 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sim-to-real for high-resolution optical tactile sensing: From images to 3D contact force distributions
Dec 21, 2020

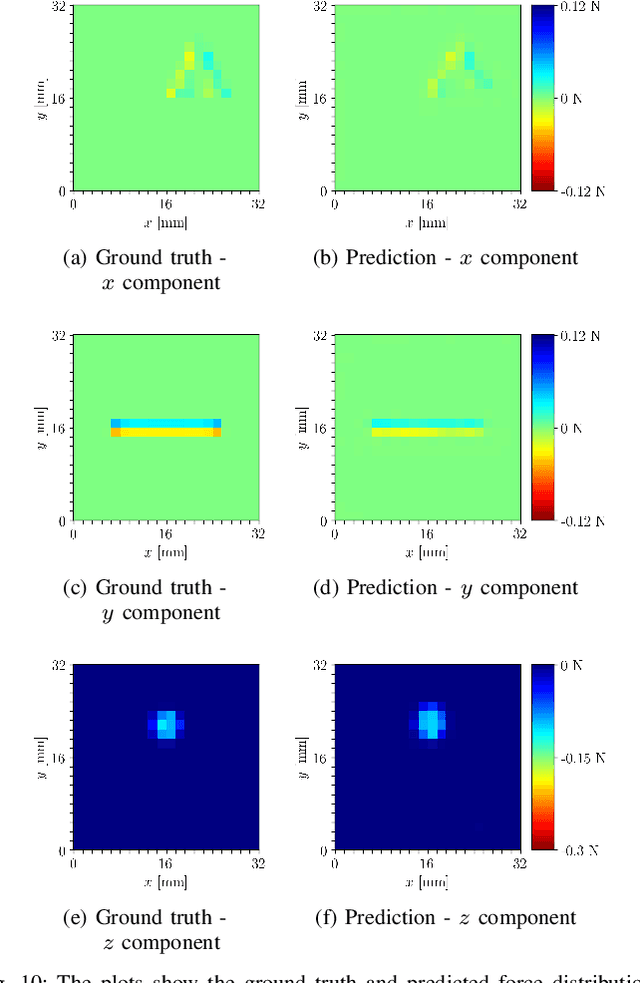


The images captured by vision-based tactile sensors carry information about high-resolution tactile fields, such as the distribution of the contact forces applied to their soft sensing surface. However, extracting the information encoded in the images is challenging and often addressed with learning-based approaches, which generally require a large amount of training data. This article proposes a strategy to generate tactile images in simulation for a vision-based tactile sensor based on an internal camera that tracks the motion of spherical particles within a soft material. The deformation of the material is simulated in a finite element environment under a diverse set of contact conditions, and spherical particles are projected to a simulated image. Features extracted from the images are mapped to the 3D contact force distribution, with the ground truth also obtained via finite-element simulations, with an artificial neural network that is therefore entirely trained on synthetic data avoiding the need for real-world data collection. The resulting model exhibits high accuracy when evaluated on real-world tactile images, is transferable across multiple tactile sensors without further training, and is suitable for efficient real-time inference.
GnetSeg: Semantic Segmentation Model Optimized on a 224mW CNN Accelerator Chip at the Speed of 318FPS
Jan 09, 2021

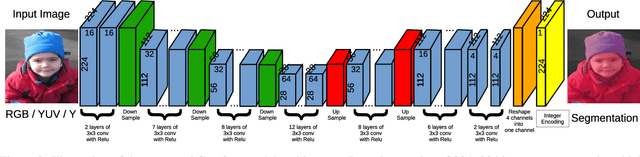
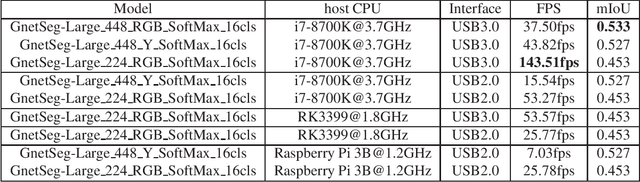
Semantic segmentation is the task to cluster pixels on an image belonging to the same class. It is widely used in the real-world applications including autonomous driving, medical imaging analysis, industrial inspection, smartphone camera for person segmentation and so on. Accelerating the semantic segmentation models on the mobile and edge devices are practical needs for the industry. Recent years have witnessed the wide availability of CNN (Convolutional Neural Networks) accelerators. They have the advantages on power efficiency, inference speed, which are ideal for accelerating the semantic segmentation models on the edge devices. However, the CNN accelerator chips also have the limitations on flexibility and memory. In addition, the CPU load is very critical because the CNN accelerator chip works as a co-processor with a host CPU. In this paper, we optimize the semantic segmentation model in order to fully utilize the limited memory and the supported operators on the CNN accelerator chips, and at the same time reduce the CPU load of the CNN model to zero. The resulting model is called GnetSeg. Furthermore, we propose the integer encoding for the mask of the GnetSeg model, which minimizes the latency of data transfer between the CNN accelerator and the host CPU. The experimental result shows that the model running on the 224mW chip achieves the speed of 318FPS with excellent accuracy for applications such as person segmentation.
Joint Generative Learning and Super-Resolution For Real-World Camera-Screen Degradation
Aug 01, 2020



In real-world single image super-resolution (SISR) task, the low-resolution image suffers more complicated degradations, not only downsampled by unknown kernels. However, existing SISR methods are generally studied with the synthetic low-resolution generation such as bicubic interpolation (BI), which greatly limits their performance. Recently, some researchers investigate real-world SISR from the perspective of the camera and smartphone. However, except the acquisition equipment, the display device also involves more complicated degradations. In this paper, we focus on the camera-screen degradation and build a real-world dataset (Cam-ScreenSR), where HR images are original ground truths from the previous DIV2K dataset and corresponding LR images are camera-captured versions of HRs displayed on the screen. We conduct extensive experiments to demonstrate that involving more real degradations is positive to improve the generalization of SISR models. Moreover, we propose a joint two-stage model. Firstly, the downsampling degradation GAN(DD-GAN) is trained to model the degradation and produces more various of LR images, which is validated to be efficient for data augmentation. Then the dual residual channel attention network (DuRCAN) learns to recover the SR image. The weighted combination of L1 loss and proposed Laplacian loss are applied to sharpen the high-frequency edges. Extensive experimental results in both typical synthetic and complicated real-world degradations validate the proposed method outperforms than existing SOTA models with less parameters, faster speed and better visual results. Moreover, in real captured photographs, our model also delivers best visual quality with sharper edge, less artifacts, especially appropriate color enhancement, which has not been accomplished by previous methods.
CSV: Image Quality Assessment Based on Color, Structure, and Visual System
Oct 15, 2018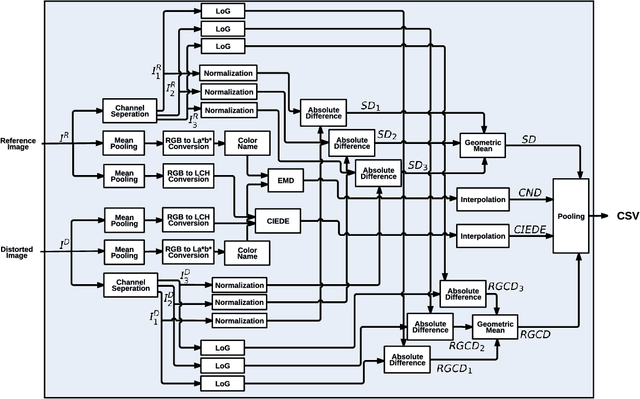

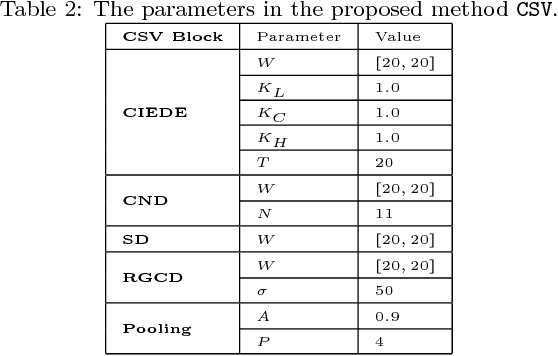
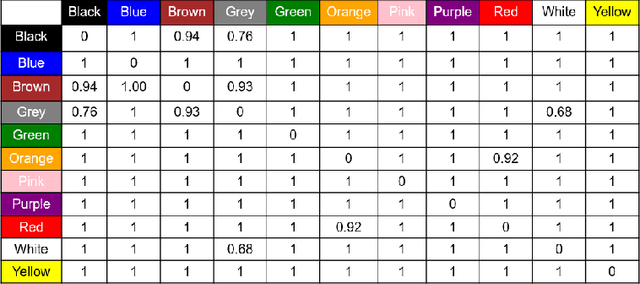
This paper presents a full-reference image quality estimator based on color, structure, and visual system characteristics denoted as CSV. In contrast to the majority of existing methods, we quantify perceptual color degradations rather than absolute pixel-wise changes. We use the CIEDE2000 color difference formulation to quantify low-level color degradations and the Earth Mover's Distance between color name descriptors to measure significant color degradations. In addition to the perceptual color difference, CSV also contains structural and perceptual differences. Structural feature maps are obtained by mean subtraction and divisive normalization, and perceptual feature maps are obtained from contrast sensitivity formulations of retinal ganglion cells. The proposed quality estimator CSV is tested on the LIVE, the Multiply Distorted LIVE, and the TID 2013 databases, and it is always among the top two performing quality estimators in terms of at least ranking, monotonic behavior or linearity.
* 31 pages, 9 figures, 7 tables
Change Detection Using Synthetic Aperture Radar Videos
Jul 28, 2020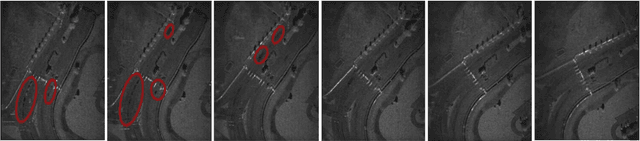


Many researches have been carried out for change detection using temporal SAR images. In this paper an algorithm for change detection using SAR videos has been proposed. There are various challenges related to SAR videos such as high level of speckle noise, rotation of SAR image frames of the video around a particular axis due to the circular movement of airborne vehicle, non-uniform back scattering of SAR pulses. Hence conventional change detection algorithms used for optical videos and SAR temporal images cannot be directly utilized for SAR videos. We propose an algorithm which is a combination of optical flow calculation using Lucas Kanade (LK) method and blob detection. The developed method follows a four steps approach: image filtering and enhancement, applying LK method, blob analysis and combining LK method with blob analysis. The performance of the developed approach was tested on SAR videos available on Sandia National Laboratories website and SAR videos generated by a SAR simulator.
Image Patch Matching Using Convolutional Descriptors with Euclidean Distance
Oct 31, 2017
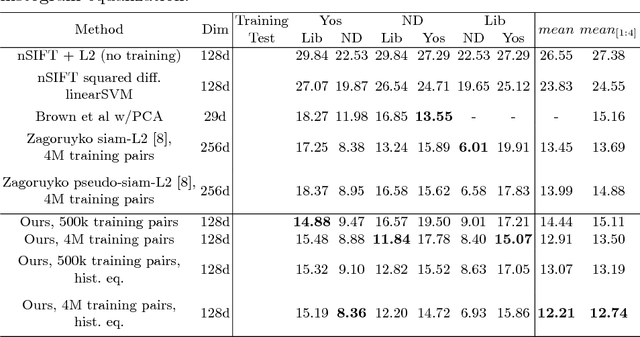
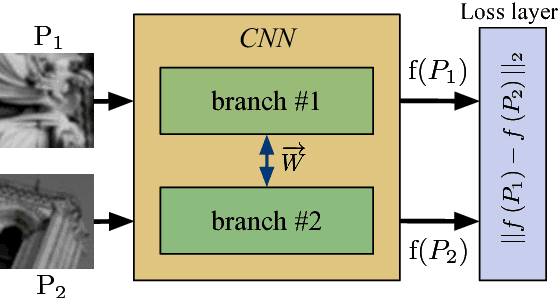
In this work we propose a neural network based image descriptor suitable for image patch matching, which is an important task in many computer vision applications. Our approach is influenced by recent success of deep convolutional neural networks (CNNs) in object detection and classification tasks. We develop a model which maps the raw input patch to a low dimensional feature vector so that the distance between representations is small for similar patches and large otherwise. As a distance metric we utilize L2 norm, i.e. Euclidean distance, which is fast to evaluate and used in most popular hand-crafted descriptors, such as SIFT. According to the results, our approach outperforms state-of-the-art L2-based descriptors and can be considered as a direct replacement of SIFT. In addition, we conducted experiments with batch normalization and histogram equalization as a preprocessing method of the input data. The results confirm that these techniques further improve the performance of the proposed descriptor. Finally, we show promising preliminary results by appending our CNNs with recently proposed spatial transformer networks and provide a visualisation and interpretation of their impact.
A Convolutional Approach to Vertebrae Detection and Labelling in Whole Spine MRI
Jul 06, 2020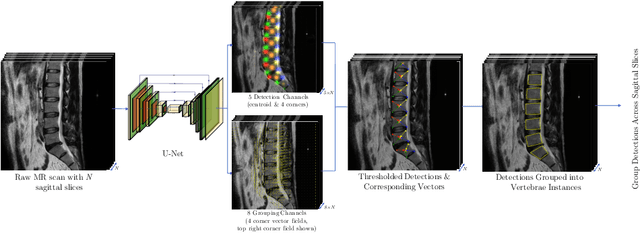
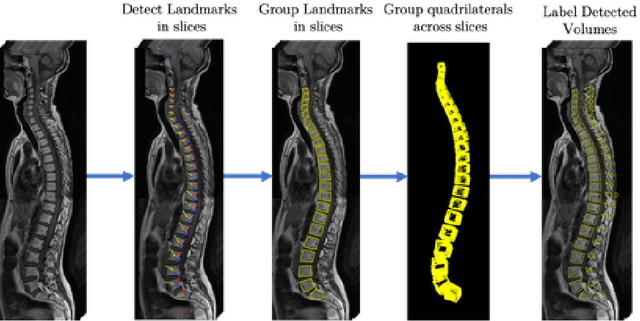

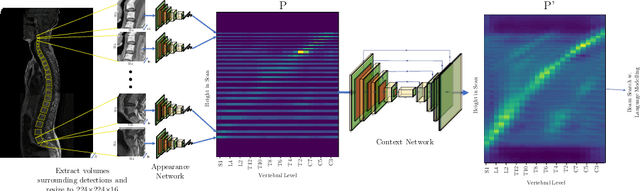
We propose a novel convolutional method for the detection and identification of vertebrae in whole spine MRIs. This involves using a learnt vector field to group detected vertebrae corners together into individual vertebral bodies and convolutional image-to-image translation followed by beam search to label vertebral levels in a self-consistent manner. The method can be applied without modification to lumbar, cervical and thoracic-only scans across a range of different MR sequences. The resulting system achieves 98.1% detection rate and 96.5% identification rate on a challenging clinical dataset of whole spine scans and matches or exceeds the performance of previous systems on lumbar-only scans. Finally, we demonstrate the clinical applicability of this method, using it for automated scoliosis detection in both lumbar and whole spine MR scans.
k-Same-Siamese-GAN: k-Same Algorithm with Generative Adversarial Network for Facial Image De-identification with Hyperparameter Tuning and Mixed Precision Training
Mar 27, 2019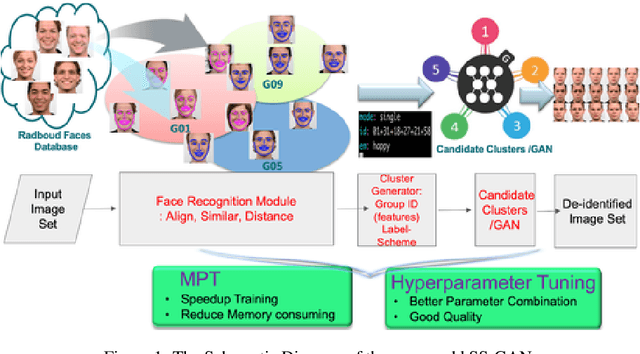

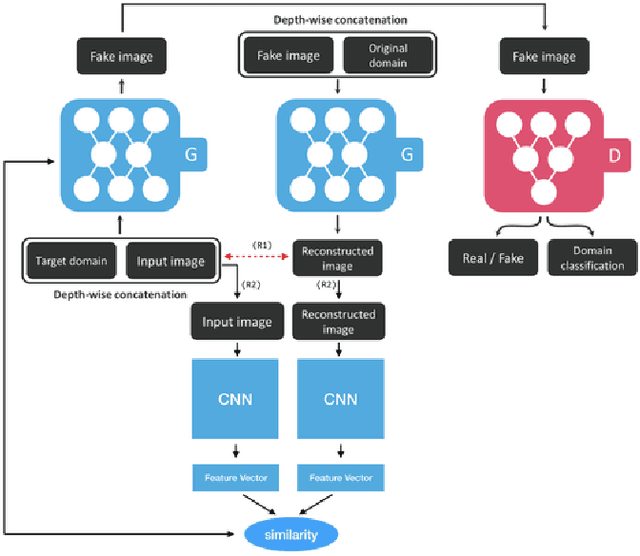

In recent years, advances in camera and computing hardware have made it easy to capture and store amounts of image and video data. Consider a data holder, such as a hospital or a government entity, who has a privately held collection of personal data. Then, how can we ensure that the data holder does conceal the identity of each individual in the imagery of personal data while still preserving certain useful aspects of the data after de-identification? In this work, we proposed a novel approach towards high-resolution facial image de-identification, called k-Same-Siamese-GAN (kSS-GAN), which leverages k-Same-Anonymity mechanism, Generative Adversarial Network (GAN), and hyperparameter tuning. To speed up training and reduce memory consumption, the mixed precision training (MPT) technique is also applied to make kSS-GAN provide guarantees regarding privacy protection on close-form identities and be trained much more efficiently as well. Finally, we dedicated our system to an actual dataset: RafD dataset for performance testing. Besides protecting privacy of high resolution of facial images, the proposed system is also justified for its ability in automating parameter tuning and breaking through the limitation of the number of adjustable parameters.
EMLight: Lighting Estimation via Spherical Distribution Approximation
Dec 21, 2020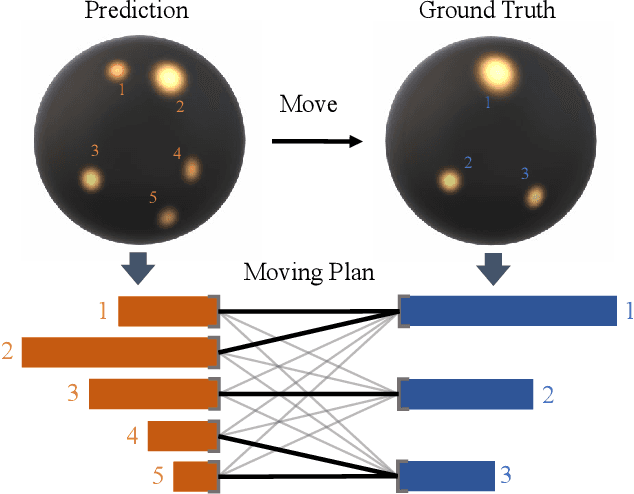
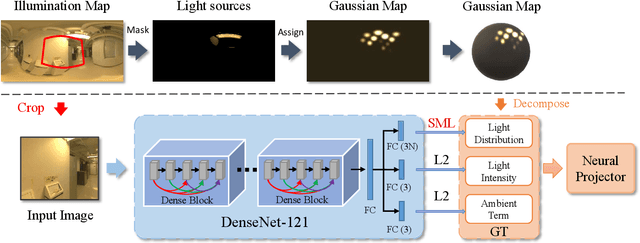

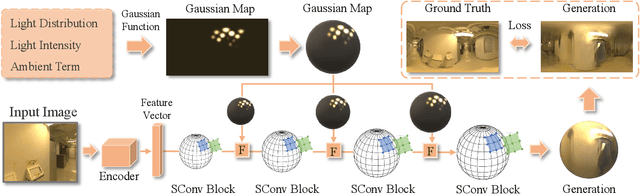
Illumination estimation from a single image is critical in 3D rendering and it has been investigated extensively in the computer vision and computer graphic research community. On the other hand, existing works estimate illumination by either regressing light parameters or generating illumination maps that are often hard to optimize or tend to produce inaccurate predictions. We propose Earth Mover Light (EMLight), an illumination estimation framework that leverages a regression network and a neural projector for accurate illumination estimation. We decompose the illumination map into spherical light distribution, light intensity and the ambient term, and define the illumination estimation as a parameter regression task for the three illumination components. Motivated by the Earth Mover distance, we design a novel spherical mover's loss that guides to regress light distribution parameters accurately by taking advantage of the subtleties of spherical distribution. Under the guidance of the predicted spherical distribution, light intensity and ambient term, the neural projector synthesizes panoramic illumination maps with realistic light frequency. Extensive experiments show that EMLight achieves accurate illumination estimation and the generated relighting in 3D object embedding exhibits superior plausibility and fidelity as compared with state-of-the-art methods.
Where is my hand? Deep hand segmentation for visual self-recognition in humanoid robots
Feb 09, 2021
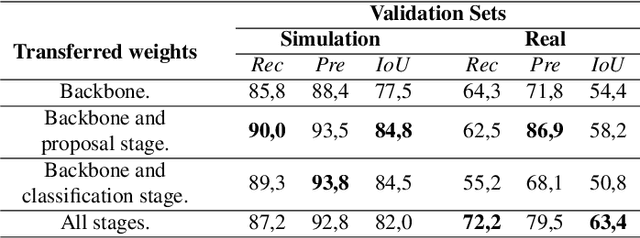
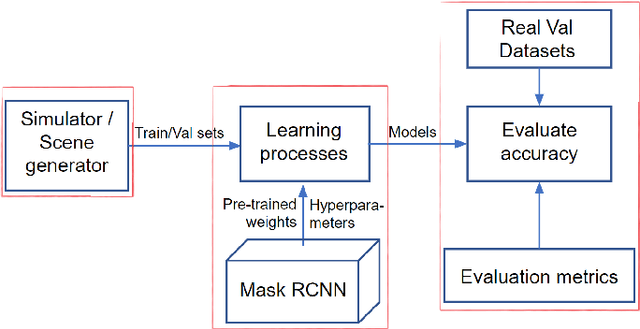
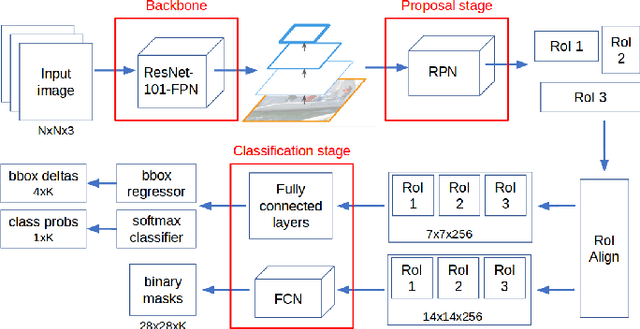
The ability to distinguish between the self and the background is of paramount importance for robotic tasks. The particular case of hands, as the end effectors of a robotic system that more often enter into contact with other elements of the environment, must be perceived and tracked with precision to execute the intended tasks with dexterity and without colliding with obstacles. They are fundamental for several applications, from Human-Robot Interaction tasks to object manipulation. Modern humanoid robots are characterized by high number of degrees of freedom which makes their forward kinematics models very sensitive to uncertainty. Thus, resorting to vision sensing can be the only solution to endow these robots with a good perception of the self, being able to localize their body parts with precision. In this paper, we propose the use of a Convolution Neural Network (CNN) to segment the robot hand from an image in an egocentric view. It is known that CNNs require a huge amount of data to be trained. To overcome the challenge of labeling real-world images, we propose the use of simulated datasets exploiting domain randomization techniques. We fine-tuned the Mask-RCNN network for the specific task of segmenting the hand of the humanoid robot Vizzy. We focus our attention on developing a methodology that requires low amounts of data to achieve reasonable performance while giving detailed insight on how to properly generate variability in the training dataset. Moreover, we analyze the fine-tuning process within the complex model of Mask-RCNN, understanding which weights should be transferred to the new task of segmenting robot hands. Our final model was trained solely on synthetic images and achieves an average IoU of 82% on synthetic validation data and 56.3% on real test data. These results were achieved with only 1000 training images and 3 hours of training time using a single GPU.