 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
See Clearer at Night: Towards Robust Nighttime Semantic Segmentation through Day-Night Image Conversion
Aug 16, 2019
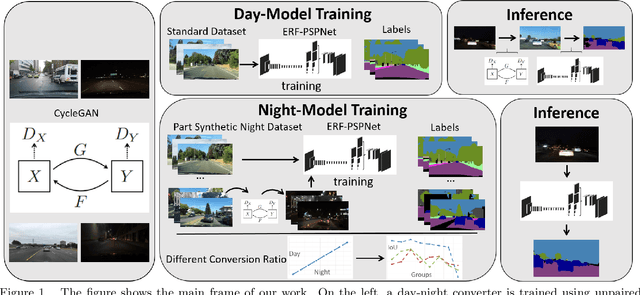
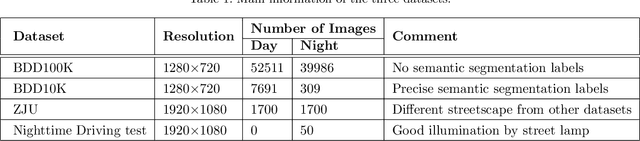


Currently, semantic segmentation shows remarkable efficiency and reliability in standard scenarios such as daytime scenes with favorable illumination conditions. However, in face of adverse conditions such as the nighttime, semantic segmentation loses its accuracy significantly. One of the main causes of the problem is the lack of sufficient annotated segmentation datasets of nighttime scenes. In this paper, we propose a framework to alleviate the accuracy decline when semantic segmentation is taken to adverse conditions by using Generative Adversarial Networks (GANs). To bridge the daytime and nighttime image domains, we made key observation that compared to datasets in adverse conditions, there are considerable amount of segmentation datasets in standard conditions such as BDD and our collected ZJU datasets. Our GAN-based nighttime semantic segmentation framework includes two methods. In the first method, GANs were used to translate nighttime images to the daytime, thus semantic segmentation can be performed using robust models already trained on daytime datasets. In another method, we use GANs to translate different ratio of daytime images in the dataset to the nighttime but still with their labels. In this sense, synthetic nighttime segmentation datasets can be generated to yield models prepared to operate at nighttime conditions robustly. In our experiment, the later method significantly boosts the performance at the nighttime evidenced by quantitative results using Intersection over Union (IoU) and Pixel Accuracy (Acc). We show that the performance varies with respect to the proportion of synthetic nighttime images in the dataset, where the sweet spot corresponds to most robust performance across the day and night.
Lunar Terrain Relative Navigation Using a Convolutional Neural Network for Visual Crater Detection
Jul 15, 2020
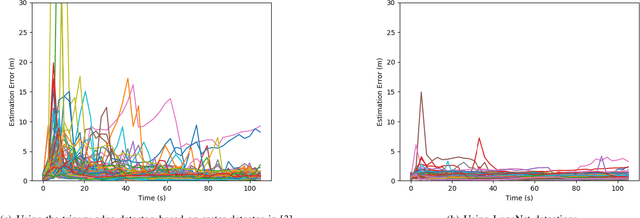
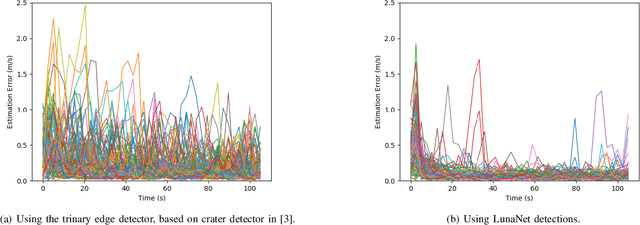
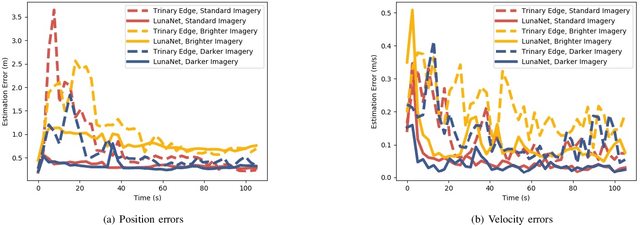
Terrain relative navigation can improve the precision of a spacecraft's position estimate by detecting global features that act as supplementary measurements to correct for drift in the inertial navigation system. This paper presents a system that uses a convolutional neural network (CNN) and image processing methods to track the location of a simulated spacecraft with an extended Kalman filter (EKF). The CNN, called LunaNet, visually detects craters in the simulated camera frame and those detections are matched to known lunar craters in the region of the current estimated spacecraft position. These matched craters are treated as features that are tracked using the EKF. LunaNet enables more reliable position tracking over a simulated trajectory due to its greater robustness to changes in image brightness and more repeatable crater detections from frame to frame throughout a trajectory. LunaNet combined with an EKF produces a decrease of 60% in the average final position estimation error and a decrease of 25% in average final velocity estimation error compared to an EKF using an image processing-based crater detection method when tested on trajectories using images of standard brightness.
Linear and Deformable Image Registration with 3D Convolutional Neural Networks
Sep 13, 2018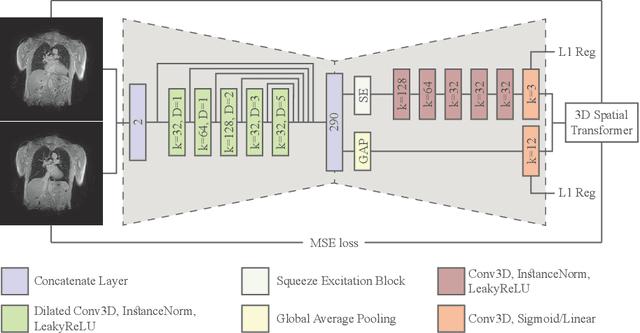
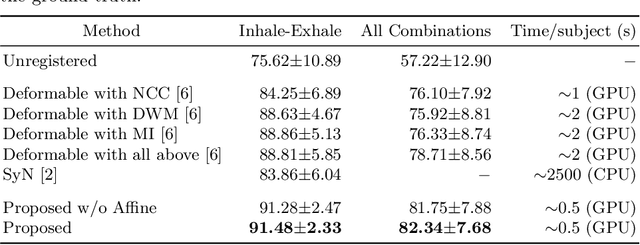

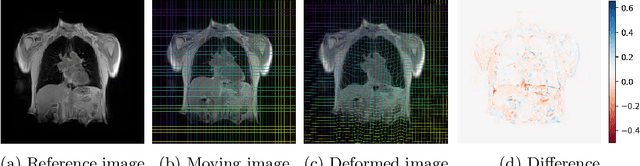
Image registration and in particular deformable registration methods are pillars of medical imaging. Inspired by the recent advances in deep learning, we propose in this paper, a novel convolutional neural network architecture that couples linear and deformable registration within a unified architecture endowed with near real-time performance. Our framework is modular with respect to the global transformation component, as well as with respect to the similarity function while it guarantees smooth displacement fields. We evaluate the performance of our network on the challenging problem of MRI lung registration, and demonstrate superior performance with respect to state of the art elastic registration methods. The proposed deformation (between inspiration & expiration) was considered within a clinically relevant task of interstitial lung disease (ILD) classification and showed promising results.
TGCN: Time Domain Graph Convolutional Network for Multiple Objects Tracking
Jan 06, 2021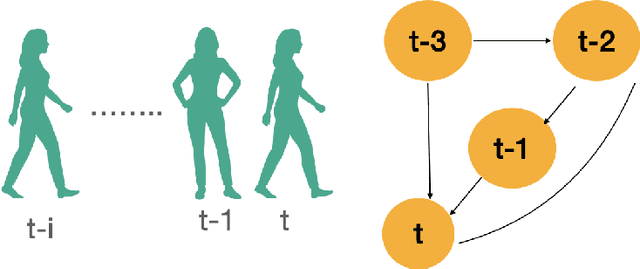

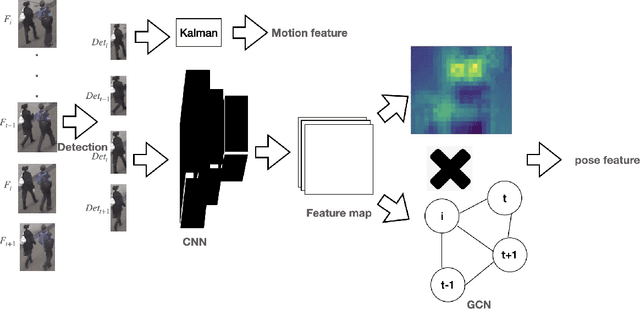

Multiple object tracking is to give each object an id in the video. The difficulty is how to match the predicted objects and detected objects in same frames. Matching features include appearance features, location features, etc. These features of the predicted object are basically based on some previous frames. However, few papers describe the relationship in the time domain between the previous frame features and the current frame features.In this paper, we proposed a time domain graph convolutional network for multiple objects tracking.The model is mainly divided into two parts, we first use convolutional neural network (CNN) to extract pedestrian appearance feature, which is a normal operation processing image in deep learning, then we use GCN to model some past frames' appearance feature to get the prediction appearance feature of the current frame. Due to this extension, we can get the pose features of the current frame according to the relationship between some frames in the past. Experimental evaluation shows that our extensions improve the MOTA by 1.3 on the MOT16, achieving overall competitive performance at high frame rates.
Image Semantic Transformation: Faster, Lighter and Stronger
Mar 27, 2018

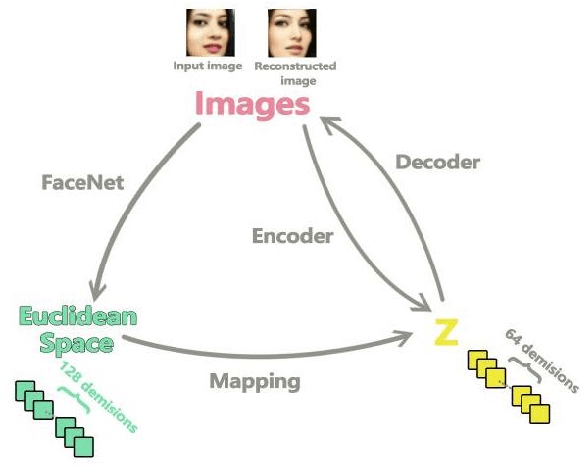
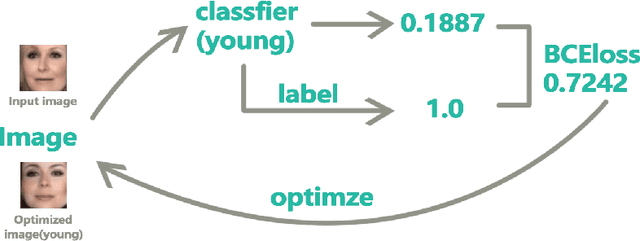
We propose Image-Semantic-Transformation-Reconstruction-Circle(ISTRC) model, a novel and powerful method using facenet's Euclidean latent space to understand the images. As the name suggests, ISTRC construct the circle, able to perfectly reconstruct images. One powerful Euclidean latent space embedded in ISTRC is FaceNet's last layer with the power of distinguishing and understanding images. Our model will reconstruct the images and manipulate Euclidean latent vectors to achieve semantic transformations and semantic images arthimetic calculations. In this paper, we show that ISTRC performs 10 high-level semantic transformations like "Male and female","add smile","open mouth", "deduct beard or add mustache", "bigger/smaller nose", "make older and younger", "bigger lips", "bigger eyes", "bigger/smaller mouths" and "more attractive". It just takes 3 hours(GTX 1080) to train the models of 10 semantic transformations.
The Benefit of Distraction: Denoising Remote Vitals Measurements using Inverse Attention
Oct 14, 2020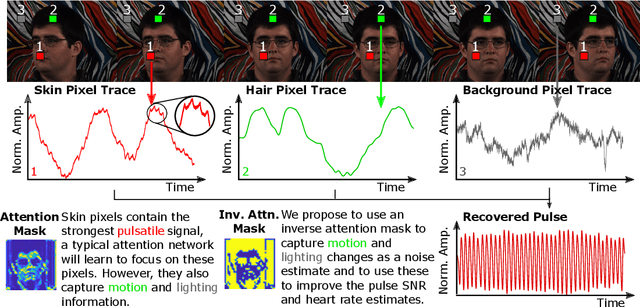
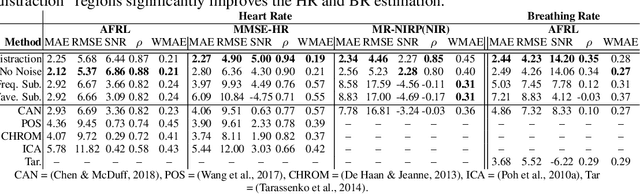
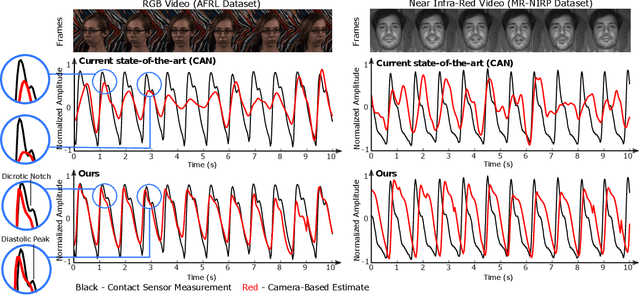
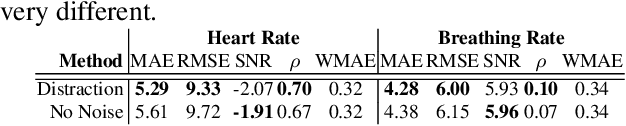
Attention is a powerful concept in computer vision. End-to-end networks that learn to focus selectively on regions of an image or video often perform strongly. However, other image regions, while not necessarily containing the signal of interest, may contain useful context. We present an approach that exploits the idea that statistics of noise may be shared between the regions that contain the signal of interest and those that do not. Our technique uses the inverse of an attention mask to generate a noise estimate that is then used to denoise temporal observations. We apply this to the task of camera-based physiological measurement. A convolutional attention network is used to learn which regions of a video contain the physiological signal and generate a preliminary estimate. A noise estimate is obtained by using the pixel intensities in the inverse regions of the learned attention mask, this in turn is used to refine the estimate of the physiological signal. We perform experiments on two large benchmark datasets and show that this approach produces state-of-the-art results, increasing the signal-to-noise ratio by up to 5.8 dB, reducing heart rate and breathing rate estimation error by as much as 30%, recovering subtle pulse waveform dynamics, and generalizing from RGB to NIR videos without retraining.
Distributional Ground Truth: Non-Redundant Crowdsourcing Data Quality Control in UI Labeling Tasks
Dec 25, 2020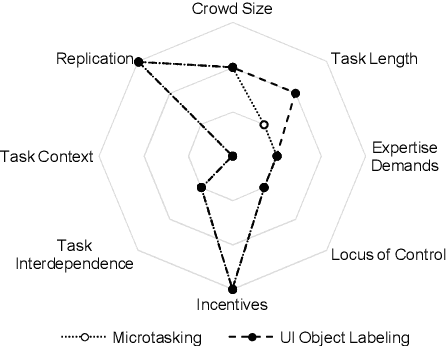
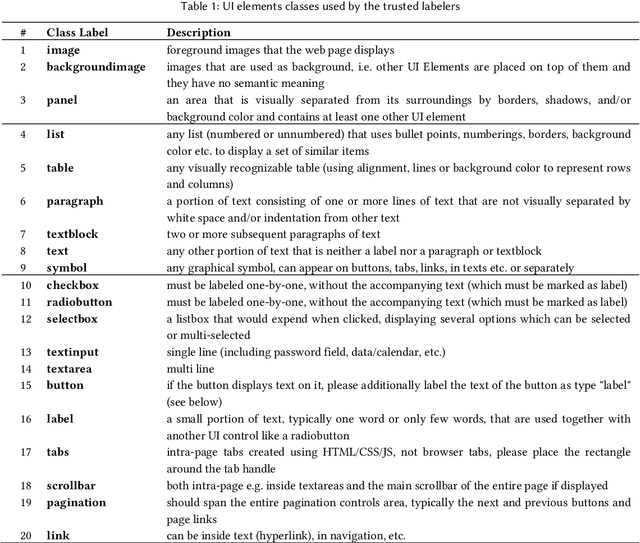

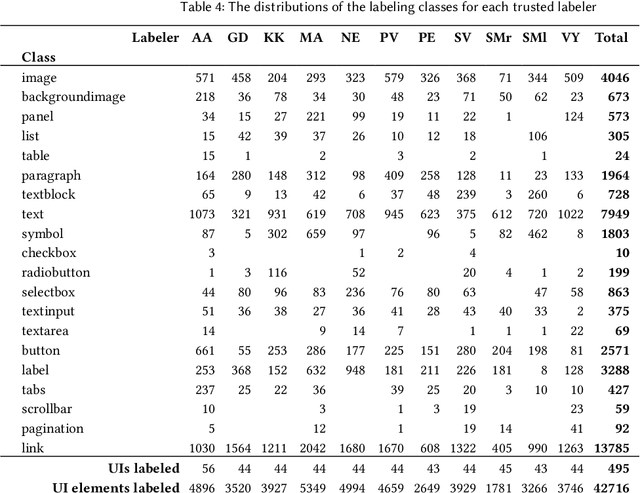
HCI increasingly employs Machine Learning and Image Recognition, in particular for visual analysis of user interfaces (UIs). A popular way for obtaining human-labeled training data is Crowdsourcing, typically using the quality control methods ground truth and majority consensus, which necessitate redundancy in the outcome. In our paper we propose a non-redundant method for prediction of crowdworkers' output quality in web UI labeling tasks, based on homogeneity of distributions assessed with two-sample Kolmogorov-Smirnov test. Using a dataset of about 500 screenshots with over 74,000 UI elements located and classified by 11 trusted labelers and 298 Amazon Mechanical Turk crowdworkers, we demonstrate the advantage of our approach over the baseline model based on mean Time-on-Task. Exploring different dataset partitions, we show that with the trusted set size of 17-27% UIs our "distributional ground truth" model can achieve R2s of over 0.8 and help to obviate the ancillary work effort and expenses.
CNN-based Visual Ego-Motion Estimation for Fast MAV Maneuvers
Jan 06, 2021
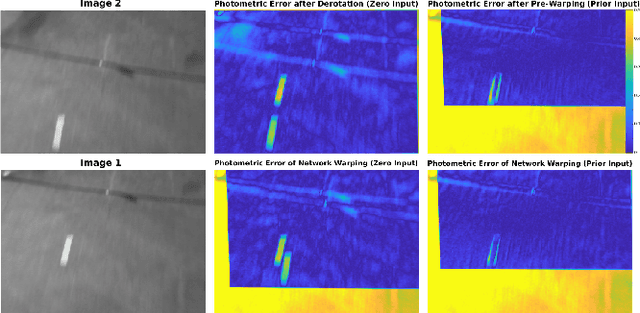
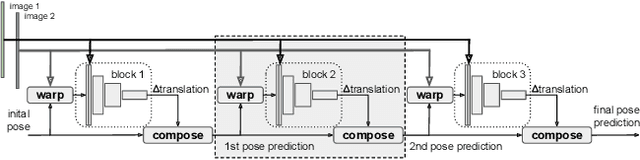

In the field of visual ego-motion estimation for Micro Air Vehicles (MAVs), fast maneuvers stay challenging mainly because of the big visual disparity and motion blur. In the pursuit of higher robustness, we study convolutional neural networks (CNNs) that predict the relative pose between subsequent images from a fast-moving monocular camera facing a planar scene. Aided by the Inertial Measurement Unit (IMU), we mainly focus on the translational motion. The networks we study have similar small model sizes (around 1.35MB) and high inference speeds (around 100Hz on a mobile GPU). Images for training and testing have realistic motion blur. Departing from a network framework that iteratively warps the first image to match the second with cascaded network blocks, we study different network architectures and training strategies. Simulated datasets and MAV flight datasets are used for evaluation. The proposed setup shows better accuracy over existing networks and traditional feature-point-based methods during fast maneuvers. Moreover, self-supervised learning outperforms supervised learning. The code developed for this paper will be open-source upon publication at https://github.com/tudelft/.
LEGAN: Disentangled Manipulation of Directional Lighting and Facial Expressions by Leveraging Human Perceptual Judgements
Oct 04, 2020
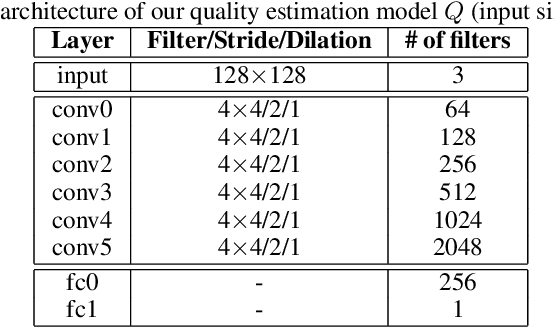
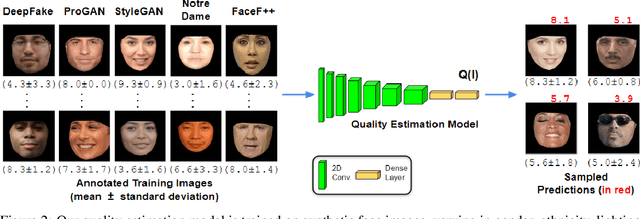
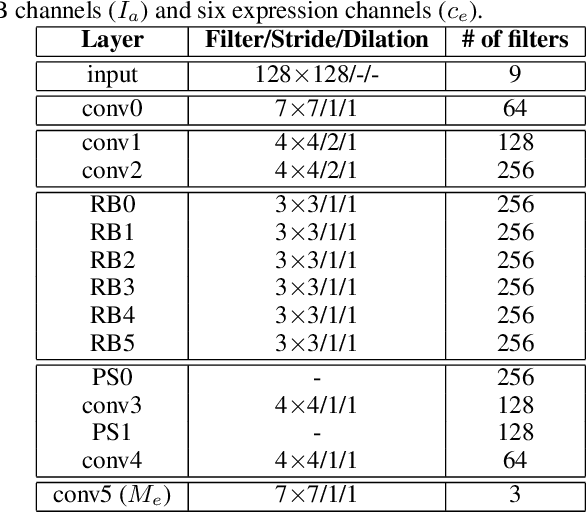
Building facial analysis systems that generalize to extreme variations in lighting and facial expressions is a challenging problem that can potentially be alleviated using natural-looking synthetic data. Towards that, we propose LEGAN, a novel synthesis framework that leverages perceptual quality judgments for jointly manipulating lighting and expressions in face images, without requiring paired training data. LEGAN disentangles the lighting and expression subspaces and performs transformations in the feature space before upscaling to the desired output image. The fidelity of the synthetic image is further refined by integrating a perceptual quality estimation model into the LEGAN framework as an auxiliary discriminator. The quality estimation model is learned from face images rendered using multiple synthesis methods and their crowd-sourced naturalness ratings using a margin-based regression loss. Using objective metrics like FID and LPIPS, LEGAN is shown to generate higher quality face images when compared with popular GAN models like pix2pix, CycleGAN and StarGAN for lighting and expression synthesis. We also conduct a perceptual study using images synthesized by LEGAN and other GAN models, trained with and without the quality based auxiliary discriminator, and show the correlation between our quality estimation and visual fidelity. Finally, we demonstrate the effectiveness of LEGAN as training data augmenter for expression recognition and face verification tasks.
FC-DCNN: A densely connected neural network for stereo estimation
Oct 14, 2020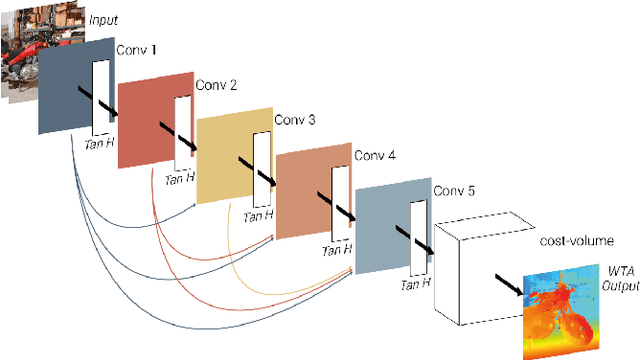


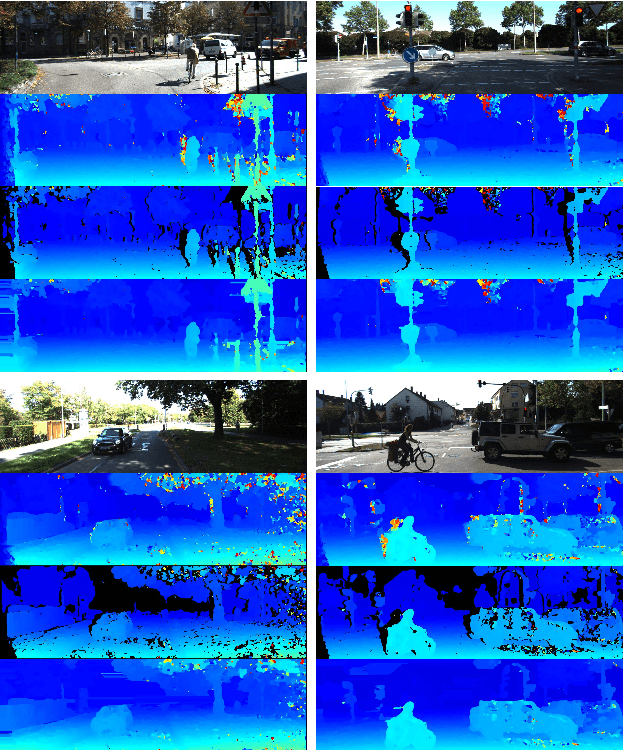
We propose a novel lightweight network for stereo estimation. Our network consists of a fully-convolutional densely connected neural network (FC-DCNN) that computes matching costs between rectified image pairs. Our FC-DCNN method learns expressive features and performs some simple but effective post-processing steps. The densely connected layer structure connects the output of each layer to the input of each subsequent layer. This network structure and the fact that we do not use any fully-connected layers or 3D convolutions leads to a very lightweight network. The output of this network is used in order to calculate matching costs and create a cost-volume. Instead of using time and memory-inefficient cost-aggregation methods such as semi-global matching or conditional random fields in order to improve the result, we rely on filtering techniques, namely median filter and guided filter. By computing a left-right consistency check we get rid of inconsistent values. Afterwards we use a watershed foreground-background segmentation on the disparity image with removed inconsistencies. This mask is then used to refine the final prediction. We show that our method works well for both challenging indoor and outdoor scenes by evaluating it on the Middlebury, KITTI and ETH3D benchmarks respectively. Our full framework is available at https://github.com/thedodo/FC-DCNN