 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Convolutional Recurrent Learning for Efficient Event-based Neuromorphic Object Detection
Jun 16, 2025Leveraging the high temporal resolution and dynamic range, object detection with event cameras can enhance the performance and safety of automotive and robotics applications in real-world scenarios. However, processing sparse event data requires compute-intensive convolutional recurrent units, complicating their integration into resource-constrained edge applications. Here, we propose the Sparse Event-based Efficient Detector (SEED) for efficient event-based object detection on neuromorphic processors. We introduce sparse convolutional recurrent learning, which achieves over 92% activation sparsity in recurrent processing, vastly reducing the cost for spatiotemporal reasoning on sparse event data. We validated our method on Prophesee's 1 Mpx and Gen1 event-based object detection datasets. Notably, SEED sets a new benchmark in computational efficiency for event-based object detection which requires long-term temporal learning. Compared to state-of-the-art methods, SEED significantly reduces synaptic operations while delivering higher or same-level mAP. Our hardware simulations showcase the critical role of SEED's hardware-aware design in achieving energy-efficient and low-latency neuromorphic processing.
Event-based Optical Flow on Neuromorphic Processor: ANN vs. SNN Comparison based on Activation Sparsification
Jul 29, 2024



Spiking neural networks (SNNs) for event-based optical flow are claimed to be computationally more efficient than their artificial neural networks (ANNs) counterparts, but a fair comparison is missing in the literature. In this work, we propose an event-based optical flow solution based on activation sparsification and a neuromorphic processor, SENECA. SENECA has an event-driven processing mechanism that can exploit the sparsity in ANN activations and SNN spikes to accelerate the inference of both types of neural networks. The ANN and the SNN for comparison have similar low activation/spike density (~5%) thanks to our novel sparsification-aware training. In the hardware-in-loop experiments designed to deduce the average time and energy consumption, the SNN consumes 44.9ms and 927.0 microjoules, which are 62.5% and 75.2% of the ANN's consumption, respectively. We find that SNN's higher efficiency attributes to its lower pixel-wise spike density (43.5% vs. 66.5%) that requires fewer memory access operations for neuron states.
TRIP: Trainable Region-of-Interest Prediction for Hardware-Efficient Neuromorphic Processing on Event-based Vision
Jun 25, 2024



Neuromorphic processors are well-suited for efficiently handling sparse events from event-based cameras. However, they face significant challenges in the growth of computing demand and hardware costs as the input resolution increases. This paper proposes the Trainable Region-of-Interest Prediction (TRIP), the first hardware-efficient hard attention framework for event-based vision processing on a neuromorphic processor. Our TRIP framework actively produces low-resolution Region-of-Interest (ROIs) for efficient and accurate classification. The framework exploits sparse events' inherent low information density to reduce the overhead of ROI prediction. We introduced extensive hardware-aware optimizations for TRIP and implemented the hardware-optimized algorithm on the SENECA neuromorphic processor. We utilized multiple event-based classification datasets for evaluation. Our approach achieves state-of-the-art accuracies in all datasets and produces reasonable ROIs with varying locations and sizes. On the DvsGesture dataset, our solution requires 46x less computation than the state-of-the-art while achieving higher accuracy. Furthermore, TRIP enables more than 2x latency and energy improvements on the SENECA neuromorphic processor compared to the conventional solution.
Fully neuromorphic vision and control for autonomous drone flight
Mar 15, 2023Biological sensing and processing is asynchronous and sparse, leading to low-latency and energy-efficient perception and action. In robotics, neuromorphic hardware for event-based vision and spiking neural networks promises to exhibit similar characteristics. However, robotic implementations have been limited to basic tasks with low-dimensional sensory inputs and motor actions due to the restricted network size in current embedded neuromorphic processors and the difficulties of training spiking neural networks. Here, we present the first fully neuromorphic vision-to-control pipeline for controlling a freely flying drone. Specifically, we train a spiking neural network that accepts high-dimensional raw event-based camera data and outputs low-level control actions for performing autonomous vision-based flight. The vision part of the network, consisting of five layers and 28.8k neurons, maps incoming raw events to ego-motion estimates and is trained with self-supervised learning on real event data. The control part consists of a single decoding layer and is learned with an evolutionary algorithm in a drone simulator. Robotic experiments show a successful sim-to-real transfer of the fully learned neuromorphic pipeline. The drone can accurately follow different ego-motion setpoints, allowing for hovering, landing, and maneuvering sideways$\unicode{x2014}$even while yawing at the same time. The neuromorphic pipeline runs on board on Intel's Loihi neuromorphic processor with an execution frequency of 200 Hz, spending only 27 $\unicode{x00b5}$J per inference. These results illustrate the potential of neuromorphic sensing and processing for enabling smaller, more intelligent robots.
CUAHN-VIO: Content-and-Uncertainty-Aware Homography Network for Visual-Inertial Odometry
Aug 30, 2022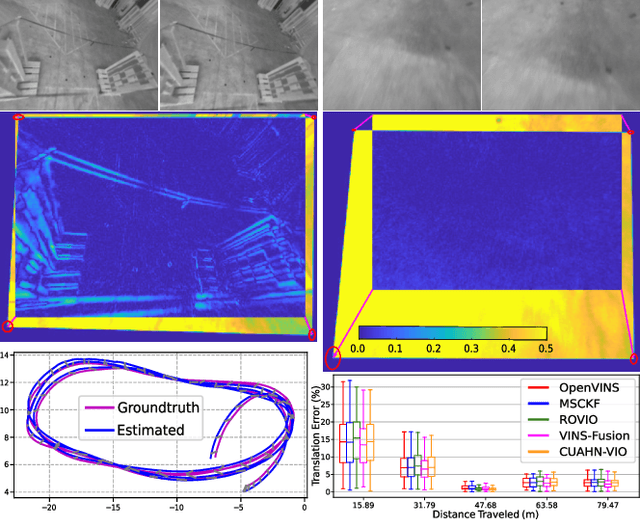

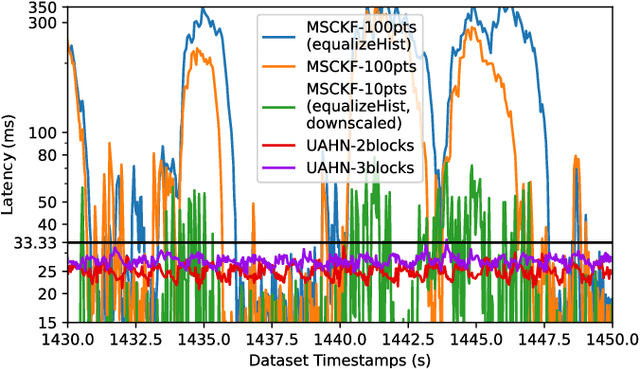
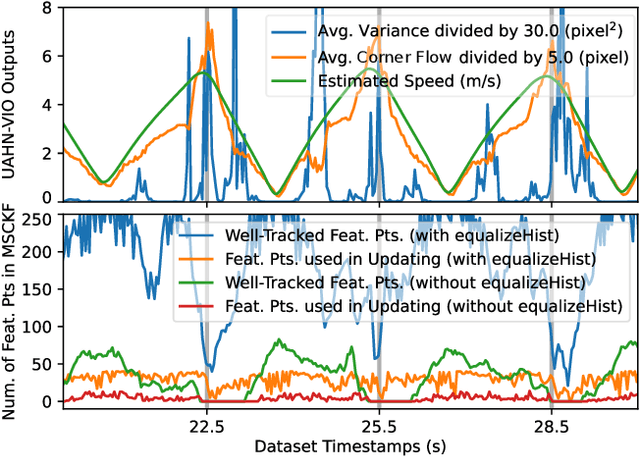
Learning-based visual ego-motion estimation is promising yet not ready for navigating agile mobile robots in the real world. In this article, we propose CUAHN-VIO, a robust and efficient monocular visual-inertial odometry (VIO) designed for micro aerial vehicles (MAVs) equipped with a downward-facing camera. The vision frontend is a content-and-uncertainty-aware homography network (CUAHN) that is robust to non-homography image content and failure cases of network prediction. It not only predicts the homography transformation but also estimates its uncertainty. The training is self-supervised, so that it does not require ground truth that is often difficult to obtain. The network has good generalization that enables "plug-and-play" deployment in new environments without fine-tuning. A lightweight extended Kalman filter (EKF) serves as the VIO backend and utilizes the mean prediction and variance estimation from the network for visual measurement updates. CUAHN-VIO is evaluated on a high-speed public dataset and shows rivaling accuracy to state-of-the-art (SOTA) VIO approaches. Thanks to the robustness to motion blur, low network inference time (~23ms), and stable processing latency (~26ms), CUAHN-VIO successfully runs onboard an Nvidia Jetson TX2 embedded processor to navigate a fast autonomous MAV.
CNN-based Visual Ego-Motion Estimation for Fast MAV Maneuvers
Jan 06, 2021
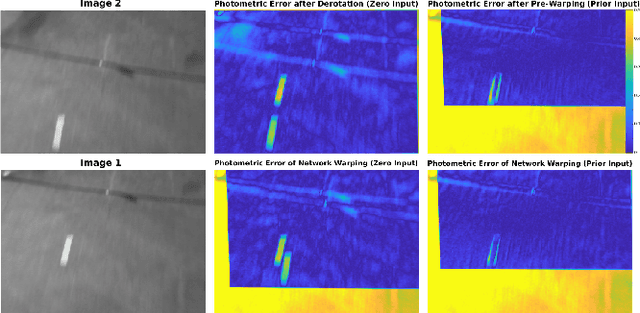
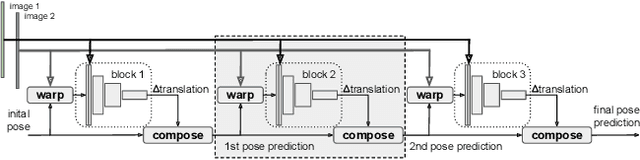

In the field of visual ego-motion estimation for Micro Air Vehicles (MAVs), fast maneuvers stay challenging mainly because of the big visual disparity and motion blur. In the pursuit of higher robustness, we study convolutional neural networks (CNNs) that predict the relative pose between subsequent images from a fast-moving monocular camera facing a planar scene. Aided by the Inertial Measurement Unit (IMU), we mainly focus on the translational motion. The networks we study have similar small model sizes (around 1.35MB) and high inference speeds (around 100Hz on a mobile GPU). Images for training and testing have realistic motion blur. Departing from a network framework that iteratively warps the first image to match the second with cascaded network blocks, we study different network architectures and training strategies. Simulated datasets and MAV flight datasets are used for evaluation. The proposed setup shows better accuracy over existing networks and traditional feature-point-based methods during fast maneuvers. Moreover, self-supervised learning outperforms supervised learning. The code developed for this paper will be open-source upon publication at https://github.com/tudelft/.