 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adversarial Training against Location-Optimized Adversarial Patches
May 05, 2020

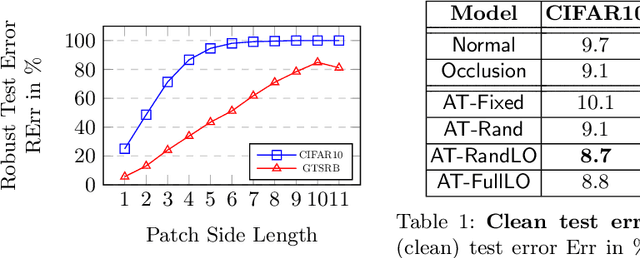

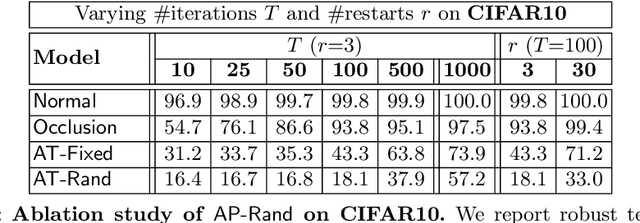
Deep neural networks have been shown to be susceptible to adversarial examples -- small, imperceptible changes constructed to cause mis-classification in otherwise highly accurate image classifiers. As a practical alternative, recent work proposed so-called adversarial patches: clearly visible, but adversarially crafted rectangular patches in images. These patches can easily be printed and applied in the physical world. While defenses against imperceptible adversarial examples have been studied extensively, robustness against adversarial patches is poorly understood. In this work, we first devise a practical approach to obtain adversarial patches while actively optimizing their location within the image. Then, we apply adversarial training on these location-optimized adversarial patches and demonstrate significantly improved robustness on CIFAR10 and GTSRB. Additionally, in contrast to adversarial training on imperceptible adversarial examples, our adversarial patch training does not reduce accuracy.
CAS-CNN: A Deep Convolutional Neural Network for Image Compression Artifact Suppression
Nov 22, 2016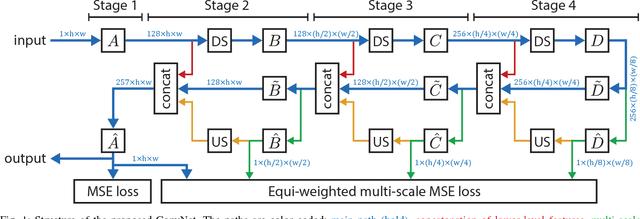
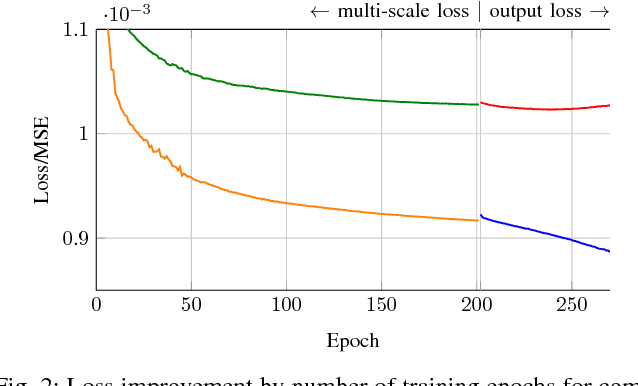
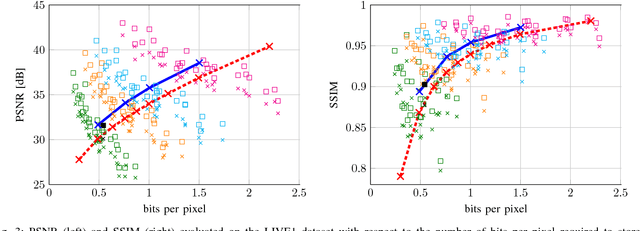
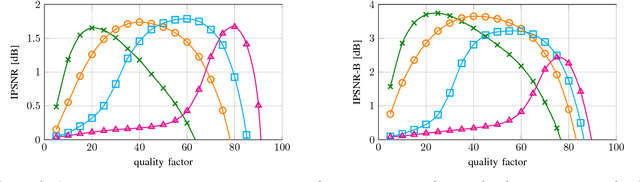
Lossy image compression algorithms are pervasively used to reduce the size of images transmitted over the web and recorded on data storage media. However, we pay for their high compression rate with visual artifacts degrading the user experience. Deep convolutional neural networks have become a widespread tool to address high-level computer vision tasks very successfully. Recently, they have found their way into the areas of low-level computer vision and image processing to solve regression problems mostly with relatively shallow networks. We present a novel 12-layer deep convolutional network for image compression artifact suppression with hierarchical skip connections and a multi-scale loss function. We achieve a boost of up to 1.79 dB in PSNR over ordinary JPEG and an improvement of up to 0.36 dB over the best previous ConvNet result. We show that a network trained for a specific quality factor (QF) is resilient to the QF used to compress the input image - a single network trained for QF 60 provides a PSNR gain of more than 1.5 dB over the wide QF range from 40 to 76.
Recurrent convolutional neural network for the surrogate modeling of subsurface flow simulation
Oct 08, 2020
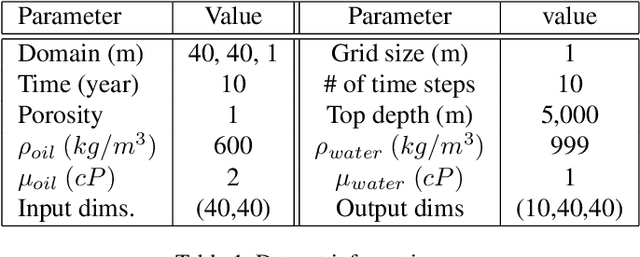
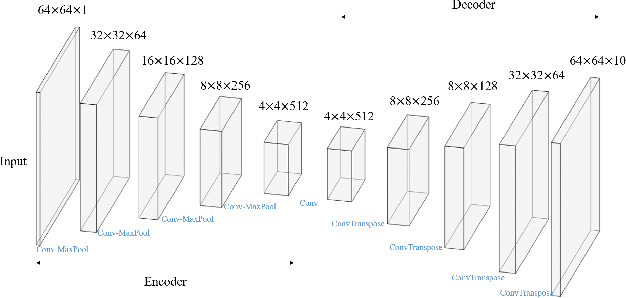
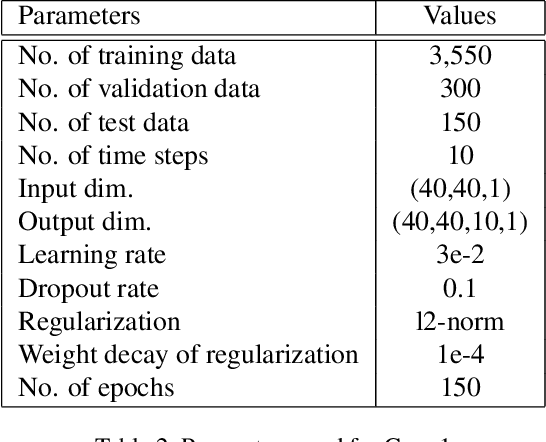
The quantification of uncertainty on fluid flow in porous media is often hampered by multi-scale heterogeneity and insufficient site characterization. Monte-Carlo simulation (MCS), which runs numerical simulations for a large number of realization of input parameters , becomes infeasible when simulation cost is expensive or the degree of uncertainty is large. Many deep-neural-network-based methods are developed in order to replace the numerical flow simulation, but previous studies focused only on generating several snapshots of outputs at the fixed time steps, and lack to reflect the time dependent property of simulation data. Recently, the convolutional long short term memory (ConvLSTM) is utilized to deal with time series image data. Here, we propose to combine SegNet with ConvLSTM layers for the surrogate modeling of numerical flow simulation. The results show that the proposed method improves the performance of SegNet based surrogate model remarkably when the output of the simulation is time series data.
RefVOS: A Closer Look at Referring Expressions for Video Object Segmentation
Oct 01, 2020

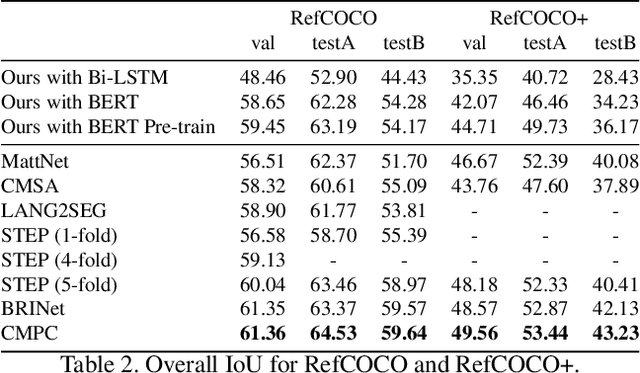
The task of video object segmentation with referring expressions (language-guided VOS) is to, given a linguistic phrase and a video, generate binary masks for the object to which the phrase refers. Our work argues that existing benchmarks used for this task are mainly composed of trivial cases, in which referents can be identified with simple phrases. Our analysis relies on a new categorization of the phrases in the DAVIS-2017 and Actor-Action datasets into trivial and non-trivial REs, with the non-trivial REs annotated with seven RE semantic categories. We leverage this data to analyze the results of RefVOS, a novel neural network that obtains competitive results for the task of language-guided image segmentation and state of the art results for language-guided VOS. Our study indicates that the major challenges for the task are related to understanding motion and static actions.
Group Invariant Deep Representations for Image Instance Retrieval
Jan 13, 2016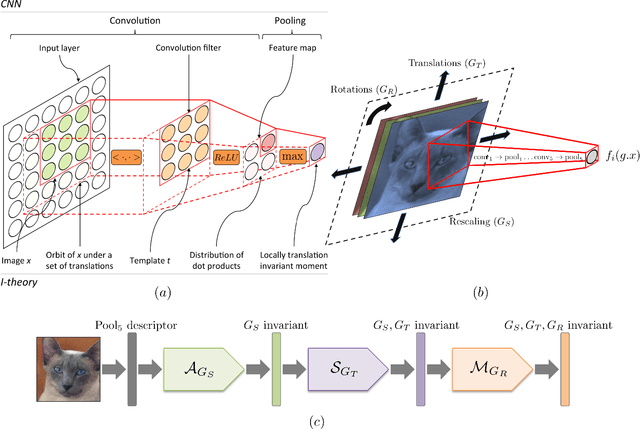

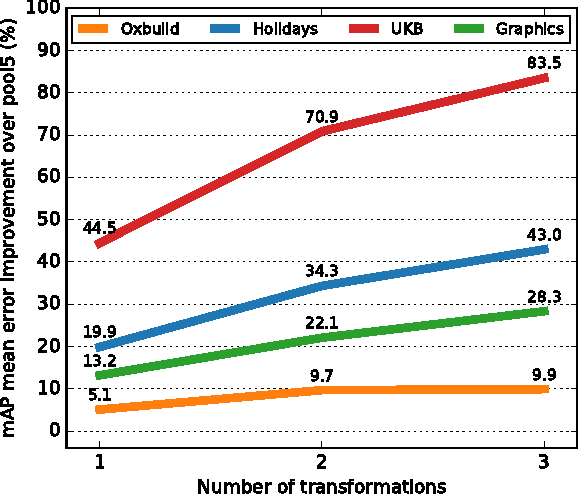
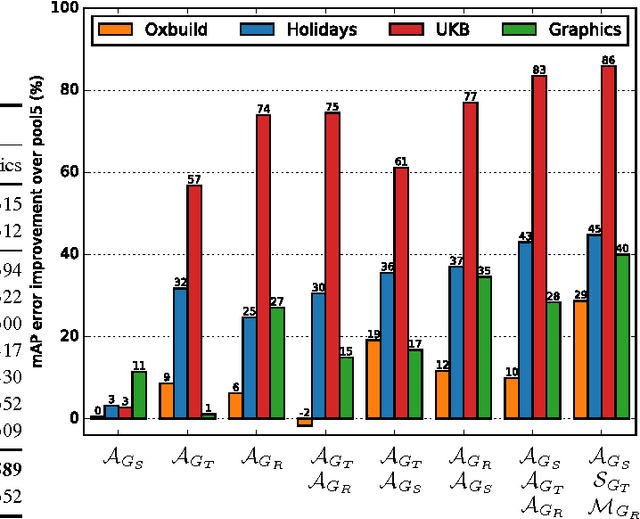
Most image instance retrieval pipelines are based on comparison of vectors known as global image descriptors between a query image and the database images. Due to their success in large scale image classification, representations extracted from Convolutional Neural Networks (CNN) are quickly gaining ground on Fisher Vectors (FVs) as state-of-the-art global descriptors for image instance retrieval. While CNN-based descriptors are generally remarked for good retrieval performance at lower bitrates, they nevertheless present a number of drawbacks including the lack of robustness to common object transformations such as rotations compared with their interest point based FV counterparts. In this paper, we propose a method for computing invariant global descriptors from CNNs. Our method implements a recently proposed mathematical theory for invariance in a sensory cortex modeled as a feedforward neural network. The resulting global descriptors can be made invariant to multiple arbitrary transformation groups while retaining good discriminativeness. Based on a thorough empirical evaluation using several publicly available datasets, we show that our method is able to significantly and consistently improve retrieval results every time a new type of invariance is incorporated. We also show that our method which has few parameters is not prone to overfitting: improvements generalize well across datasets with different properties with regard to invariances. Finally, we show that our descriptors are able to compare favourably to other state-of-the-art compact descriptors in similar bitranges, exceeding the highest retrieval results reported in the literature on some datasets. A dedicated dimensionality reduction step --quantization or hashing-- may be able to further improve the competitiveness of the descriptors.
UFO$^2$: A Unified Framework towards Omni-supervised Object Detection
Oct 21, 2020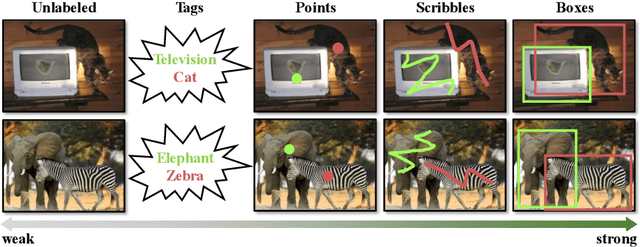


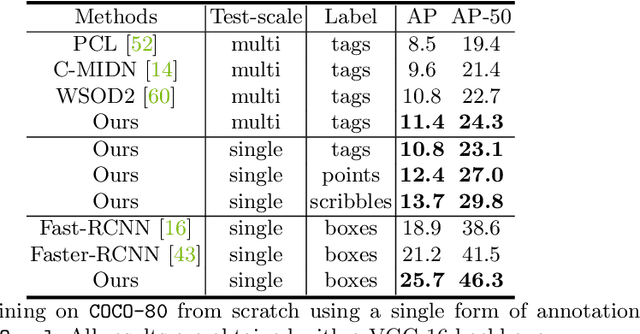
Existing work on object detection often relies on a single form of annotation: the model is trained using either accurate yet costly bounding boxes or cheaper but less expressive image-level tags. However, real-world annotations are often diverse in form, which challenges these existing works. In this paper, we present UFO$^2$, a unified object detection framework that can handle different forms of supervision simultaneously. Specifically, UFO$^2$ incorporates strong supervision (e.g., boxes), various forms of partial supervision (e.g., class tags, points, and scribbles), and unlabeled data. Through rigorous evaluations, we demonstrate that each form of label can be utilized to either train a model from scratch or to further improve a pre-trained model. We also use UFO$^2$ to investigate budget-aware omni-supervised learning, i.e., various annotation policies are studied under a fixed annotation budget: we show that competitive performance needs no strong labels for all data. Finally, we demonstrate the generalization of UFO$^2$, detecting more than 1,000 different objects without bounding box annotations.
Learning to Generate Customized Dynamic 3D Facial Expressions
Jul 19, 2020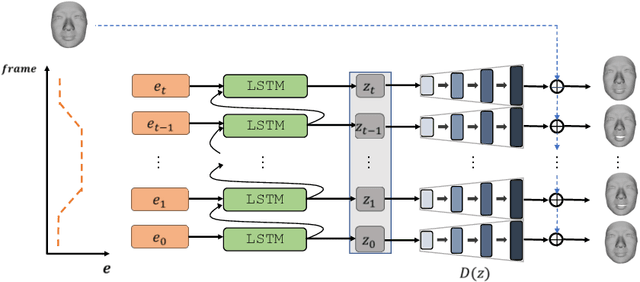
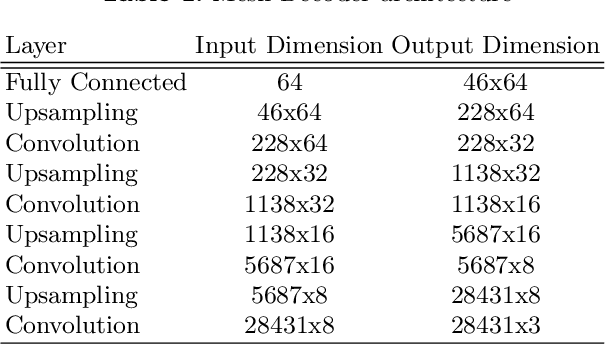
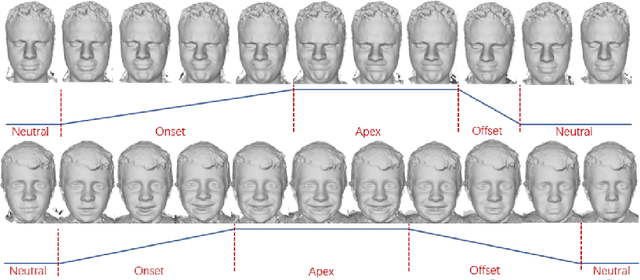

Recent advances in deep learning have significantly pushed the state-of-the-art in photorealistic video animation given a single image. In this paper, we extrapolate those advances to the 3D domain, by studying 3D image-to-video translation with a particular focus on 4D facial expressions. Although 3D facial generative models have been widely explored during the past years, 4D animation remains relatively unexplored. To this end, in this study we employ a deep mesh encoder-decoder like architecture to synthesize realistic high resolution facial expressions by using a single neutral frame along with an expression identification. In addition, processing 3D meshes remains a non-trivial task compared to data that live on grid-like structures, such as images. Given the recent progress in mesh processing with graph convolutions, we make use of a recently introduced learnable operator which acts directly on the mesh structure by taking advantage of local vertex orderings. In order to generalize to 4D facial expressions across subjects, we trained our model using a high resolution dataset with 4D scans of six facial expressions from 180 subjects. Experimental results demonstrate that our approach preserves the subject's identity information even for unseen subjects and generates high quality expressions. To the best of our knowledge, this is the first study tackling the problem of 4D facial expression synthesis.
Removing Bias in Multi-modal Classifiers: Regularization by Maximizing Functional Entropies
Oct 21, 2020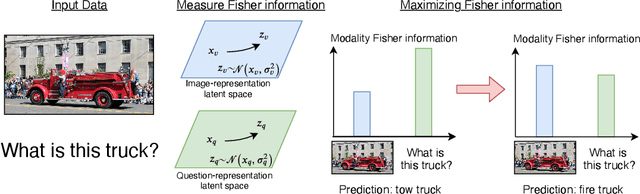
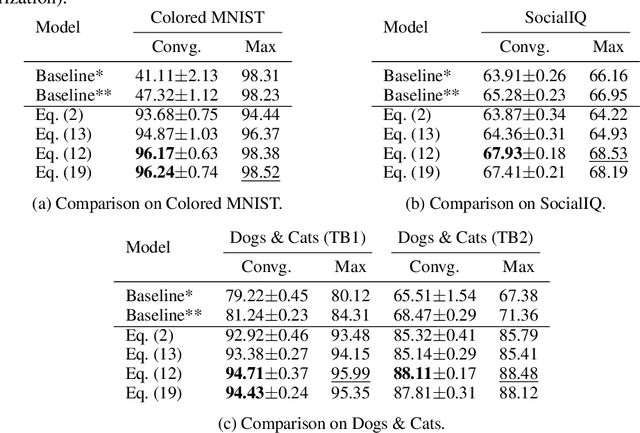
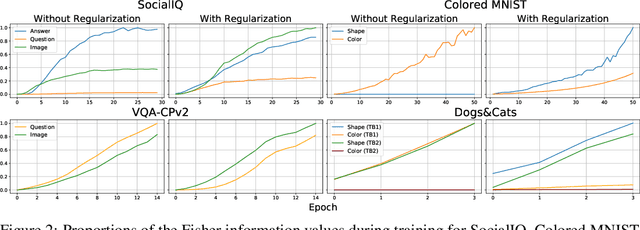
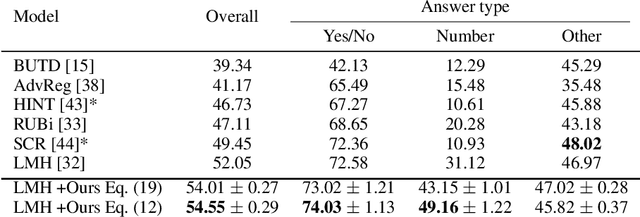
Many recent datasets contain a variety of different data modalities, for instance, image, question, and answer data in visual question answering (VQA). When training deep net classifiers on those multi-modal datasets, the modalities get exploited at different scales, i.e., some modalities can more easily contribute to the classification results than others. This is suboptimal because the classifier is inherently biased towards a subset of the modalities. To alleviate this shortcoming, we propose a novel regularization term based on the functional entropy. Intuitively, this term encourages to balance the contribution of each modality to the classification result. However, regularization with the functional entropy is challenging. To address this, we develop a method based on the log-Sobolev inequality, which bounds the functional entropy with the functional-Fisher-information. Intuitively, this maximizes the amount of information that the modalities contribute. On the two challenging multi-modal datasets VQA-CPv2 and SocialIQ, we obtain state-of-the-art results while more uniformly exploiting the modalities. In addition, we demonstrate the efficacy of our method on Colored MNIST.
Real-Time Image Distortion Correction: Analysis and Evaluation of FPGA-Compatible Algorithms
Oct 30, 2016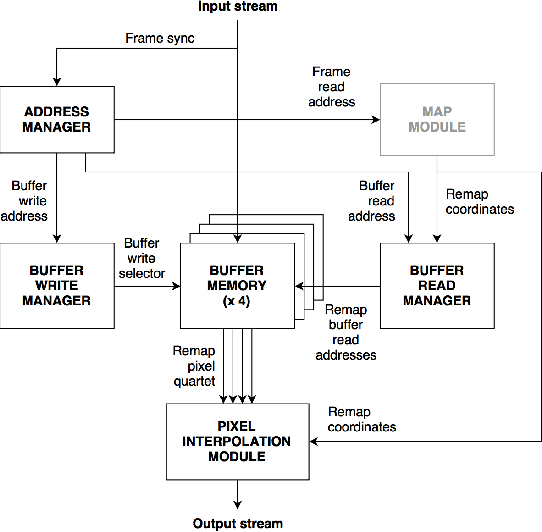
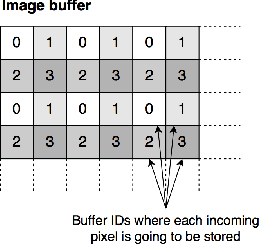

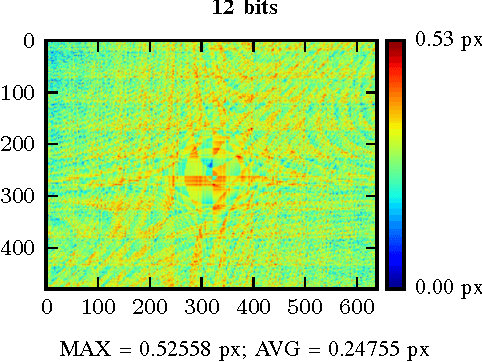
Image distortion correction is a critical pre-processing step for a variety of computer vision and image processing algorithms. Standard real-time software implementations are generally not suited for direct hardware porting, so appropriated versions need to be designed in order to obtain implementations deployable on FPGAs. In this paper, hardware-compatible techniques for image distortion correction are introduced and analyzed in details. The considered solutions are compared in terms of output quality by using a geometrical-error-based approach, with particular emphasis on robustness with respect to increasing lens distortion. The required amount of hardware resources is also estimated for each considered approach.
Image Enhancement with Statistical Estimation
May 07, 2012
Contrast enhancement is an important area of research for the image analysis. Over the decade, the researcher worked on this domain to develop an efficient and adequate algorithm. The proposed method will enhance the contrast of image using Binarization method with the help of Maximum Likelihood Estimation (MLE). The paper aims to enhance the image contrast of bimodal and multi-modal images. The proposed methodology use to collect mathematical information retrieves from the image. In this paper, we are using binarization method that generates the desired histogram by separating image nodes. It generates the enhanced image using histogram specification with binarization method. The proposed method has showed an improvement in the image contrast enhancement compare with the other image.
* 9 pages,6 figures; ISSN:0975-5578 (Online); 0975-5934 (Print)