 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Real-World Datasets Contain Natural Experiments? An Empirical Study Using Causal Feature Selection
Jun 02, 2026In nature, events that affect some individuals or groups but not others constitute an implicit intervention and are known as natural experiments. For example, the COVID-19 pandemic was an intervention by the coronavirus on the sub-population infected with COVID. We ask, do natural experiments occur in existing real-world datasets? If yes, how should we treat them? To detect natural experiments in data, we use causal discovery to recover the underlying causal graph and perform feature selection based on causal links. If downstream performance improves by treating the data as interventional rather than observational, we argue that this suggests the dataset contains natural experiments. We first validate this hypothesis by simulating datasets with and without natural experiments using synthetic graphs. We then perform a systematic empirical evaluation on a large suite of real-world datasets. Our results indicate that real-world datasets do contain natural experiments and we can take advantage of those natural experiments to improve model performance using causal inference. Our work represents the initial foray into this area, offering a preliminary exploration within a limited scope.
Meta-Learned Adaptive Optimization for Robust Human Mesh Recovery with Uncertainty-Aware Parameter Updates
Mar 27, 2026Human mesh recovery from single images remains challenging due to inherent depth ambiguity and limited generalization across domains. While recent methods combine regression and optimization approaches, they struggle with poor initialization for test-time refinement and inefficient parameter updates during optimization. We propose a novel meta-learning framework that trains models to produce optimization-friendly initializations while incorporating uncertainty-aware adaptive updates during test-time refinement. Our approach introduces three key innovations: (1) a meta-learning strategy that simulates test-time optimization during training to learn better parameter initializations, (2) a selective parameter caching mechanism that identifies and freezes converged joints to reduce computational overhead, and (3) distribution-based adaptive updates that sample parameter changes from learned distributions, enabling robust exploration while quantifying uncertainty. Additionally, we employ stochastic approximation techniques to handle intractable gradients in complex loss landscapes. Extensive experiments on standard benchmarks demonstrate that our method achieves state-of-the-art performance, reducing MPJPE by 10.3 on 3DPW and 8.0 on Human3.6M compared to strong baselines. Our approach shows superior domain adaptation capabilities with minimal performance degradation across different environmental conditions, while providing meaningful uncertainty estimates that correlate with actual prediction errors. Combining meta-learning and adaptive optimization enables accurate mesh recovery and robust generalization to challenging scenarios.
DetPO: In-Context Learning with Multi-Modal LLMs for Few-Shot Object Detection
Mar 24, 2026Multi-Modal LLMs (MLLMs) demonstrate strong visual grounding capabilities on popular object detection benchmarks like OdinW-13 and RefCOCO. However, state-of-the-art models still struggle to generalize to out-of-distribution classes, tasks and imaging modalities not typically found in their pre-training. While in-context prompting is a common strategy to improve performance across diverse tasks, we find that it often yields lower detection accuracy than prompting with class names alone. This suggests that current MLLMs cannot yet effectively leverage few-shot visual examples and rich textual descriptions for object detection. Since frontier MLLMs are typically only accessible via APIs, and state-of-the-art open-weights models are prohibitively expensive to fine-tune on consumer-grade hardware, we instead explore black-box prompt optimization for few-shot object detection. To this end, we propose Detection Prompt Optimization (DetPO), a gradient-free test-time optimization approach that refines text-only prompts by maximizing detection accuracy on few-shot visual training examples while calibrating prediction confidence. Our proposed approach yields consistent improvements across generalist MLLMs on Roboflow20-VL and LVIS, outperforming prior black-box approaches by up to 9.7%. Our code is available at https://github.com/ggare-cmu/DetPO
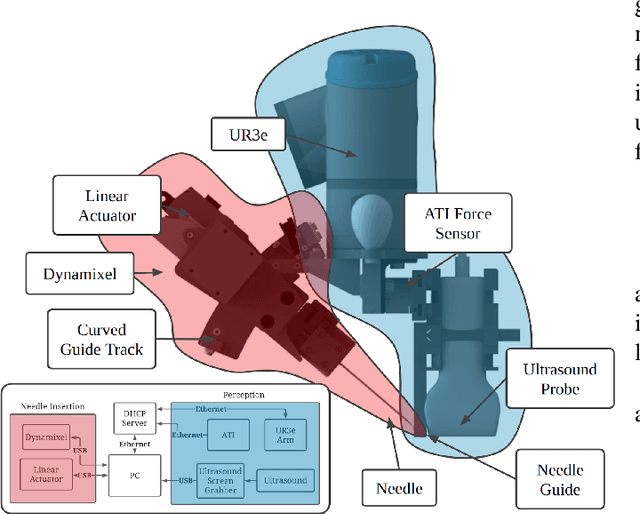
Automatic Cannulation of Femoral Vessels in a Porcine Shock Model
Jun 17, 2025Rapid and reliable vascular access is critical in trauma and critical care. Central vascular catheterization enables high-volume resuscitation, hemodynamic monitoring, and advanced interventions like ECMO and REBOA. While peripheral access is common, central access is often necessary but requires specialized ultrasound-guided skills, posing challenges in prehospital settings. The complexity arises from deep target vessels and the precision needed for needle placement. Traditional techniques, like the Seldinger method, demand expertise to avoid complications. Despite its importance, ultrasound-guided central access is underutilized due to limited field expertise. While autonomous needle insertion has been explored for peripheral vessels, only semi-autonomous methods exist for femoral access. This work advances toward full automation, integrating robotic ultrasound for minimally invasive emergency procedures. Our key contribution is the successful femoral vein and artery cannulation in a porcine hemorrhagic shock model.
* 2 pages, 2 figures, conference
LEARNER: Learning Granular Labels from Coarse Labels using Contrastive Learning
Nov 02, 2024



A crucial question in active patient care is determining if a treatment is having the desired effect, especially when changes are subtle over short periods. We propose using inter-patient data to train models that can learn to detect these fine-grained changes within a single patient. Specifically, can a model trained on multi-patient scans predict subtle changes in an individual patient's scans? Recent years have seen increasing use of deep learning (DL) in predicting diseases using biomedical imaging, such as predicting COVID-19 severity using lung ultrasound (LUS) data. While extensive literature exists on successful applications of DL systems when well-annotated large-scale datasets are available, it is quite difficult to collect a large corpus of personalized datasets for an individual. In this work, we investigate the ability of recent computer vision models to learn fine-grained differences while being trained on data showing larger differences. We evaluate on an in-house LUS dataset and a public ADNI brain MRI dataset. We find that models pre-trained on clips from multiple patients can better predict fine-grained differences in scans from a single patient by employing contrastive learning.
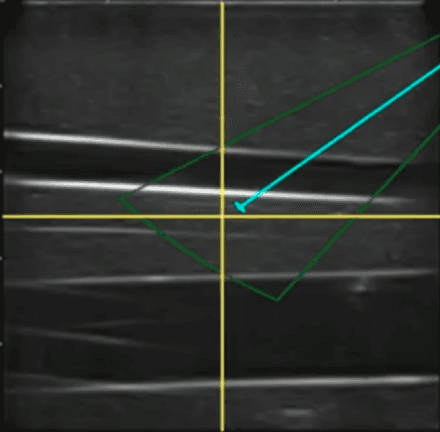
Motion Informed Needle Segmentation in Ultrasound Images
Dec 05, 2023



Segmenting a moving needle in ultrasound images is challenging due to the presence of artifacts, noise, and needle occlusion. This task becomes even more demanding in scenarios where data availability is limited. Convolutional Neural Networks (CNNs) have been successful in many computer vision applications, but struggle to accurately segment needles without considering their motion. In this paper, we present a novel approach for needle segmentation that combines classical Kalman Filter (KF) techniques with data-driven learning, incorporating both needle features and needle motion. Our method offers two key contributions. First, we propose a compatible framework that seamlessly integrates into commonly used encoder-decoder style architectures. Second, we demonstrate superior performance compared to recent state-of-the-art needle segmentation models using our novel convolutional neural network (CNN) based KF-inspired block, achieving a 15\% reduction in pixel-wise needle tip error and an 8\% reduction in length error. Third, to our knowledge we are the first to implement a learnable filter to incorporate non-linear needle motion for improving needle segmentation.
Unsupervised Deformable Image Registration for Respiratory Motion Compensation in Ultrasound Images
Jun 23, 2023In this paper, we present a novel deep-learning model for deformable registration of ultrasound images and an unsupervised approach to training this model. Our network employs recurrent all-pairs field transforms (RAFT) and a spatial transformer network (STN) to generate displacement fields at online rates (apprx. 30 Hz) and accurately track pixel movement. We call our approach unsupervised recurrent all-pairs field transforms (U-RAFT). In this work, we use U-RAFT to track pixels in a sequence of ultrasound images to cancel out respiratory motion in lung ultrasound images. We demonstrate our method on in-vivo porcine lung videos. We show a reduction of 76% in average pixel movement in the porcine dataset using respiratory motion compensation strategy. We believe U-RAFT is a promising tool for compensating different kinds of motions like respiration and heartbeat in ultrasound images of deformable tissue.
Unsupervised Deformable Ultrasound Image Registration and Its Application for Vessel Segmentation
Jun 23, 2023This paper presents a deep-learning model for deformable registration of ultrasound images at online rates, which we call U-RAFT. As its name suggests, U-RAFT is based on RAFT, a convolutional neural network for estimating optical flow. U-RAFT, however, can be trained in an unsupervised manner and can generate synthetic images for training vessel segmentation models. We propose and compare the registration quality of different loss functions for training U-RAFT. We also show how our approach, together with a robot performing force-controlled scans, can be used to generate synthetic deformed images to significantly expand the size of a femoral vessel segmentation training dataset without the need for additional manual labeling. We validate our approach on both a silicone human tissue phantom as well as on in-vivo porcine images. We show that U-RAFT generates synthetic ultrasound images with 98% and 81% structural similarity index measure (SSIM) to the real ultrasound images for the phantom and porcine datasets, respectively. We also demonstrate that synthetic deformed images from U-RAFT can be used as a data augmentation technique for vessel segmentation models to improve intersection-over-union (IoU) segmentation performance
Toward Robotically Automated Femoral Vascular Access
Jul 06, 2021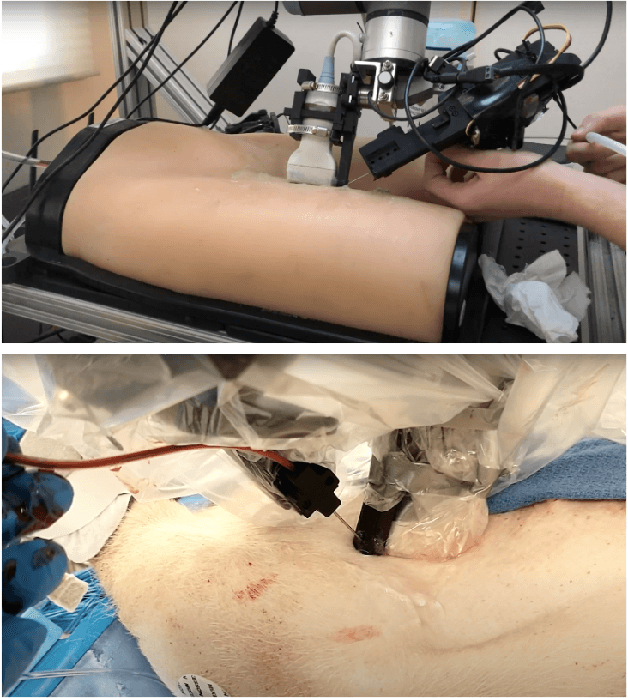
Advanced resuscitative technologies, such as Extra Corporeal Membrane Oxygenation (ECMO) cannulation or Resuscitative Endovascular Balloon Occlusion of the Aorta (REBOA), are technically difficult even for skilled medical personnel. This paper describes the core technologies that comprise a teleoperated system capable of granting femoral vascular access, which is an important step in both of these procedures and a major roadblock in their wider use in the field. These technologies include a kinematic manipulator, various sensing modalities, and a user interface. In addition, we evaluate our system on a surgical phantom as well as in-vivo porcine experiments. These resulted in, to the best of our knowledge, the first robot-assisted arterial catheterizations; a major step towards our eventual goal of automatic catheter insertion through the Seldinger technique.
Good and Bad Boundaries in Ultrasound Compounding: Preserving Anatomic Boundaries While Suppressing Artifacts
Nov 24, 2020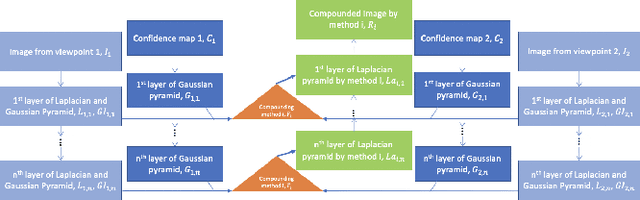
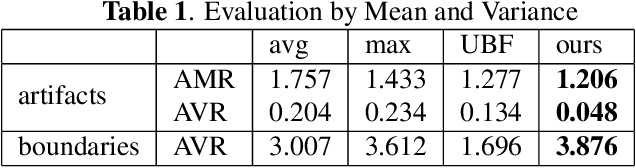
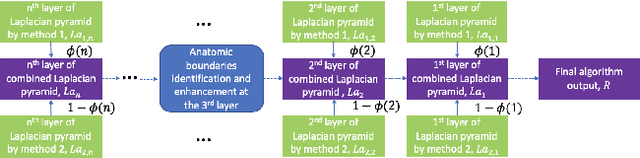

Ultrasound 3D compounding is important for volumetric reconstruction, but as of yet there is no consensus on best practices for compounding. Ultrasound images depend on probe direction and the path sound waves pass through, so when multiple intersecting B-scans of the same spot from different perspectives yield different pixel values, there is not a single, ideal representation for compounding (i.e. combining) the overlapping pixel values. Current popular methods inevitably suppress or altogether leave out bright or dark regions that are useful, and potentially introduce new artifacts. In this work, we establish a new algorithm to compound the overlapping pixels from different view points in ultrasound. We uniquely leverage Laplacian and Gaussian Pyramids to preserve the maximum boundary contrast without overemphasizing noise and speckle. We evaluate our algorithm by comparing ours with previous algorithms, and we show that our approach not only preserves both light and dark details, but also somewhat suppresses artifacts, rather than amplifying them.