 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Good is Zero-Shot MT Evaluation for Low Resource Indian Languages?
Jun 06, 2024While machine translation evaluation has been studied primarily for high-resource languages, there has been a recent interest in evaluation for low-resource languages due to the increasing availability of data and models. In this paper, we focus on a zero-shot evaluation setting focusing on low-resource Indian languages, namely Assamese, Kannada, Maithili, and Punjabi. We collect sufficient Multi-Dimensional Quality Metrics (MQM) and Direct Assessment (DA) annotations to create test sets and meta-evaluate a plethora of automatic evaluation metrics. We observe that even for learned metrics, which are known to exhibit zero-shot performance, the Kendall Tau and Pearson correlations with human annotations are only as high as 0.32 and 0.45. Synthetic data approaches show mixed results and overall do not help close the gap by much for these languages. This indicates that there is still a long way to go for low-resource evaluation.
Closing the Gap in the Trade-off between Fair Representations and Accuracy
Apr 15, 2024



The rapid developments of various machine learning models and their deployments in several applications has led to discussions around the importance of looking beyond the accuracies of these models. Fairness of such models is one such aspect that is deservedly gaining more attention. In this work, we analyse the natural language representations of documents and sentences (i.e., encodings) for any embedding-level bias that could potentially also affect the fairness of the downstream tasks that rely on them. We identify bias in these encodings either towards or against different sub-groups based on the difference in their reconstruction errors along various subsets of principal components. We explore and recommend ways to mitigate such bias in the encodings while also maintaining a decent accuracy in classification models that use them.
BiPhone: Modeling Inter Language Phonetic Influences in Text
Jul 06, 2023A large number of people are forced to use the Web in a language they have low literacy in due to technology asymmetries. Written text in the second language (L2) from such users often contains a large number of errors that are influenced by their native language (L1). We propose a method to mine phoneme confusions (sounds in L2 that an L1 speaker is likely to conflate) for pairs of L1 and L2. These confusions are then plugged into a generative model (Bi-Phone) for synthetically producing corrupted L2 text. Through human evaluations, we show that Bi-Phone generates plausible corruptions that differ across L1s and also have widespread coverage on the Web. We also corrupt the popular language understanding benchmark SuperGLUE with our technique (FunGLUE for Phonetically Noised GLUE) and show that SoTA language understating models perform poorly. We also introduce a new phoneme prediction pre-training task which helps byte models to recover performance close to SuperGLUE. Finally, we also release the FunGLUE benchmark to promote further research in phonetically robust language models. To the best of our knowledge, FunGLUE is the first benchmark to introduce L1-L2 interactions in text.
IndicMT Eval: A Dataset to Meta-Evaluate Machine Translation metrics for Indian Languages
Dec 20, 2022



The rapid growth of machine translation (MT) systems has necessitated comprehensive studies to meta-evaluate evaluation metrics being used, which enables a better selection of metrics that best reflect MT quality. Unfortunately, most of the research focuses on high-resource languages, mainly English, the observations for which may not always apply to other languages. Indian languages, having over a billion speakers, are linguistically different from English, and to date, there has not been a systematic study of evaluating MT systems from English into Indian languages. In this paper, we fill this gap by creating an MQM dataset consisting of 7000 fine-grained annotations, spanning 5 Indian languages and 7 MT systems, and use it to establish correlations between annotator scores and scores obtained using existing automatic metrics. Our results show that pre-trained metrics, such as COMET, have the highest correlations with annotator scores. Additionally, we find that the metrics do not adequately capture fluency-based errors in Indian languages, and there is a need to develop metrics focused on Indian languages. We hope that our dataset and analysis will help promote further research in this area.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Perturbation CheckLists for Evaluating NLG Evaluation Metrics
Sep 13, 2021
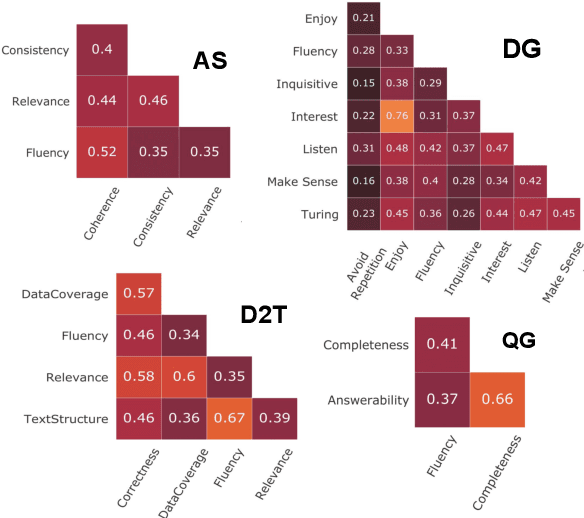
Natural Language Generation (NLG) evaluation is a multifaceted task requiring assessment of multiple desirable criteria, e.g., fluency, coherency, coverage, relevance, adequacy, overall quality, etc. Across existing datasets for 6 NLG tasks, we observe that the human evaluation scores on these multiple criteria are often not correlated. For example, there is a very low correlation between human scores on fluency and data coverage for the task of structured data to text generation. This suggests that the current recipe of proposing new automatic evaluation metrics for NLG by showing that they correlate well with scores assigned by humans for a single criteria (overall quality) alone is inadequate. Indeed, our extensive study involving 25 automatic evaluation metrics across 6 different tasks and 18 different evaluation criteria shows that there is no single metric which correlates well with human scores on all desirable criteria, for most NLG tasks. Given this situation, we propose CheckLists for better design and evaluation of automatic metrics. We design templates which target a specific criteria (e.g., coverage) and perturb the output such that the quality gets affected only along this specific criteria (e.g., the coverage drops). We show that existing evaluation metrics are not robust against even such simple perturbations and disagree with scores assigned by humans to the perturbed output. The proposed templates thus allow for a fine-grained assessment of automatic evaluation metrics exposing their limitations and will facilitate better design, analysis and evaluation of such metrics.
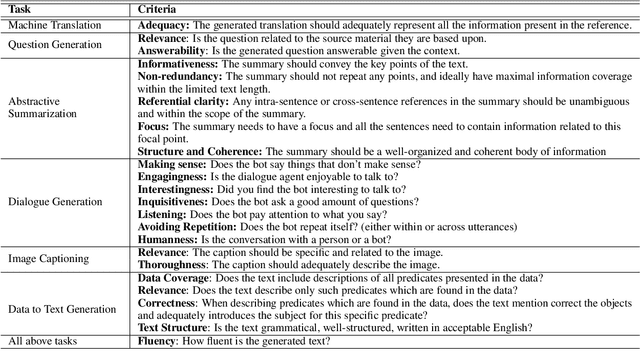
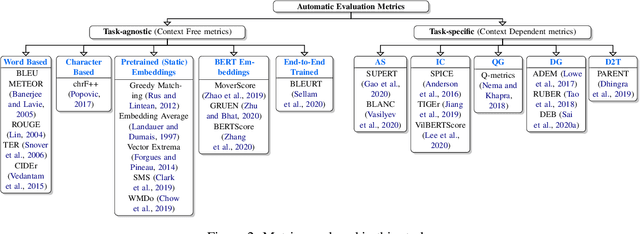
A Survey of Evaluation Metrics Used for NLG Systems
Oct 05, 2020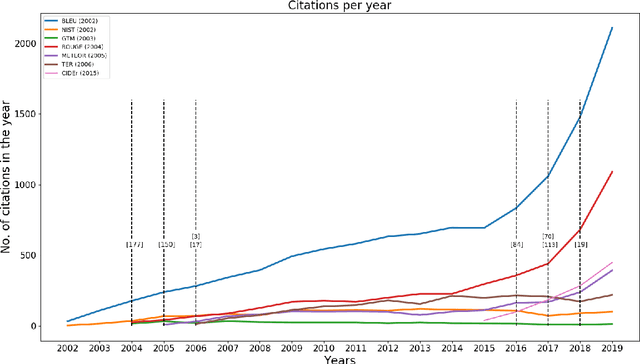
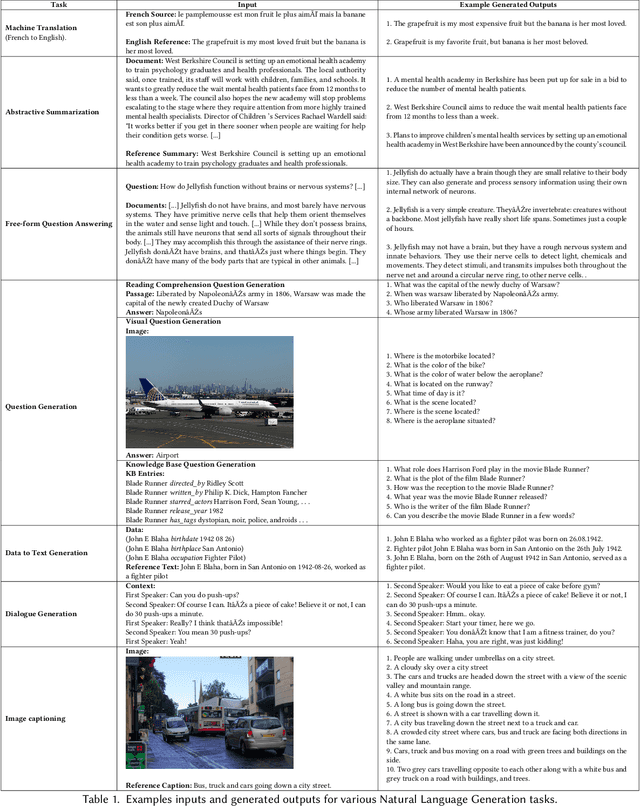


The success of Deep Learning has created a surge in interest in a wide a range of Natural Language Generation (NLG) tasks. Deep Learning has not only pushed the state of the art in several existing NLG tasks but has also facilitated researchers to explore various newer NLG tasks such as image captioning. Such rapid progress in NLG has necessitated the development of accurate automatic evaluation metrics that would allow us to track the progress in the field of NLG. However, unlike classification tasks, automatically evaluating NLG systems in itself is a huge challenge. Several works have shown that early heuristic-based metrics such as BLEU, ROUGE are inadequate for capturing the nuances in the different NLG tasks. The expanding number of NLG models and the shortcomings of the current metrics has led to a rapid surge in the number of evaluation metrics proposed since 2014. Moreover, various evaluation metrics have shifted from using pre-determined heuristic-based formulae to trained transformer models. This rapid change in a relatively short time has led to the need for a survey of the existing NLG metrics to help existing and new researchers to quickly come up to speed with the developments that have happened in NLG evaluation in the last few years. Through this survey, we first wish to highlight the challenges and difficulties in automatically evaluating NLG systems. Then, we provide a coherent taxonomy of the evaluation metrics to organize the existing metrics and to better understand the developments in the field. We also describe the different metrics in detail and highlight their key contributions. Later, we discuss the main shortcomings identified in the existing metrics and describe the methodology used to evaluate evaluation metrics. Finally, we discuss our suggestions and recommendations on the next steps forward to improve the automatic evaluation metrics.
Improving Dialog Evaluation with a Multi-reference Adversarial Dataset and Large Scale Pretraining
Sep 23, 2020
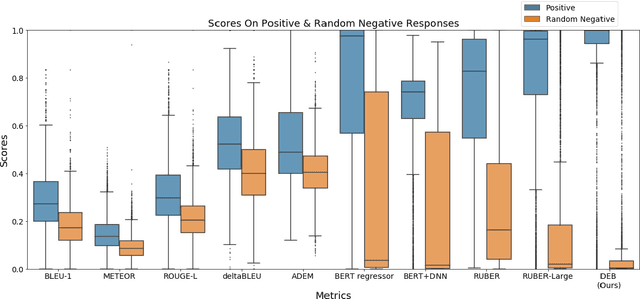

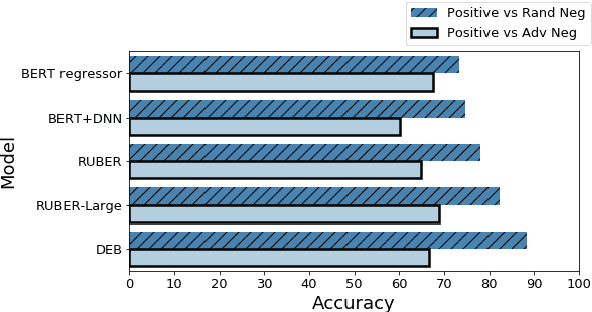
There is an increasing focus on model-based dialog evaluation metrics such as ADEM, RUBER, and the more recent BERT-based metrics. These models aim to assign a high score to all relevant responses and a low score to all irrelevant responses. Ideally, such models should be trained using multiple relevant and irrelevant responses for any given context. However, no such data is publicly available, and hence existing models are usually trained using a single relevant response and multiple randomly selected responses from other contexts (random negatives). To allow for better training and robust evaluation of model-based metrics, we introduce the DailyDialog++ dataset, consisting of (i) five relevant responses for each context and (ii) five adversarially crafted irrelevant responses for each context. Using this dataset, we first show that even in the presence of multiple correct references, n-gram based metrics and embedding based metrics do not perform well at separating relevant responses from even random negatives. While model-based metrics perform better than n-gram and embedding based metrics on random negatives, their performance drops substantially when evaluated on adversarial examples. To check if large scale pretraining could help, we propose a new BERT-based evaluation metric called DEB, which is pretrained on 727M Reddit conversations and then finetuned on our dataset. DEB significantly outperforms existing models, showing better correlation with human judgements and better performance on random negatives (88.27% accuracy). However, its performance again drops substantially, when evaluated on adversarial responses, thereby highlighting that even large-scale pretrained evaluation models are not robust to the adversarial examples in our dataset. The dataset and code are publicly available.
Frustratingly Poor Performance of Reading Comprehension Models on Non-adversarial Examples
Apr 04, 2019
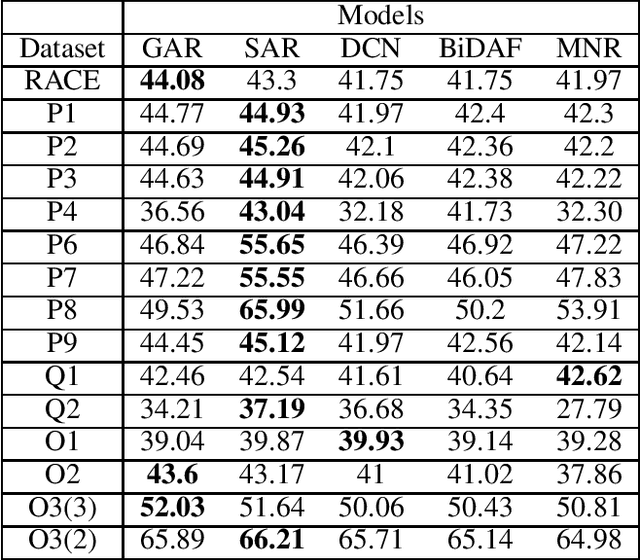

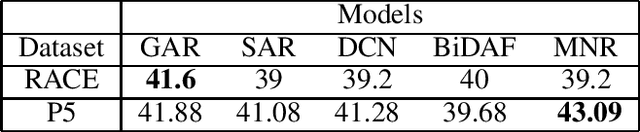
When humans learn to perform a difficult task (say, reading comprehension (RC) over longer passages), it is typically the case that their performance improves significantly on an easier version of this task (say, RC over shorter passages). Ideally, we would want an intelligent agent to also exhibit such a behavior. However, on experimenting with state of the art RC models using the standard RACE dataset, we observe that this is not true. Specifically, we see counter-intuitive results wherein even when we show frustratingly easy examples to the model at test time, there is hardly any improvement in its performance. We refer to this as non-adversarial evaluation as opposed to adversarial evaluation. Such non-adversarial examples allow us to assess the utility of specialized neural components. For example, we show that even for easy examples where the answer is clearly embedded in the passage, the neural components designed for paying attention to relevant portions of the passage fail to serve their intended purpose. We believe that the non-adversarial dataset created as a part of this work would complement the research on adversarial evaluation and give a more realistic assessment of the ability of RC models. All the datasets and codes developed as a part of this work will be made publicly available.
ElimiNet: A Model for Eliminating Options for Reading Comprehension with Multiple Choice Questions
Apr 04, 2019
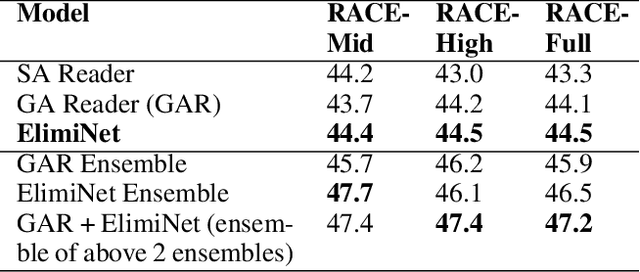
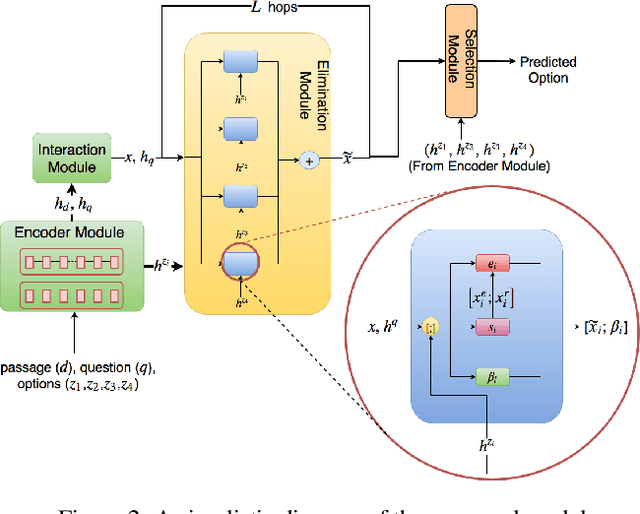
The task of Reading Comprehension with Multiple Choice Questions, requires a human (or machine) to read a given passage, question pair and select one of the n given options. The current state of the art model for this task first computes a question-aware representation for the passage and then selects the option which has the maximum similarity with this representation. However, when humans perform this task they do not just focus on option selection but use a combination of elimination and selection. Specifically, a human would first try to eliminate the most irrelevant option and then read the passage again in the light of this new information (and perhaps ignore portions corresponding to the eliminated option). This process could be repeated multiple times till the reader is finally ready to select the correct option. We propose ElimiNet, a neural network-based model which tries to mimic this process. Specifically, it has gates which decide whether an option can be eliminated given the passage, question pair and if so it tries to make the passage representation orthogonal to this eliminated option (akin to ignoring portions of the passage corresponding to the eliminated option). The model makes multiple rounds of partial elimination to refine the passage representation and finally uses a selection module to pick the best option. We evaluate our model on the recently released large scale RACE dataset and show that it outperforms the current state of the art model on 7 out of the $13$ question types in this dataset. Further, we show that taking an ensemble of our elimination-selection based method with a selection based method gives us an improvement of 3.1% over the best-reported performance on this dataset.
* IJCAI-18