 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A ParaBoost Stereoscopic Image Quality Assessment (PBSIQA) System
Mar 31, 2016

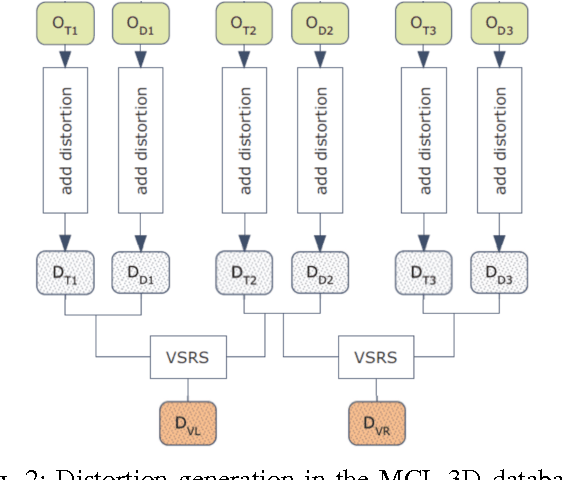
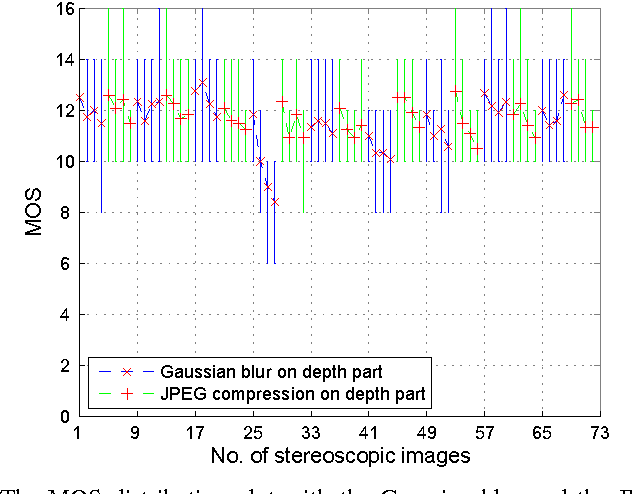
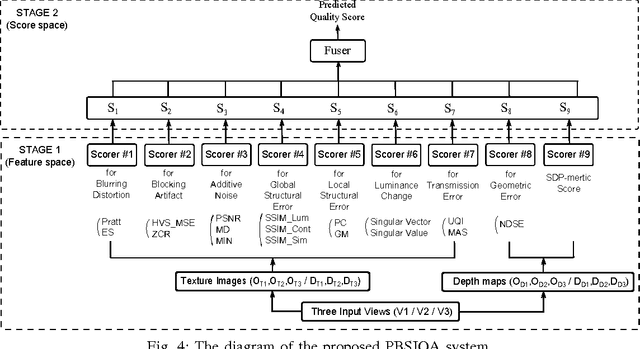
The problem of stereoscopic image quality assessment, which finds applications in 3D visual content delivery such as 3DTV, is investigated in this work. Specifically, we propose a new ParaBoost (parallel-boosting) stereoscopic image quality assessment (PBSIQA) system. The system consists of two stages. In the first stage, various distortions are classified into a few types, and individual quality scorers targeting at a specific distortion type are developed. These scorers offer complementary performance in face of a database consisting of heterogeneous distortion types. In the second stage, scores from multiple quality scorers are fused to achieve the best overall performance, where the fuser is designed based on the parallel boosting idea borrowed from machine learning. Extensive experimental results are conducted to compare the performance of the proposed PBSIQA system with those of existing stereo image quality assessment (SIQA) metrics. The developed quality metric can serve as an objective function to optimize the performance of a 3D content delivery system.
Real-Time Edge Classification: Optimal Offloading under Token Bucket Constraints
Oct 26, 2020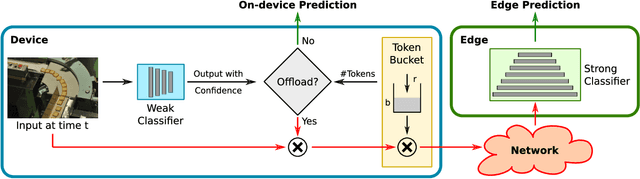
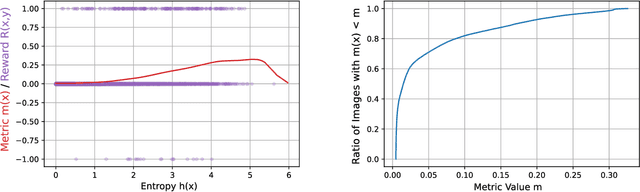
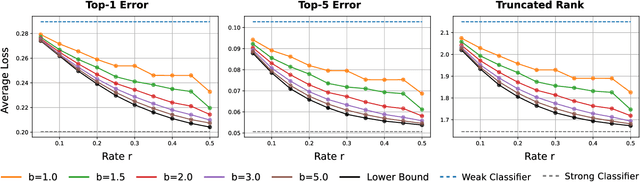
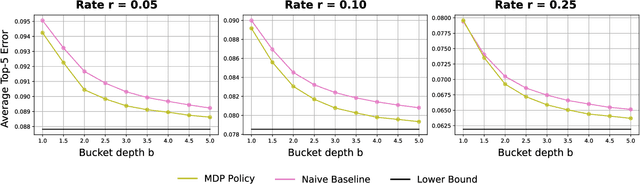
To deploy machine learning-based algorithms for real-time applications with strict latency constraints, we consider an edge-computing setting where a subset of inputs are offloaded to the edge for processing by an accurate but resource-intensive model, and the rest are processed only by a less-accurate model on the device itself. Both models have computational costs that match available compute resources, and process inputs with low-latency. But offloading incurs network delays, and to manage these delays to meet application deadlines, we use a token bucket to constrain the average rate and burst length of transmissions from the device. We introduce a Markov Decision Process-based framework to make offload decisions under these constraints, based on the local model's confidence and the token bucket state, with the goal of minimizing a specified error measure for the application. Beyond isolated decisions for individual devices, we also propose approaches to allow multiple devices connected to the same access switch to share their bursting allocation. We evaluate and analyze the policies derived using our framework on the standard ImageNet image classification benchmark.
Dehazing Cost Volume for Deep Multi-view Stereo in Scattering Media with Airlight and Scattering Coefficient Estimation
Nov 18, 2020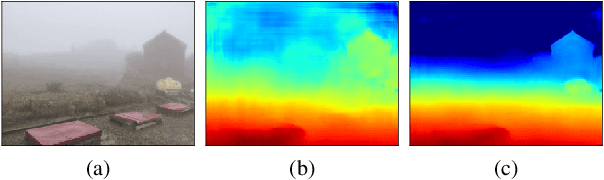
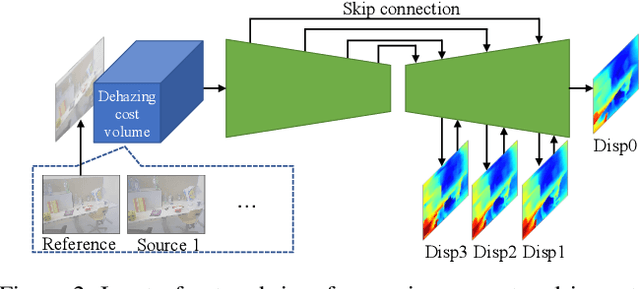
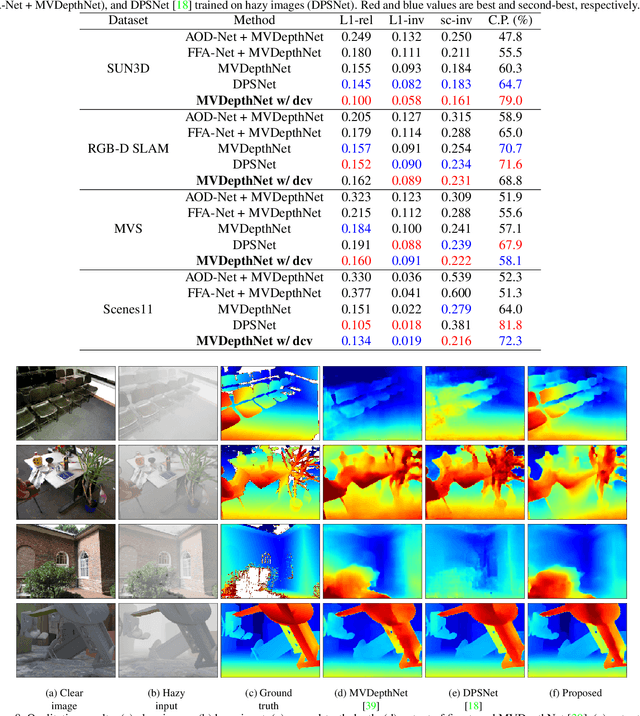
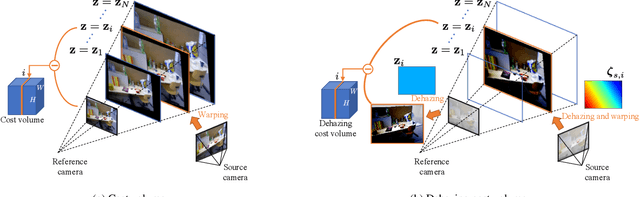
We propose a learning-based multi-view stereo (MVS) method in scattering media, such as fog or smoke, with a novel cost volume, called the dehazing cost volume. Images captured in scattering media are degraded due to light scattering and attenuation caused by suspended particles. This degradation depends on scene depth; thus, it is difficult for traditional MVS methods to evaluate photometric consistency because the depth is unknown before three-dimensional (3D) reconstruction. The dehazing cost volume can solve this chicken-and-egg problem of depth estimation and image restoration by computing the scattering effect using swept planes in the cost volume. We also propose a method of estimating scattering parameters, such as airlight, and a scattering coefficient, which are required for our dehazing cost volume. The output depth of a network with our dehazing cost volume can be regarded as a function of these parameters; thus, they are geometrically optimized with a sparse 3D point cloud obtained at a structure-from-motion step. Experimental results on synthesized hazy images indicate the effectiveness of our dehazing cost volume against the ordinary cost volume regarding scattering media. We also demonstrated the applicability of our dehazing cost volume to real foggy scenes.
Automatic Visual Theme Discovery from Joint Image and Text Corpora
Sep 07, 2016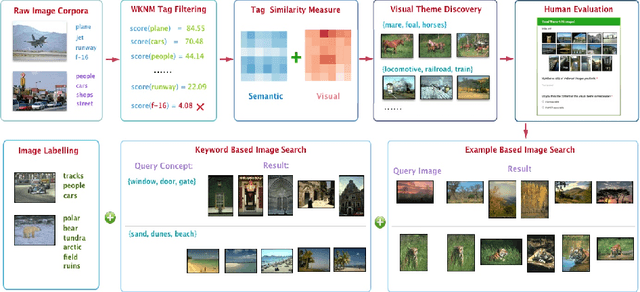
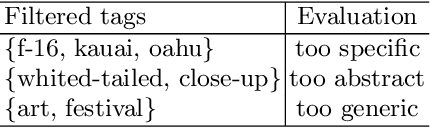
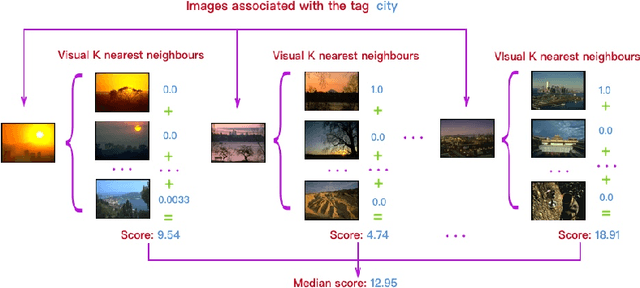

A popular approach to semantic image understanding is to manually tag images with keywords and then learn a mapping from vi- sual features to keywords. Manually tagging images is a subjective pro- cess and the same or very similar visual contents are often tagged with different keywords. Furthermore, not all tags have the same descriptive power for visual contents and large vocabulary available from natural language could result in a very diverse set of keywords. In this paper, we propose an unsupervised visual theme discovery framework as a better (more compact, efficient and effective) alternative to semantic represen- tation of visual contents. We first show that tag based annotation lacks consistency and compactness for describing visually similar contents. We then learn the visual similarity between tags based on the visual features of the images containing the tags. At the same time, we use a natural language processing technique (word embedding) to measure the seman- tic similarity between tags. Finally, we cluster tags into visual themes based on their visual similarity and semantic similarity measures using a spectral clustering algorithm. We conduct user studies to evaluate the effectiveness and rationality of the visual themes discovered by our unsu- pervised algorithm and obtains promising result. We then design three common computer vision tasks, example based image search, keyword based image search and image labelling to explore potential applica- tion of our visual themes discovery framework. In experiments, visual themes significantly outperforms tags on semantic image understand- ing and achieve state-of-art performance in all three tasks. This again demonstrate the effectiveness and versatility of proposed framework.
Document image classification, with a specific view on applications of patent images
Jan 13, 2016
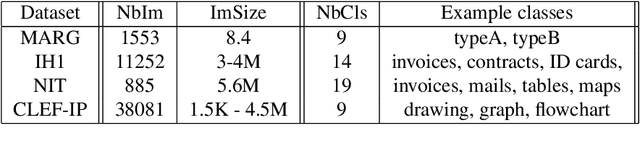
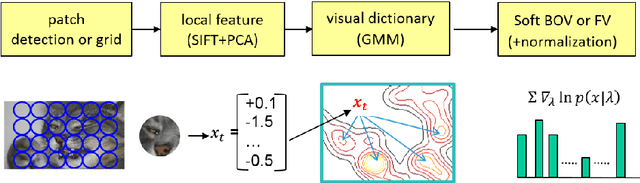
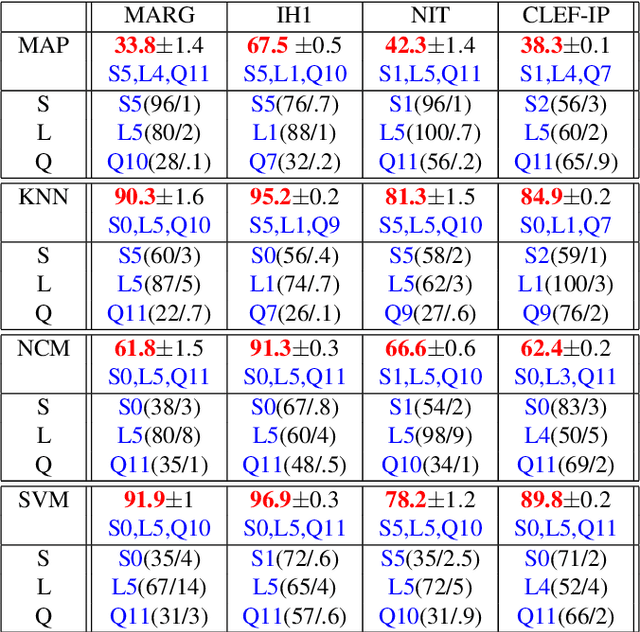
The main focus of this paper is document image classification and retrieval, where we analyze and compare different parameters for the RunLeght Histogram (RL) and Fisher Vector (FV) based image representations. We do an exhaustive experimental study using different document image datasets, including the MARG benchmarks, two datasets built on customer data and the images from the Patent Image Classification task of the Clef-IP 2011. The aim of the study is to give guidelines on how to best choose the parameters such that the same features perform well on different tasks. As an example of such need, we describe the Image-based Patent Retrieval task's of Clef-IP 2011, where we used the same image representation to predict the image type and retrieve relevant patents.
Iterative Methods for Computing Eigenvectors of Nonlinear Operators
Oct 06, 2020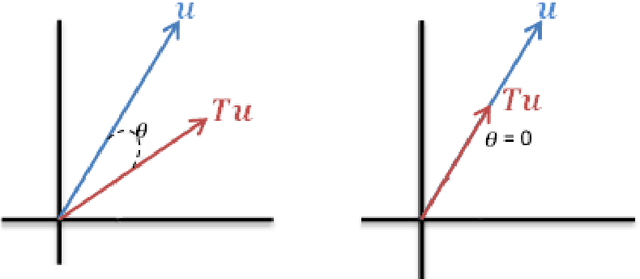
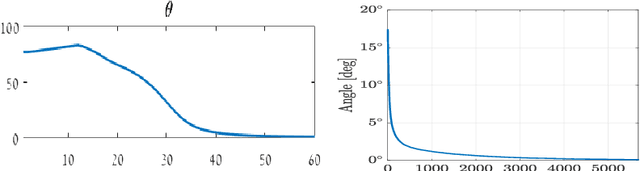

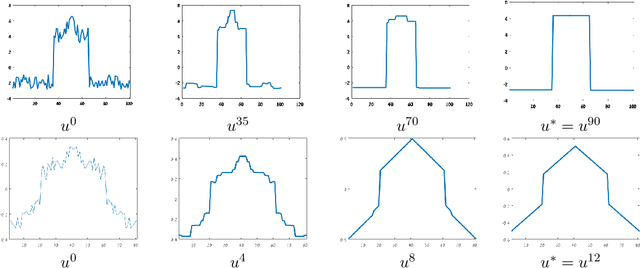
In this chapter we are examining several iterative methods for solving nonlinear eigenvalue problems. These arise in variational image-processing, graph partition and classification, nonlinear physics and more. The canonical eigenproblem we solve is $T(u)=\lambda u$, where $T:\R^n\to \R^n$ is some bounded nonlinear operator. Other variations of eigenvalue problems are also discussed. We present a progression of 5 algorithms, coauthored in recent years by the author and colleagues. Each algorithm attempts to solve a unique problem or to improve the theoretical foundations. The algorithms can be understood as nonlinear PDE's which converge to an eigenfunction in the continuous time domain. This allows a unique view and understanding of the discrete iterative process. Finally, it is shown how to evaluate numerically the results, along with some examples and insights related to priors of nonlinear denoisers, both classical algorithms and ones based on deep networks.
TOMAAT: volumetric medical image analysis as a cloud service
Apr 25, 2018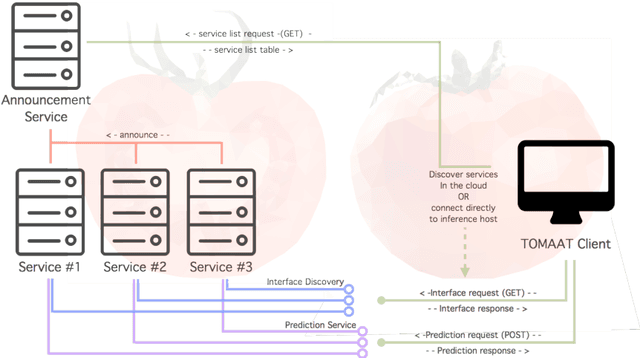

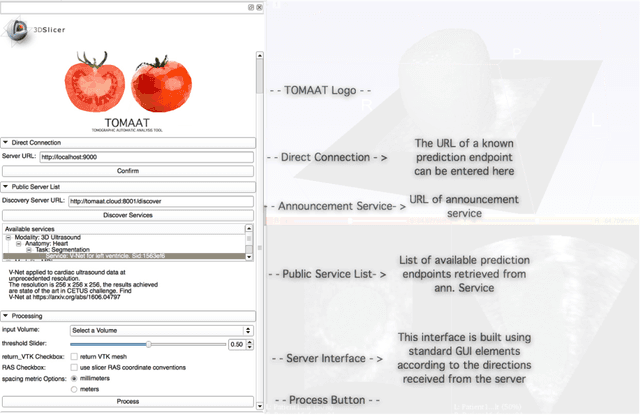
Deep learning has been recently applied to a multitude of computer vision and medical image analysis problems. Although recent research efforts have improved the state of the art, most of the methods cannot be easily accessed, compared or used by either researchers or the general public. Researchers often publish their code and trained models on the internet, but this does not always enable these approaches to be easily used or integrated in stand-alone applications and existing workflows. In this paper we propose a framework which allows easy deployment and access of deep learning methods for segmentation through a cloud-based architecture. Our approach comprises three parts: a server, which wraps trained deep learning models and their pre- and post-processing data pipelines and makes them available on the cloud; a client which interfaces with the server to obtain predictions on user data; a service registry that informs clients about available prediction endpoints that are available in the cloud. These three parts constitute the open-source TOMAAT framework.
Neural Head Reenactment with Latent Pose Descriptors
Apr 24, 2020
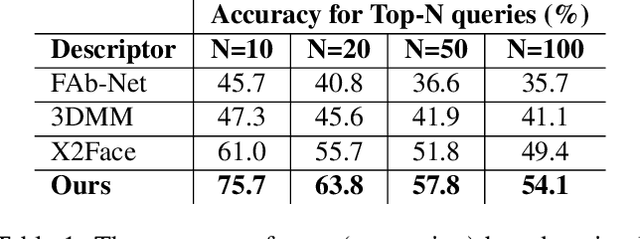
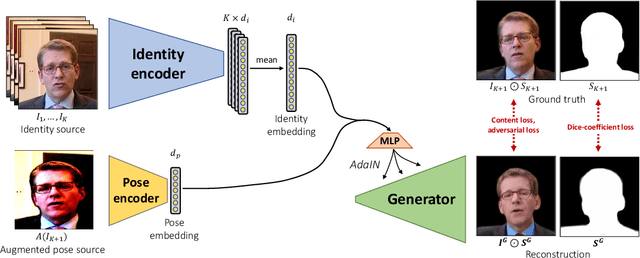

We propose a neural head reenactment system, which is driven by a latent pose representation and is capable of predicting the foreground segmentation alongside the RGB image. The latent pose representation is learned as a part of the entire reenactment system, and the learning process is based solely on image reconstruction losses. We show that despite its simplicity, with a large and diverse enough training dataset, such learning successfully decomposes pose from identity. The resulting system can then reproduce mimics of the driving person and, furthermore, can perform cross-person reenactment. Additionally, we show that the learned descriptors are useful for other pose-related tasks, such as keypoint prediction and pose-based retrieval.
An Indexing Scheme and Descriptor for 3D Object Retrieval Based on Local Shape Querying
Aug 07, 2020
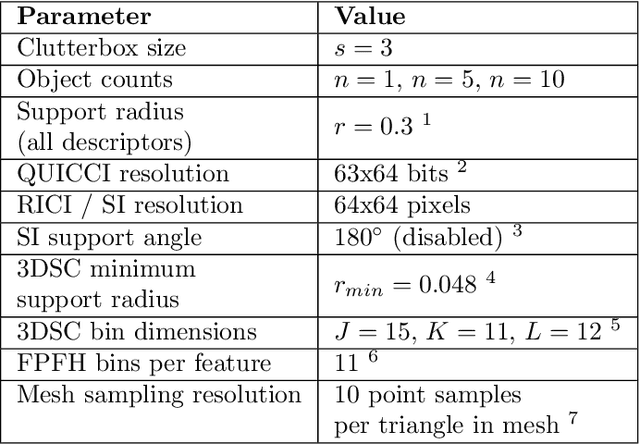
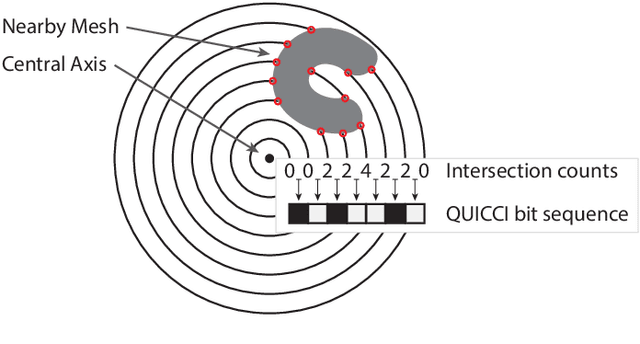
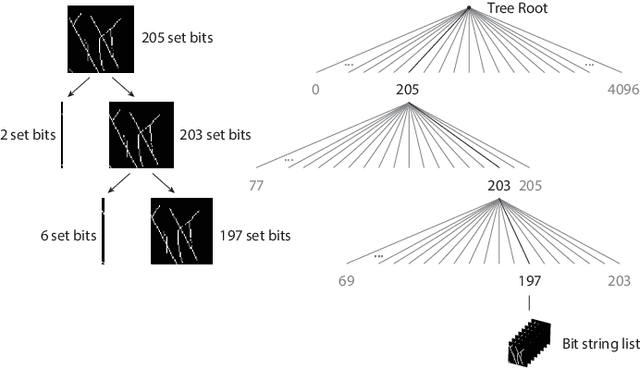
A binary descriptor indexing scheme based on Hamming distance called the Hamming tree for local shape queries is presented. A new binary clutter resistant descriptor named Quick Intersection Count Change Image (QUICCI) is also introduced. This local shape descriptor is extremely small and fast to compare. Additionally, a novel distance function called Weighted Hamming applicable to QUICCI images is proposed for retrieval applications. The effectiveness of the indexing scheme and QUICCI is demonstrated on 828 million QUICCI images derived from the SHREC2017 dataset, while the clutter resistance of QUICCI is shown using the clutterbox experiment.
CT-SRCNN: Cascade Trained and Trimmed Deep Convolutional Neural Networks for Image Super Resolution
Nov 11, 2017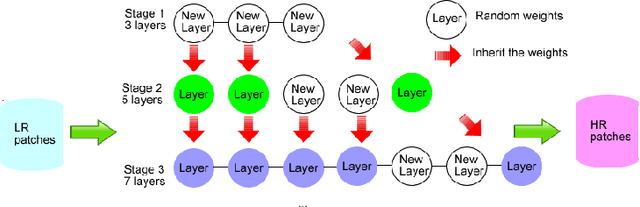
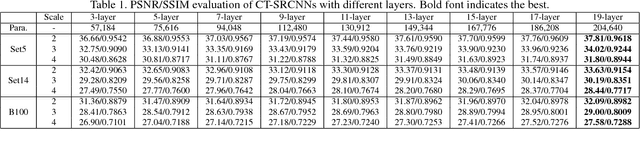
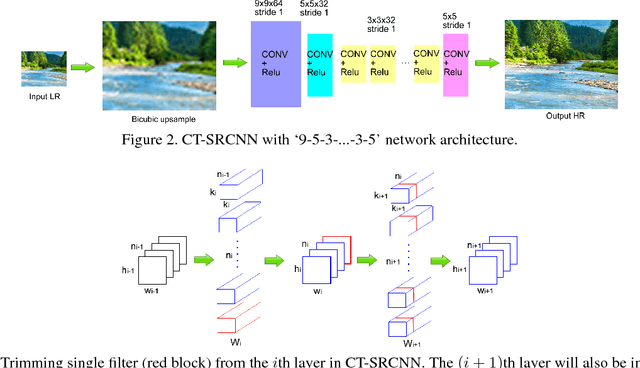

We propose methodologies to train highly accurate and efficient deep convolutional neural networks (CNNs) for image super resolution (SR). A cascade training approach to deep learning is proposed to improve the accuracy of the neural networks while gradually increasing the number of network layers. Next, we explore how to improve the SR efficiency by making the network slimmer. Two methodologies, the one-shot trimming and the cascade trimming, are proposed. With the cascade trimming, the network's size is gradually reduced layer by layer, without significant loss on its discriminative ability. Experiments on benchmark image datasets show that our proposed SR network achieves the state-of-the-art super resolution accuracy, while being more than 4 times faster compared to existing deep super resolution networks.