 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Patch augmentation: Towards efficient decision boundaries for neural networks
Nov 25, 2019
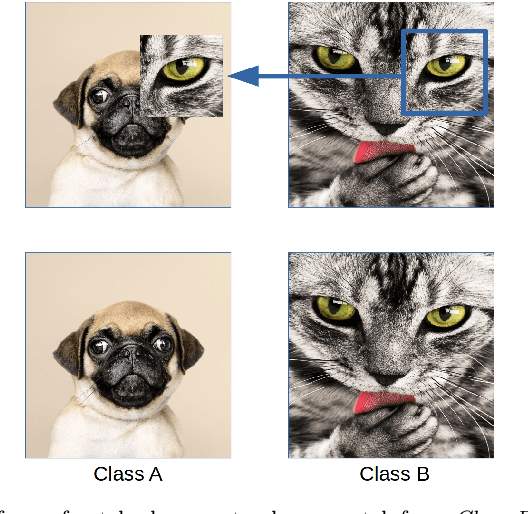


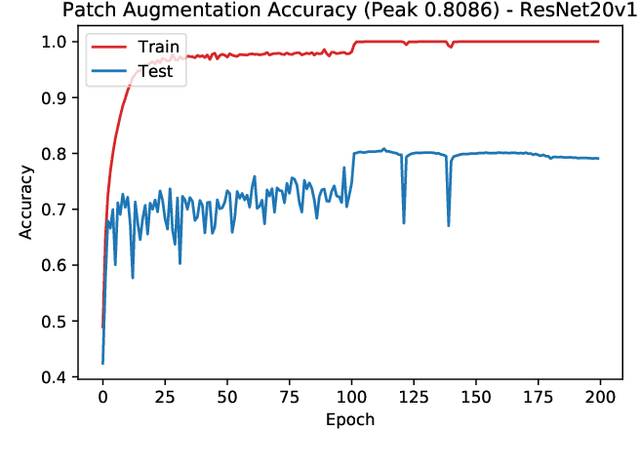
In this paper we propose a new augmentation technique, called patch augmentation, that, in our experiments, improves model accuracy and makes networks more robust to adversarial attacks. In brief, this data-independent approach creates new image data based on image/label pairs, where a patch from one of the two images in the pair is superimposed on to the other image, creating a new augmented sample. The new image's label is a linear combination of the image pair's corresponding labels. Initial experiments show a several percentage point increase in accuracy on CIFAR-10, from a baseline of approximately 81% to 89%. CIFAR-100 sees larger improvements still, from a baseline of 52% to 68% accuracy. Networks trained using patch augmentation are also more robust to adversarial attacks, which we demonstrate using the Fast Gradient Sign Method.
Survey on 3D face reconstruction from uncalibrated images
Nov 11, 2020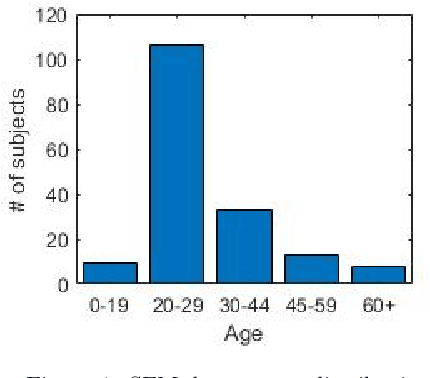
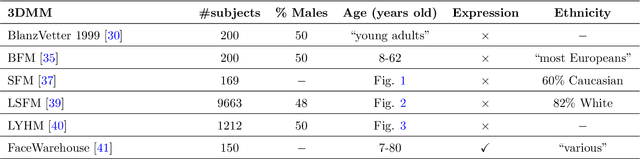
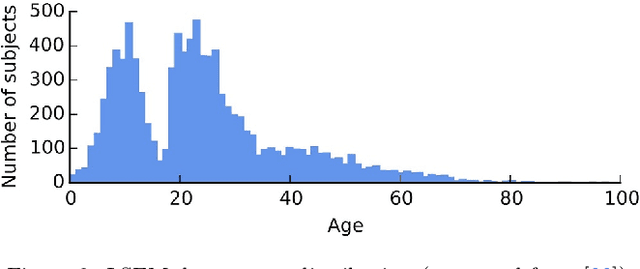
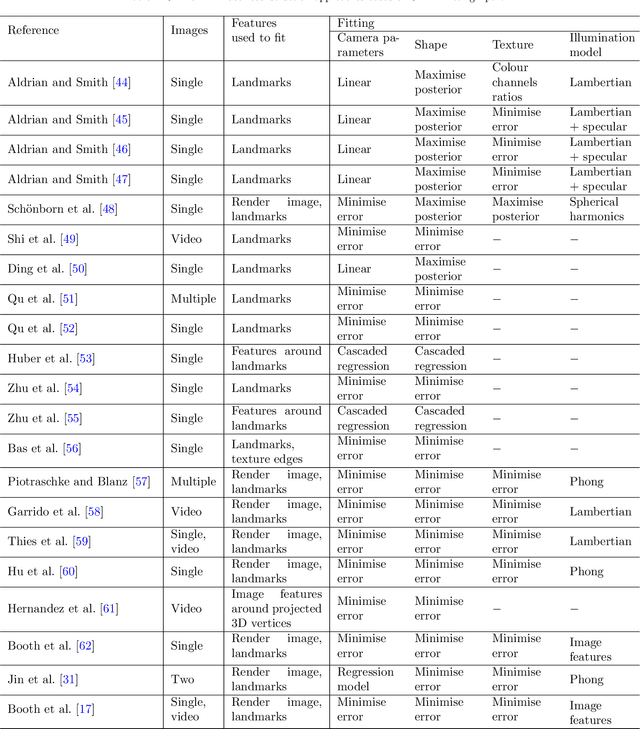
Recently, a lot of attention has been focused on the incorporation of 3D data into face analysis and its applications. Despite providing a more accurate representation of the face, 3D face images are more complex to acquire than 2D pictures. As a consequence, great effort has been invested in developing systems that reconstruct 3D faces from an uncalibrated 2D image. However, the 3D-from-2D face reconstruction problem is ill-posed, thus prior knowledge is needed to restrict the solutions space. In this work, we review 3D face reconstruction methods in the last decade, focusing on those that only use 2D pictures captured under uncontrolled conditions. We present a classification of the proposed methods based on the technique used to add prior knowledge, considering three main strategies, namely, statistical model fitting, photometry, and deep learning, and reviewing each of them separately. In addition, given the relevance of statistical 3D facial models as prior knowledge, we explain the construction procedure and provide a comprehensive list of the publicly available 3D facial models. After the exhaustive study of 3D-from-2D face reconstruction approaches, we observe that the deep learning strategy is rapidly growing since the last few years, matching its extension to that of the widespread statistical model fitting. Unlike the other two strategies, photometry-based methods have decreased in number since the required strong assumptions cause the reconstructions to be of more limited quality than those resulting from model fitting and deep learning methods. The review also identifies current gaps and suggests avenues for future research.
Robust Noise Filtering in Image Sequences
Apr 17, 2013
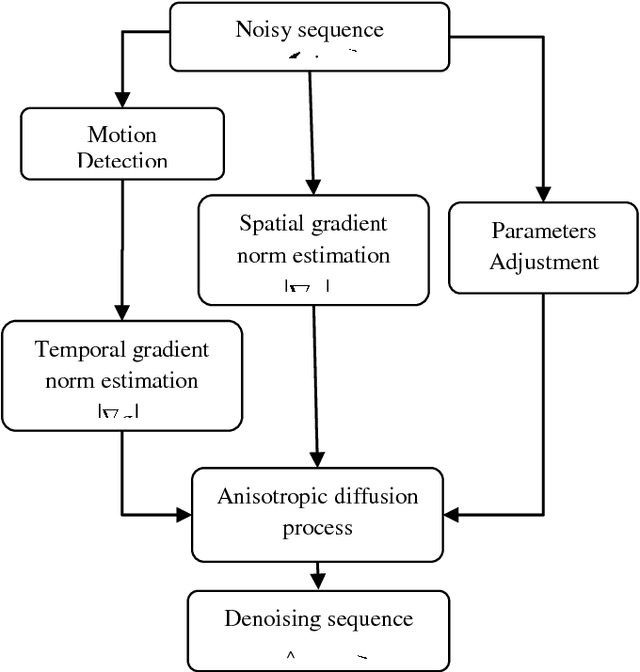
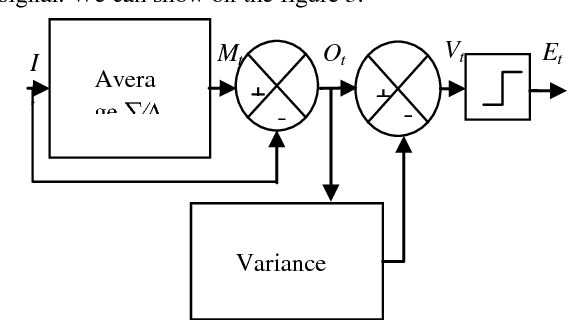
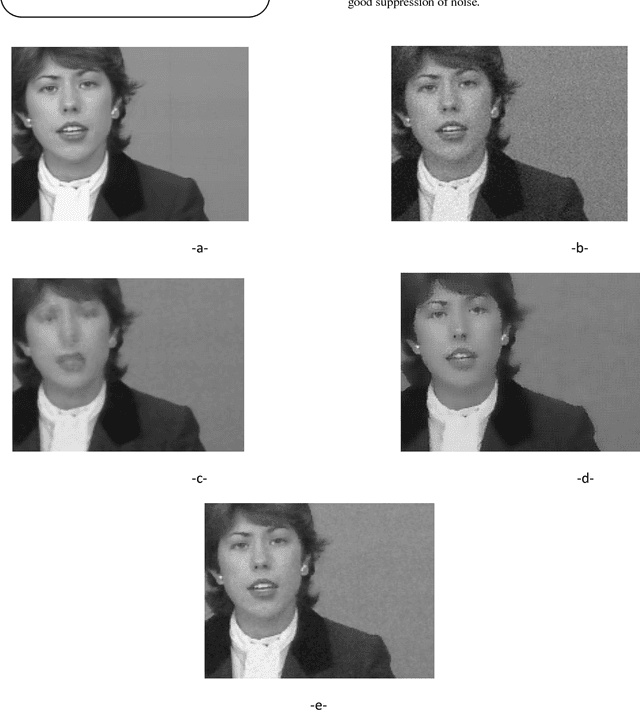
Image sequences filtering have recently become a very important technical problem especially with the advent of new technology in multimedia and video systems applications. Often image sequences are corrupted by some amount of noise introduced by the image sensor and therefore inherently present in the imaging process. The main problem in the image sequences is how to deal with spatio-temporal and non stationary signals. In this paper, we propose a robust method for noise removal of image sequence based on coupled spatial and temporal anisotropic diffusion. The idea is to achieve an adaptive smoothing in both spatial and temporal directions, by solving a nonlinear diffusion equation. This allows removing noise while preserving all spatial and temporal discontinuities
* 5 pages
Trainable Nonlinear Reaction Diffusion: A Flexible Framework for Fast and Effective Image Restoration
Aug 20, 2016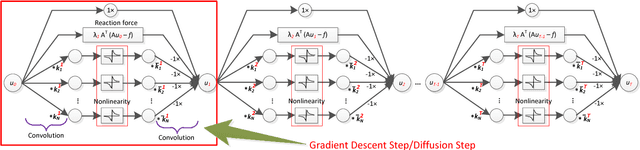
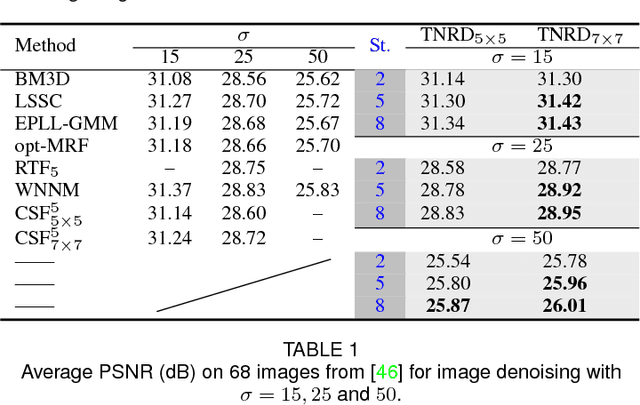
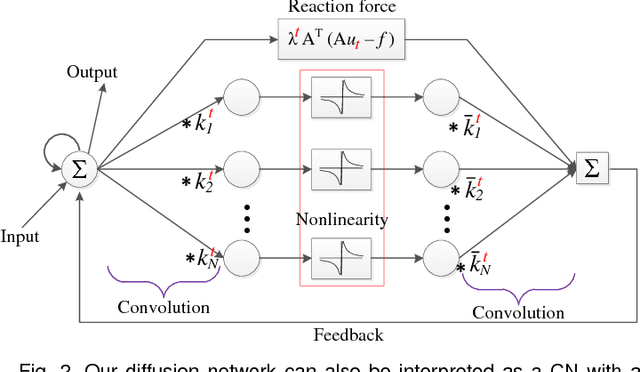
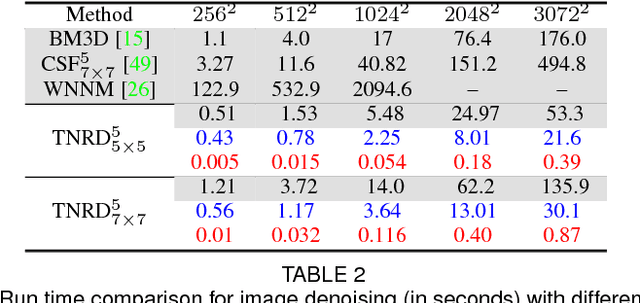
Image restoration is a long-standing problem in low-level computer vision with many interesting applications. We describe a flexible learning framework based on the concept of nonlinear reaction diffusion models for various image restoration problems. By embodying recent improvements in nonlinear diffusion models, we propose a dynamic nonlinear reaction diffusion model with time-dependent parameters (\ie, linear filters and influence functions). In contrast to previous nonlinear diffusion models, all the parameters, including the filters and the influence functions, are simultaneously learned from training data through a loss based approach. We call this approach TNRD -- \textit{Trainable Nonlinear Reaction Diffusion}. The TNRD approach is applicable for a variety of image restoration tasks by incorporating appropriate reaction force. We demonstrate its capabilities with three representative applications, Gaussian image denoising, single image super resolution and JPEG deblocking. Experiments show that our trained nonlinear diffusion models largely benefit from the training of the parameters and finally lead to the best reported performance on common test datasets for the tested applications. Our trained models preserve the structural simplicity of diffusion models and take only a small number of diffusion steps, thus are highly efficient. Moreover, they are also well-suited for parallel computation on GPUs, which makes the inference procedure extremely fast.
AdaBelief Optimizer: Adapting Stepsizes by the Belief in Observed Gradients
Oct 24, 2020
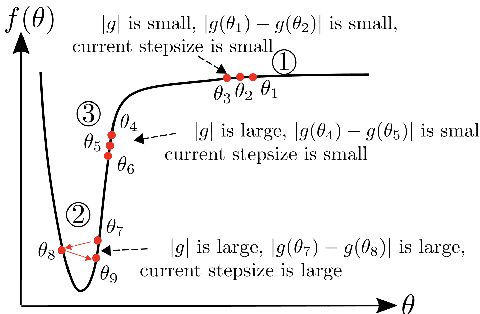
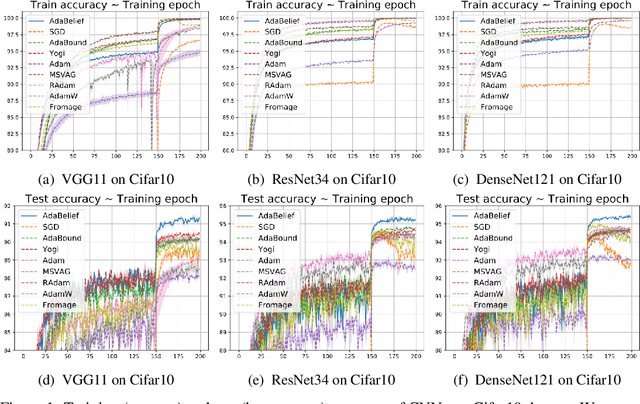

Most popular optimizers for deep learning can be broadly categorized as adaptive methods (e.g. Adam) and accelerated schemes (e.g. stochastic gradient descent (SGD) with momentum). For many models such as convolutional neural networks (CNNs), adaptive methods typically converge faster but generalize worse compared to SGD; for complex settings such as generative adversarial networks (GANs), adaptive methods are typically the default because of their stability.We propose AdaBelief to simultaneously achieve three goals: fast convergence as in adaptive methods, good generalization as in SGD, and training stability. The intuition for AdaBelief is to adapt the stepsize according to the "belief" in the current gradient direction. Viewing the exponential moving average (EMA) of the noisy gradient as the prediction of the gradient at the next time step, if the observed gradient greatly deviates from the prediction, we distrust the current observation and take a small step; if the observed gradient is close to the prediction, we trust it and take a large step. We validate AdaBelief in extensive experiments, showing that it outperforms other methods with fast convergence and high accuracy on image classification and language modeling. Specifically, on ImageNet, AdaBelief achieves comparable accuracy to SGD. Furthermore, in the training of a GAN on Cifar10, AdaBelief demonstrates high stability and improves the quality of generated samples compared to a well-tuned Adam optimizer. Code is available at https://github.com/juntang-zhuang/Adabelief-Optimizer
DeepRepair: Style-Guided Repairing for DNNs in the Real-world Operational Environment
Nov 19, 2020
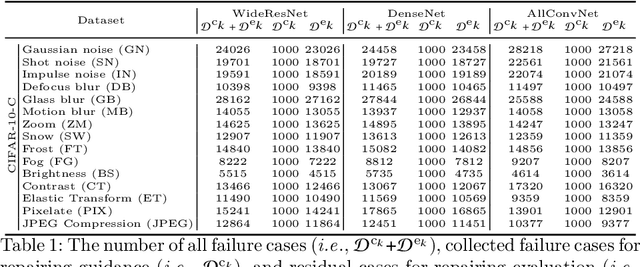
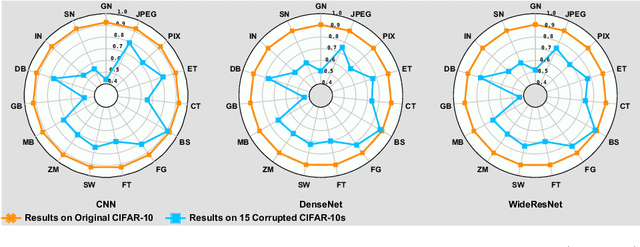
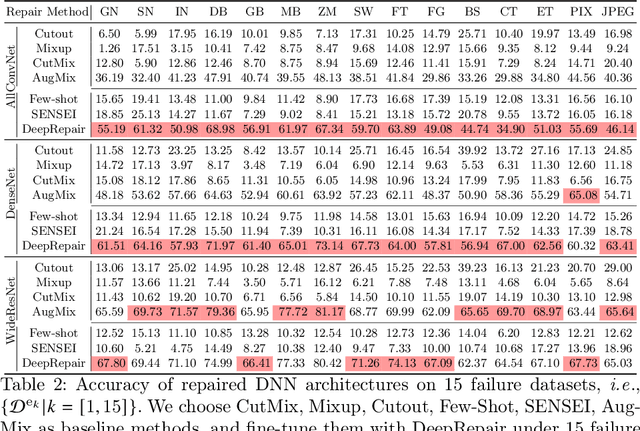
Deep neural networks (DNNs) are being widely applied for various real-world applications across domains due to their high performance (e.g., high accuracy on image classification). Nevertheless, a well-trained DNN after deployment could oftentimes raise errors during practical use in the operational environment due to the mismatching between distributions of the training dataset and the potential unknown noise factors in the operational environment, e.g., weather, blur, noise etc. Hence, it poses a rather important problem for the DNNs' real-world applications: how to repair the deployed DNNs for correcting the failure samples (i.e., incorrect prediction) under the deployed operational environment while not harming their capability of handling normal or clean data. The number of failure samples we can collect in practice, caused by the noise factors in the operational environment, is often limited. Therefore, It is rather challenging how to repair more similar failures based on the limited failure samples we can collect. In this paper, we propose a style-guided data augmentation for repairing DNN in the operational environment. We propose a style transfer method to learn and introduce the unknown failure patterns within the failure data into the training data via data augmentation. Moreover, we further propose the clustering-based failure data generation for much more effective style-guided data augmentation. We conduct a large-scale evaluation with fifteen degradation factors that may happen in the real world and compare with four state-of-the-art data augmentation methods and two DNN repairing methods, demonstrating that our method can significantly enhance the deployed DNNs on the corrupted data in the operational environment, and with even better accuracy on clean datasets.
Visual Camera Re-Localization from RGB and RGB-D Images Using DSAC
Feb 27, 2020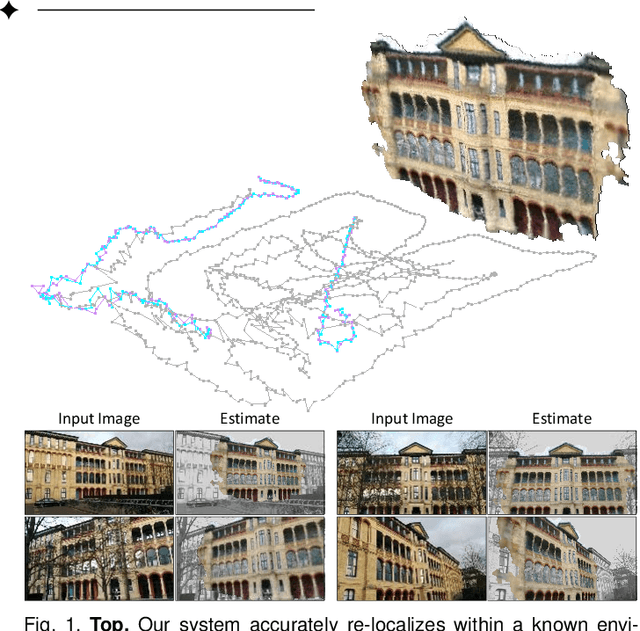

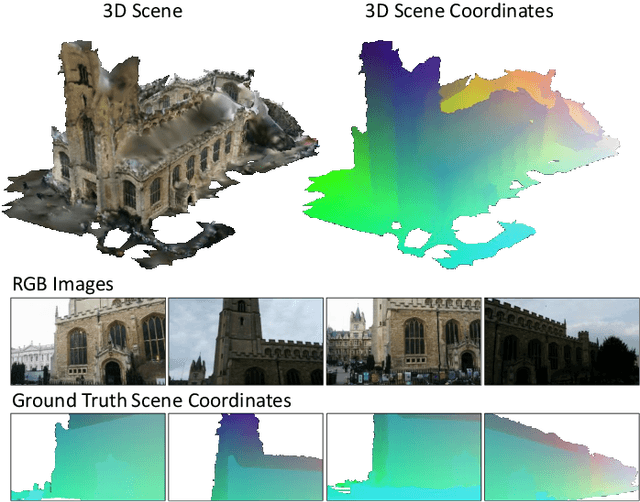
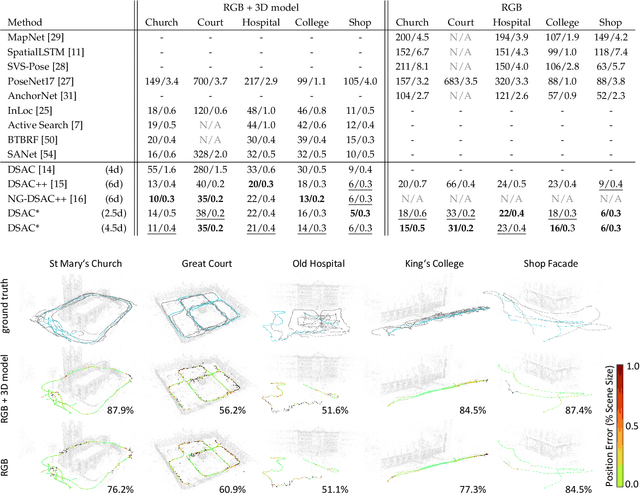
We describe a learning-based system that estimates the camera position and orientation from a single input image relative to a known environment. The system is flexible w.r.t. the amount of information available at test and at training time, catering to different applications. Input images can be RGB-D or RGB, and a 3D model of the environment can be utilized for training but is not necessary. In the minimal case, our system requires only RGB images and ground truth poses at training time, and it requires only a single RGB image at test time. The framework consists of a deep neural network and fully differentiable pose optimization. The neural network predicts so called scene coordinates, i.e. dense correspondences between the input image and 3D scene space of the environment. The pose optimization implements robust fitting of pose parameters using differentiable RANSAC (DSAC) to facilitate end-to-end training. The system, an extension of DSAC++ and referred to as DSAC*, achieves state-of-the-art accuracy an various public datasets for RGB-based re-localization, and competitive accuracy for RGB-D based re-localization.
Detection as Regression: Certified Object Detection by Median Smoothing
Jul 07, 2020
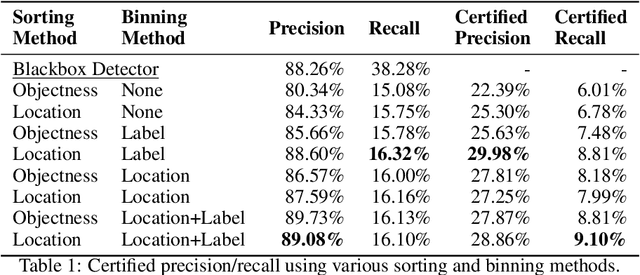

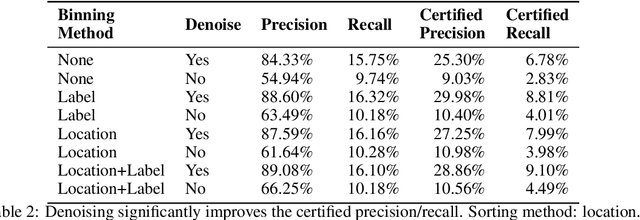
Despite the vulnerability of object detectors to adversarial attacks, very few defenses are known to date. While adversarial training can improve the empirical robustness of image classifiers, a direct extension to object detection is very expensive. This work is motivated by recent progress on certified classification by randomized smoothing. We start by presenting a reduction from object detection to a regression problem. Then, to enable certified regression, where standard mean smoothing fails, we propose median smoothing, which is of independent interest. We obtain the first model-agnostic, training-free, and certified defense for object detection against $\ell_2$-bounded attacks.
Explaining Clinical Decision Support Systems in Medical Imaging using Cycle-Consistent Activation Maximization
Oct 13, 2020
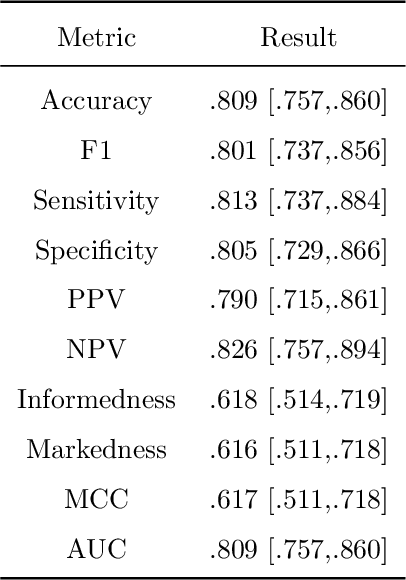
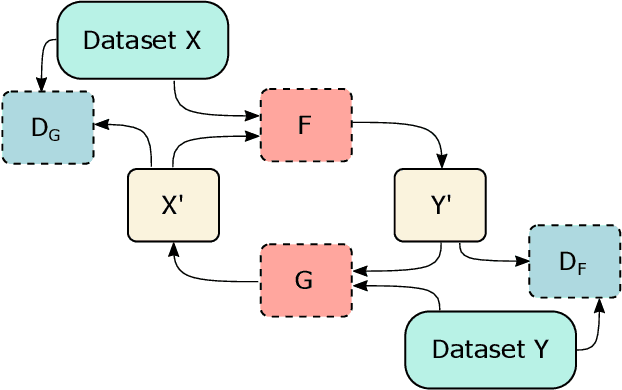
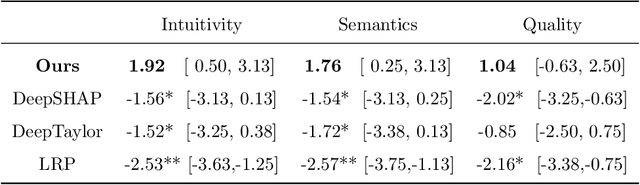
Clinical decision support using deep neural networks has become a topic of steadily growing interest. While recent work has repeatedly demonstrated that deep learning offers major advantages for medical image classification over traditional methods, clinicians are often hesitant to adopt the technology because its underlying decision-making process is considered to be intransparent and difficult to comprehend. In recent years, this has been addressed by a variety of approaches that have successfully contributed to providing deeper insight. Most notably, additive feature attribution methods are able to propagate decisions back into the input space by creating a saliency map which allows the practitioner to "see what the network sees." However, the quality of the generated maps can become poor and the images noisy if only limited data is available - a typical scenario in clinical contexts. We propose a novel decision explanation scheme based on CycleGAN activation maximization which generates high-quality visualizations of classifier decisions even in smaller data sets. We conducted a user study in which these visualizations significantly outperformed existing methods on the LIDC dataset for lung lesion malignancy classification. With our approach we make a significant contribution to a better understanding of clinical decision support systems based on deep neural networks and thus aim to foster overall clinical acceptance.
Beyond Gauss: Image-Set Matching on the Riemannian Manifold of PDFs
Jul 31, 2015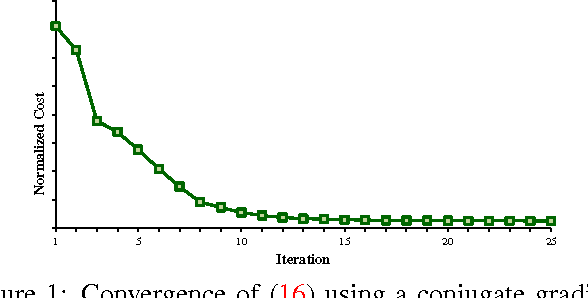
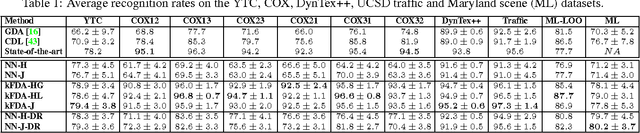

State-of-the-art image-set matching techniques typically implicitly model each image-set with a Gaussian distribution. Here, we propose to go beyond these representations and model image-sets as probability distribution functions (PDFs) using kernel density estimators. To compare and match image-sets, we exploit Csiszar f-divergences, which bear strong connections to the geodesic distance defined on the space of PDFs, i.e., the statistical manifold. Furthermore, we introduce valid positive definite kernels on the statistical manifolds, which let us make use of more powerful classification schemes to match image-sets. Finally, we introduce a supervised dimensionality reduction technique that learns a latent space where f-divergences reflect the class labels of the data. Our experiments on diverse problems, such as video-based face recognition and dynamic texture classification, evidence the benefits of our approach over the state-of-the-art image-set matching methods.