 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Anisotropic Diffusion for Details Enhancement in Multi-Exposure Image Fusion
Jul 10, 2013

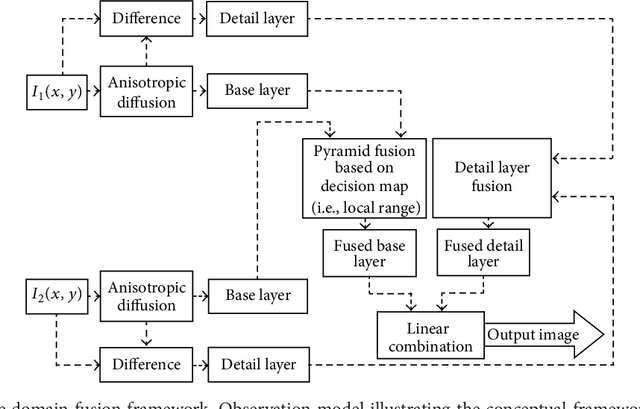
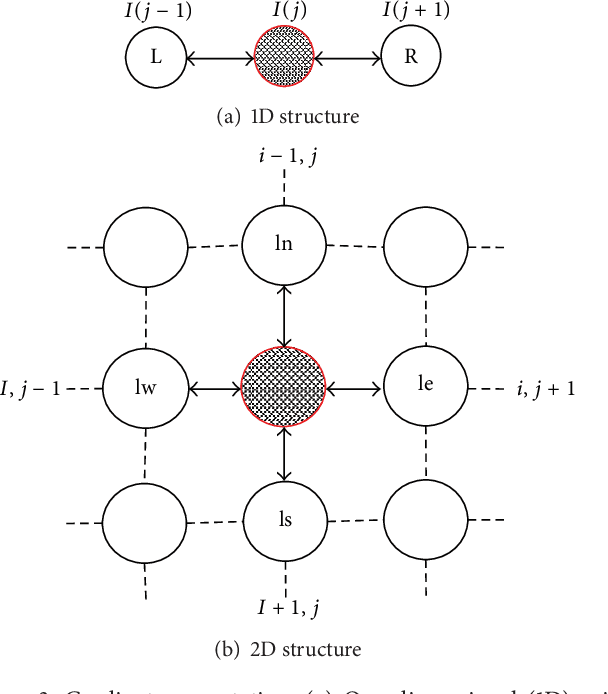
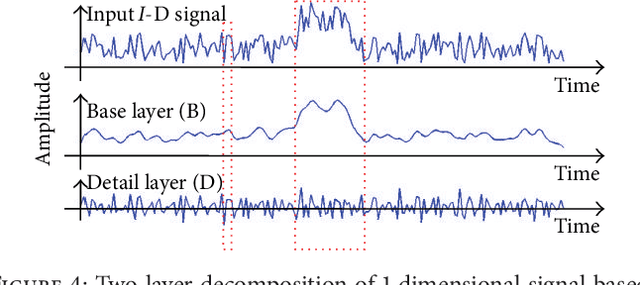
We develop a multiexposure image fusion method based on texture features, which exploits the edge preserving and intraregion smoothing property of nonlinear diffusion filters based on partial differential equations (PDE). With the captured multiexposure image series, we first decompose images into base layers and detail layers to extract sharp details and fine details, respectively. The magnitude of the gradient of the image intensity is utilized to encourage smoothness at homogeneous regions in preference to inhomogeneous regions. Then, we have considered texture features of the base layer to generate a mask (i.e., decision mask) that guides the fusion of base layers in multiresolution fashion. Finally, well-exposed fused image is obtained that combines fused base layer and the detail layers at each scale across all the input exposures. Proposed algorithm skipping complex High Dynamic Range Image (HDRI) generation and tone mapping steps to produce detail preserving image for display on standard dynamic range display devices. Moreover, our technique is effective for blending flash/no-flash image pair and multifocus images, that is, images focused on different targets.
* 30 pages
FusionNet: A deep fully residual convolutional neural network for image segmentation in connectomics
Dec 26, 2016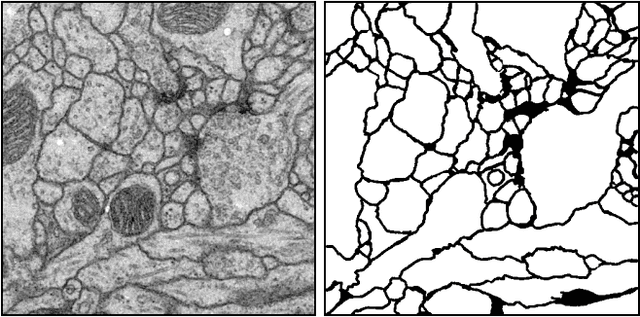
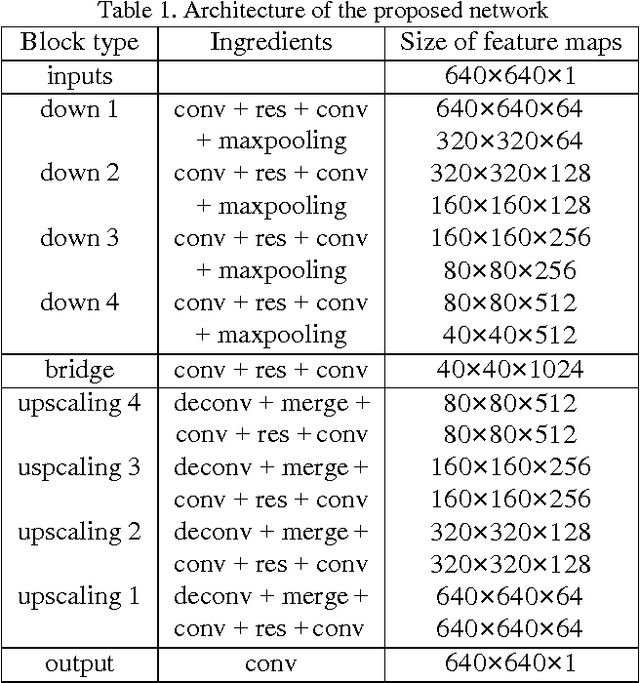
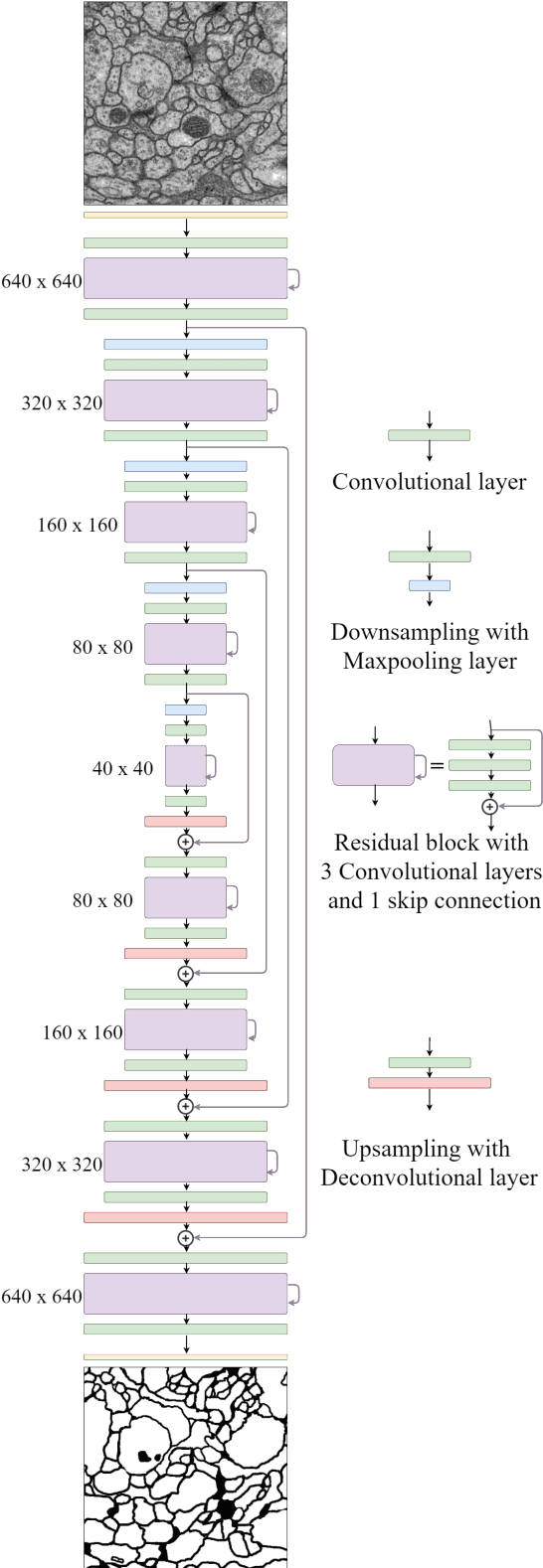
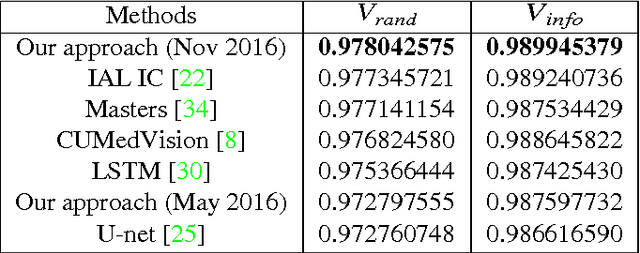
Electron microscopic connectomics is an ambitious research direction with the goal of studying comprehensive brain connectivity maps by using high-throughput, nano-scale microscopy. One of the main challenges in connectomics research is developing scalable image analysis algorithms that require minimal user intervention. Recently, deep learning has drawn much attention in computer vision because of its exceptional performance in image classification tasks. For this reason, its application to connectomic analyses holds great promise, as well. In this paper, we introduce a novel deep neural network architecture, FusionNet, for the automatic segmentation of neuronal structures in connectomics data. FusionNet leverages the latest advances in machine learning, such as semantic segmentation and residual neural networks, with the novel introduction of summation-based skip connections to allow a much deeper network architecture for a more accurate segmentation. We demonstrate the performance of the proposed method by comparing it with state-of-the-art electron microscopy (EM) segmentation methods from the ISBI EM segmentation challenge. We also show the segmentation results on two different tasks including cell membrane and cell body segmentation and a statistical analysis of cell morphology.
Packet2Vec: Utilizing Word2Vec for Feature Extraction in Packet Data
Apr 29, 2020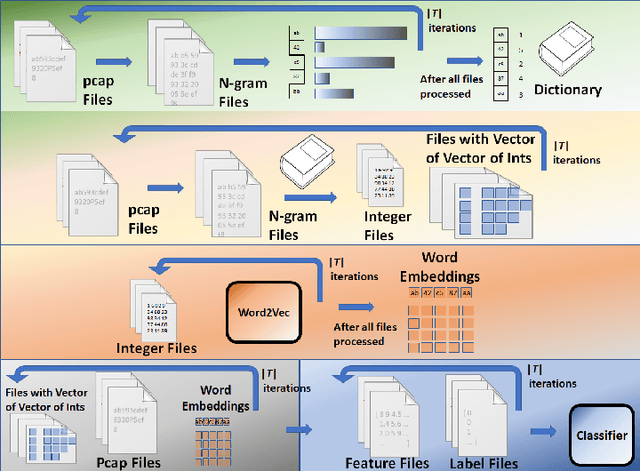


One of deep learning's attractive benefits is the ability to automatically extract relevant features for a target problem from largely raw data, instead of utilizing human engineered and error prone handcrafted features. While deep learning has shown success in fields such as image classification and natural language processing, its application for feature extraction on raw network packet data for intrusion detection is largely unexplored. In this paper we modify a Word2Vec approach, used for text processing, and apply it to packet data for automatic feature extraction. We call this approach Packet2Vec. For the classification task of benign versus malicious traffic on a 2009 DARPA network data set, we obtain an area under the curve (AUC) of the receiver operating characteristic (ROC) between 0.988-0.996 and an AUC of the Precision/Recall curve between 0.604-0.667.
Seeking multi-thresholds for image segmentation with Learning Automata
May 28, 2014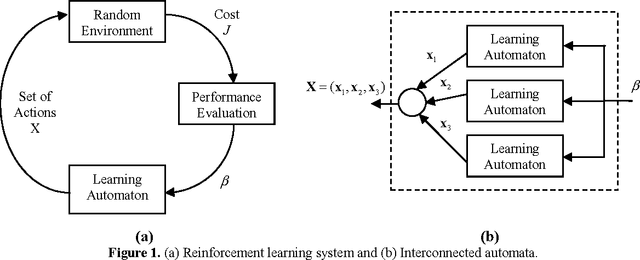


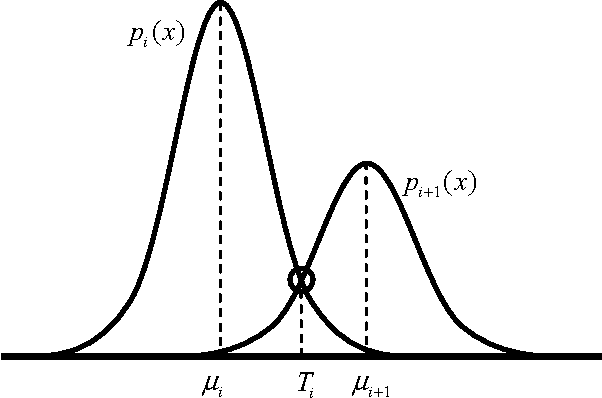
This paper explores the use of the Learning Automata (LA) algorithm to compute threshold selection for image segmentation as it is a critical preprocessing step for image analysis, pattern recognition and computer vision. LA is a heuristic method which is able to solve complex optimization problems with interesting results in parameter estimation. Despite other techniques commonly seek through the parameter map, LA explores in the probability space providing appropriate convergence properties and robustness. The segmentation task is therefore considered as an optimization problem and the LA is used to generate the image multi-threshold separation. In this approach, one 1D histogram of a given image is approximated through a Gaussian mixture model whose parameters are calculated using the LA algorithm. Each Gaussian function approximating the histogram represents a pixel class and therefore a threshold point. The method shows fast convergence avoiding the typical sensitivity to initial conditions such as the Expectation Maximization (EM) algorithm or the complex time-consuming computations commonly found in gradient methods. Experimental results demonstrate the algorithm ability to perform automatic multi-threshold selection and show interesting advantages as it is compared to other algorithms solving the same task.
* 22 Pages. arXiv admin note: text overlap with arXiv:1405.7229
GhostImage: Perception Domain Attacks against Vision-based Object Classification Systems
Jan 21, 2020
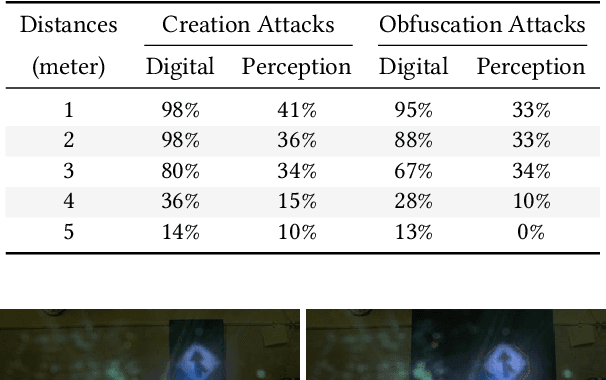
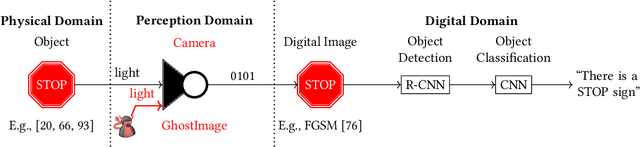
In vision-based object classification systems, imaging sensors perceive the environment and then objects are detected and classified for decision-making purposes. Vulnerabilities in the perception domain enable an attacker to inject false data into the sensor which could lead to unsafe consequences. In this work, we focus on camera-based systems and propose GhostImage attacks, with the goal of either creating a fake perceived object or obfuscating the object's image that leads to wrong classification results. This is achieved by remotely projecting adversarial patterns into camera-perceived images, exploiting two common effects in optical imaging systems, namely lens flare/ghost effects, and auto-exposure control. To improve the robustness of the attack to channel perturbations, we generate optimal input patterns by integrating adversarial machine learning techniques with a trained end-to-end channel model. We realize GhostImage attacks with a projector, and conducted comprehensive experiments, using three different image datasets, in indoor and outdoor environments, and three different cameras. We demonstrate that GhostImage attacks are applicable to both autonomous driving and security surveillance scenarios. Experiment results show that, depending on the projector-camera distance, attack success rates can reach as high as 100%.
Few shot domain adaptation for in situ macromolecule structural classification in cryo-electron tomograms
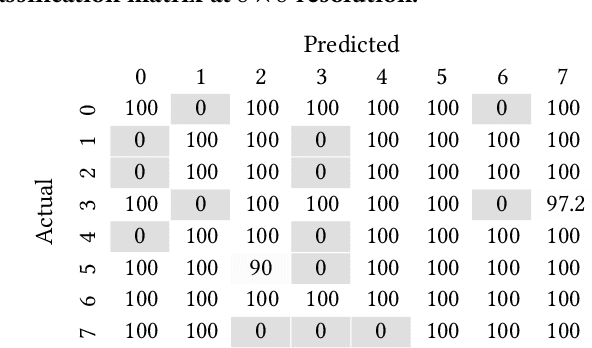
Jul 30, 2020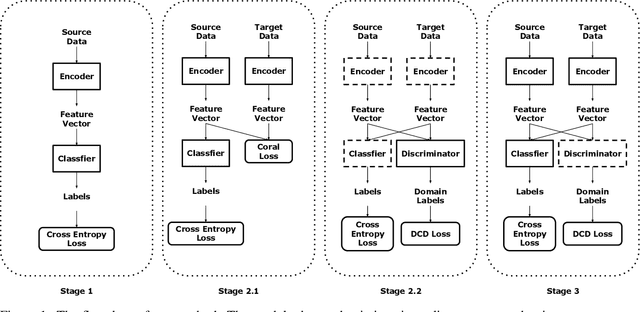
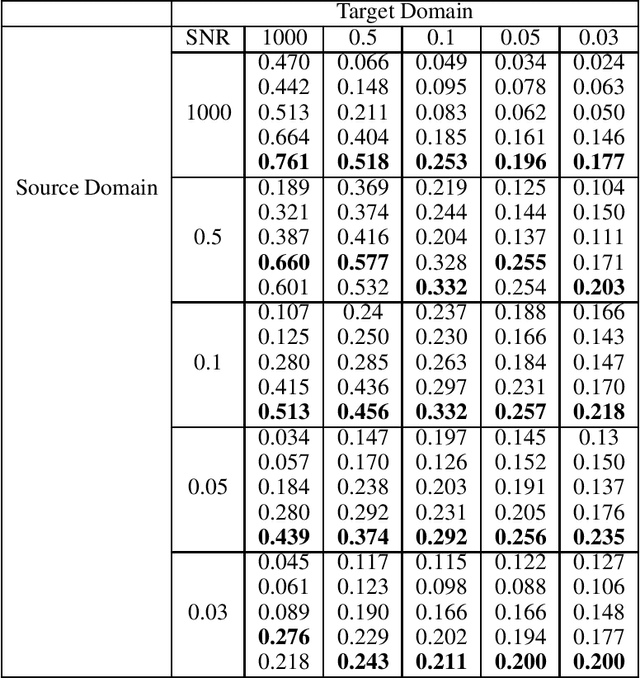
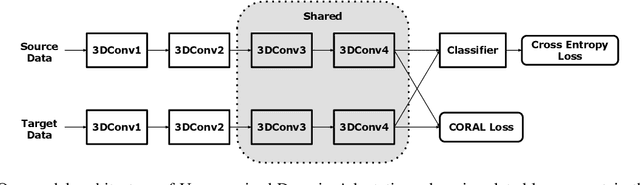
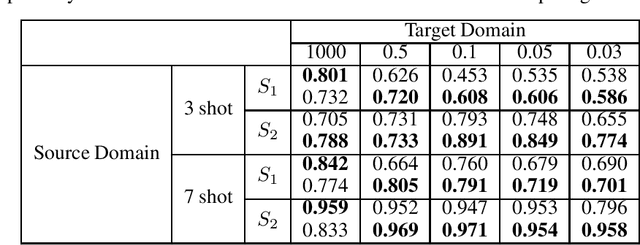
Motivation: Cryo-Electron Tomography (cryo-ET) visualizes structure and spatial organization of macromolecules and their interactions with other subcellular components inside single cells in the close-to-native state at sub-molecular resolution. Such information is critical for the accurate understanding of cellular processes. However, subtomogram classification remains one of the major challenges for the systematic recognition and recovery of the macromolecule structures in cryo-ET because of imaging limits and data quantity. Recently, deep learning has significantly improved the throughput and accuracy of large-scale subtomogram classification. However often it is difficult to get enough high-quality annotated subtomogram data for supervised training due to the enormous expense of labeling. To tackle this problem, it is beneficial to utilize another already annotated dataset to assist the training process. However, due to the discrepancy of image intensity distribution between source domain and target domain, the model trained on subtomograms in source domainmay perform poorly in predicting subtomogram classes in the target domain. Results: In this paper, we adapt a few shot domain adaptation method for deep learning based cross-domain subtomogram classification. The essential idea of our method consists of two parts: 1) take full advantage of the distribution of plentiful unlabeled target domain data, and 2) exploit the correlation between the whole source domain dataset and few labeled target domain data. Experiments conducted on simulated and real datasets show that our method achieves significant improvement on cross domain subtomogram classification compared with baseline methods.
* This article has been accepted for publication in Bioinformatics Published by Oxford University Press
Fine-grained Synthesis of Unrestricted Adversarial Examples
Nov 20, 2019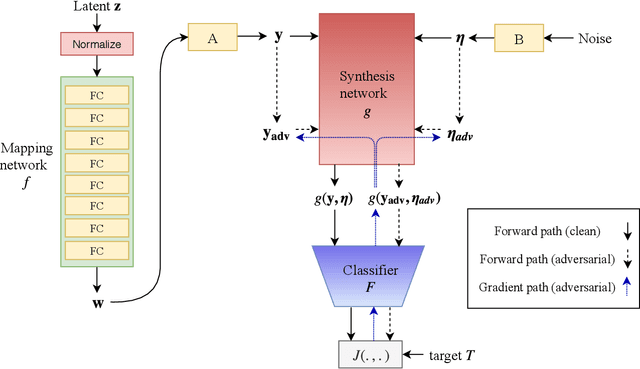
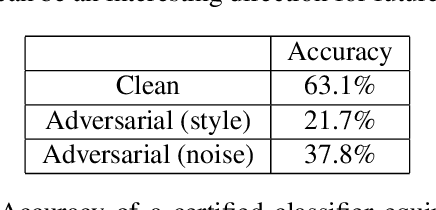

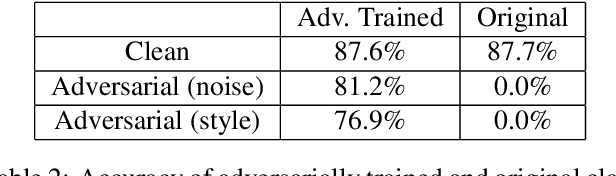
We propose a novel approach for generating unrestricted adversarial examples by manipulating fine-grained aspects of image generation. Unlike existing unrestricted attacks that typically hand-craft geometric transformations, we learn stylistic and stochastic modifications leveraging state-of-the-art generative models. This allows us to manipulate an image in a controlled, fine-grained manner without being bounded by a norm threshold. Our model can be used for both targeted and non-targeted unrestricted attacks. We demonstrate that our attacks can bypass certified defenses, yet our adversarial images look indistinguishable from natural images as verified by human evaluation. Adversarial training can be used as an effective defense without degrading performance of the model on clean images. We perform experiments on LSUN and CelebA-HQ as high resolution datasets to validate efficacy of our proposed approach.
A Survey of Evaluation Metrics Used for NLG Systems
Aug 27, 2020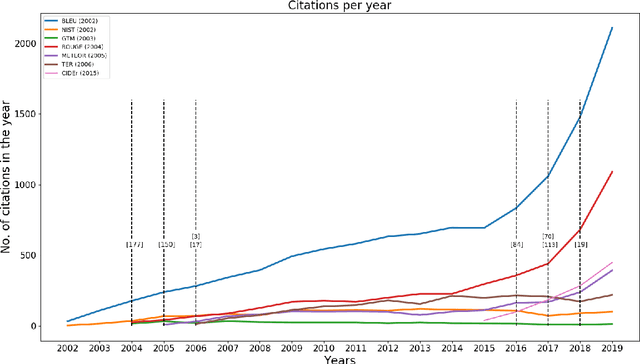
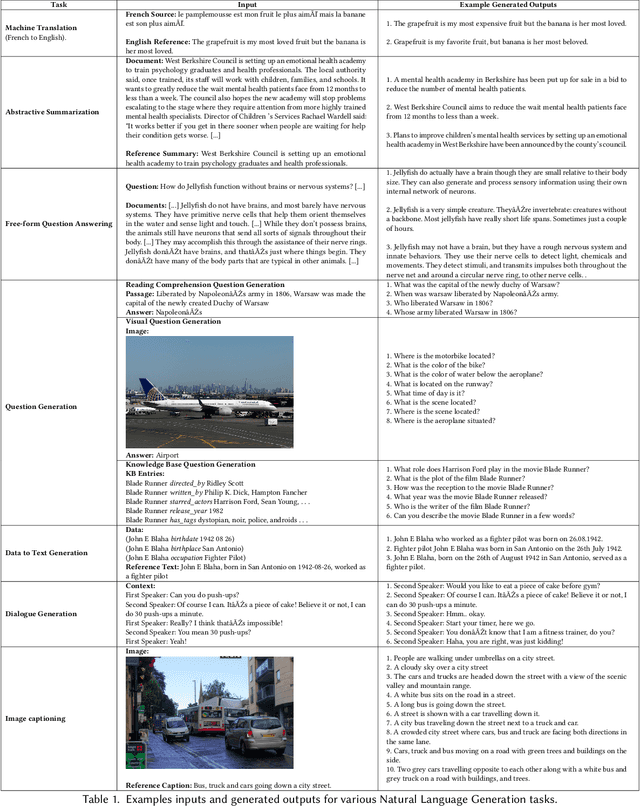


The success of Deep Learning has created a surge in interest in a wide a range of Natural Language Generation (NLG) tasks. Deep Learning has not only pushed the state of the art in several existing NLG tasks but has also facilitated researchers to explore various newer NLG tasks such as image captioning. Such rapid progress in NLG has necessitated the development of accurate automatic evaluation metrics that would allow us to track the progress in the field of NLG. However, unlike classification tasks, automatically evaluating NLG systems in itself is a huge challenge. Several works have shown that early heuristic-based metrics such as BLEU, ROUGE are inadequate for capturing the nuances in the different NLG tasks. The expanding number of NLG models and the shortcomings of the current metrics has led to a rapid surge in the number of evaluation metrics proposed since 2014. Moreover, various evaluation metrics have shifted from using pre-determined heuristic-based formulae to trained transformer models. This rapid change in a relatively short time has led to the need for a survey of the existing NLG metrics to help existing and new researchers to quickly come up to speed with the developments that have happened in NLG evaluation in the last few years. Through this survey, we first wish to highlight the challenges and difficulties in automatically evaluating NLG systems. Then, we provide a coherent taxonomy of the evaluation metrics to organize the existing metrics and to better understand the developments in the field. We also describe the different metrics in detail and highlight their key contributions. Later, we discuss the main shortcomings identified in the existing metrics and describe the methodology used to evaluate evaluation metrics. Finally, we discuss our suggestions and recommendations on the next steps forward to improve the automatic evaluation metrics.
Human Synthesis and Scene Compositing
Oct 18, 2019



Generating good quality and geometrically plausible synthetic images of humans with the ability to control appearance, pose and shape parameters, has become increasingly important for a variety of tasks ranging from photo editing, fashion virtual try-on, to special effects and image compression. In this paper, we propose HUSC, a HUman Synthesis and Scene Compositing framework for the realistic synthesis of humans with different appearance, in novel poses and scenes. Central to our formulation is 3d reasoning for both people and scenes, in order to produce realistic collages, by correctly modeling perspective effects and occlusion, by taking into account scene semantics and by adequately handling relative scales. Conceptually our framework consists of three components: (1) a human image synthesis model with controllable pose and appearance, based on a parametric representation, (2) a person insertion procedure that leverages the geometry and semantics of the 3d scene, and (3) an appearance compositing process to create a seamless blending between the colors of the scene and the generated human image, and avoid visual artifacts. The performance of our framework is supported by both qualitative and quantitative results, in particular state-of-the art synthesis scores for the DeepFashion dataset.
Tiny Descriptors for Image Retrieval with Unsupervised Triplet Hashing
Nov 10, 2015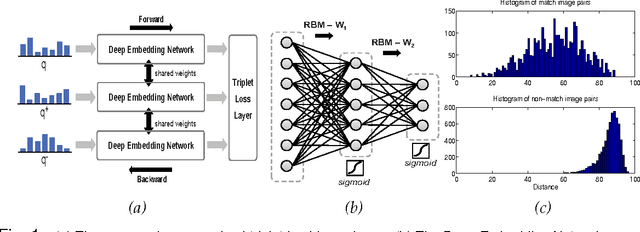
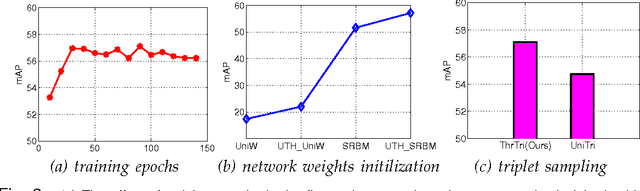
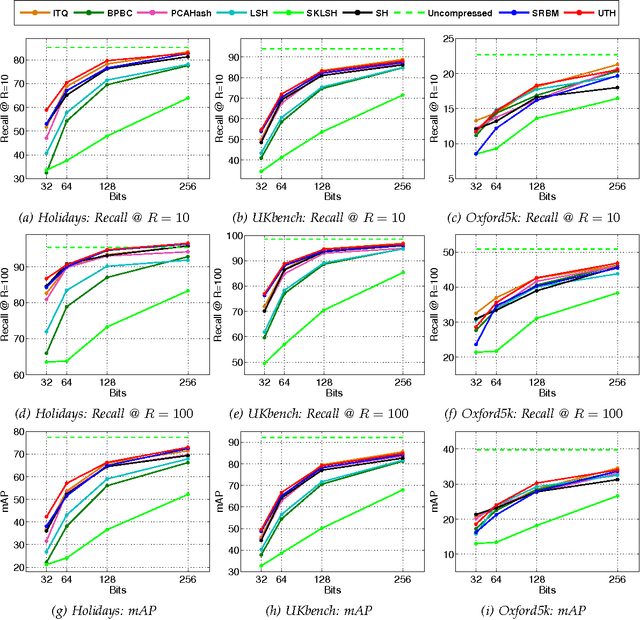
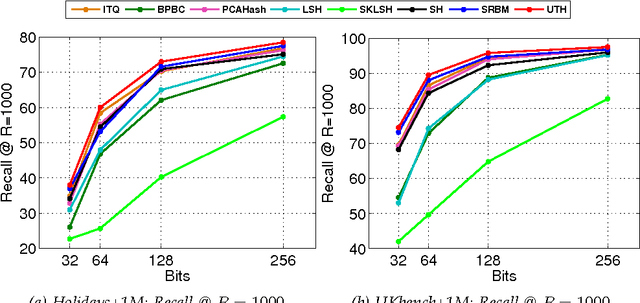
A typical image retrieval pipeline starts with the comparison of global descriptors from a large database to find a short list of candidate matches. A good image descriptor is key to the retrieval pipeline and should reconcile two contradictory requirements: providing recall rates as high as possible and being as compact as possible for fast matching. Following the recent successes of Deep Convolutional Neural Networks (DCNN) for large scale image classification, descriptors extracted from DCNNs are increasingly used in place of the traditional hand crafted descriptors such as Fisher Vectors (FV) with better retrieval performances. Nevertheless, the dimensionality of a typical DCNN descriptor --extracted either from the visual feature pyramid or the fully-connected layers-- remains quite high at several thousands of scalar values. In this paper, we propose Unsupervised Triplet Hashing (UTH), a fully unsupervised method to compute extremely compact binary hashes --in the 32-256 bits range-- from high-dimensional global descriptors. UTH consists of two successive deep learning steps. First, Stacked Restricted Boltzmann Machines (SRBM), a type of unsupervised deep neural nets, are used to learn binary embedding functions able to bring the descriptor size down to the desired bitrate. SRBMs are typically able to ensure a very high compression rate at the expense of loosing some desirable metric properties of the original DCNN descriptor space. Then, triplet networks, a rank learning scheme based on weight sharing nets is used to fine-tune the binary embedding functions to retain as much as possible of the useful metric properties of the original space. A thorough empirical evaluation conducted on multiple publicly available dataset using DCNN descriptors shows that our method is able to significantly outperform state-of-the-art unsupervised schemes in the target bit range.