 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Optimizing Codes for Source Separation in Color Image Demosaicing and Compressive Video Recovery
Jul 11, 2017


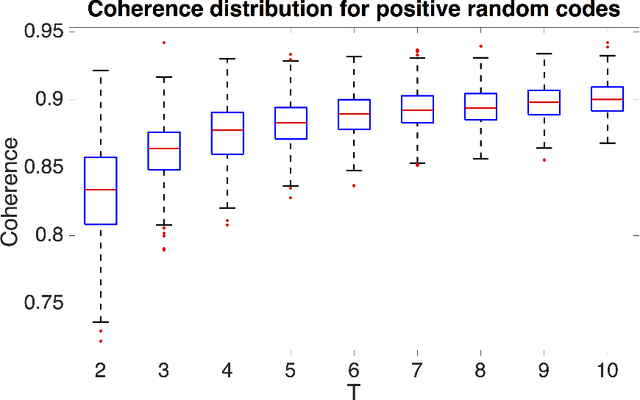
There exist several applications in image processing (eg: video compressed sensing [Hitomi, Y. et al, "Video from a single coded exposure photograph using a learned overcomplete dictionary"] and color image demosaicing [Moghadam, A. A. et al, "Compressive Framework for Demosaicing of Natural Images"]) which require separation of constituent images given measurements in the form of a coded superposition of those images. Physically practical code patterns in these applications are non-negative, systematically structured, and do not always obey the nice incoherence properties of other patterns such as Gaussian codes, which can adversely affect reconstruction performance. The contribution of this paper is to design code patterns for video compressed sensing and demosaicing by minimizing the mutual coherence of the matrix $\boldsymbol{\Phi \Psi}$ where $\boldsymbol{\Phi}$ represents the sensing matrix created from the code, and $\boldsymbol{\Psi}$ is the signal representation matrix. Our main contribution is that we explicitly take into account the special structure of those code patterns as required by these applications: (1)~non-negativity, (2)~block-diagonal nature, and (3)~circular shifting. In particular, the last property enables for accurate and seamless patch-wise reconstruction for some important compressed sensing architectures.
CAN: A Causal Adversarial Network for Learning Observational and Interventional Distributions
Aug 26, 2020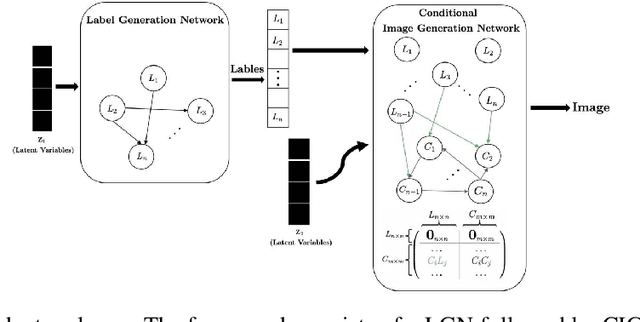
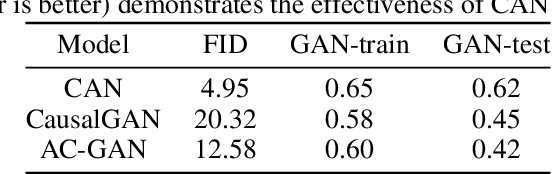


We propose a generative Causal Adversarial Network (CAN) for learning and sampling from observational (conditional) and interventional distributions. In contrast to the existing CausalGAN which requires the causal graph for the labels to be given, our proposed framework learns the causal relations from the data and generates samples accordingly. In addition to the relationships between labels, our model also learns the label-pixel and pixel-pixel dependencies and incorporate them in sample generation. The proposed CAN comprises a two-fold process namely Label Generation Network (LGN) and Conditional Image Generation Network (CIGN). The LGN is a novel GAN architecture which learns and samples from the causal graph over multi-categorical labels. The sampled labels are then fed to CIGN, a new conditional GAN architecture, which learns the relationships amongst labels and pixels and pixels themselves and generates samples based on them. This framework additionally provides an intervention mechanism which enables the model to generate samples from interventional distributions. We quantitatively and qualitatively assess the performance of CAN and empirically show that our model is able to generate both interventional and observational samples without having access to the causal graph for the application of face generation on CelebA data.
Lifespan Age Transformation Synthesis
Mar 21, 2020

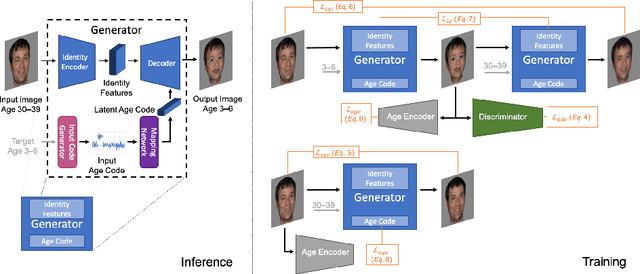
We address the problem of single photo age progression and regression-the prediction of how a person might look in the future, or how they looked in the past. Most existing aging methods are limited to changing the texture, overlooking transformations in head shape that occur during the human aging and growth process. This limits the applicability of previous methods to aging of adults to slightly older adults, and application of those methods to photos of children does not produce quality results. We propose a novel multi-domain image-to-image generative adversarial network architecture, whose learned latent space models a continuous bi-directional aging process. The network is trained on the FFHQ dataset, which we labeled for ages, gender, and semantic segmentation. Fixed age classes are used as anchors to approximate continuous age transformation. Our framework can predict a full head portrait for ages 0-70 from a single photo, modifying both texture and shape of the head. We demonstrate results on a wide variety of photos and datasets, and show significant improvement over the state of the art.
Spectral-Spatial Classification of Hyperspectral Image Using Autoencoders
Nov 09, 2015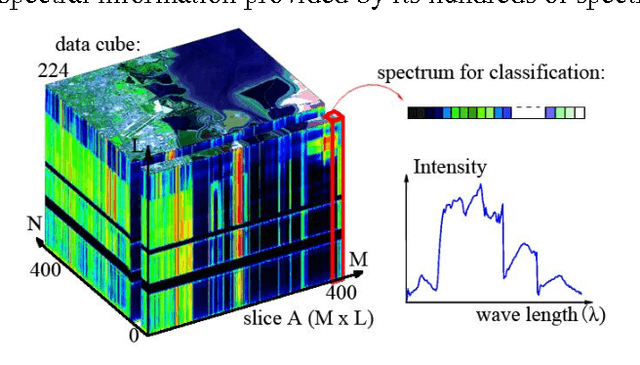
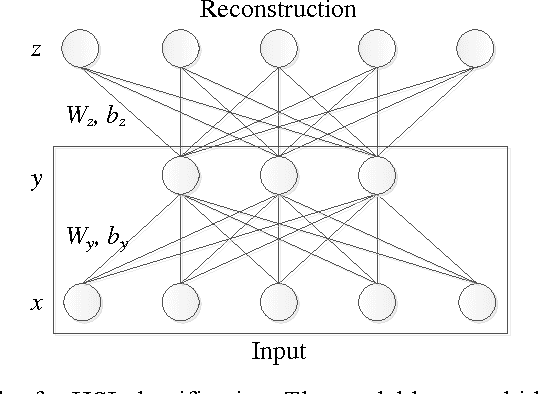
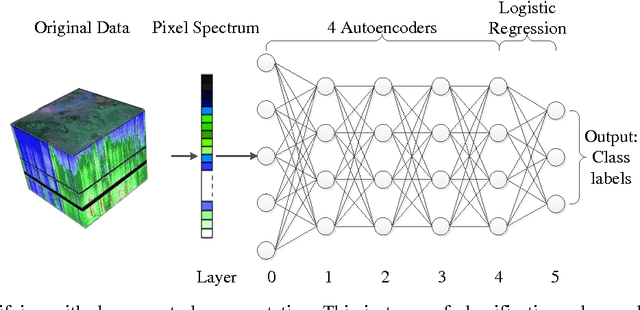
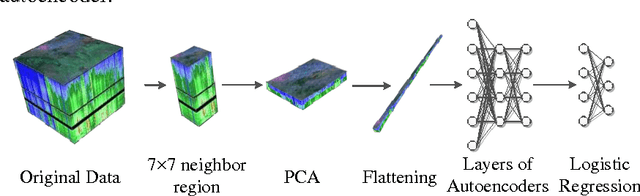
Hyperspectral image (HSI) classification is a hot topic in the remote sensing community. This paper proposes a new framework of spectral-spatial feature extraction for HSI classification, in which for the first time the concept of deep learning is introduced. Specifically, the model of autoencoder is exploited in our framework to extract various kinds of features. First we verify the eligibility of autoencoder by following classical spectral information based classification and use autoencoders with different depth to classify hyperspectral image. Further in the proposed framework, we combine PCA on spectral dimension and autoencoder on the other two spatial dimensions to extract spectral-spatial information for classification. The experimental results show that this framework achieves the highest classification accuracy among all methods, and outperforms classical classifiers such as SVM and PCA-based SVM.
Dynamic Federated Learning Model for Identifying Adversarial Clients
Jul 29, 2020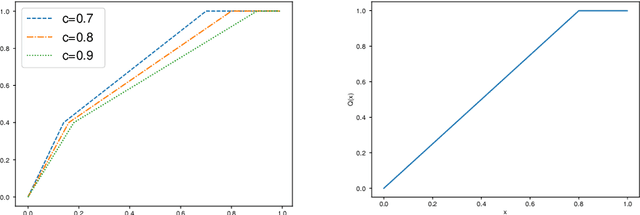
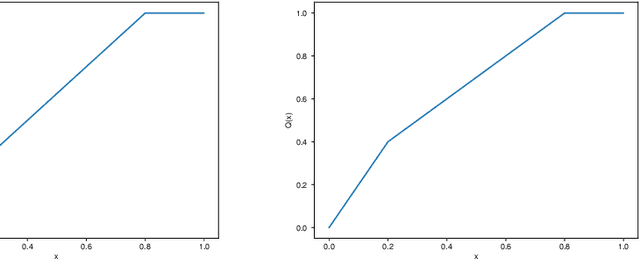
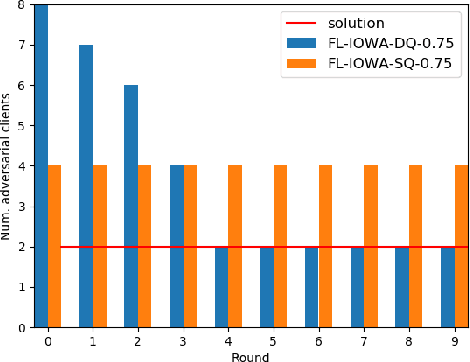
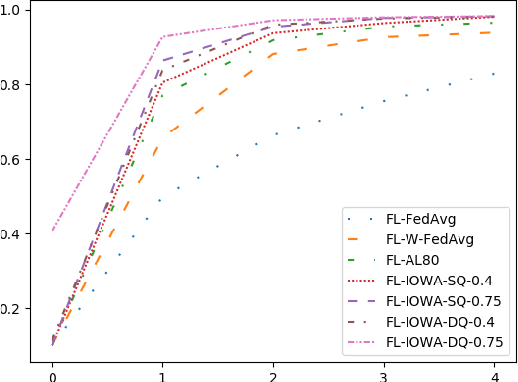
Federated learning, as a distributed learning that conducts the training on the local devices without accessing to the training data, is vulnerable to dirty-label data poisoning adversarial attacks. We claim that the federated learning model has to avoid those kind of adversarial attacks through filtering out the clients that manipulate the local data. We propose a dynamic federated learning model that dynamically discards those adversarial clients, which allows to prevent the corruption of the global learning model. We evaluate the dynamic discarding of adversarial clients deploying a deep learning classification model in a federated learning setting, and using the EMNIST Digits and Fashion MNIST image classification datasets. Likewise, we analyse the capacity of detecting clients with poor data distribution and reducing the number of rounds of learning by selecting the clients to aggregate. The results show that the dynamic selection of the clients to aggregate enhances the performance of the global learning model, discards the adversarial and poor clients and reduces the rounds of learning.
3D Path Planning from a Single 2D Fluoroscopic Image for Robot Assisted Fenestrated Endovascular Aortic Repair
Sep 16, 2018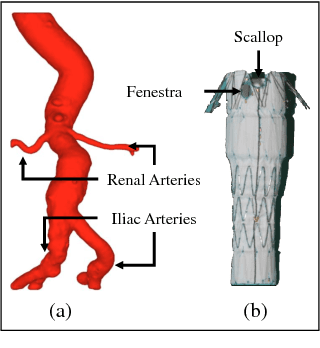
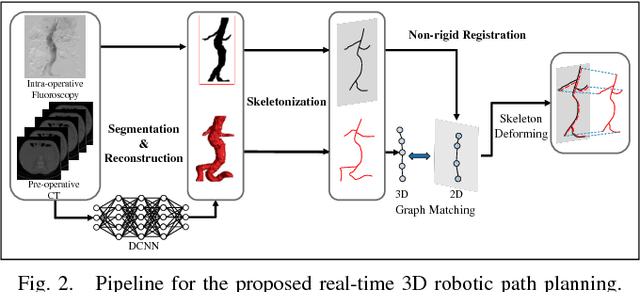

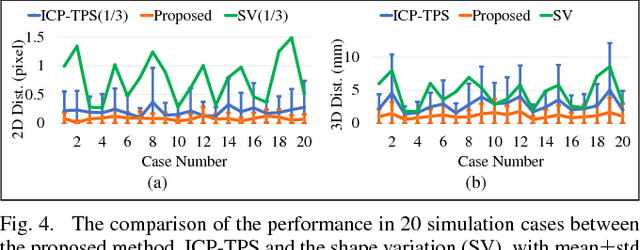
The current standard of intra-operative navigation during Fenestrated Endovascular Aortic Repair (FEVAR) calls for need of 3D alignments between inserted devices and aortic branches. The navigation commonly via 2D fluoroscopic images, lacks anatomical information, resulting in longer operation hours and radiation exposure. In this paper, a framework for real-time 3D robotic path planning from a single 2D fluoroscopic image of Abdominal Aortic Aneurysm (AAA) is introduced. A graph matching method is proposed to establish the correspondence between the 3D preoperative and 2D intra-operative AAA skeletons, and then the two skeletons are registered by skeleton deformation and regularization in respect to skeleton length and smoothness. Furthermore, deep learning was used to segment 3D pre-operative AAA from Computed Tomography (CT) scans to facilitate the framework automation. Simulation, phantom and patient AAA data sets have been used to validate the proposed framework. 3D distance error of 2mm was achieved in the phantom setup. Performance advantages were also achieved in terms of accuracy, robustness and time-efficiency. All the code will be open source.
Approximate Manifold Defense Against Multiple Adversarial Perturbations
Apr 05, 2020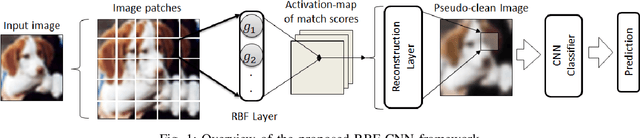



Existing defenses against adversarial attacks are typically tailored to a specific perturbation type. Using adversarial training to defend against multiple types of perturbation requires expensive adversarial examples from different perturbation types at each training step. In contrast, manifold-based defense incorporates a generative network to project an input sample onto the clean data manifold. This approach eliminates the need to generate expensive adversarial examples while achieving robustness against multiple perturbation types. However, the success of this approach relies on whether the generative network can capture the complete clean data manifold, which remains an open problem for complex input domain. In this work, we devise an approximate manifold defense mechanism, called RBF-CNN, for image classification. Instead of capturing the complete data manifold, we use an RBF layer to learn the density of small image patches. RBF-CNN also utilizes a reconstruction layer that mitigates any minor adversarial perturbations. Further, incorporating our proposed reconstruction process for training improves the adversarial robustness of our RBF-CNN models. Experiment results on MNIST and CIFAR-10 datasets indicate that RBF-CNN offers robustness for multiple perturbations without the need for expensive adversarial training.
Effective Image Retrieval via Multilinear Multi-index Fusion
Sep 27, 2017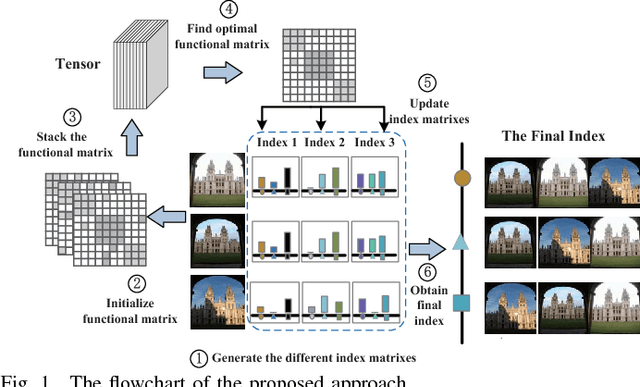
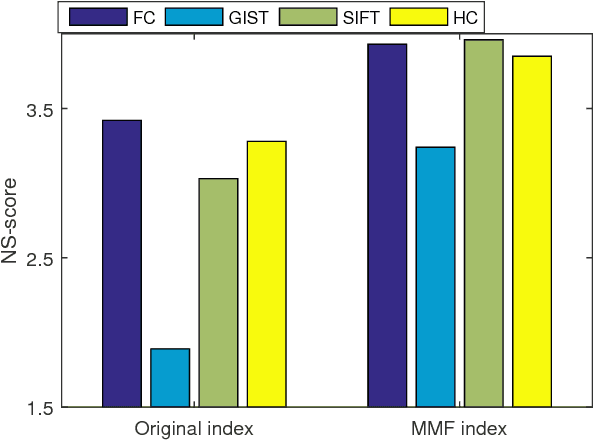
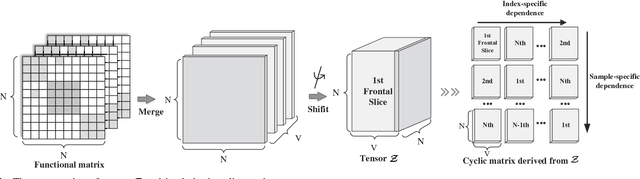
Multi-index fusion has demonstrated impressive performances in retrieval task by integrating different visual representations in a unified framework. However, previous works mainly consider propagating similarities via neighbor structure, ignoring the high order information among different visual representations. In this paper, we propose a new multi-index fusion scheme for image retrieval. By formulating this procedure as a multilinear based optimization problem, the complementary information hidden in different indexes can be explored more thoroughly. Specially, we first build our multiple indexes from various visual representations. Then a so-called index-specific functional matrix, which aims to propagate similarities, is introduced for updating the original index. The functional matrices are then optimized in a unified tensor space to achieve a refinement, such that the relevant images can be pushed more closer. The optimization problem can be efficiently solved by the augmented Lagrangian method with theoretical convergence guarantee. Unlike the traditional multi-index fusion scheme, our approach embeds the multi-index subspace structure into the new indexes with sparse constraint, thus it has little additional memory consumption in online query stage. Experimental evaluation on three benchmark datasets reveals that the proposed approach achieves the state-of-the-art performance, i.e., N-score 3.94 on UKBench, mAP 94.1\% on Holiday and 62.39\% on Market-1501.
Human-Object Interaction Detection:A Quick Survey and Examination of Methods
Sep 27, 2020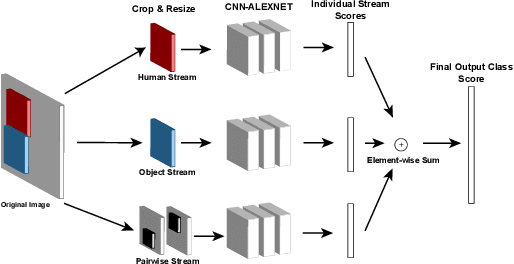
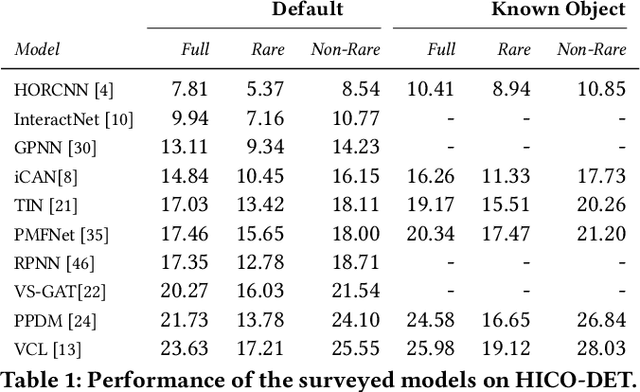
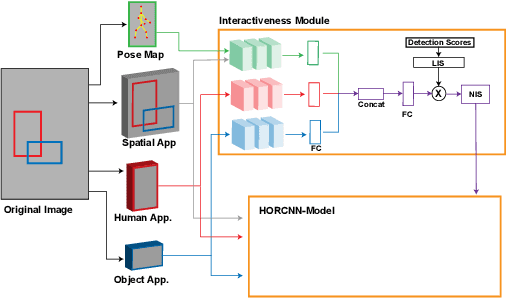

Human-object interaction detection is a relatively new task in the world of computer vision and visual semantic information extraction. With the goal of machines identifying interactions that humans perform on objects, there are many real-world use cases for the research in this field. To our knowledge, this is the first general survey of the state-of-the-art and milestone works in this field. We provide a basic survey of the developments in the field of human-object interaction detection. Many works in this field use multi-stream convolutional neural network architectures, which combine features from multiple sources in the input image. Most commonly these are the humans and objects in question, as well as the spatial quality of the two. As far as we are aware, there have not been in-depth studies performed that look into the performance of each component individually. In order to provide insight to future researchers, we perform an individualized study that examines the performance of each component of a multi-stream convolutional neural network architecture for human-object interaction detection. Specifically, we examine the HORCNN architecture as it is a foundational work in the field. In addition, we provide an in-depth look at the HICO-DET dataset, a popular benchmark in the field of human-object interaction detection. Code and papers can be found at https://github.com/SHI-Labs/Human-Object-Interaction-Detection.
Between Subjectivity and Imposition: Power Dynamics in Data Annotation for Computer Vision
Jul 29, 2020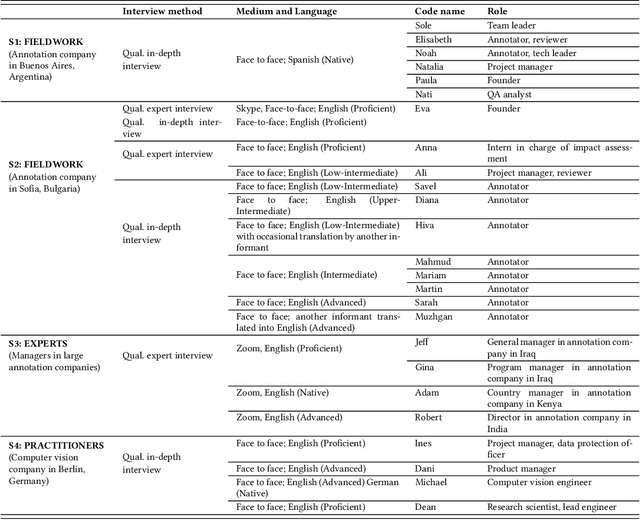
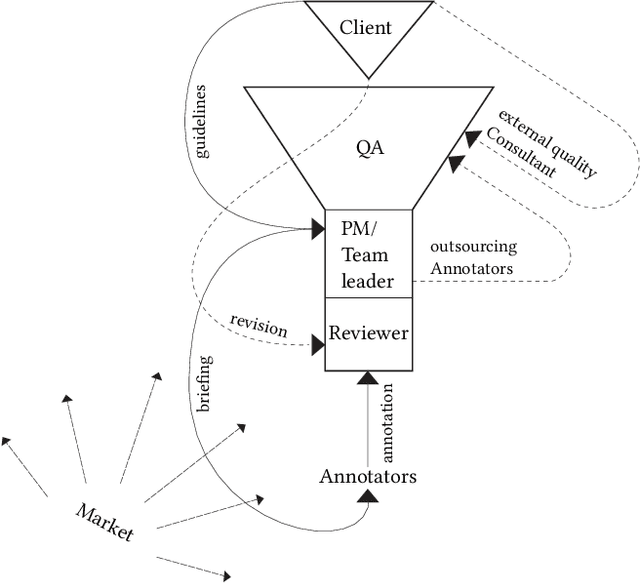
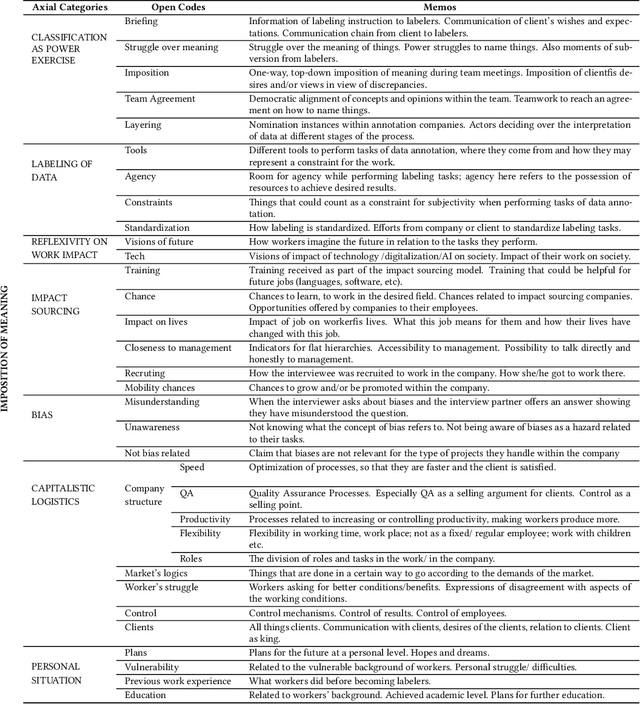
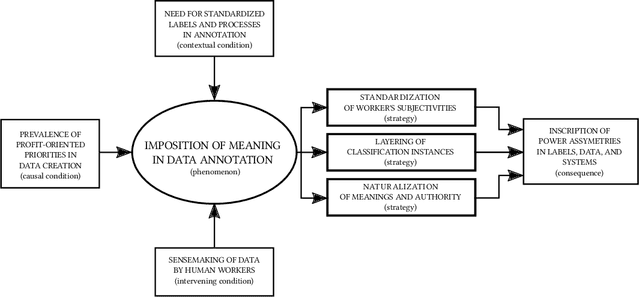
The interpretation of data is fundamental to machine learning. This paper investigates practices of image data annotation as performed in industrial contexts. We define data annotation as a sense-making practice, where annotators assign meaning to data through the use of labels. Previous human-centered investigations have largely focused on annotators subjectivity as a major cause for biased labels. We propose a wider view on this issue: guided by constructivist grounded theory, we conducted several weeks of fieldwork at two annotation companies. We analyzed which structures, power relations, and naturalized impositions shape the interpretation of data. Our results show that the work of annotators is profoundly informed by the interests, values, and priorities of other actors above their station. Arbitrary classifications are vertically imposed on annotators, and through them, on data. This imposition is largely naturalized. Assigning meaning to data is often presented as a technical matter. This paper shows it is, in fact, an exercise of power with multiple implications for individuals and society.