 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CPR: Classifier-Projection Regularization for Continual Learning
Jun 12, 2020
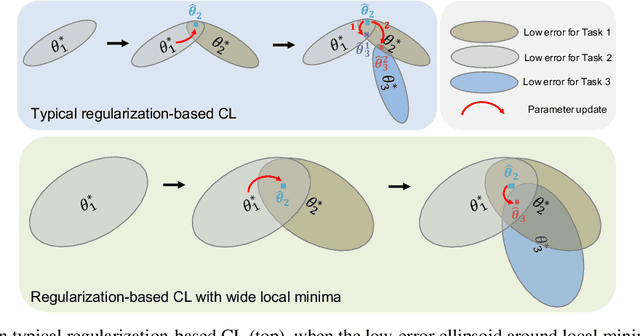
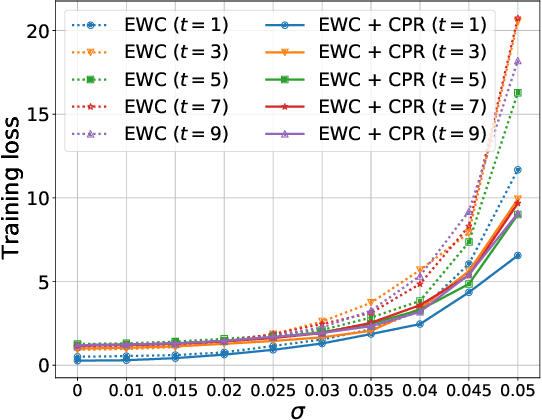
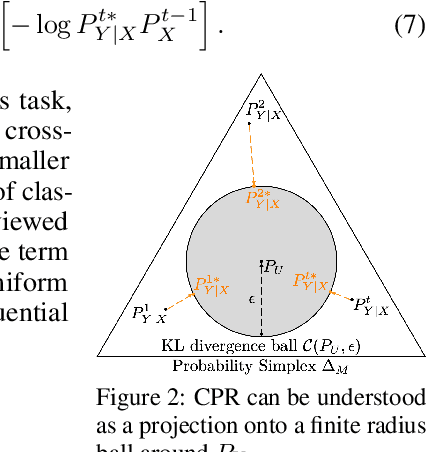
We propose a general, yet simple patch that can be applied to existing regularization-based continual learning methods called classifier-projection regularization (CPR). Inspired by both recent results on neural networks with wide local minima and information theory, CPR adds an additional regularization term that maximizes the entropy of a classifier's output probability. We demonstrate that this additional term can be interpreted as a projection of the conditional probability given by a classifier's output to the uniform distribution. By applying the Pythagorean theorem for KL divergence, we then prove that this projection may (in theory) improve the performance of continual learning methods. In our extensive experimental results, we apply CPR to several state-of-the-art regularization-based continual learning methods and benchmark performance on popular image recognition datasets. Our results demonstrate that CPR indeed promotes a wide local minima and significantly improves both accuracy and plasticity while simultaneously mitigating the catastrophic forgetting of baseline continual learning methods.
Out-of-Distribution Detection in Multi-Label Datasets using Latent Space of $β$-VAE
Mar 10, 2020
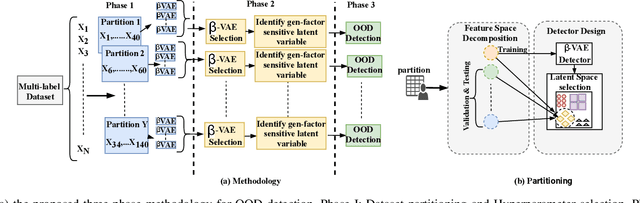
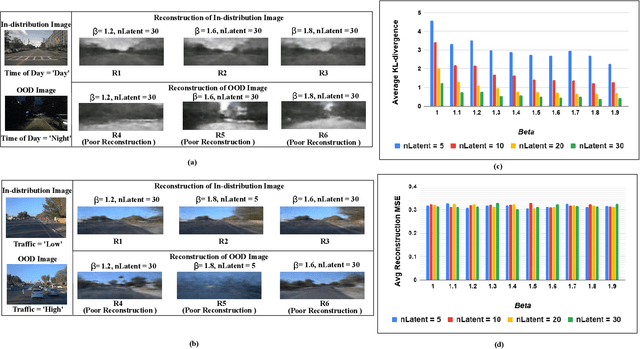
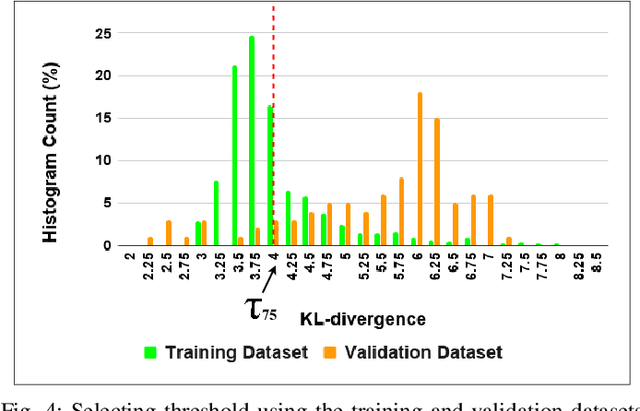
Learning Enabled Components (LECs) are widely being used in a variety of perception based autonomy tasks like image segmentation, object detection, end-to-end driving, etc. These components are trained with large image datasets with multimodal factors like weather conditions, time-of-day, traffic-density, etc. The LECs learn from these factors during training, and while testing if there is variation in any of these factors, the components get confused resulting in low confidence predictions. The images with factors not seen during training is commonly referred to as Out-of-Distribution (OOD). For safe autonomy it is important to identify the OOD images, so that a suitable mitigation strategy can be performed. Classical one-class classifiers like SVM and SVDD are used to perform OOD detection. However, the multiple labels attached to the images in these datasets, restricts the direct application of these techniques. We address this problem using the latent space of the $\beta$-Variational Autoencoder ($\beta$-VAE). We use the fact that compact latent space generated by an appropriately selected $\beta$-VAE will encode the information about these factors in a few latent variables, and that can be used for computationally inexpensive detection. We evaluate our approach on the nuScenes dataset, and our results shows the latent space of $\beta$-VAE is sensitive to encode changes in the values of the generative factor.
Edge-Gated CNNs for Volumetric Semantic Segmentation of Medical Images
Feb 11, 2020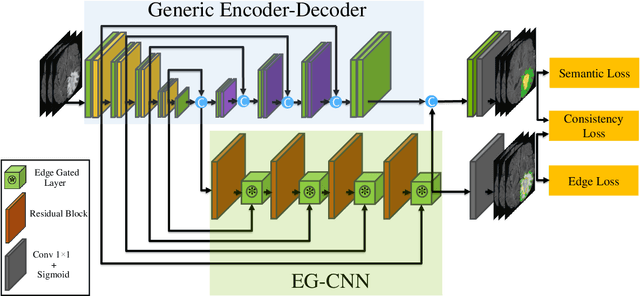
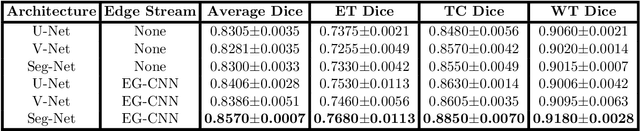
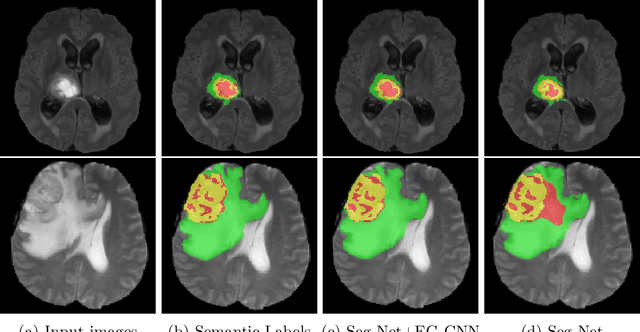
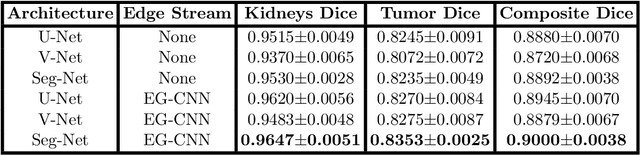
Textures and edges contribute different information to image recognition. Edges and boundaries encode shape information, while textures manifest the appearance of regions. Despite the success of Convolutional Neural Networks (CNNs) in computer vision and medical image analysis applications, predominantly only texture abstractions are learned, which often leads to imprecise boundary delineations. In medical imaging, expert manual segmentation often relies on organ boundaries; for example, to manually segment a liver, a medical practitioner usually identifies edges first and subsequently fills in the segmentation mask. Motivated by these observations, we propose a plug-and-play module, dubbed Edge-Gated CNNs (EG-CNNs), that can be used with existing encoder-decoder architectures to process both edge and texture information. The EG-CNN learns to emphasize the edges in the encoder, to predict crisp boundaries by an auxiliary edge supervision, and to fuse its output with the original CNN output. We evaluate the effectiveness of the EG-CNN with various mainstream CNNs on two publicly available datasets, BraTS 19 and KiTS 19 for brain tumor and kidney semantic segmentation. We demonstrate how the addition of EG-CNN consistently improves segmentation accuracy and generalization performance.
Domain Independent Unsupervised Learning to grasp the Novel Objects
Jan 09, 2020
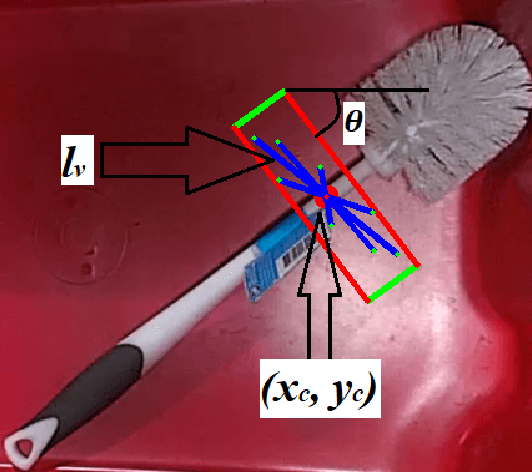
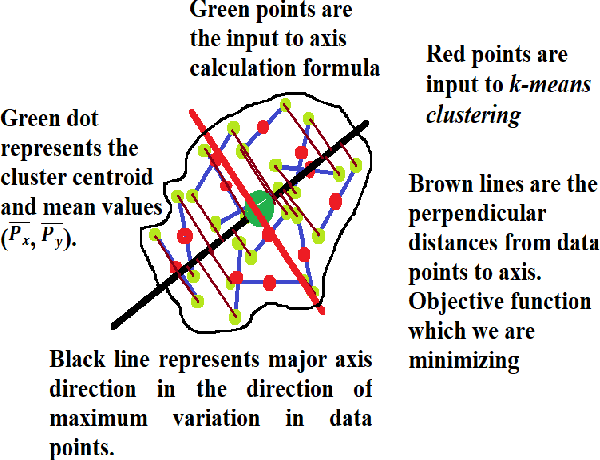
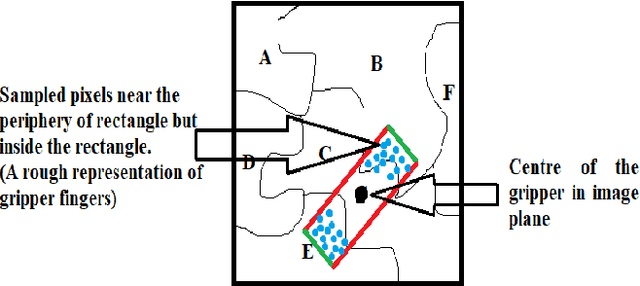
One of the main challenges in the vision-based grasping is the selection of feasible grasp regions while interacting with novel objects. Recent approaches exploit the power of the convolutional neural network (CNN) to achieve accurate grasping at the cost of high computational power and time. In this paper, we present a novel unsupervised learning based algorithm for the selection of feasible grasp regions. Unsupervised learning infers the pattern in data-set without any external labels. We apply k-means clustering on the image plane to identify the grasp regions, followed by an axis assignment method. We define a novel concept of Grasp Decide Index (GDI) to select the best grasp pose in image plane. We have conducted several experiments in clutter or isolated environment on standard objects of Amazon Robotics Challenge 2017 and Amazon Picking Challenge 2016. We compare the results with prior learning based approaches to validate the robustness and adaptive nature of our algorithm for a variety of novel objects in different domains.
Global Hashing System for Fast Image Search
Apr 18, 2019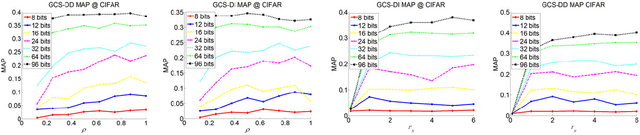
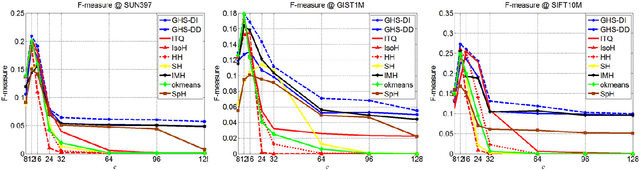
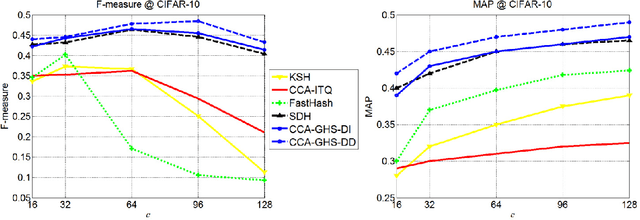

Hashing methods have been widely investigated for fast approximate nearest neighbor searching in large data sets. Most existing methods use binary vectors in lower dimensional spaces to represent data points that are usually real vectors of higher dimensionality. We divide the hashing process into two steps. Data points are first embedded in a low-dimensional space, and the global positioning system method is subsequently introduced but modified for binary embedding. We devise dataindependent and data-dependent methods to distribute the satellites at appropriate locations. Our methods are based on finding the tradeoff between the information losses in these two steps. Experiments show that our data-dependent method outperforms other methods in different-sized data sets from 100k to 10M. By incorporating the orthogonality of the code matrix, both our data-independent and data-dependent methods are particularly impressive in experiments on longer bits.
Training Multiscale-CNN for Large Microscopy Image Classification in One Hour
Oct 03, 2019
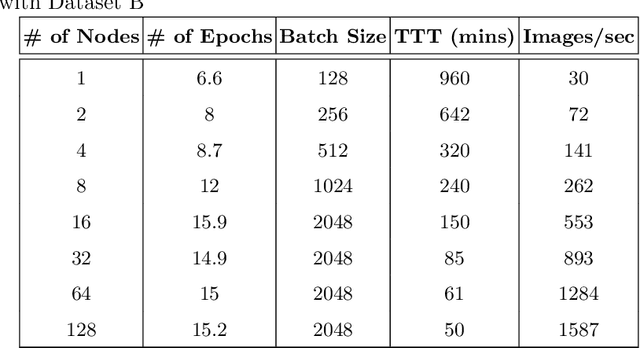
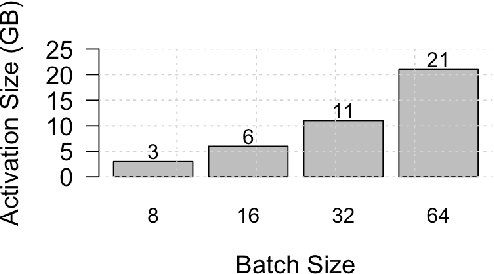
Existing approaches to train neural networks that use large images require to either crop or down-sample data during pre-processing, use small batch sizes, or split the model across devices mainly due to the prohibitively limited memory capacity available on GPUs and emerging accelerators. These techniques often lead to longer time to convergence or time to train (TTT), and in some cases, lower model accuracy. CPUs, on the other hand, can leverage significant amounts of memory. While much work has been done on parallelizing neural network training on multiple CPUs, little attention has been given to tune neural network training with large images on CPUs. In this work, we train a multi-scale convolutional neural network (M-CNN) to classify large biomedical images for high content screening in one hour. The ability to leverage large memory capacity on CPUs enables us to scale to larger batch sizes without having to crop or down-sample the input images. In conjunction with large batch sizes, we find a generalized methodology of linearly scaling of learning rate and train M-CNN to state-of-the-art (SOTA) accuracy of 99% within one hour. We achieve fast time to convergence using 128 two socket Intel Xeon 6148 processor nodes with 192GB DDR4 memory connected with 100Gbps Intel Omnipath architecture.
* 15 pages, 10 figures
Texture Bias Of CNNs Limits Few-Shot Classification Performance
Oct 18, 2019
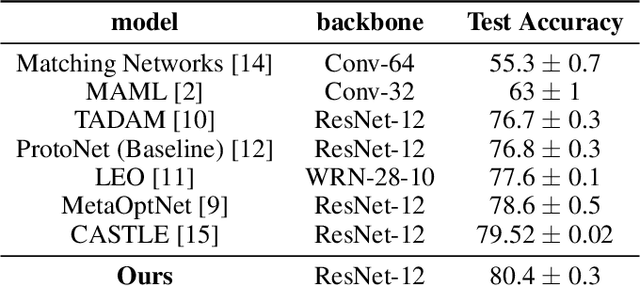

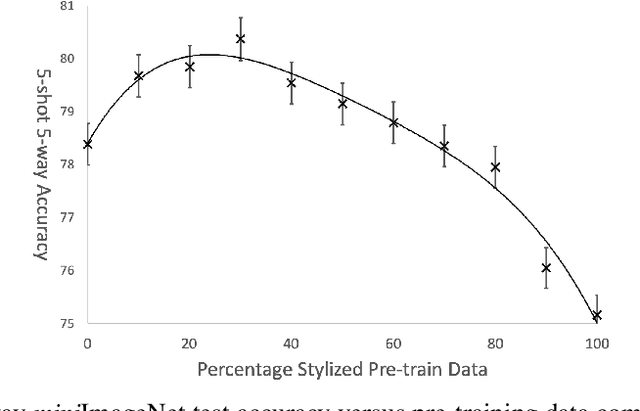
Accurate image classification given small amounts of labelled data (few-shot classification) remains an open problem in computer vision. In this work we examine how the known texture bias of Convolutional Neural Networks (CNNs) affects few-shot classification performance. Although texture bias can help in standard image classification, in this work we show it significantly harms few-shot classification performance. After correcting this bias we demonstrate state-of-the-art performance on the competitive miniImageNet task using a method far simpler than the current best performing few-shot learning approaches.
A bi-level view of inpainting - based image compression
May 09, 2014
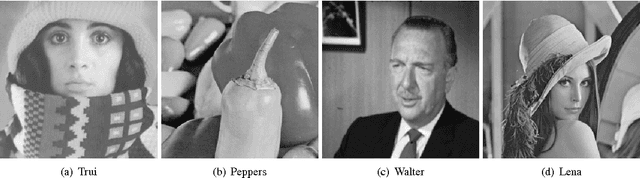

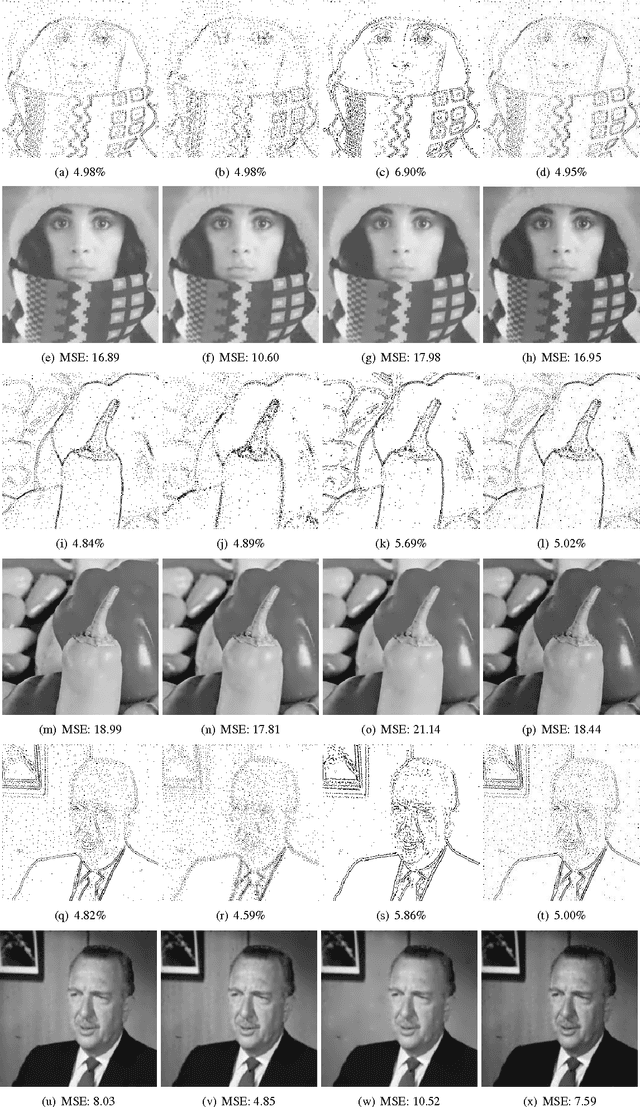
Inpainting based image compression approaches, especially linear and non-linear diffusion models, are an active research topic for lossy image compression. The major challenge in these compression models is to find a small set of descriptive supporting points, which allow for an accurate reconstruction of the original image. It turns out in practice that this is a challenging problem even for the simplest Laplacian interpolation model. In this paper, we revisit the Laplacian interpolation compression model and introduce two fast algorithms, namely successive preconditioning primal dual algorithm and the recently proposed iPiano algorithm, to solve this problem efficiently. Furthermore, we extend the Laplacian interpolation based compression model to a more general form, which is based on principles from bi-level optimization. We investigate two different variants of the Laplacian model, namely biharmonic interpolation and smoothed Total Variation regularization. Our numerical results show that significant improvements can be obtained from the biharmonic interpolation model, and it can recover an image with very high quality from only 5% pixels.
Efficient Region-Based Image Querying
Jun 23, 2010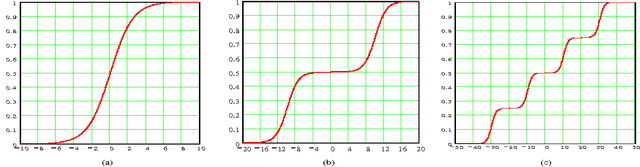
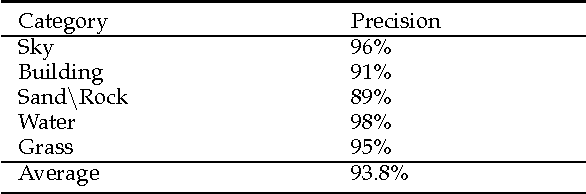

Retrieving images from large and varied repositories using visual contents has been one of major research items, but a challenging task in the image management community. In this paper we present an efficient approach for region-based image classification and retrieval using a fast multi-level neural network model. The advantages of this neural model in image classification and retrieval domain will be highlighted. The proposed approach accomplishes its goal in three main steps. First, with the help of a mean-shift based segmentation algorithm, significant regions of the image are isolated. Secondly, color and texture features of each region are extracted by using color moments and 2D wavelets decomposition technique. Thirdly the multi-level neural classifier is trained in order to classify each region in a given image into one of five predefined categories, i.e., "Sky", "Building", "SandnRock", "Grass" and "Water". Simulation results show that the proposed method is promising in terms of classification and retrieval accuracy results. These results compare favorably with the best published results obtained by other state-of-the-art image retrieval techniques.
* IEEE Publication Format, https://sites.google.com/site/journalofcomputing/
When Relation Networks meet GANs: Relation GANs with Triplet Loss
Feb 25, 2020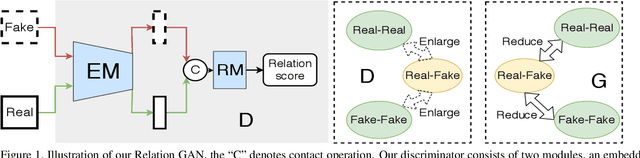
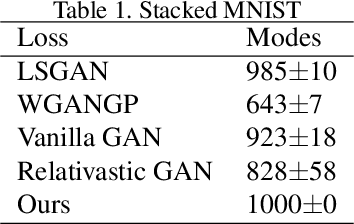
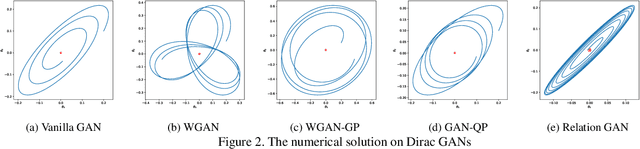
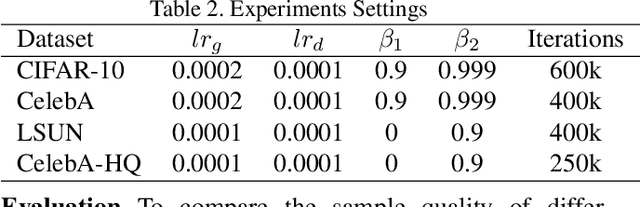
Though recent research has achieved remarkable progress in generating realistic images with generative adversarial networks (GANs), the lack of training stability is still a lingering concern of most GANs, especially on high-resolution inputs and complex datasets. Since the randomly generated distribution can hardly overlap with the real distribution, training GANs often suffers from the gradient vanishing problem. A number of approaches have been proposed to address this issue by constraining the discriminator's capabilities using empirical techniques, like weight clipping, gradient penalty, spectral normalization etc. In this paper, we provide a more principled approach as an alternative solution to this issue. Instead of training the discriminator to distinguish real and fake input samples, we investigate the relationship between paired samples by training the discriminator to separate paired samples from the same distribution and those from different distributions. To this end, we explore a relation network architecture for the discriminator and design a triplet loss which performs better generalization and stability. Extensive experiments on benchmark datasets show that the proposed relation discriminator and new loss can provide significant improvement on variable vision tasks including unconditional and conditional image generation and image translation. Our source codes are available on the website: \url{https://github.com/JosephineRabbit/Relation-GAN}