 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere is my hand? Deep hand segmentation for visual self-recognition in humanoid robots
Paper and Code

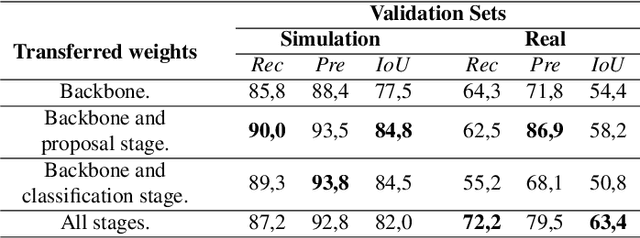
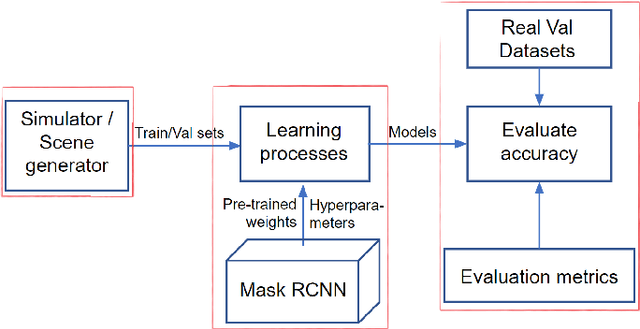
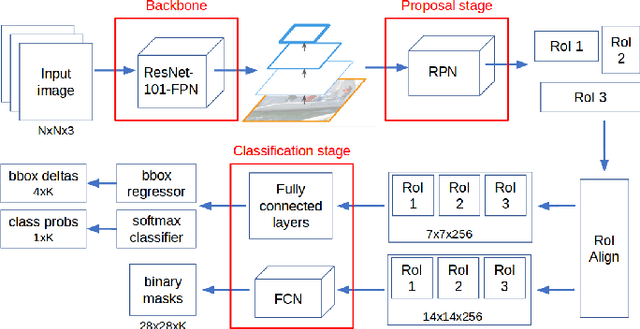
The ability to distinguish between the self and the background is of paramount importance for robotic tasks. The particular case of hands, as the end effectors of a robotic system that more often enter into contact with other elements of the environment, must be perceived and tracked with precision to execute the intended tasks with dexterity and without colliding with obstacles. They are fundamental for several applications, from Human-Robot Interaction tasks to object manipulation. Modern humanoid robots are characterized by high number of degrees of freedom which makes their forward kinematics models very sensitive to uncertainty. Thus, resorting to vision sensing can be the only solution to endow these robots with a good perception of the self, being able to localize their body parts with precision. In this paper, we propose the use of a Convolution Neural Network (CNN) to segment the robot hand from an image in an egocentric view. It is known that CNNs require a huge amount of data to be trained. To overcome the challenge of labeling real-world images, we propose the use of simulated datasets exploiting domain randomization techniques. We fine-tuned the Mask-RCNN network for the specific task of segmenting the hand of the humanoid robot Vizzy. We focus our attention on developing a methodology that requires low amounts of data to achieve reasonable performance while giving detailed insight on how to properly generate variability in the training dataset. Moreover, we analyze the fine-tuning process within the complex model of Mask-RCNN, understanding which weights should be transferred to the new task of segmenting robot hands. Our final model was trained solely on synthetic images and achieves an average IoU of 82% on synthetic validation data and 56.3% on real test data. These results were achieved with only 1000 training images and 3 hours of training time using a single GPU.