 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Compositional Explanations of Neurons
Jun 24, 2020

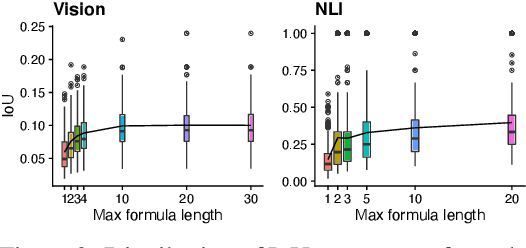


We describe a procedure for explaining neurons in deep representations by identifying compositional logical concepts that closely approximate neuron behavior. Compared to prior work that uses atomic labels as explanations, analyzing neurons compositionally allows us to more precisely and expressively characterize their behavior. We use this procedure to answer several questions on interpretability in models for vision and natural language processing. First, we examine the kinds of abstractions learned by neurons. In image classification, we find that many neurons learn highly abstract but semantically coherent visual concepts, while other polysemantic neurons detect multiple unrelated features; in natural language inference (NLI), neurons learn shallow lexical heuristics from dataset biases. Second, we see whether compositional explanations give us insight into model performance: vision neurons that detect human-interpretable concepts are positively correlated with task performance, while NLI neurons that fire for shallow heuristics are negatively correlated with task performance. Finally, we show how compositional explanations provide an accessible way for end users to produce simple "copy-paste" adversarial examples that change model behavior in predictable ways.
An Overview of Deep Semi-Supervised Learning
Jun 09, 2020
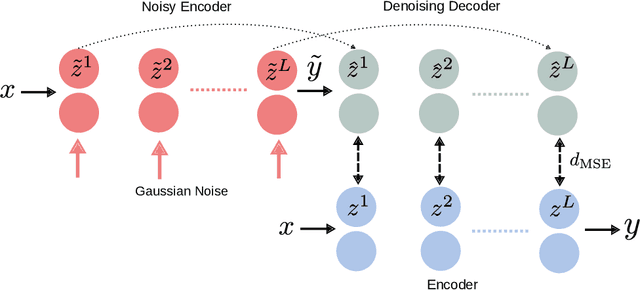

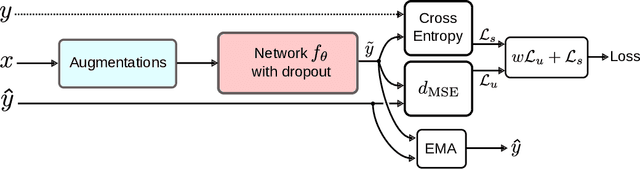
Deep neural networks demonstrated their ability to provide remarkable performances on particular supervised learning tasks (e.g., image classification) when trained on extensive collections of labeled data (e.g., ImageNet). However, creating such large datasets requires a considerable amount of resources, time, and effort. Such resources may not be available in many practical cases, limiting the adoption and application of many deep learning methods. In a search for more data-efficient deep learning methods to overcome this need for large annotated datasets, we a rising research interest in recent years with regards to the application of semi-supervised learning to deep neural nets as a possible alternative, by developing novel methods and adopting existing semi-supervised learning frameworks for a deep learning setting. In this paper, we provide a comprehensive overview of deep semi-supervised learning, starting with an introduction to semi-supervised learning. Followed by a summarization of the dominant semi-supervised approaches in deep learning.
Labelling imaging datasets on the basis of neuroradiology reports: a validation study
Jul 08, 2020

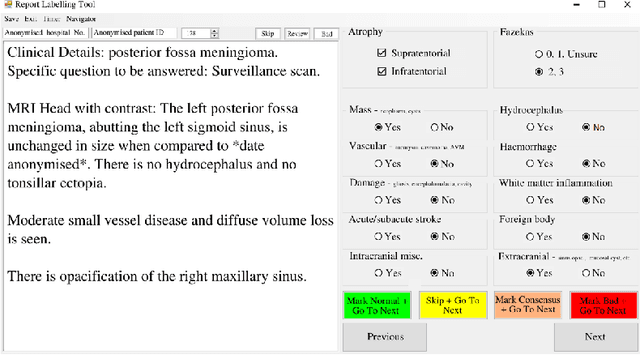

Natural language processing (NLP) shows promise as a means to automate the labelling of hospital-scale neuroradiology magnetic resonance imaging (MRI) datasets for computer vision applications. To date, however, there has been no thorough investigation into the validity of this approach, including determining the accuracy of report labels compared to image labels as well as examining the performance of non-specialist labellers. In this work, we draw on the experience of a team of neuroradiologists who labelled over 5000 MRI neuroradiology reports as part of a project to build a dedicated deep learning-based neuroradiology report classifier. We show that, in our experience, assigning binary labels (i.e. normal vs abnormal) to images from reports alone is highly accurate. In contrast to the binary labels, however, the accuracy of more granular labelling is dependent on the category, and we highlight reasons for this discrepancy. We also show that downstream model performance is reduced when labelling of training reports is performed by a non-specialist. To allow other researchers to accelerate their research, we make our refined abnormality definitions and labelling rules available, as well as our easy-to-use radiology report labelling app which helps streamline this process.
ID-aware Quality for Set-based Person Re-identification
Nov 20, 2019
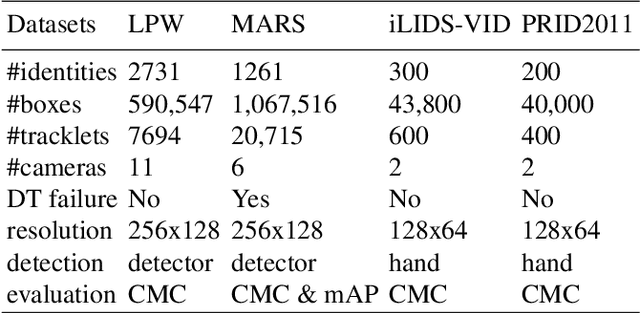
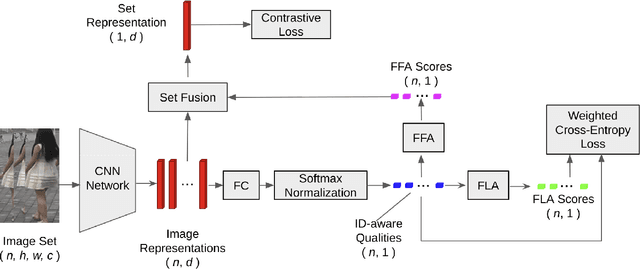
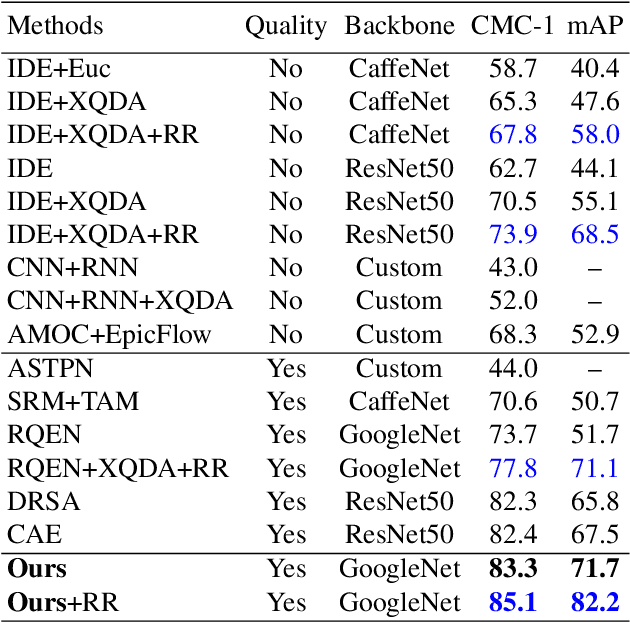
Set-based person re-identification (SReID) is a matching problem that aims to verify whether two sets are of the same identity (ID). Existing SReID models typically generate a feature representation per image and aggregate them to represent the set as a single embedding. However, they can easily be perturbed by noises--perceptually/semantically low quality images--which are inevitable due to imperfect tracking/detection systems, or overfit to trivial images. In this work, we present a novel and simple solution to this problem based on ID-aware quality that measures the perceptual and semantic quality of images guided by their ID information. Specifically, we propose an ID-aware Embedding that consists of two key components: (1) Feature learning attention that aims to learn robust image embeddings by focusing on 'medium' hard images. This way it can prevent overfitting to trivial images, and alleviate the influence of outliers. (2) Feature fusion attention is to fuse image embeddings in the set to obtain the set-level embedding. It ignores noisy information and pays more attention to discriminative images to aggregate more discriminative information. Experimental results on four datasets show that our method outperforms state-of-the-art approaches despite the simplicity of our approach.
Breaking the Limits of Remote Sensing by Simulation and Deep Learning for Flood and Debris Flow Mapping
Jun 09, 2020
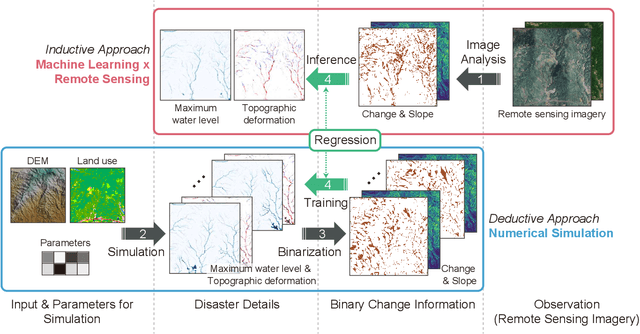
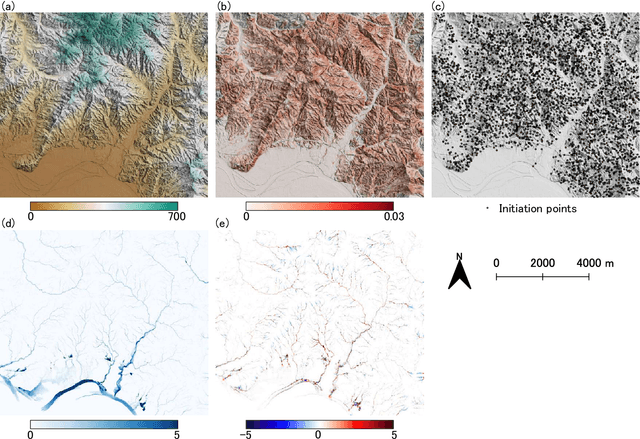
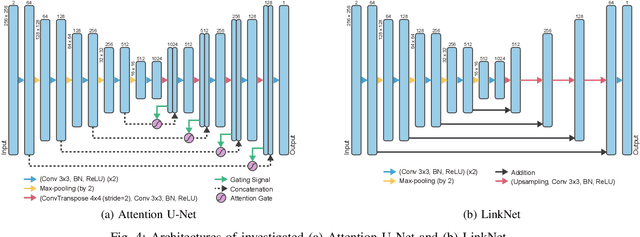
We propose a framework that estimates inundation depth (maximum water level) and debris-flow-induced topographic deformation from remote sensing imagery by integrating deep learning and numerical simulation. A water and debris flow simulator generates training data for various artificial disaster scenarios. We show that regression models based on Attention U-Net and LinkNet architectures trained on such synthetic data can predict the maximum water level and topographic deformation from a remote sensing-derived change detection map and a digital elevation model. The proposed framework has an inpainting capability, thus mitigating the false negatives that are inevitable in remote sensing image analysis. Our framework breaks the limits of remote sensing and enables rapid estimation of inundation depth and topographic deformation, essential information for emergency response, including rescue and relief activities. We conduct experiments with both synthetic and real data for two disaster events that caused simultaneous flooding and debris flows and demonstrate the effectiveness of our approach quantitatively and qualitatively.
DeepSearch: Simple and Effective Blackbox Fuzzing of Deep Neural Networks
Oct 14, 2019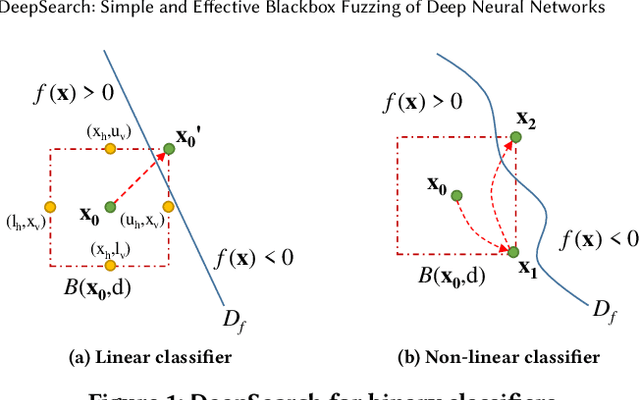
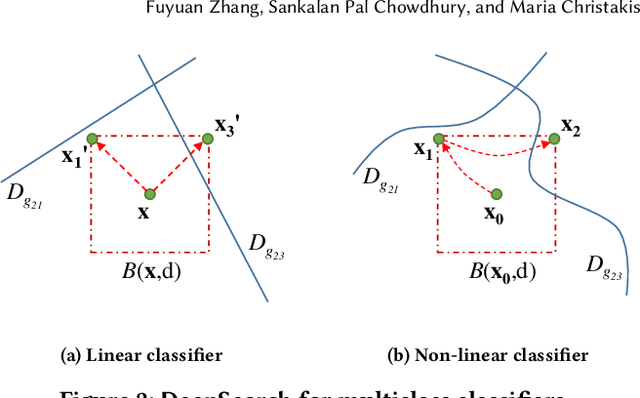
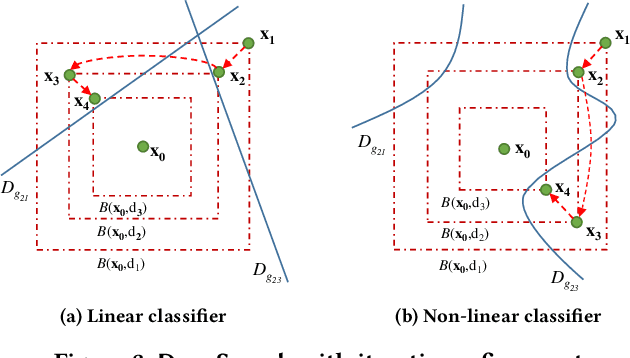
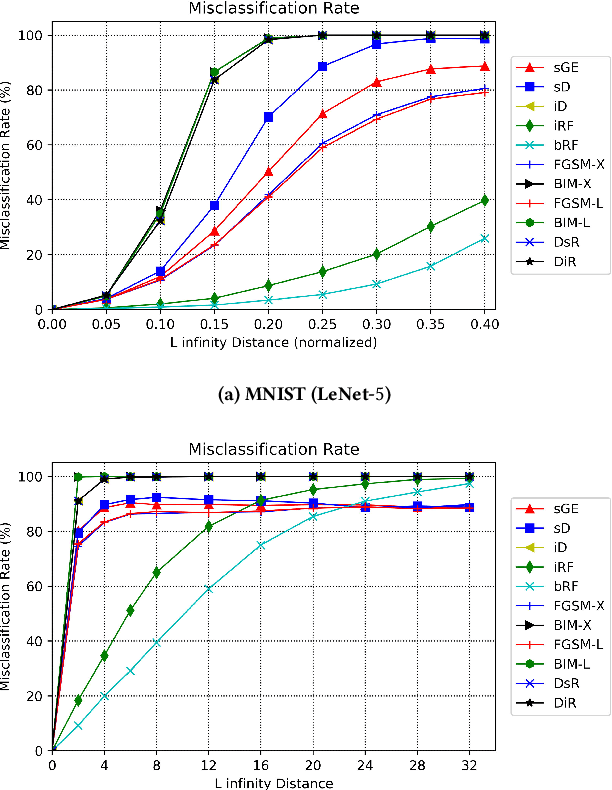
Although deep neural networks have been successful in image classification, they are prone to adversarial attacks. To generate misclassified inputs, there has emerged a wide variety of techniques, such as black- and whitebox testing of neural networks. In this paper, we present DeepSearch, a novel blackbox-fuzzing technique for image classifiers. Despite its simplicity, DeepSearch is shown to be more effective in finding adversarial examples than closely related black- and whitebox approaches. DeepSearch is additionally able to generate the most subtle adversarial examples in comparison to these approaches.
Manifold-Aware CycleGAN for High Resolution Structural-to-DTI Synthesis
Apr 01, 2020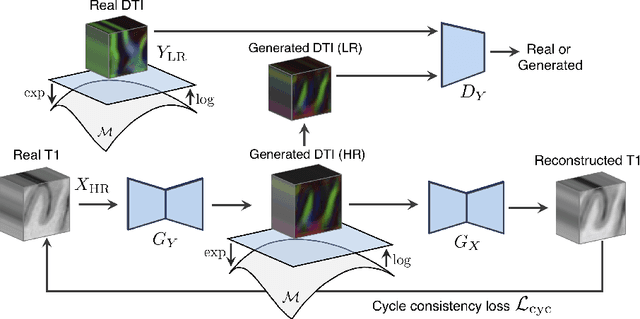
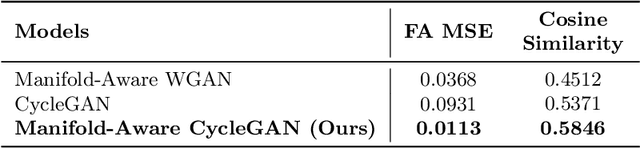
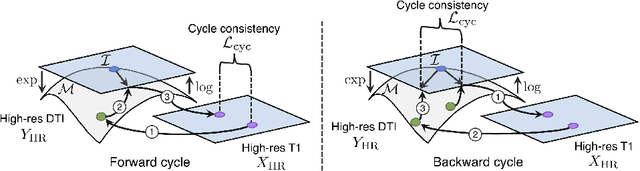
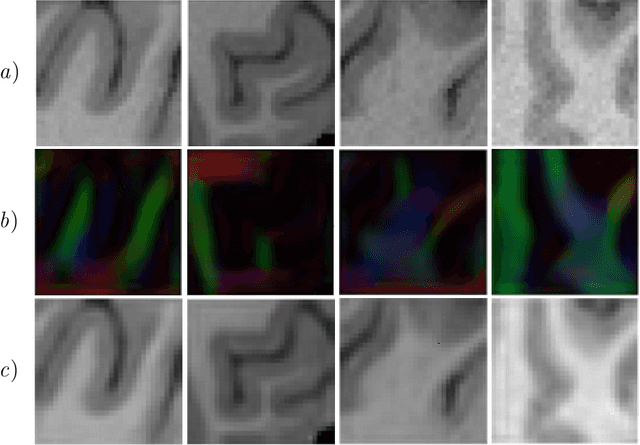
Unpaired image-to-image translation has been applied successfully to natural images but has received very little attention for manifold-valued data such as in diffusion tensor imaging (DTI). The non-Euclidean nature of DTI prevents current generative adversarial networks (GANs) from generating plausible images and has mostly limited their application to diffusion MRI scalar maps, such as fractional anisotropy (FA) or mean diffusivity (MD). Even if these scalar maps are clinically useful, they mostly ignore fiber orientations and have, therefore, limited applications for analyzing brain fibers, for instance, impairing fiber tractography. Here, we propose a manifold-aware CycleGAN that learns the generation of high resolution DTI from unpaired T1w images. We formulate the objective as a Wasserstein distance minimization problem of data distributions on a Riemannian manifold of symmetric positive definite 3x3 matrices SPD(3), using adversarial and cycle-consistency losses. To ensure that the generated diffusion tensors lie on the SPD(3) manifold, we exploit the theoretical properties of the exponential and logarithm maps. We demonstrate that, unlike standard GANs, our method is able to generate realistic high resolution DTI that can be used to compute diffusion-based metrics and run fiber tractography algorithms. To evaluate our model's performance, we compute the cosine similarity between the generated tensors principal orientation and their ground truth orientation and the mean squared error (MSE) of their derived FA values. We demonstrate that our method produces up to 8 times better FA MSE than a standard CycleGAN and 30% better cosine similarity than a manifold-aware Wasserstein GAN while synthesizing sharp high resolution DTI.
Generator From Edges: Reconstruction of Facial Images
Feb 22, 2020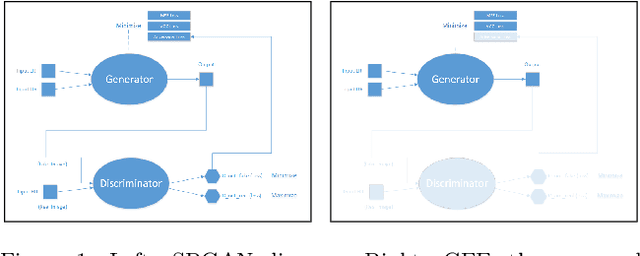


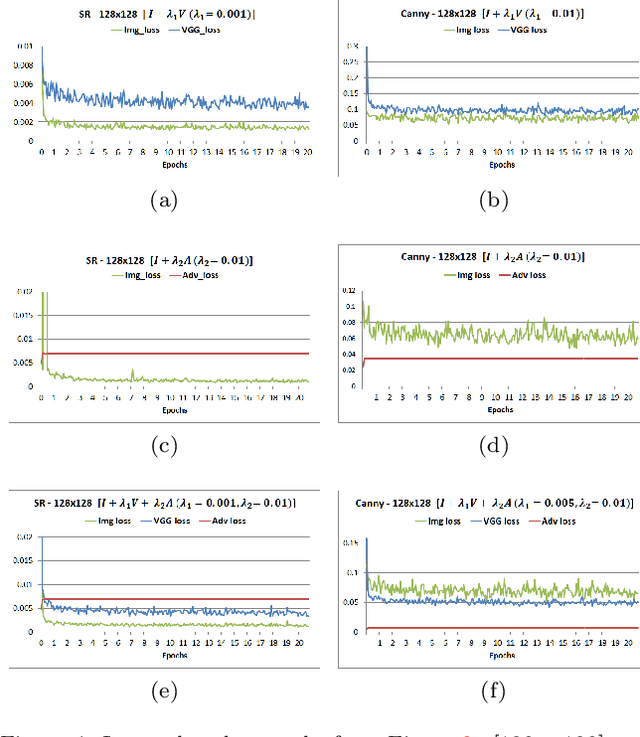
Applications that involve supervised training require paired images. Researchers of single image super-resolution (SISR) create such images by artificially generating blurry input images from the corresponding ground truth. Similarly we can create paired images with the canny edge. We propose Generator From Edges (GFE) [Figure 2]. Our aim is to determine the best architecture for GFE, along with reviews of perceptual loss [1, 2]. To this end, we conducted three experiments. First, we explored the effects of the adversarial loss often used in SISR. In particular, we uncovered that it is not an essential component to form a perceptual loss. Eliminating adversarial loss will lead to a more effective architecture from the perspective of hardware resource. It also means that considerations for the problems pertaining to generative adversarial network (GAN) [3], such as mode collapse, are not necessary. Second, we reexamined VGG loss and found that the mid-layers yield the best results. By extracting the full potential of VGG loss, the overall performance of perceptual loss improves significantly. Third, based on the findings of the first two experiments, we reevaluated the dense network to construct GFE. Using GFE as an intermediate process, reconstructing a facial image from a pencil sketch can become an easy task.
Remix: Rebalanced Mixup
Jul 08, 2020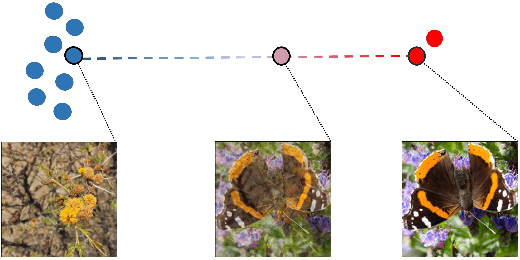
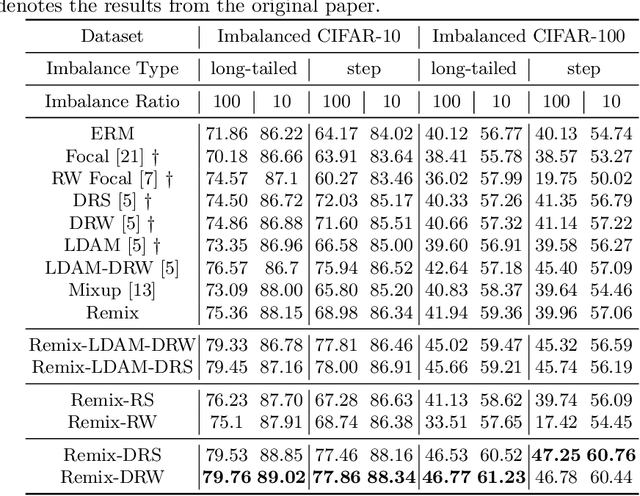
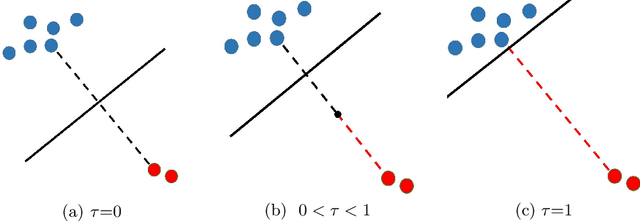
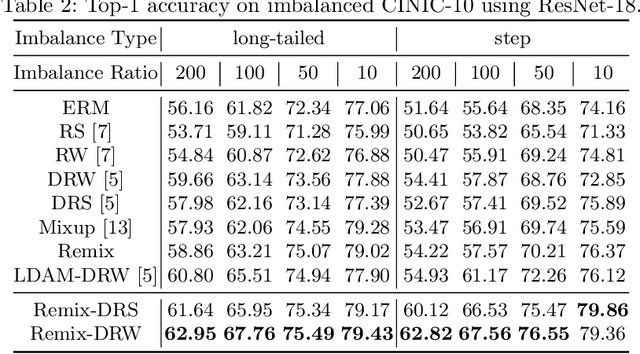
Deep image classifiers often perform poorly when training data are heavily class-imbalanced. In this work, we propose a new regularization technique, Remix, that relaxes Mixup's formulation and enables the mixing factors of features and labels to be disentangled. Specifically, when mixing two samples, while features are mixed up proportionally in the same fashion as Mixup methods, Remix assigns the label in favor of the minority class by providing a disproportionately higher weight to the minority class. By doing so, the classifier learns to push the decision boundaries towards the majority classes and balances the generalization error between majority and minority classes. We have studied the state of the art regularization techniques such as Mixup, Manifold Mixup and CutMix under class-imbalanced regime, and shown that the proposed Remix significantly outperforms these state-of-the-arts and several re-weighting and re-sampling techniques, on the imbalanced datasets constructed by CIFAR-10, CIFAR-100, and CINIC-10. We have also evaluated Remix on a real-world large-scale imbalanced dataset, iNaturalist 2018. The experimental results confirmed that Remix provides consistent and significant improvements over the previous state-of-the-arts.
Manifold regularized kernel logistic regression for web image annotation
Dec 21, 2013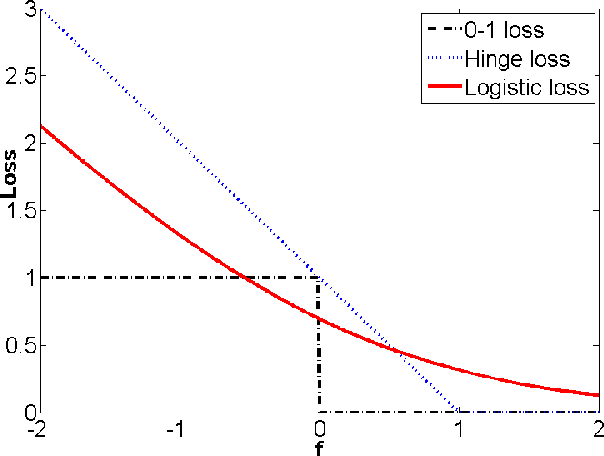

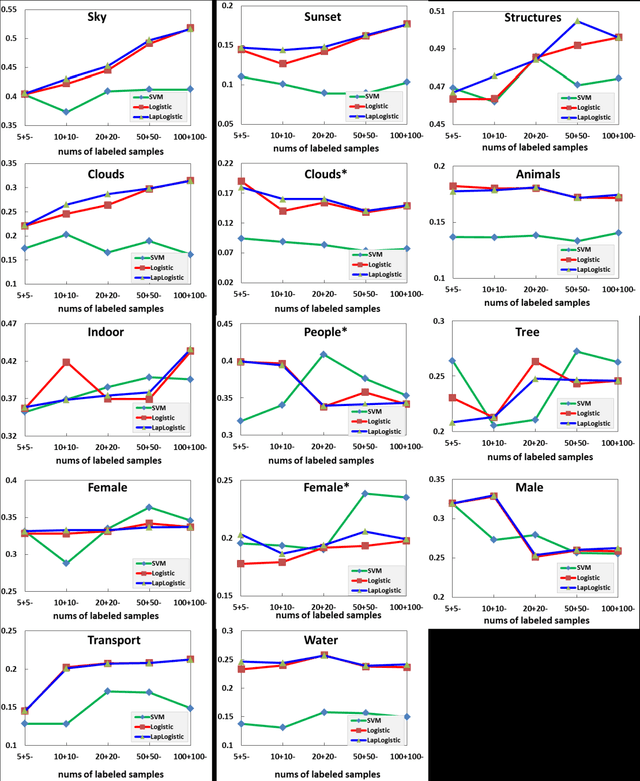
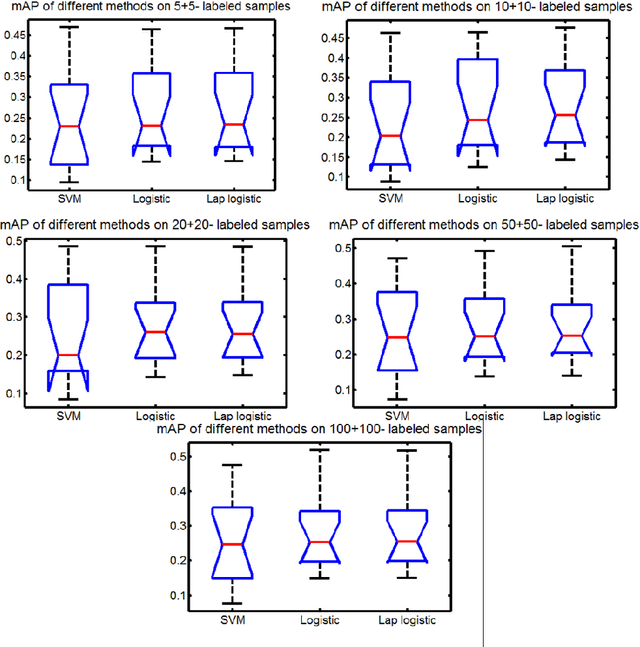
With the rapid advance of Internet technology and smart devices, users often need to manage large amounts of multimedia information using smart devices, such as personal image and video accessing and browsing. These requirements heavily rely on the success of image (video) annotation, and thus large scale image annotation through innovative machine learning methods has attracted intensive attention in recent years. One representative work is support vector machine (SVM). Although it works well in binary classification, SVM has a non-smooth loss function and can not naturally cover multi-class case. In this paper, we propose manifold regularized kernel logistic regression (KLR) for web image annotation. Compared to SVM, KLR has the following advantages: (1) the KLR has a smooth loss function; (2) the KLR produces an explicit estimate of the probability instead of class label; and (3) the KLR can naturally be generalized to the multi-class case. We carefully conduct experiments on MIR FLICKR dataset and demonstrate the effectiveness of manifold regularized kernel logistic regression for image annotation.