) and Gradient-based Structural Similarity Index(G-SSIM) it can be shown that face region is less compressed than any other region of the image.
Deep learning on edge: extracting field boundaries from satellite images with a convolutional neural network
Oct 26, 2019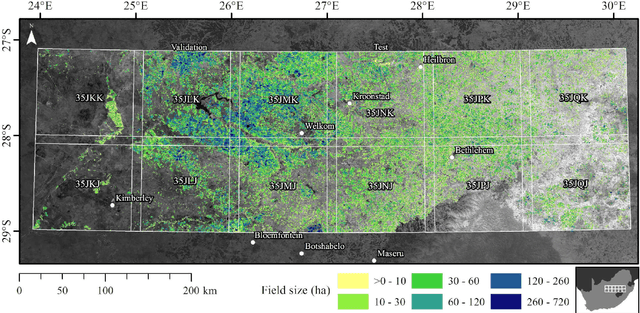
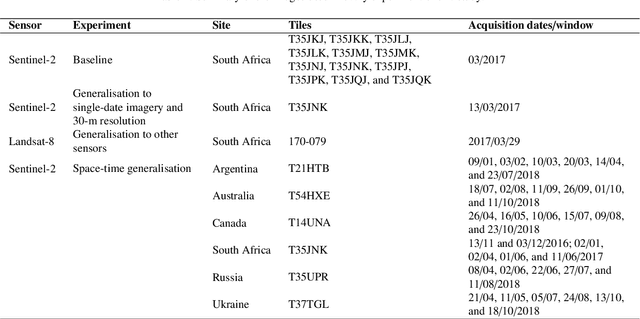
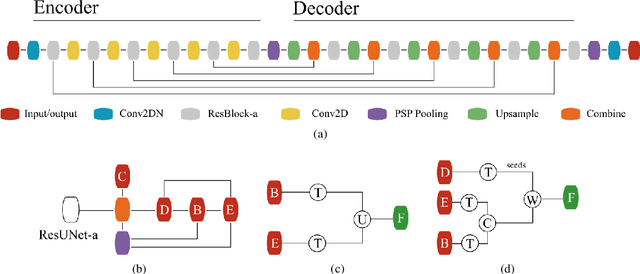
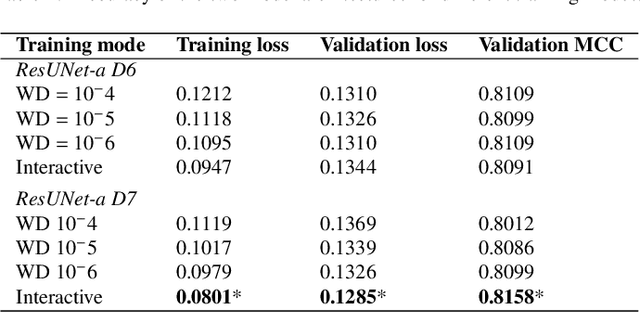
Applications of digital agricultural services often require either farmers or their advisers to provide digital records of their field boundaries. Automatic extraction of field boundaries from satellite imagery would reduce the reliance on manual input of these records which is time consuming and error-prone, and would underpin the provision of remote products and services. The lack of current field boundary data sets seems to indicate low uptake of existing methods,presumably because of expensive image preprocessing requirements and local, often arbitrary, tuning. In this paper, we address the problem of field boundary extraction from satellite images as a multitask semantic segmentation problem. We used ResUNet-a, a deep convolutional neural network with a fully connected UNet backbone that features dilated convolutions and conditioned inference, to assign three labels to each pixel: 1) the probability of belonging to a field; 2) the probability of being part of a boundary; and 3) the distance to the closest boundary. These labels can then be combined to obtain closed field boundaries. Using a single composite image from Sentinel-2, the model was highly accurate in mapping field extent, field boundaries, and, consequently, individual fields. Replacing the monthly composite with a single-date image close to the compositing period only marginally decreased accuracy. We then showed in a series of experiments that our model generalised well across resolutions, sensors, space and time without recalibration. Building consensus by averaging model predictions from at least four images acquired across the season is the key to coping with the temporal variations of accuracy. By minimising image preprocessing requirements and replacing local arbitrary decisions by data-driven ones, our approach is expected to facilitate the extraction of individual crop fields at scale.
DO-Conv: Depthwise Over-parameterized Convolutional Layer
Jun 22, 2020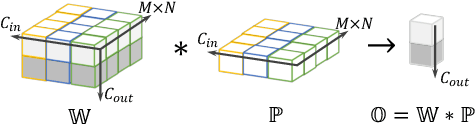
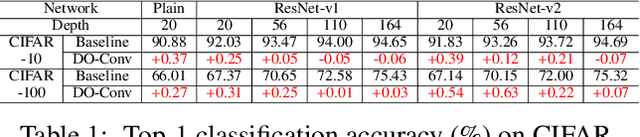

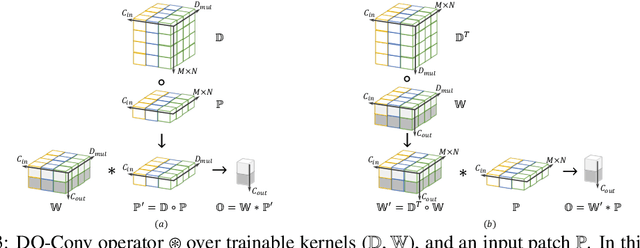
Convolutional layers are the core building blocks of Convolutional Neural Networks (CNNs). In this paper, we propose to augment a convolutional layer with an additional depthwise convolution, where each input channel is convolved with a different 2D kernel. The composition of the two convolutions constitutes an over-parameterization, since it adds learnable parameters, while the resulting linear operation can be expressed by a single convolution layer. We refer to this depthwise over-parameterized convolutional layer as DO-Conv. We show with extensive experiments that the mere replacement of conventional convolutional layers with DO-Conv layers boosts the performance of CNNs on many classical vision tasks, such as image classification, detection, and segmentation. Moreover, in the inference phase, the depthwise convolution is folded into the conventional convolution, reducing the computation to be exactly equivalent to that of a convolutional layer without over-parameterization. As DO-Conv introduces performance gains without incurring any computational complexity increase for inference, we advocate it as an alternative to the conventional convolutional layer. We open-source a reference implementation of DO-Conv in Tensorflow, PyTorch and GluonCV at https://github.com/yangyanli/DO-Conv.
Simultaneous Inpainting and Denoising by Directional Global Three-part Decomposition: Connecting Variational and Fourier Domain Based Image Processing
Jun 09, 2016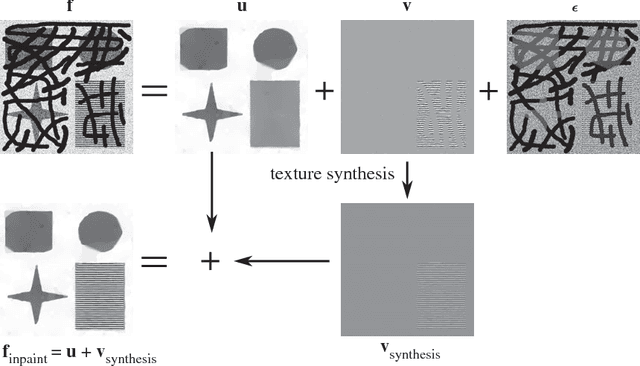


We consider the very challenging task of restoring images (i) which have a large number of missing pixels, (ii) whose existing pixels are corrupted by noise and (iii) the ideal image to be restored contains both cartoon and texture elements. The combination of these three properties makes this inverse problem a very difficult one. The solution proposed in this manuscript is based on directional global three-part decomposition (DG3PD) [ThaiGottschlich2016] with directional total variation norm, directional G-norm and $\ell_\infty$-norm in curvelet domain as key ingredients of the model. Image decomposition by DG3PD enables a decoupled inpainting and denoising of the cartoon and texture components. A comparison to existing approaches for inpainting and denoising shows the advantages of the proposed method. Moreover, we regard the image restoration problem from the viewpoint of a Bayesian framework and we discuss the connections between the proposed solution by function space and related image representation by harmonic analysis and pyramid decomposition.