 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Classification and Optimized Image Reproduction
Sep 23, 2012

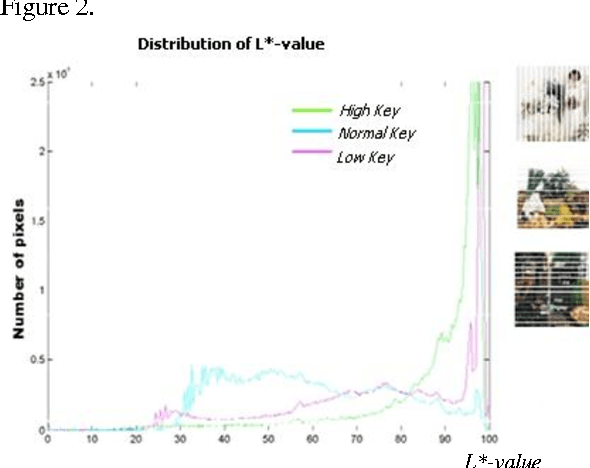
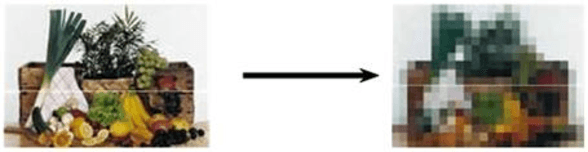
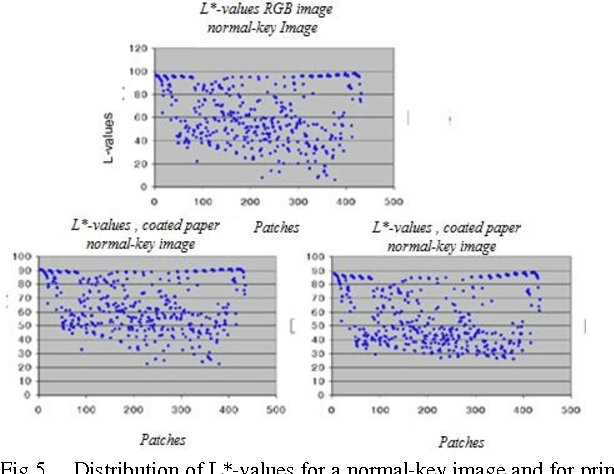
By taking into account the properties and limitations of the human visual system, images can be more efficiently compressed, colors more accurately reproduced, prints better rendered. To show all these advantages in this paper new adapted color charts have been created based on technical and visual image category analysis. A number of tests have been carried out using extreme images with their key information strictly in dark and light areas. It was shown that the image categorization using the adapted color charts improves the analysis of relevant image information with regard to both the image gradation and the detail reproduction. The images with key information in hi-key areas were also test printed using the adapted color charts.
* 5 Pages, 9 Figures
Incident Light Frequency-based Image Defogging Algorithm
Mar 03, 2017



Considering the problem of color distortion caused by the defogging algorithm based on dark channel prior, an improved algorithm was proposed to calculate the transmittance of all channels respectively. First, incident light frequency's effect on the transmittance of various color channels was analyzed according to the Beer-Lambert's Law, from which a proportion among various channel transmittances was derived; afterwards, images were preprocessed by down-sampling to refine transmittance, and then the original size was restored to enhance the operational efficiency of the algorithm; finally, the transmittance of all color channels was acquired in accordance with the proportion, and then the corresponding transmittance was used for image restoration in each channel. The experimental results show that compared with the existing algorithm, this improved image defogging algorithm could make image colors more natural, solve the problem of slightly higher color saturation caused by the existing algorithm, and shorten the operation time by four to nine times.
Defending Adversarial Examples via DNN Bottleneck Reinforcement
Aug 12, 2020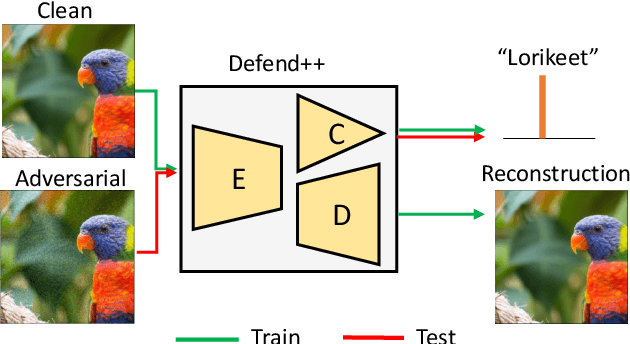
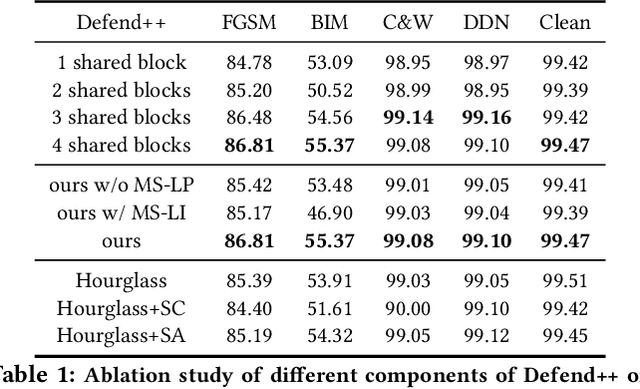

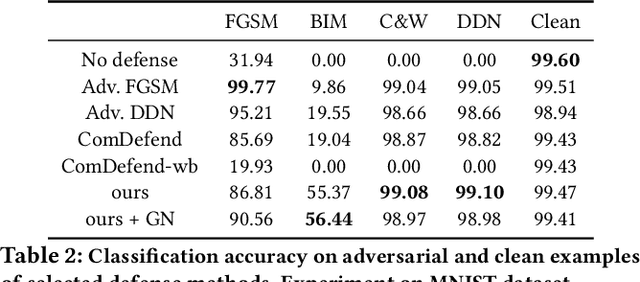
This paper presents a DNN bottleneck reinforcement scheme to alleviate the vulnerability of Deep Neural Networks (DNN) against adversarial attacks. Typical DNN classifiers encode the input image into a compressed latent representation more suitable for inference. This information bottleneck makes a trade-off between the image-specific structure and class-specific information in an image. By reinforcing the former while maintaining the latter, any redundant information, be it adversarial or not, should be removed from the latent representation. Hence, this paper proposes to jointly train an auto-encoder (AE) sharing the same encoding weights with the visual classifier. In order to reinforce the information bottleneck, we introduce the multi-scale low-pass objective and multi-scale high-frequency communication for better frequency steering in the network. Unlike existing approaches, our scheme is the first reforming defense per se which keeps the classifier structure untouched without appending any pre-processing head and is trained with clean images only. Extensive experiments on MNIST, CIFAR-10 and ImageNet demonstrate the strong defense of our method against various adversarial attacks.
Retrospective Motion Correction of MR Images using Prior-Assisted Deep Learning
Nov 28, 2020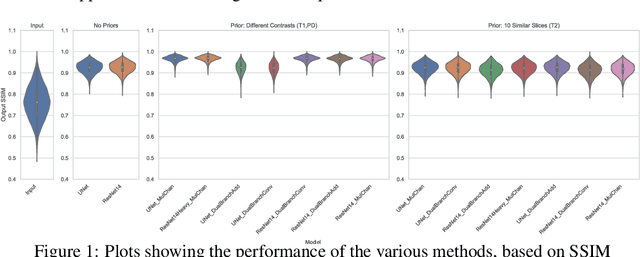
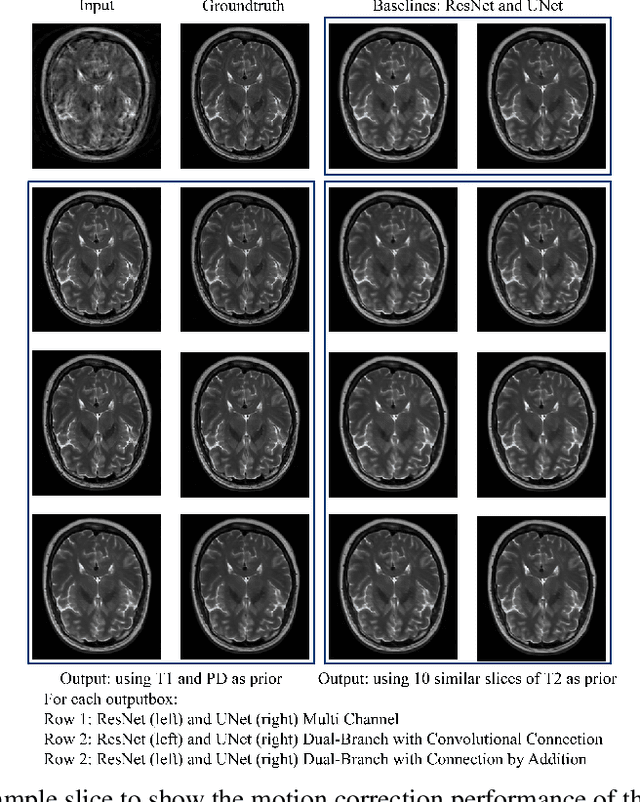
In MRI, motion artefacts are among the most common types of artefacts. They can degrade images and render them unusable for accurate diagnosis. Traditional methods, such as prospective or retrospective motion correction, have been proposed to avoid or alleviate motion artefacts. Recently, several other methods based on deep learning approaches have been proposed to solve this problem. This work proposes to enhance the performance of existing deep learning models by the inclusion of additional information present as image priors. The proposed approach has shown promising results and will be further investigated for clinical validity.
Generative Cooperative Net for Image Generation and Data Augmentation
Feb 08, 2018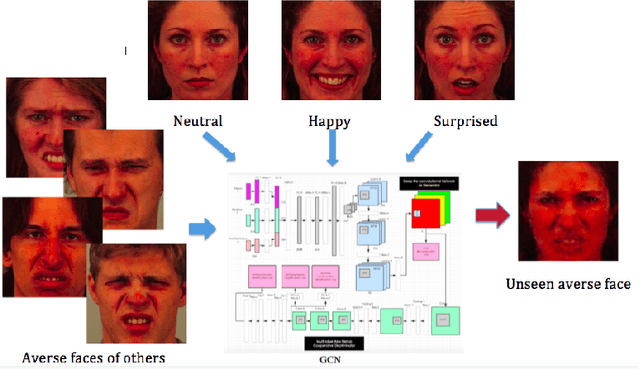
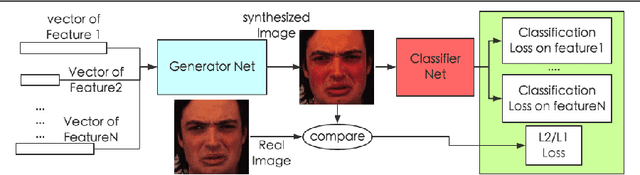
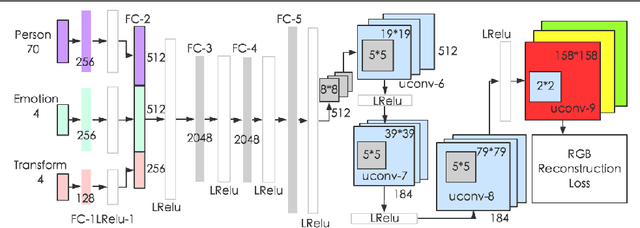
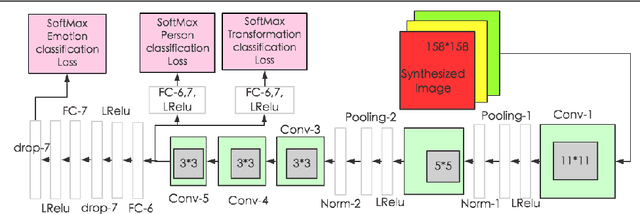
How to build a good model for image generation given an abstract concept is a fundamental problem in computer vision. In this paper, we explore a generative model for the task of generating unseen images with desired features. We propose the Generative Cooperative Net (GCN) for image generation. The idea is similar to generative adversarial networks except that the generators and discriminators are trained to work accordingly. Our experiments on hand-written digit generation and facial expression generation show that GCN's two cooperative counterparts (the generator and the classifier) can work together nicely and achieve promising results. We also discovered a usage of such generative model as an data-augmentation tool. Our experiment of applying this method on a recognition task shows that it is very effective comparing to other existing methods. It is easy to set up and could help generate a very large synthesized dataset.
Adversarially Approximated Autoencoder for Image Generation and Manipulation
Feb 14, 2019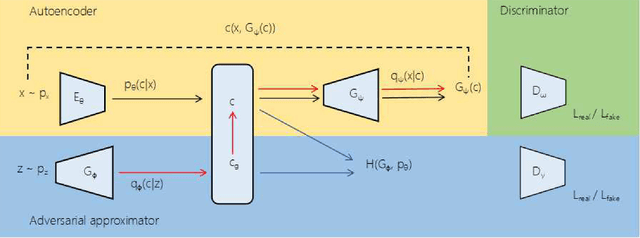
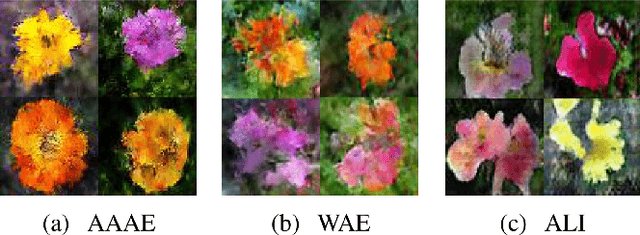


Regularized autoencoders learn the latent codes, a structure with the regularization under the distribution, which enables them the capability to infer the latent codes given observations and generate new samples given the codes. However, they are sometimes ambiguous as they tend to produce reconstructions that are not necessarily faithful reproduction of the inputs. The main reason is to enforce the learned latent code distribution to match a prior distribution while the true distribution remains unknown. To improve the reconstruction quality and learn the latent space a manifold structure, this work present a novel approach using the adversarially approximated autoencoder (AAAE) to investigate the latent codes with adversarial approximation. Instead of regularizing the latent codes by penalizing on the distance between the distributions of the model and the target, AAAE learns the autoencoder flexibly and approximates the latent space with a simpler generator. The ratio is estimated using generative adversarial network (GAN) to enforce the similarity of the distributions. Additionally, the image space is regularized with an additional adversarial regularizer. The proposed approach unifies two deep generative models for both latent space inference and diverse generation. The learning scheme is realized without regularization on the latent codes, which also encourages faithful reconstruction. Extensive validation experiments on four real-world datasets demonstrate the superior performance of AAAE. In comparison to the state-of-the-art approaches, AAAE generates samples with better quality and shares the properties of regularized autoencoder with a nice latent manifold structure.
Back-Projection Pipeline
Jan 25, 2021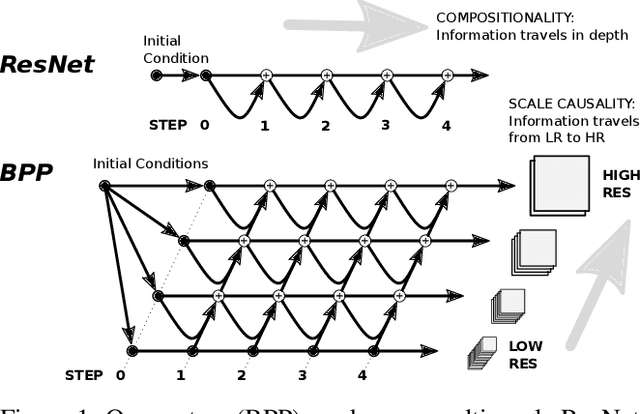
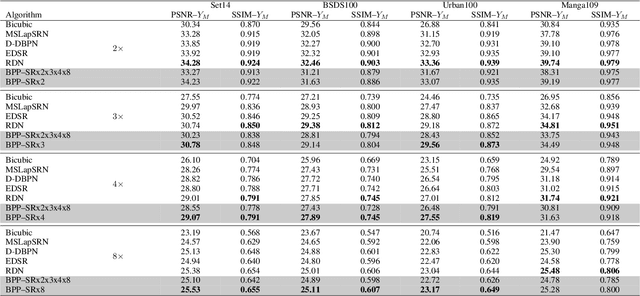
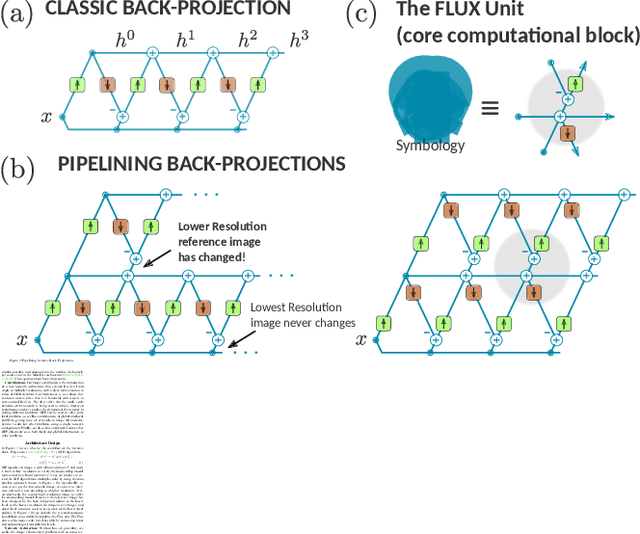
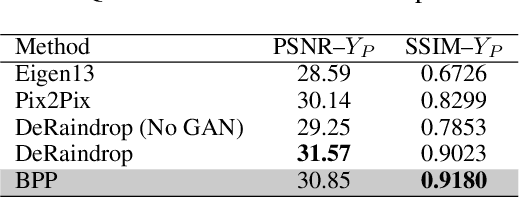
We propose a simple extension of residual networks that works simultaneously in multiple resolutions. Our network design is inspired by the iterative back-projection algorithm but seeks the more difficult task of learning how to enhance images. Compared to similar approaches, we propose a novel solution to make back-projections run in multiple resolutions by using a data pipeline workflow. Features are updated at multiple scales in each layer of the network. The update dynamic through these layers includes interactions between different resolutions in a way that is causal in scale, and it is represented by a system of ODEs, as opposed to a single ODE in the case of ResNets. The system can be used as a generic multi-resolution approach to enhance images. We test it on several challenging tasks with special focus on super-resolution and raindrop removal. Our results are competitive with state-of-the-arts and show a strong ability of our system to learn both global and local image features.
Universal Denoising Networks : A Novel CNN Architecture for Image Denoising
Mar 24, 2018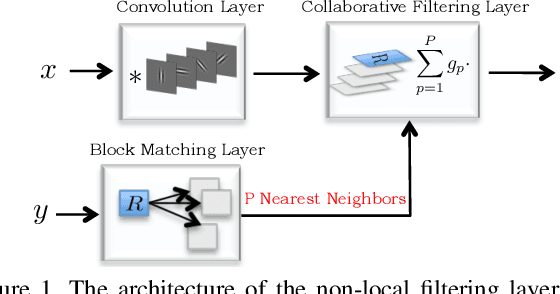
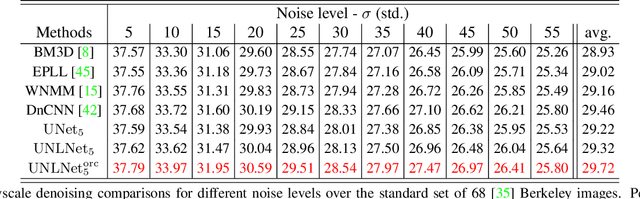
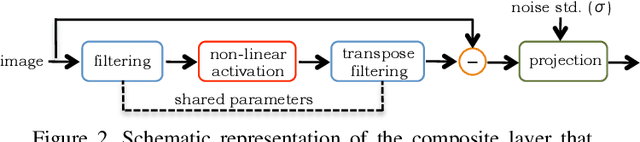
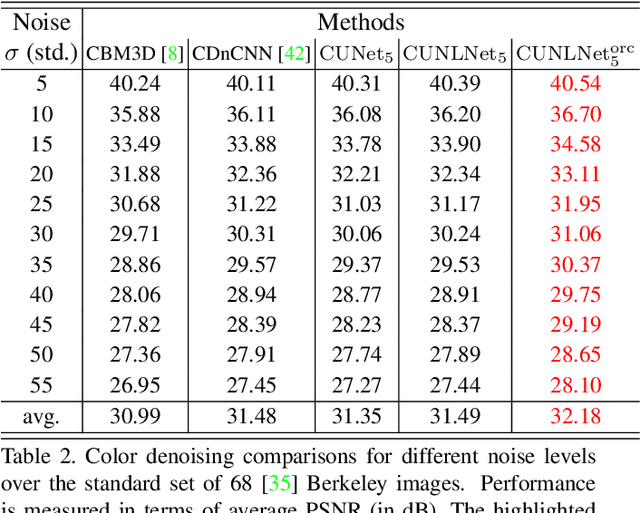
We design a novel network architecture for learning discriminative image models that are employed to efficiently tackle the problem of grayscale and color image denoising. Based on the proposed architecture, we introduce two different variants. The first network involves convolutional layers as a core component, while the second one relies instead on non-local filtering layers and thus it is able to exploit the inherent non-local self-similarity property of natural images. As opposed to most of the existing deep network approaches, which require the training of a specific model for each considered noise level, the proposed models are able to handle a wide range of noise levels using a single set of learned parameters, while they are very robust when the noise degrading the latent image does not match the statistics of the noise used during training. The latter argument is supported by results that we report on publicly available images corrupted by unknown noise and which we compare against solutions obtained by competing methods. At the same time the introduced networks achieve excellent results under additive white Gaussian noise (AWGN), which are comparable to those of the current state-of-the-art network, while they depend on a more shallow architecture with the number of trained parameters being one order of magnitude smaller. These properties make the proposed networks ideal candidates to serve as sub-solvers on restoration methods that deal with general inverse imaging problems such as deblurring, demosaicking, superresolution, etc.
Ordinal Neural Network Transformation Models: Deep and interpretable regression models for ordinal outcomes
Oct 16, 2020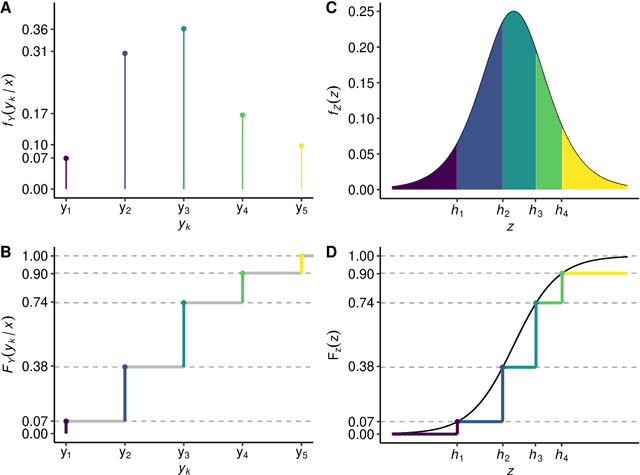
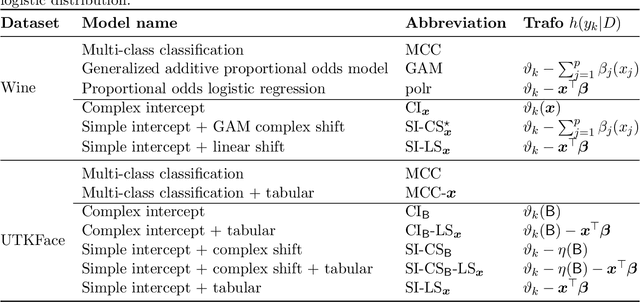
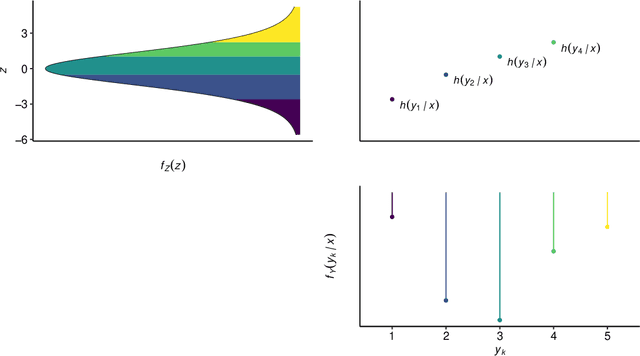
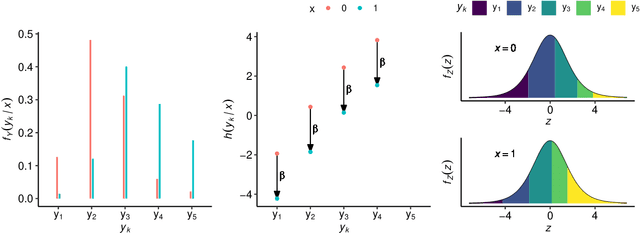
Outcomes with a natural order, such as quality of life scores or movie ratings, commonly occur in prediction tasks. The available input data are often a mixture of complex inputs like images and tabular predictors. Deep Learning (DL) methods have shown outstanding performances on perceptual tasks. Yet, most DL applications treat ordered outcomes as unordered classes and lack interpretability of individual predictors. In contrast, traditional ordinal regression models are specific for ordered outcomes and enable to interpret predictor effects but are limited to tabular input data. Here, we present the highly modular class of ordinal neural network transformation models (ONTRAMs) which can include both tabular and complex data using multiple neural networks. All neural networks are jointly trained to optimize the likelihood, which is parametrized to take the outcome's natural order into account. We recapitulate statistical ordinal regression models and discuss how they can be understood as transformation models. Transformation models use a parametric transformation function and a simple distribution, the former of which determines the flexibility and interpretability of the individual model components. We demonstrate how to set up interpretable ONTRAMs with tabular and/or image data. We show that the most flexible ONTRAMs achieve on-par performance with existing DL approaches while outperforming them in training speed. We highlight that ONTRAMs with image and tabular predictors yield correct effect estimates while keeping the high prediction performance of DL methods. We showcase how to interpret individual components of ONTRAMs and discuss the case where the included tabular predictors are correlated with the image data. In this work, we demonstrate how to join the benefits of DL and statistical regression methods to create efficient and interpretable models for ordinal outcomes.
EEC: Learning to Encode and Regenerate Images for Continual Learning
Jan 13, 2021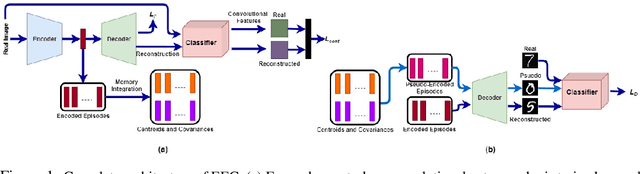
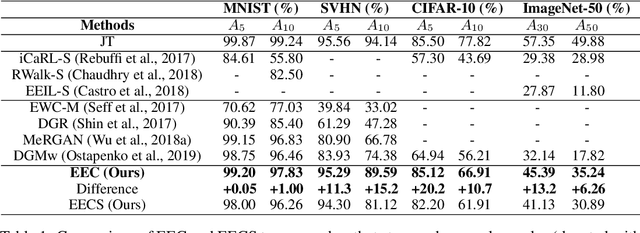

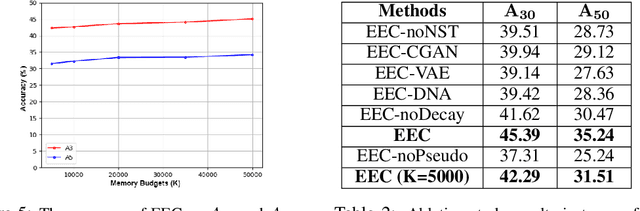
The two main impediments to continual learning are catastrophic forgetting and memory limitations on the storage of data. To cope with these challenges, we propose a novel, cognitively-inspired approach which trains autoencoders with Neural Style Transfer to encode and store images. During training on a new task, reconstructed images from encoded episodes are replayed in order to avoid catastrophic forgetting. The loss function for the reconstructed images is weighted to reduce its effect during classifier training to cope with image degradation. When the system runs out of memory the encoded episodes are converted into centroids and covariance matrices, which are used to generate pseudo-images during classifier training, keeping classifier performance stable while using less memory. Our approach increases classification accuracy by 13-17% over state-of-the-art methods on benchmark datasets, while requiring 78% less storage space.