 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Advancing Eosinophilic Esophagitis Diagnosis and Phenotype Assessment with Deep Learning Computer Vision
Jan 13, 2021
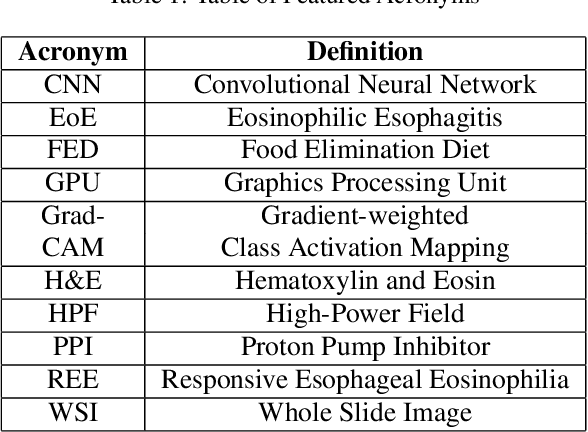
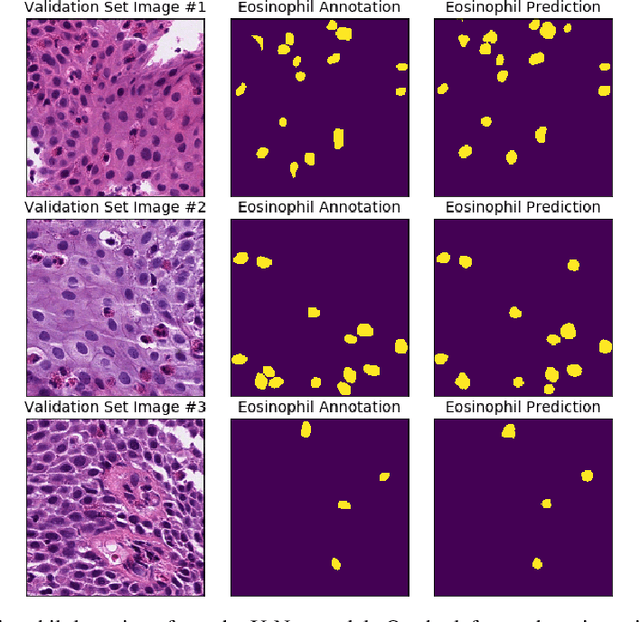
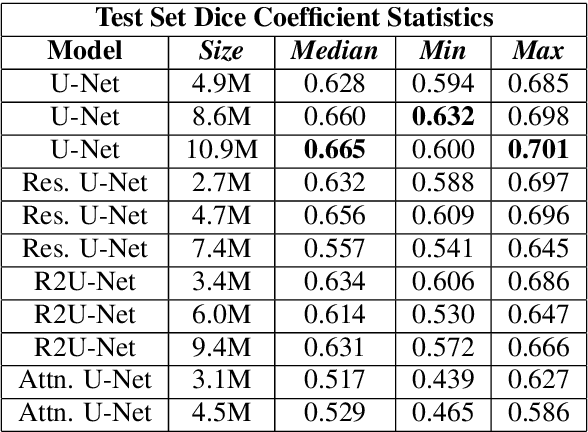
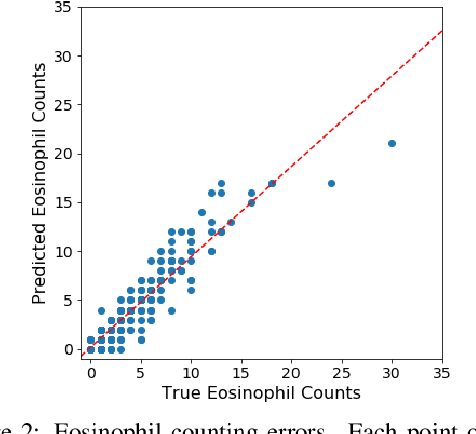
Eosinophilic Esophagitis (EoE) is an inflammatory esophageal disease which is increasing in prevalence. The diagnostic gold-standard involves manual review of a patient's biopsy tissue sample by a clinical pathologist for the presence of 15 or greater eosinophils within a single high-power field (400x magnification). Diagnosing EoE can be a cumbersome process with added difficulty for assessing the severity and progression of disease. We propose an automated approach for quantifying eosinophils using deep image segmentation. A U-Net model and post-processing system are applied to generate eosinophil-based statistics that can diagnose EoE as well as describe disease severity and progression. These statistics are captured in biopsies at the initial EoE diagnosis and are then compared with patient metadata: clinical and treatment phenotypes. The goal is to find linkages that could potentially guide treatment plans for new patients at their initial disease diagnosis. A deep image classification model is further applied to discover features other than eosinophils that can be used to diagnose EoE. This is the first study to utilize a deep learning computer vision approach for EoE diagnosis and to provide an automated process for tracking disease severity and progression.
Medical Image Analysis using Convolutional Neural Networks: A Review
Sep 04, 2017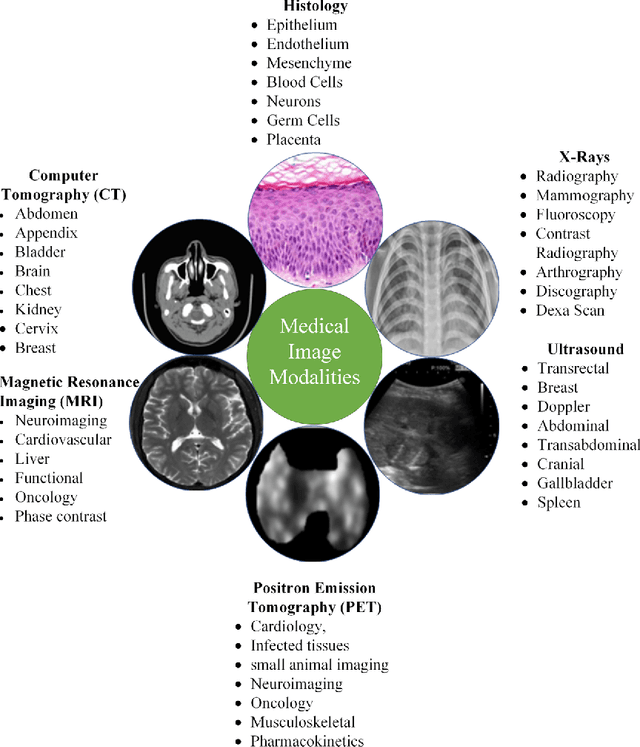
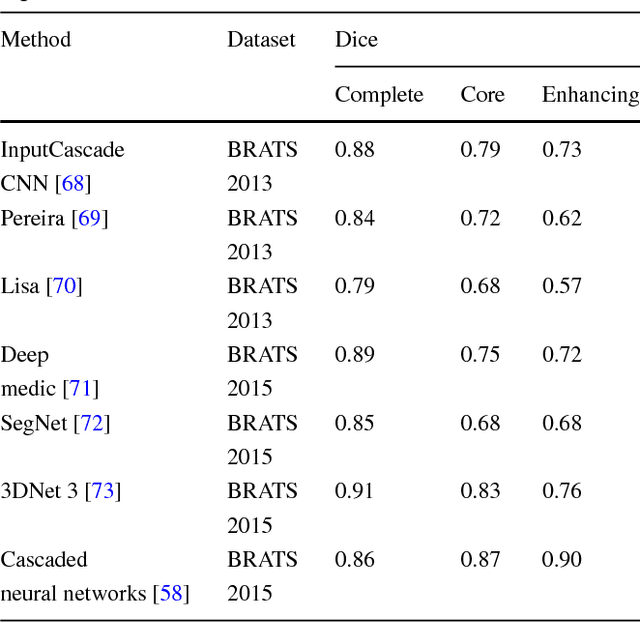
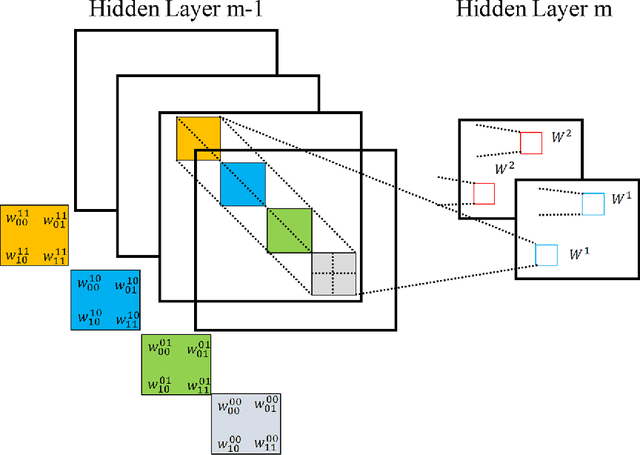
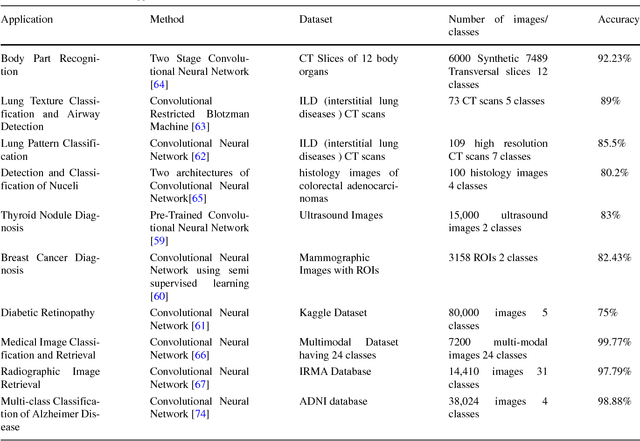
Medical image analysis is the science of analyzing or solving medical problems using different image analysis techniques for affective and efficient extraction of information. It has emerged as one of the top research area in the field of engineering and medicine. Recent years have witnessed rapid use of machine learning algorithms in medical image analysis. These machine learning techniques are used to extract compact information for improved performance of medical image analysis system, when compared to the traditional methods that use extraction of handcrafted features. Deep learning is a breakthrough in machine learning techniques that has overwhelmed the field of pattern recognition and computer vision research by providing state-of-the-art results. Deep learning provides different machine learning algorithms that model high level data abstractions and do not rely on handcrafted features. Recently, deep learning methods utilizing deep convolutional neural networks have been applied to medical image analysis providing promising results. The application area covers the whole spectrum of medical image analysis including detection, segmentation, classification, and computer aided diagnosis. This paper presents a review of the state-of-the-art convolutional neural network based techniques used for medical image analysis.
Skip-Convolutions for Efficient Video Processing
Apr 23, 2021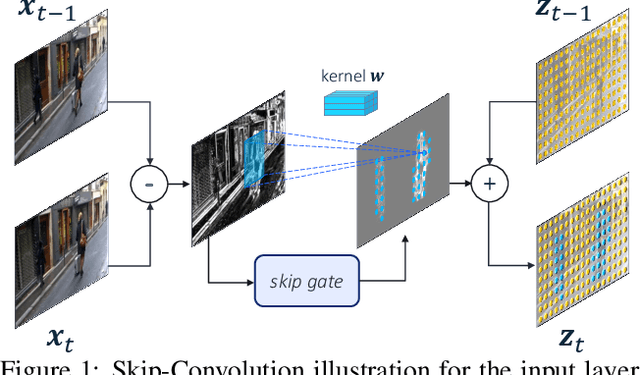
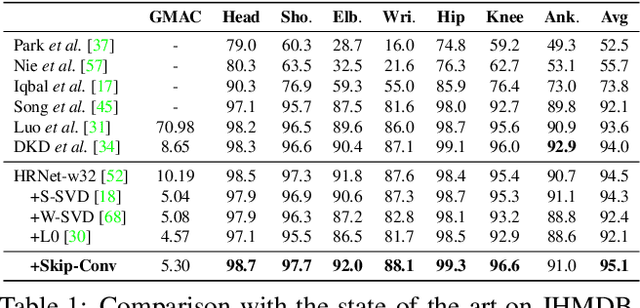
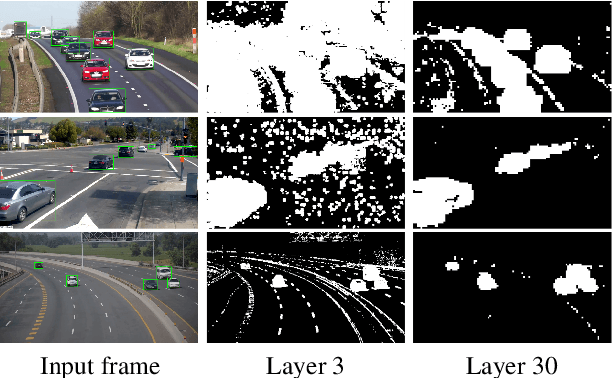
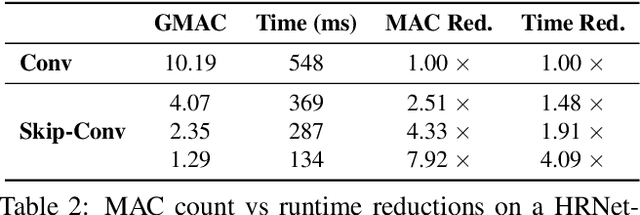
We propose Skip-Convolutions to leverage the large amount of redundancies in video streams and save computations. Each video is represented as a series of changes across frames and network activations, denoted as residuals. We reformulate standard convolution to be efficiently computed on residual frames: each layer is coupled with a binary gate deciding whether a residual is important to the model prediction,~\eg foreground regions, or it can be safely skipped, e.g. background regions. These gates can either be implemented as an efficient network trained jointly with convolution kernels, or can simply skip the residuals based on their magnitude. Gating functions can also incorporate block-wise sparsity structures, as required for efficient implementation on hardware platforms. By replacing all convolutions with Skip-Convolutions in two state-of-the-art architectures, namely EfficientDet and HRNet, we reduce their computational cost consistently by a factor of 3~4x for two different tasks, without any accuracy drop. Extensive comparisons with existing model compression, as well as image and video efficiency methods demonstrate that Skip-Convolutions set a new state-of-the-art by effectively exploiting the temporal redundancies in videos.
LeBenchmark: A Reproducible Framework for Assessing Self-Supervised Representation Learning from Speech
Apr 23, 2021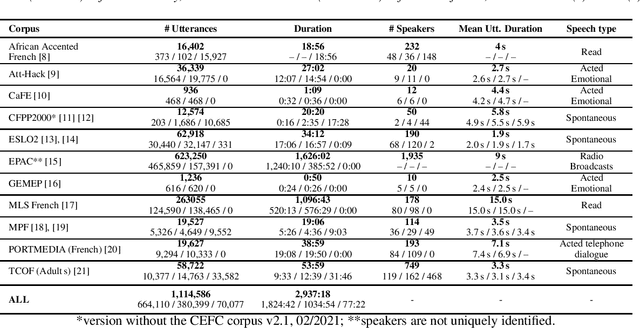
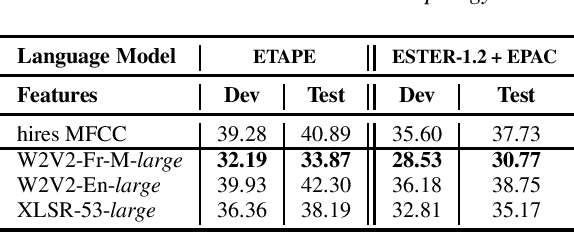
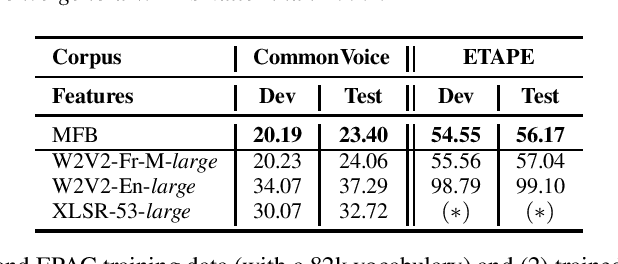
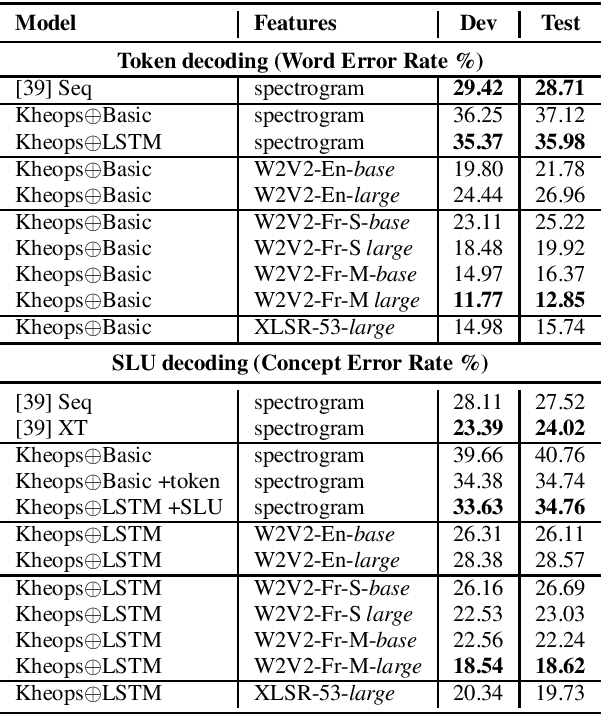
Self-Supervised Learning (SSL) using huge unlabeled data has been successfully explored for image and natural language processing. Recent works also investigated SSL from speech. They were notably successful to improve performance on downstream tasks such as automatic speech recognition (ASR). While these works suggest it is possible to reduce dependence on labeled data for building efficient speech systems, their evaluation was mostly made on ASR and using multiple and heterogeneous experimental settings (most of them for English). This renders difficult the objective comparison between SSL approaches and the evaluation of their impact on building speech systems. In this paper, we propose LeBenchmark: a reproducible framework for assessing SSL from speech. It not only includes ASR (high and low resource) tasks but also spoken language understanding, speech translation and emotion recognition. We also target speech technologies in a language different than English: French. SSL models of different sizes are trained from carefully sourced and documented datasets. Experiments show that SSL is beneficial for most but not all tasks which confirms the need for exhaustive and reliable benchmarks to evaluate its real impact. LeBenchmark is shared with the scientific community for reproducible research in SSL from speech.
A Sketching Framework for Reduced Data Transfer in Photon Counting Lidar
Feb 17, 2021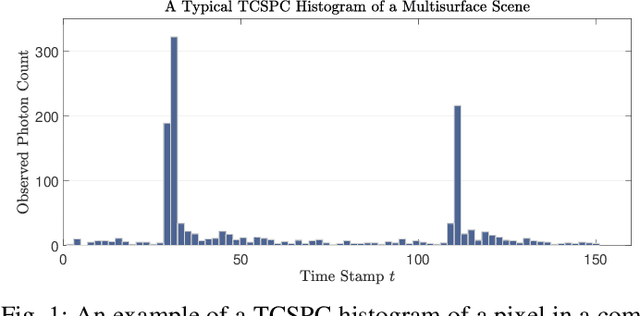
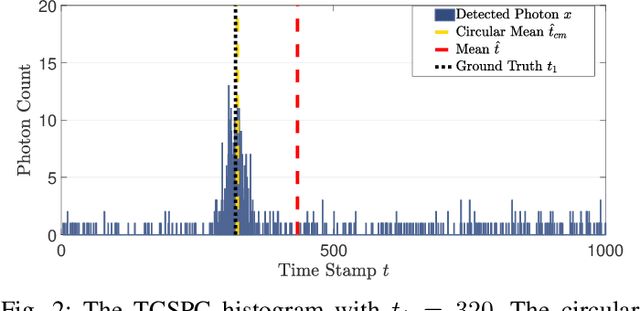
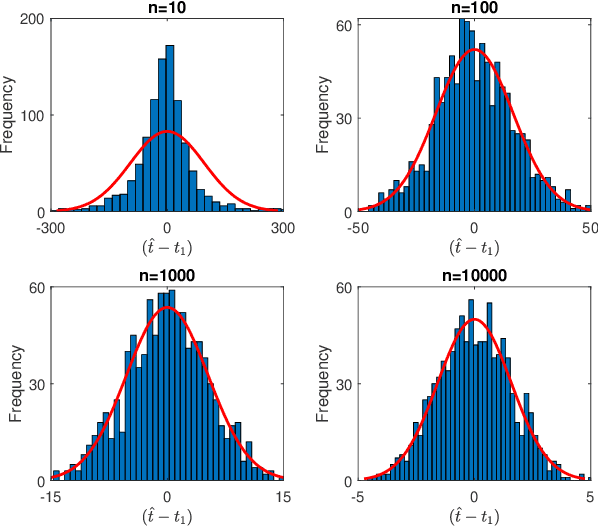
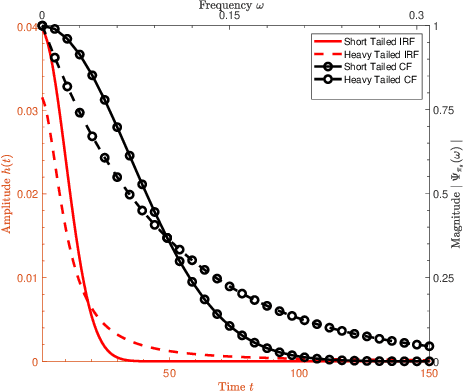
Single-photon lidar has become a prominent tool for depth imaging in recent years. At the core of the technique, the depth of a target is measured by constructing a histogram of time delays between emitted light pulses and detected photon arrivals. A major data processing bottleneck arises on the device when either the number of photons per pixel is large or the resolution of the time stamp is fine, as both the space requirement and the complexity of the image reconstruction algorithms scale with these parameters. We solve this limiting bottleneck of existing lidar techniques by sampling the characteristic function of the time of flight (ToF) model to build a compressive statistic, a so-called sketch of the time delay distribution, which is sufficient to infer the spatial distance and intensity of the object. The size of the sketch scales with the degrees of freedom of the ToF model (number of objects) and not, fundamentally, with the number of photons or the time stamp resolution. Moreover, the sketch is highly amenable for on-chip online processing. We show theoretically that the loss of information for compression is controlled and the mean squared error of the inference quickly converges towards the optimal Cram\'er-Rao bound (i.e. no loss of information) for modest sketch sizes. The proposed compressed single-photon lidar framework is tested and evaluated on real life datasets of complex scenes where it is shown that a compression rate of up-to 1/150 is achievable in practice without sacrificing the overall resolution of the reconstructed image.
Real-Time Surface Fitting to RGBD Sensor Data
Mar 11, 2021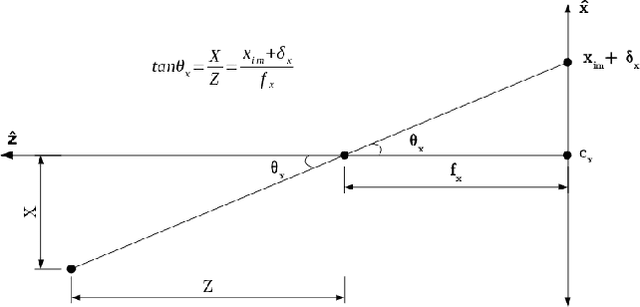
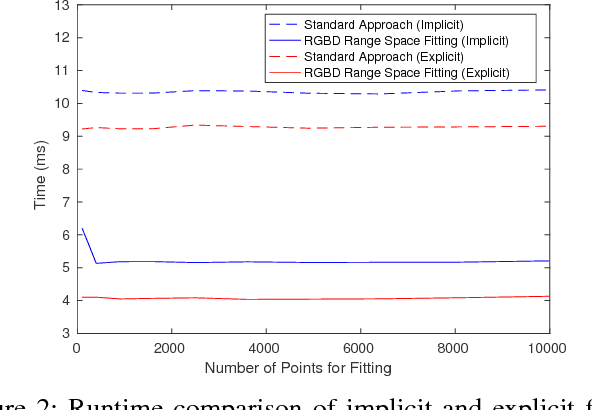
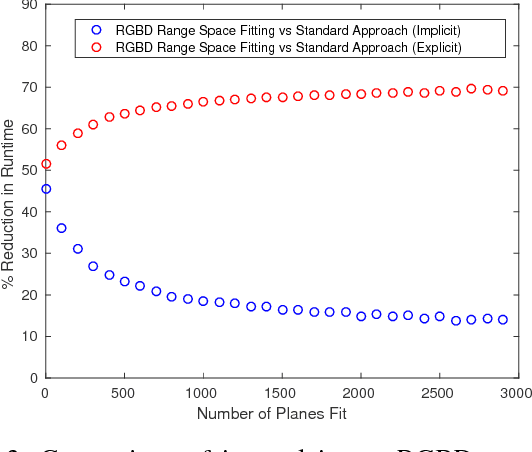

This article describes novel approaches to quickly estimate planar surfaces from RGBD sensor data. The approach manipulates the standard algebraic fitting equations into a form that allows many of the needed regression variables to be computed directly from the camera calibration information. As such, much of the computational burden required by a standard algebraic surface fit can be pre-computed. This provides a significant time and resource savings, especially when many surface fits are being performed which is often the case when RGBD point-cloud data is being analyzed for normal estimation, curvature estimation, polygonization or 3D segmentation applications. Using an integral image implementation, the proposed approaches show a significant increase in performance compared to the standard algebraic fitting approaches.
Domain-Specific Mappings for Generative Adversarial Style Transfer
Aug 05, 2020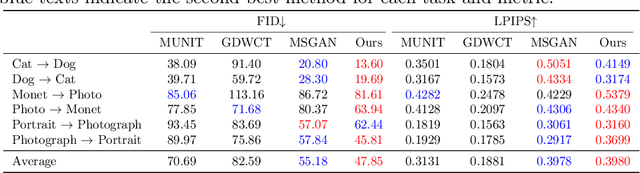
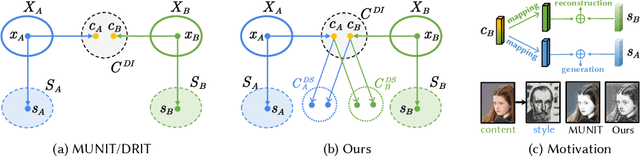
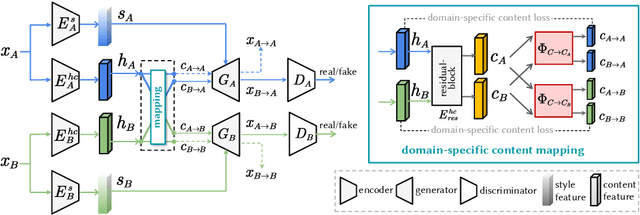

Style transfer generates an image whose content comes from one image and style from the other. Image-to-image translation approaches with disentangled representations have been shown effective for style transfer between two image categories. However, previous methods often assume a shared domain-invariant content space, which could compromise the content representation power. For addressing this issue, this paper leverages domain-specific mappings for remapping latent features in the shared content space to domain-specific content spaces. This way, images can be encoded more properly for style transfer. Experiments show that the proposed method outperforms previous style transfer methods, particularly on challenging scenarios that would require semantic correspondences between images. Code and results are available at https://acht7111020.github.io/DSMAP-demo/.
Large-scale Image Geo-Localization Using Dominant Sets
Sep 14, 2017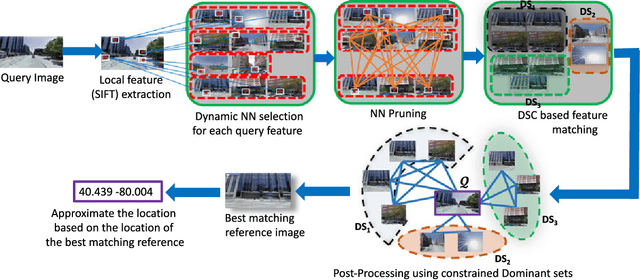

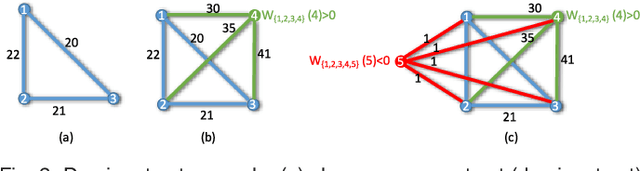
This paper presents a new approach for the challenging problem of geo-locating an image using image matching in a structured database of city-wide reference images with known GPS coordinates. We cast the geo-localization as a clustering problem on local image features. Akin to existing approaches on the problem, our framework builds on low-level features which allow partial matching between images. For each local feature in the query image, we find its approximate nearest neighbors in the reference set. Next, we cluster the features from reference images using Dominant Set clustering, which affords several advantages over existing approaches. First, it permits variable number of nodes in the cluster which we use to dynamically select the number of nearest neighbors (typically coming from multiple reference images) for each query feature based on its discrimination value. Second, as we also quantify in our experiments, this approach is several orders of magnitude faster than existing approaches. Thus, we obtain multiple clusters (different local maximizers) and obtain a robust final solution to the problem using multiple weak solutions through constrained Dominant Set clustering on global image features, where we enforce the constraint that the query image must be included in the cluster. This second level of clustering also bypasses heuristic approaches to voting and selecting the reference image that matches to the query. We evaluated the proposed framework on an existing dataset of 102k street view images as well as a new dataset of 300k images, and show that it outperforms the state-of-the-art by 20% and 7%, respectively, on the two datasets.
Domain-invariant Similarity Activation Map Metric Learning for Retrieval-based Long-term Visual Localization
Sep 16, 2020
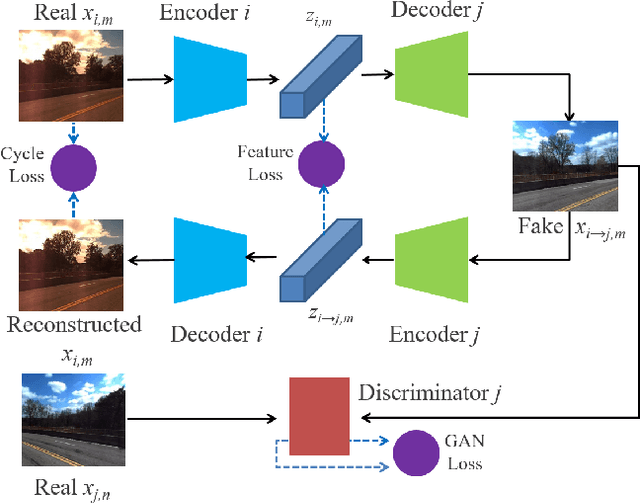
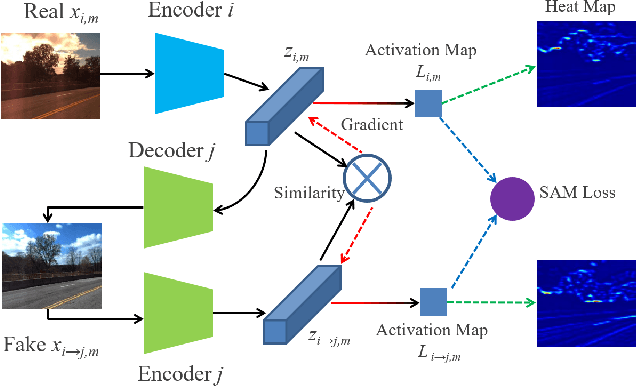
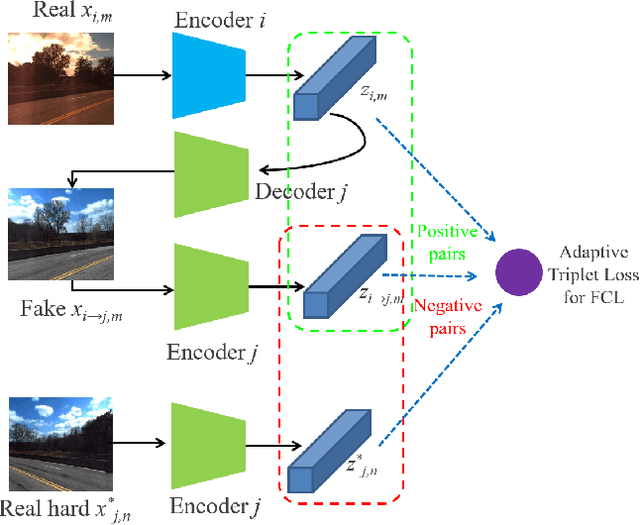
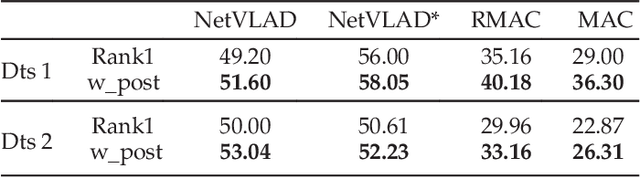
Visual localization is a crucial component in the application of mobile robot and autonomous driving. Image retrieval is an efficient and effective technique in image-based localization methods. Due to the drastic variability of environmental conditions, e.g.Su illumination, seasonal and weather changes, retrieval-based visual localization is severely affected and becomes a challenging problem. In this work, a general architecture is first formulated probabilistically to extract domain-invariant feature through multi-domain image translation. And then a novel gradient-weighted similarity activation mapping loss (Grad-SAM) is incorporated for finer localization with high accuracy. We also propose a new adaptive triplet loss to boost the metric learning of the embedding in a self-supervised manner. The final coarse-to-fine image retrieval pipeline is implemented as the sequential combination of models without and with Grad-SAM loss. Extensive experiments have been conducted to validate the effectiveness of the proposed approach on the CMU-Seasons dataset. The strong generalization ability of our approach is verified on RobotCar dataset using models pre-trained on urban part of CMU-Seasons dataset. Our performance is on par with or even outperforms the state-of-the-art image-based localization baselines in medium or high precision, especially under the challenging environments with illumination variance, vegetation and night-time images.
Fully Convolutional Line Parsing
Apr 23, 2021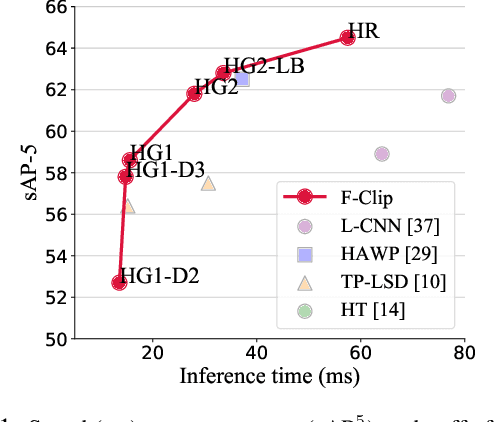
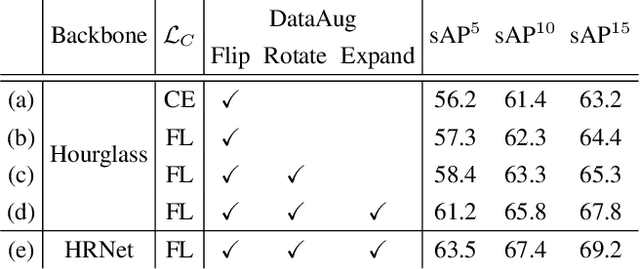
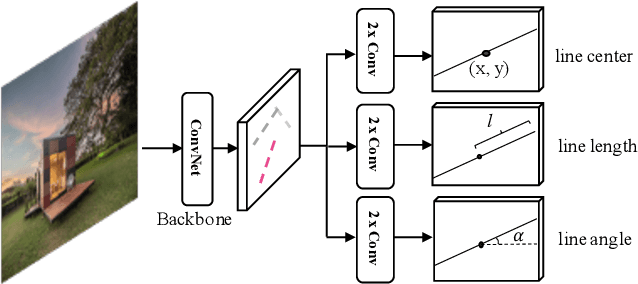

We present a one-stage Fully Convolutional Line Parsing network (F-Clip) that detects line segments from images. The proposed network is very simple and flexible with variations that gracefully trade off between speed and accuracy for different applications. F-Clip detects line segments in an end-to-end fashion by predicting them with each line's center position, length, and angle. Based on empirical observation of the distribution of line angles in real image datasets, we further customize the design of convolution kernels of our fully convolutional network to effectively exploit such statistical priors. We conduct extensive experiments and show that our method achieves a significantly better trade-off between efficiency and accuracy, resulting in a real-time line detector at up to 73 FPS on a single GPU. Such inference speed makes our method readily applicable to real-time tasks without compromising any accuracy of previous methods. Moreover, when equipped with a performance-improving backbone network, F-Clip is able to significantly outperform all state-of-the-art line detectors on accuracy at a similar or even higher frame rate. Source code https://github.com/Delay-Xili/F-Clip.