 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-temporal Sentinel-1 and -2 Data Fusion for Optical Image Simulation
Jul 26, 2018
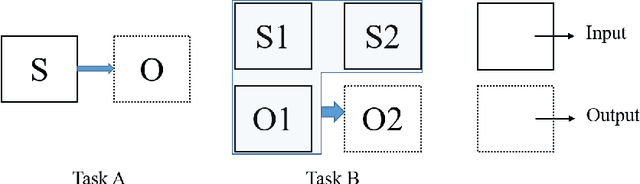

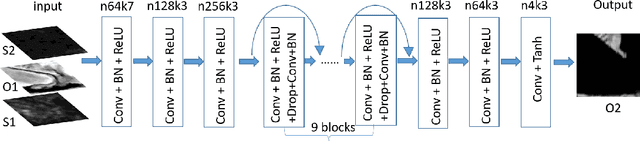
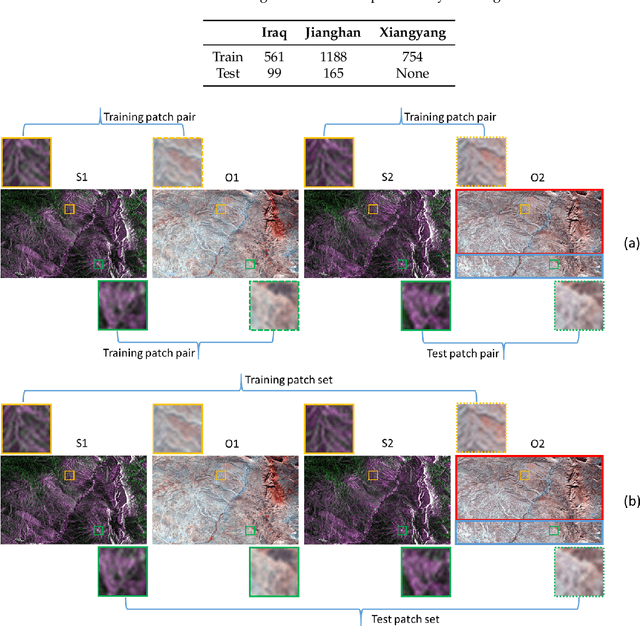
In this paper, we present the optical image simulation from a synthetic aperture radar (SAR) data using deep learning based methods. Two models, i.e., optical image simulation directly from the SAR data and from multi-temporal SARoptical data, are proposed to testify the possibilities. The deep learning based methods that we chose to achieve the models are a convolutional neural network (CNN) with a residual architecture and a conditional generative adversarial network (cGAN). We validate our models using the Sentinel-1 and -2 datasets. The experiments demonstrate that the model with multi-temporal SAR-optical data can successfully simulate the optical image, meanwhile, the model with simple SAR data as input failed. The optical image simulation results indicate the possibility of SARoptical information blending for the subsequent applications such as large-scale cloud removal, and optical data temporal superresolution. We also investigate the sensitivity of the proposed models against the training samples, and reveal possible future directions.
Knowledge Distillation By Sparse Representation Matching
Mar 31, 2021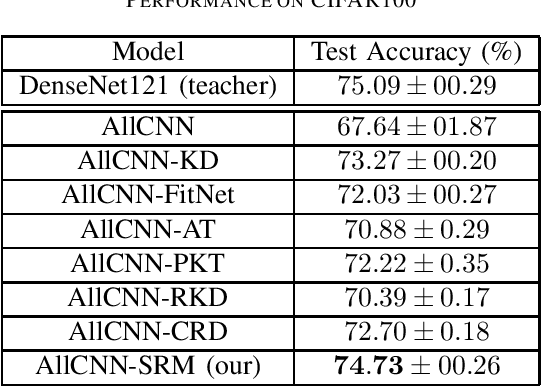

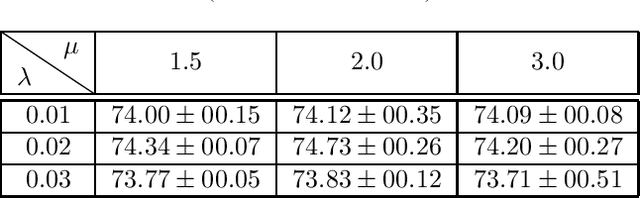

Knowledge Distillation refers to a class of methods that transfers the knowledge from a teacher network to a student network. In this paper, we propose Sparse Representation Matching (SRM), a method to transfer intermediate knowledge obtained from one Convolutional Neural Network (CNN) to another by utilizing sparse representation learning. SRM first extracts sparse representations of the hidden features of the teacher CNN, which are then used to generate both pixel-level and image-level labels for training intermediate feature maps of the student network. We formulate SRM as a neural processing block, which can be efficiently optimized using stochastic gradient descent and integrated into any CNN in a plug-and-play manner. Our experiments demonstrate that SRM is robust to architectural differences between the teacher and student networks, and outperforms other KD techniques across several datasets.
Explaining Image Classifiers by Counterfactual Generation
Oct 11, 2018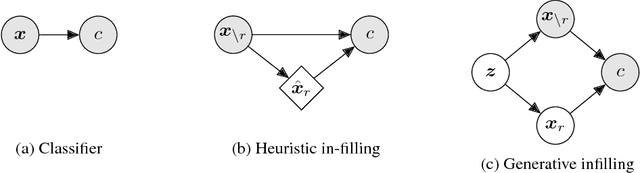

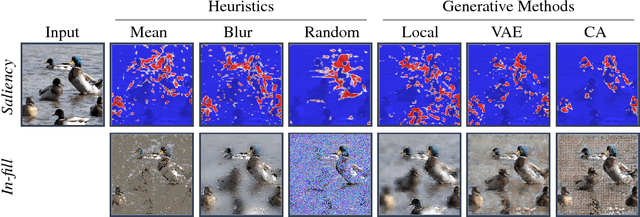

When a black-box classifier processes an input to render a prediction, which input features are relevant and why? We propose to answer this question by efficiently marginalizing over the universe of plausible alternative values for a subset of features by conditioning a generative model of the input distribution on the remaining features. In contrast with recent approaches that compute alternative feature values ad-hoc --- generating counterfactual inputs far from the natural data distribution --- our model-agnostic method produces realistic explanations, generating plausible inputs that either preserve or alter the classification confidence. When applied to image classification, our method produces more compact and relevant per-feature saliency assignment, with fewer artifacts compared to previous methods.
A Neural Network for Semigroups
Mar 12, 2021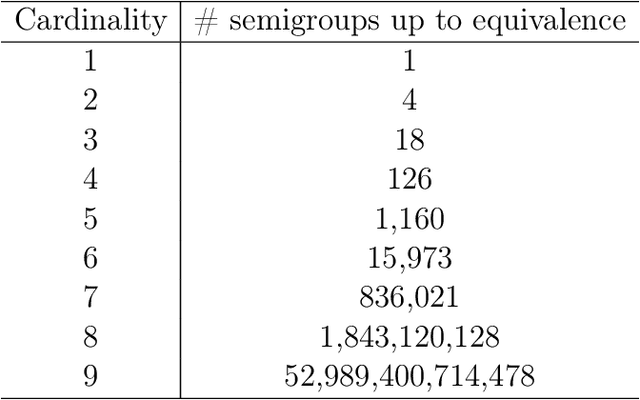
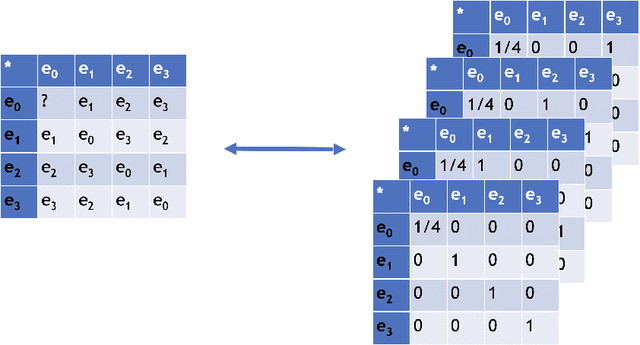
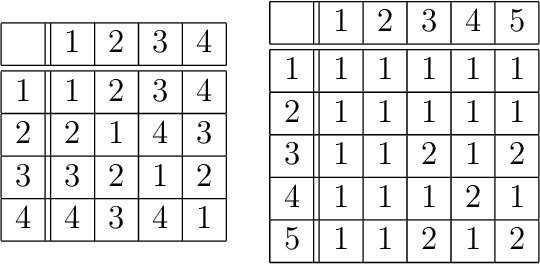
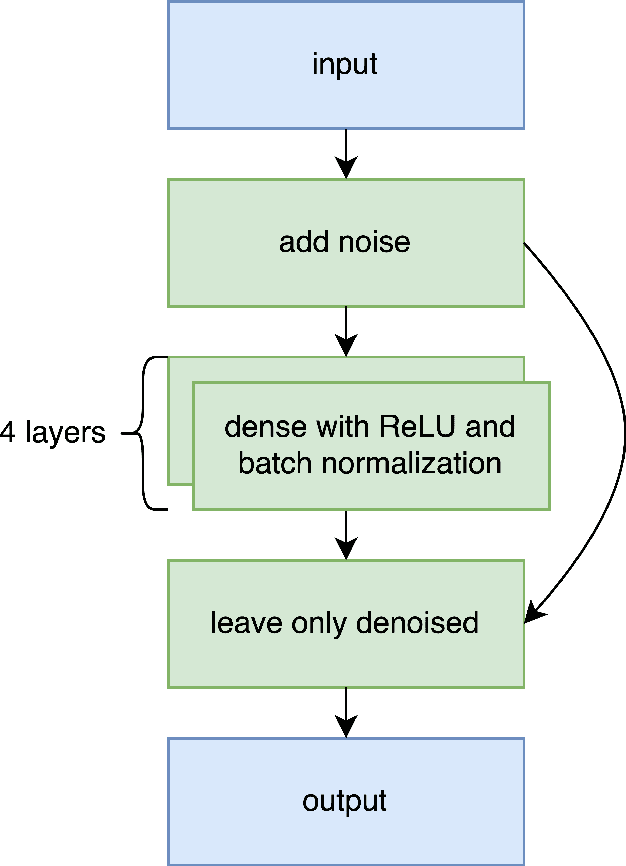
Tasks like image reconstruction in computer vision, matrix completion in recommender systems and link prediction in graph theory, are well studied in machine learning literature. In this work, we apply a denoising autoencoder-based neural network architecture to the task of completing partial multiplication (Cayley) tables of finite semigroups. We suggest a novel loss function for that task based on the algebraic nature of the semigroup data. We also provide a software package for conducting experiments similar to those carried out in this work. Our experiments showed that with only about 10% of the available data, it is possible to build a model capable of reconstructing a full Cayley from only half of it in about 80% of cases.
Flickr1024: A Dataset for Stereo Image Super-Resolution
Mar 15, 2019
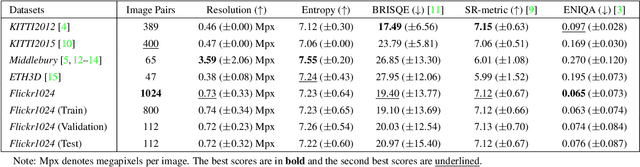


With the popularity of dual cameras in recently released smart phones, a growing number of super-resolution (SR) methods have been proposed to enhance the resolution of stereo image pairs. However, the lack of high-quality stereo datasets has limited the research in this area. To facilitate the training and evaluation of novel stereo SR algorithms, in this paper, we propose a large-scale stereo dataset named Flickr1024. Compared to the existing stereo datasets, the proposed dataset contains much more high-quality images and covers diverse scenarios. We train two state-of-the-art stereo SR methods (i.e., StereoSR and PASSRnet) on the KITTI2015, Middlebury, and Flickr1024 datasets. Experimental results demonstrate that our dataset can improve the performance of stereo SR algorithms. The Flickr1024 dataset is available online at: https://yingqianwang.github.io/Flickr1024.
Interpretable Semantic Photo Geolocalization
Apr 30, 2021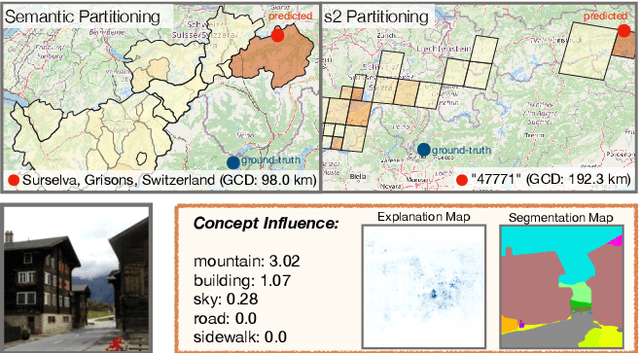

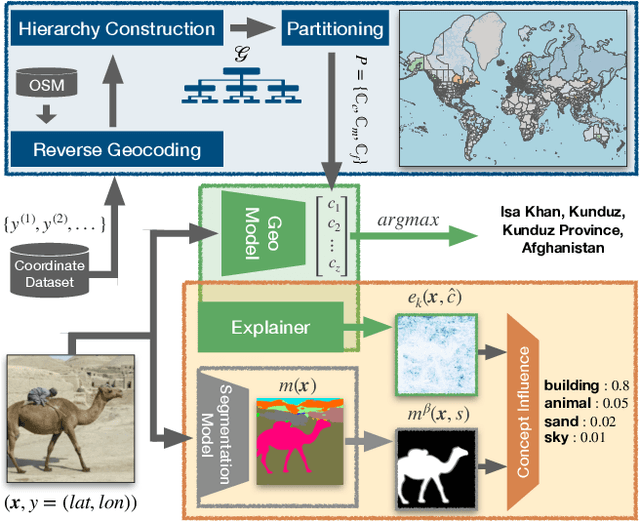
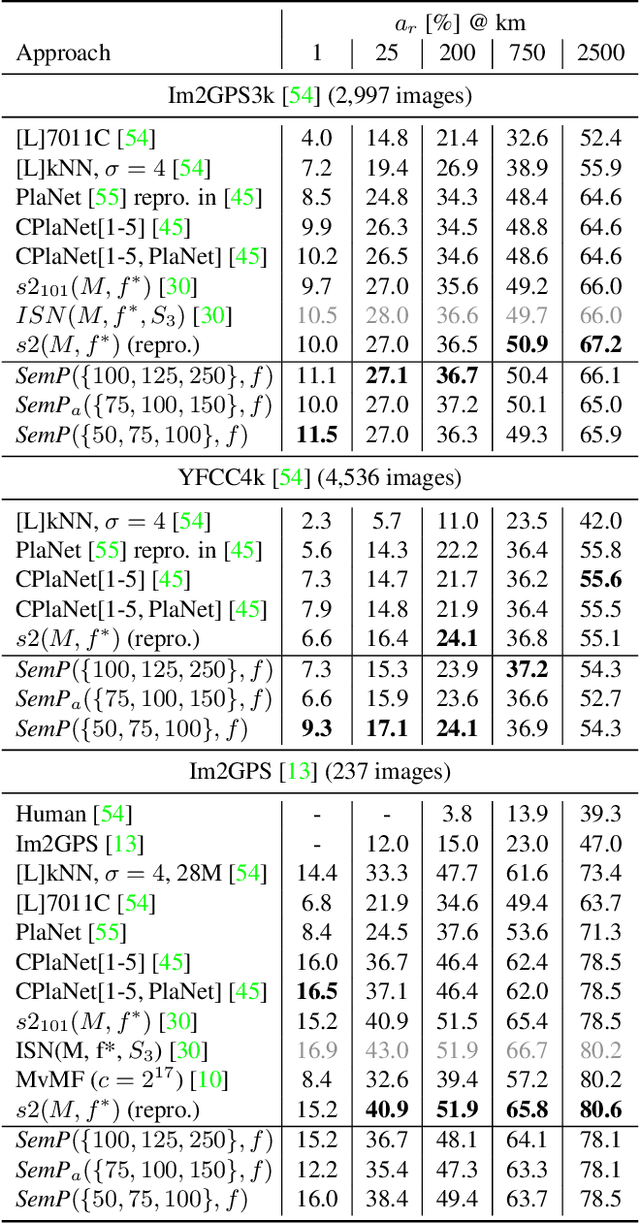
Planet-scale photo geolocalization is the complex task of estimating the location depicted in an image solely based on its visual content. Due to the success of convolutional neural networks (CNNs), current approaches achieve super-human performance. However, previous work has exclusively focused on optimizing geolocalization accuracy. Moreover, due to the black-box property of deep learning systems, their predictions are difficult to validate for humans. State-of-the-art methods treat the task as a classification problem, where the choice of the classes, that is the partitioning of the world map, is the key for success. In this paper, we present two contributions in order to improve the interpretability of a geolocalization model: (1) We propose a novel, semantic partitioning method which intuitively leads to an improved understanding of the predictions, while at the same time state-of-the-art results are achieved for geolocational accuracy on benchmark test sets; (2) We introduce a novel metric to assess the importance of semantic visual concepts for a certain prediction to provide additional interpretable information, which allows for a large-scale analysis of already trained models.
A Convolutional Neural Network with Mapping Layers for Hyperspectral Image Classification
Aug 26, 2019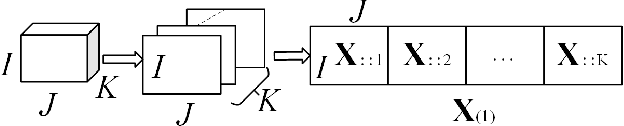
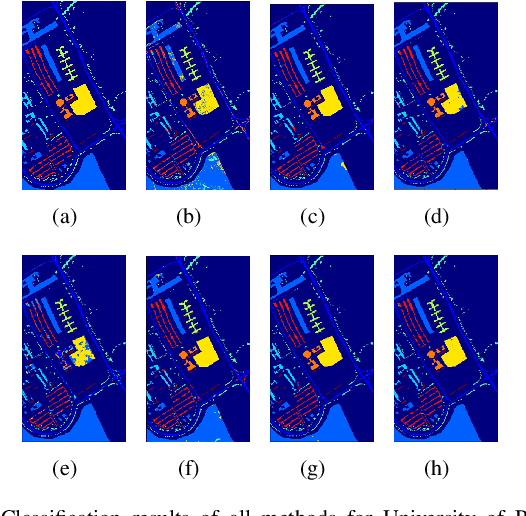
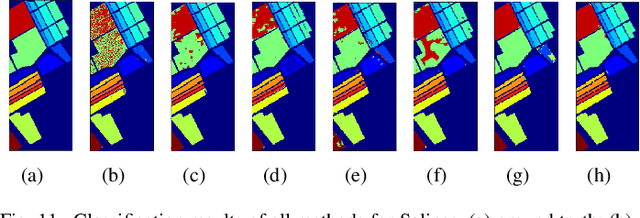
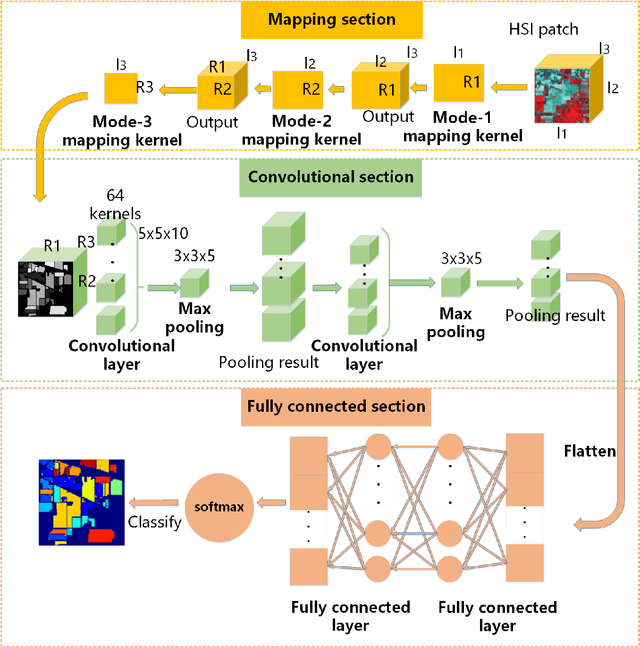
In this paper, we propose a convolutional neural network with mapping layers (MCNN) for hyperspectral image (HSI) classification. The proposed mapping layers map the input patch into a low dimensional subspace by multilinear algebra. We use our mapping layers to reduce the spectral and spatial redundancy and maintain most energy of the input. The feature extracted by our mapping layers can also reduce the number of following convolutional layers for feature extraction. Our MCNN architecture avoids the declining accuracy with increasing layers phenomenon of deep learning models for HSI classification and also saves the training time for its effective mapping layers. Furthermore, we impose the 3-D convolutional kernel on convolutional layer to extract the spectral-spatial features for HSI. We tested our MCNN on three datasets of Indian Pines, University of Pavia and Salinas, and we achieved the classification accuracy of 98.3%, 99.5% and 99.3%, respectively. Experimental results demonstrate that the proposed MCNN can significantly improve the classification accuracy and save much time consumption.
Current Status and Performance Analysis of Table Recognition in Document Images with Deep Neural Networks
May 08, 2021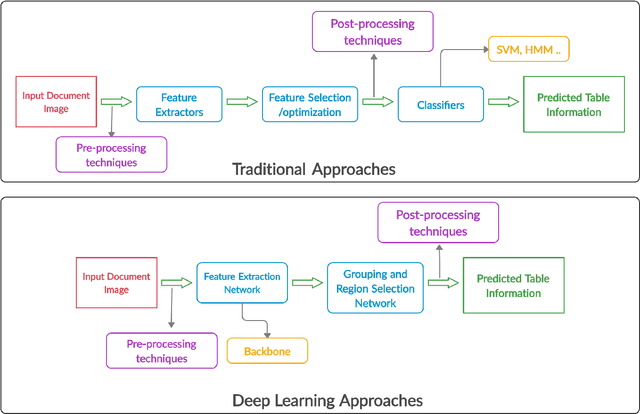
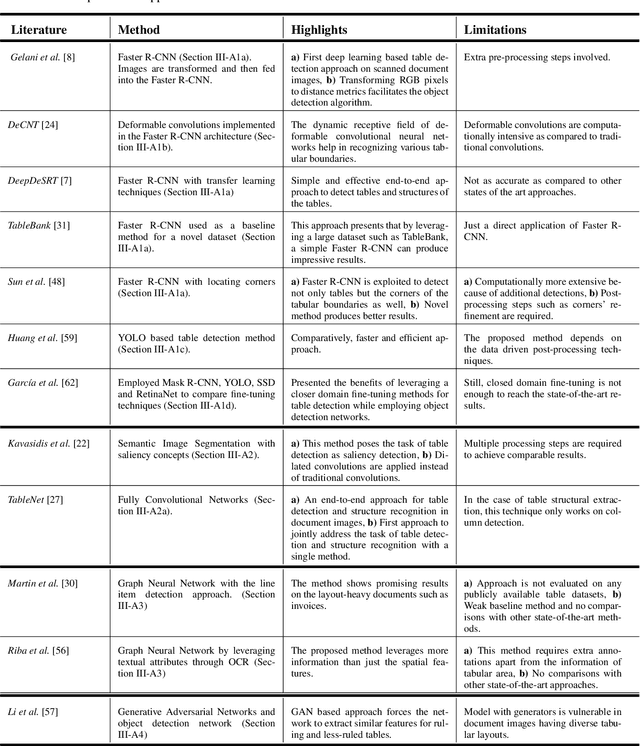
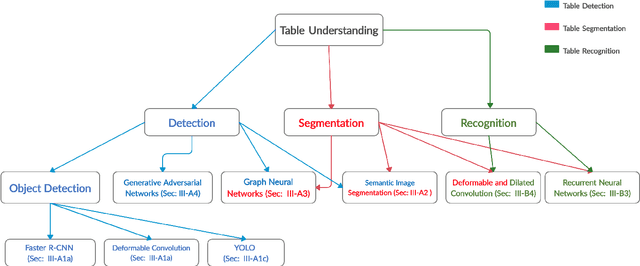
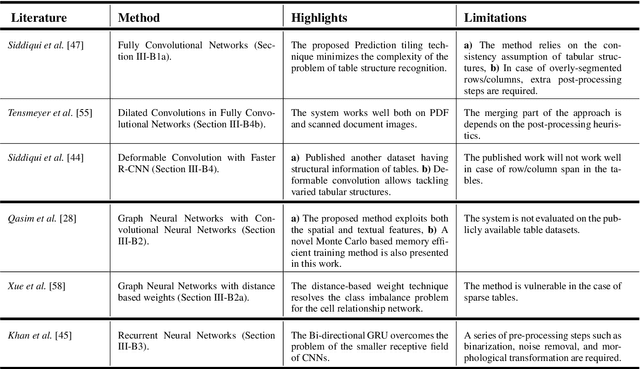
The first phase of table recognition is to detect the tabular area in a document. Subsequently, the tabular structures are recognized in the second phase in order to extract information from the respective cells. Table detection and structural recognition are pivotal problems in the domain of table understanding. However, table analysis is a perplexing task due to the colossal amount of diversity and asymmetry in tables. Therefore, it is an active area of research in document image analysis. Recent advances in the computing capabilities of graphical processing units have enabled deep neural networks to outperform traditional state-of-the-art machine learning methods. Table understanding has substantially benefited from the recent breakthroughs in deep neural networks. However, there has not been a consolidated description of the deep learning methods for table detection and table structure recognition. This review paper provides a thorough analysis of the modern methodologies that utilize deep neural networks. This work provided a thorough understanding of the current state-of-the-art and related challenges of table understanding in document images. Furthermore, the leading datasets and their intricacies have been elaborated along with the quantitative results. Moreover, a brief overview is given regarding the promising directions that can serve as a guide to further improve table analysis in document images.
Weakly- and Semi-Supervised Probabilistic Segmentation and Quantification of Ultrasound Needle-Reverberation Artifacts to Allow Better AI Understanding of Tissue Beneath Needles
Nov 24, 2020
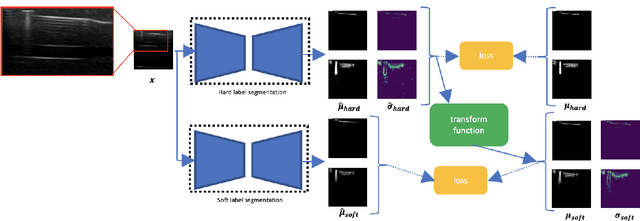

Ultrasound image quality has been continually improving. However, when needles or other metallic objects are operating inside the tissue, the resulting reverberation artifacts can severely corrupt the surrounding image quality. Such effects are challenging for existing computer vision algorithms for medical image analysis. Needle reverberation artifacts can be hard to identify at times and affect various pixel values to different degrees. The boundaries of such artifacts are ambiguous, leading to disagreement among human experts labeling the artifacts. We purpose a weakly- and semi-supervised, probabilistic needle-and-needle-artifact segmentation algorithm to separate the desired tissue-based pixel values from the superimposed artifacts. Our method models the intensity decay of artifact intensities and is designed to minimize the human labeling error. We demonstrate the applicability of the approach, comparing it against other segmentation algorithms. Our method is capable of differentiating the reverberations from artifact-free patches between reverberations, as well as modeling the intensity fall-off in the artifacts. Our method matches state-of-the-art artifact segmentation performance, and sets a new standard in estimating the per-pixel contributions of artifact vs underlying anatomy, especially in the immediately adjacent regions between reverberation lines.
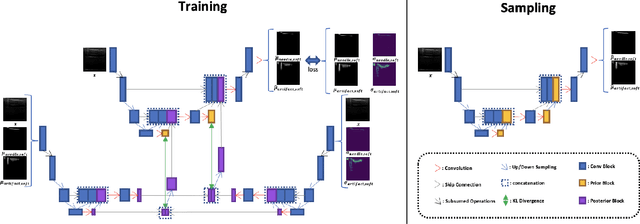
3D U$^2$-Net: A 3D Universal U-Net for Multi-Domain Medical Image Segmentation
Sep 04, 2019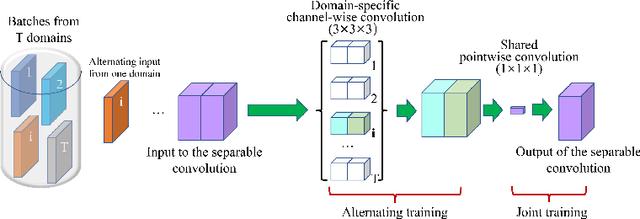

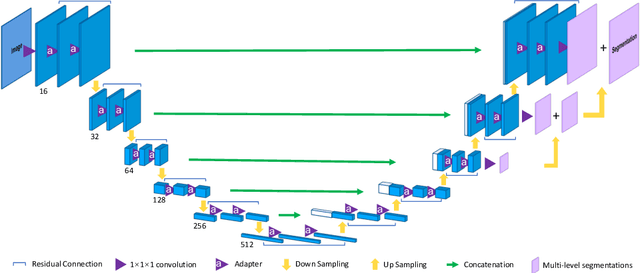
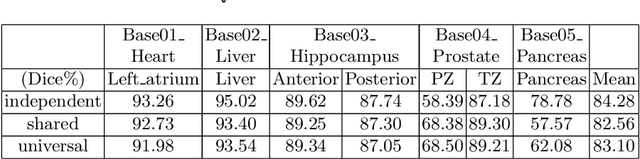
Fully convolutional neural networks like U-Net have been the state-of-the-art methods in medical image segmentation. Practically, a network is highly specialized and trained separately for each segmentation task. Instead of a collection of multiple models, it is highly desirable to learn a universal data representation for different tasks, ideally a single model with the addition of a minimal number of parameters steered to each task. Inspired by the recent success of multi-domain learning in image classification, for the first time we explore a promising universal architecture that handles multiple medical segmentation tasks and is extendable for new tasks, regardless of different organs and imaging modalities. Our 3D Universal U-Net (3D U$^2$-Net) is built upon separable convolution, assuming that {\it images from different domains have domain-specific spatial correlations which can be probed with channel-wise convolution while also share cross-channel correlations which can be modeled with pointwise convolution}. We evaluate the 3D U$^2$-Net on five organ segmentation datasets. Experimental results show that this universal network is capable of competing with traditional models in terms of segmentation accuracy, while requiring only about $1\%$ of the parameters. Additionally, we observe that the architecture can be easily and effectively adapted to a new domain without sacrificing performance in the domains used to learn the shared parameterization of the universal network. We put the code of 3D U$^2$-Net into public domain. \url{https://github.com/huangmozhilv/u2net_torch/}