 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vertical Look at UAV Connectivity in the Wild: Cellular vs. Starlink, 3D Characterization, and Performance Prediction
May 28, 2026In this paper, we present an open-source measurement platform designed to characterize the performance of commercial cellular (Verizon, a major US provider) and LEO satellite (Starlink) networks through real-world flight tests in rural environments. We implement a comprehensive multi-layer measurement approach spanning physical layer signal metrics, multi-cell network topology, and end-to-end (E2E) application performance. Through an extensive flight campaign with more than $10$ flight tests, $4.5$+ hours of flight time resulting in more than $18$K samples, we present the first detailed, open-source dataset analyzing dual cellular and Starlink performance for low-altitude UAV operations. Our cellular-Starlink comparative results, which are collected \emph{simultaneously at the same time and location}, demonstrate significant performance differences between the two technologies: the LEO satellite link achieves superior latency performance with $95\%$ of Round-Trip Time (RTT) measurements below $50$ ms compared to $80\%$ under $150$ ms for cellular, and exceptional downlink capacity with $95\%$ exceeding $25$ Mbps versus only $5$ Mbps for cellular. Our analysis on cellular network performance demonstrates that while higher altitudes (e.g., $330+$ m above the sea level) improve signal power by $15-20$ dB via line-of-sight (LOS) propagation, it causes a $3-4$ $\times$ increase in handover rates, which is due to excessive multi-cell visibility rather than signal degradation. Furthermore, we observe asymmetric impacts on the RTT performance due to handovers such that $53.5$\% of handovers improve RTT, but worst-case degradation ($275$ ms) is $2$ $\times$ larger than best-case improvement ($137$ ms).
Stacked Wasserstein Autoencoder
Oct 04, 2019
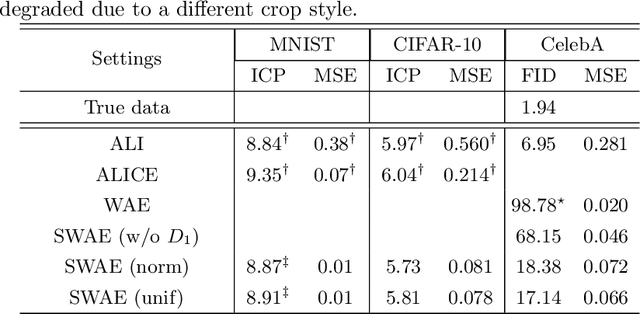
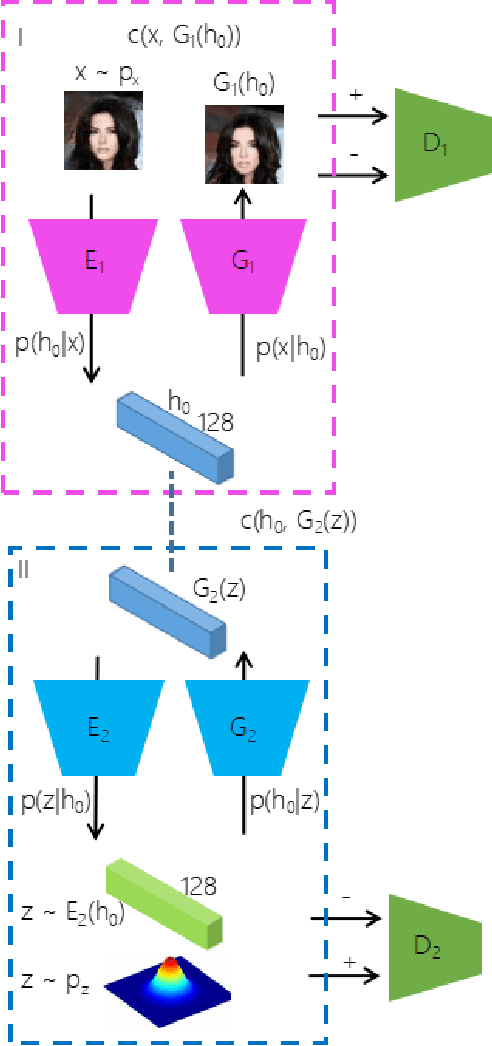
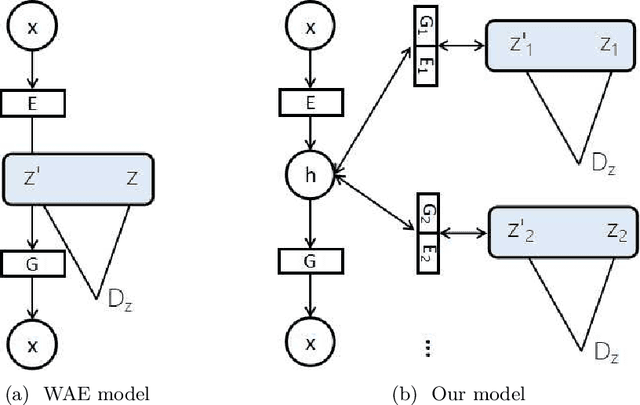
Approximating distributions over complicated manifolds, such as natural images, are conceptually attractive. The deep latent variable model, trained using variational autoencoders and generative adversarial networks, is now a key technique for representation learning. However, it is difficult to unify these two models for exact latent-variable inference and parallelize both reconstruction and sampling, partly due to the regularization under the latent variables, to match a simple explicit prior distribution. These approaches are prone to be oversimplified, and can only characterize a few modes of the true distribution. Based on the recently proposed Wasserstein autoencoder (WAE) with a new regularization as an optimal transport. The paper proposes a stacked Wasserstein autoencoder (SWAE) to learn a deep latent variable model. SWAE is a hierarchical model, which relaxes the optimal transport constraints at two stages. At the first stage, the SWAE flexibly learns a representation distribution, i.e., the encoded prior; and at the second stage, the encoded representation distribution is approximated with a latent variable model under the regularization encouraging the latent distribution to match the explicit prior. This model allows us to generate natural textual outputs as well as perform manipulations in the latent space to induce changes in the output space. Both quantitative and qualitative results demonstrate the superior performance of SWAE compared with the state-of-the-art approaches in terms of faithful reconstruction and generation quality.
Toward Learning a Unified Many-to-Many Mapping for Diverse Image Translation
May 21, 2019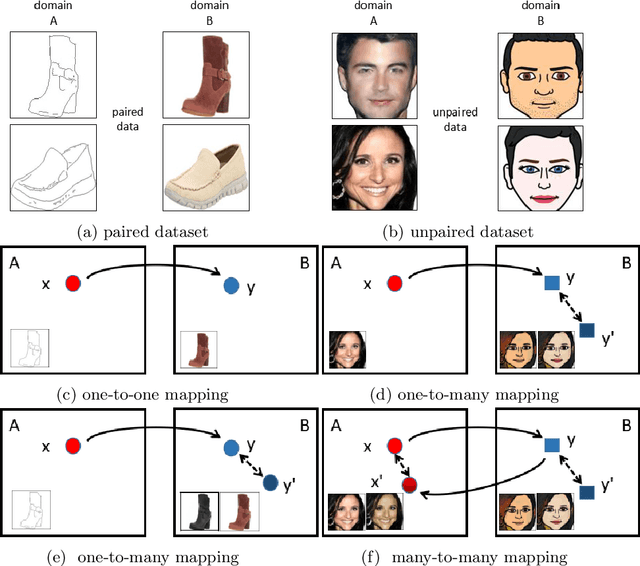

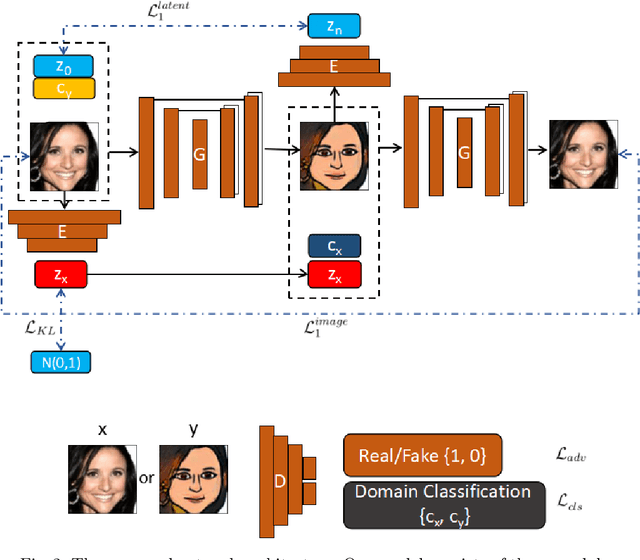
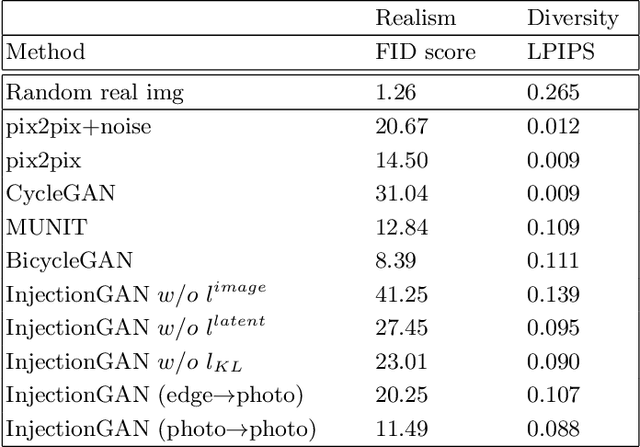
Image-to-image translation, which translates input images to a different domain with a learned one-to-one mapping, has achieved impressive success in recent years. The success of translation mainly relies on the network architecture to reserve the structural information while modify the appearance slightly at the pixel level through adversarial training. Although these networks are able to learn the mapping, the translated images are predictable without exclusion. It is more desirable to diversify them using image-to-image translation by introducing uncertainties, i.e., the generated images hold potential for variations in colors and textures in addition to the general similarity to the input images, and this happens in both the target and source domains. To this end, we propose a novel generative adversarial network (GAN) based model, InjectionGAN, to learn a many-to-many mapping. In this model, the input image is combined with latent variables, which comprise of domain-specific attribute and unspecific random variations. The domain-specific attribute indicates the target domain of the translation, while the unspecific random variations introduce uncertainty into the model. A unified framework is proposed to regroup these two parts and obtain diverse generations in each domain. Extensive experiments demonstrate that the diverse generations have high quality for the challenging image-to-image translation tasks where no pairing information of the training dataset exits. Both quantitative and qualitative results prove the superior performance of InjectionGAN over the state-of-the-art approaches.
Adversarially Approximated Autoencoder for Image Generation and Manipulation
Feb 14, 2019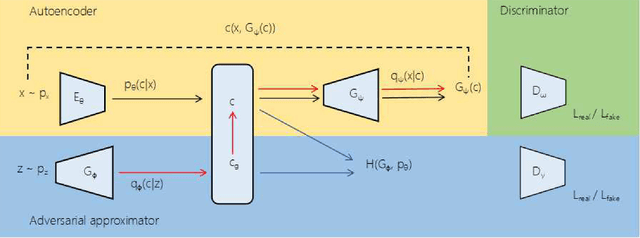
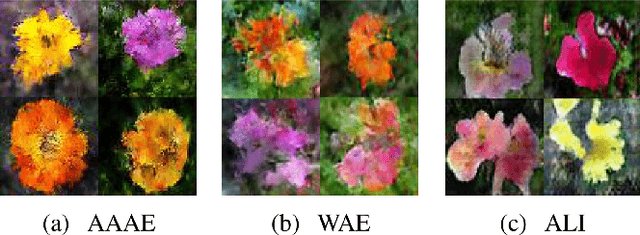


Regularized autoencoders learn the latent codes, a structure with the regularization under the distribution, which enables them the capability to infer the latent codes given observations and generate new samples given the codes. However, they are sometimes ambiguous as they tend to produce reconstructions that are not necessarily faithful reproduction of the inputs. The main reason is to enforce the learned latent code distribution to match a prior distribution while the true distribution remains unknown. To improve the reconstruction quality and learn the latent space a manifold structure, this work present a novel approach using the adversarially approximated autoencoder (AAAE) to investigate the latent codes with adversarial approximation. Instead of regularizing the latent codes by penalizing on the distance between the distributions of the model and the target, AAAE learns the autoencoder flexibly and approximates the latent space with a simpler generator. The ratio is estimated using generative adversarial network (GAN) to enforce the similarity of the distributions. Additionally, the image space is regularized with an additional adversarial regularizer. The proposed approach unifies two deep generative models for both latent space inference and diverse generation. The learning scheme is realized without regularization on the latent codes, which also encourages faithful reconstruction. Extensive validation experiments on four real-world datasets demonstrate the superior performance of AAAE. In comparison to the state-of-the-art approaches, AAAE generates samples with better quality and shares the properties of regularized autoencoder with a nice latent manifold structure.