 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Canonical Correlation Analysis for Misaligned Satellite Image Change Detection
Dec 21, 2018
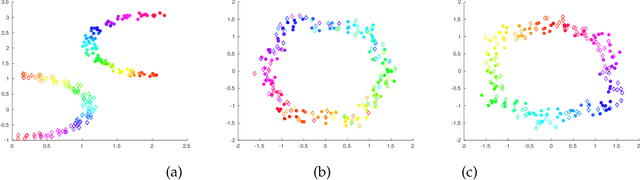

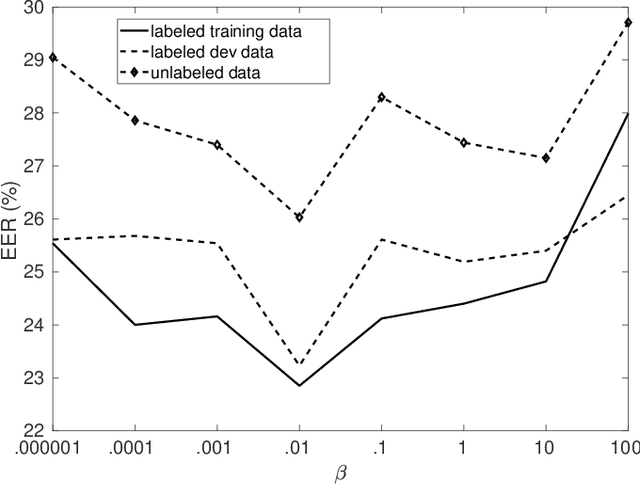
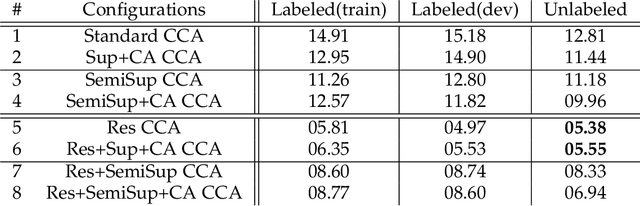
Canonical correlation analysis (CCA) is a statistical learning method that seeks to build view-independent latent representations from multi-view data. This method has been successfully applied to several pattern analysis tasks such as image-to-text mapping and view-invariant object/action recognition. However, this success is highly dependent on the quality of data pairing (i.e., alignments) and mispairing adversely affects the generalization ability of the learned CCA representations. In this paper, we address the issue of alignment errors using a new variant of canonical correlation analysis referred to as alignment-agnostic (AA) CCA. Starting from erroneously paired data taken from different views, this CCA finds transformation matrices by optimizing a constrained maximization problem that mixes a data correlation term with context regularization; the particular design of these two terms mitigates the effect of alignment errors when learning the CCA transformations. Experiments conducted on multi-view tasks, including multi-temporal satellite image change detection, show that our AA CCA method is highly effective and resilient to mispairing errors.
Real-time Semantic Image Segmentation via Spatial Sparsity
Dec 01, 2017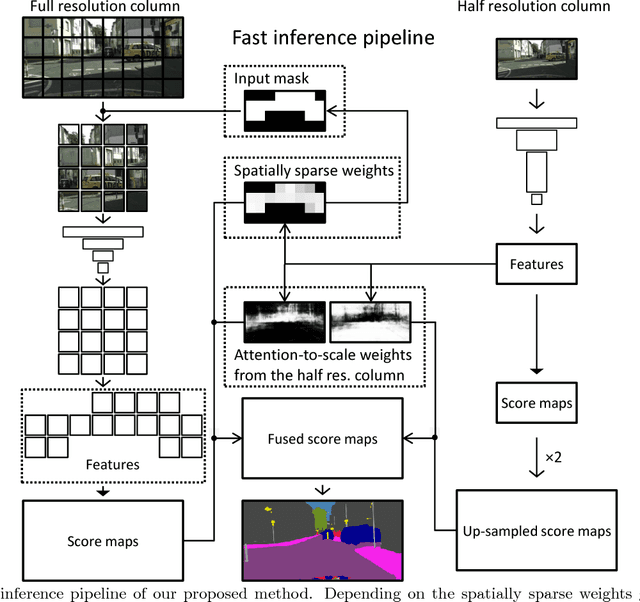

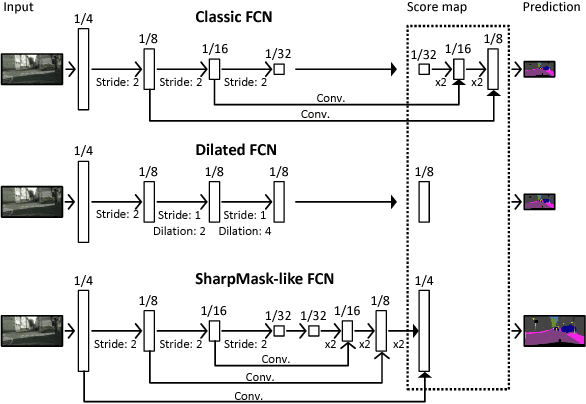
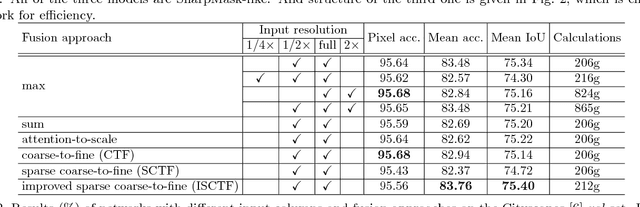
We propose an approach to semantic (image) segmentation that reduces the computational costs by a factor of 25 with limited impact on the quality of results. Semantic segmentation has a number of practical applications, and for most such applications the computational costs are critical. The method follows a typical two-column network structure, where one column accepts an input image, while the other accepts a half-resolution version of that image. By identifying specific regions in the full-resolution image that can be safely ignored, as well as carefully tailoring the network structure, we can process approximately 15 highresolution Cityscapes images (1024x2048) per second using a single GTX 980 video card, while achieving a mean intersection-over-union score of 72.9% on the Cityscapes test set.
From Points to Multi-Object 3D Reconstruction
Dec 21, 2020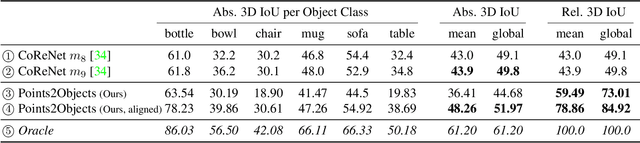
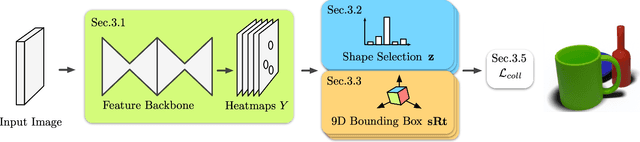

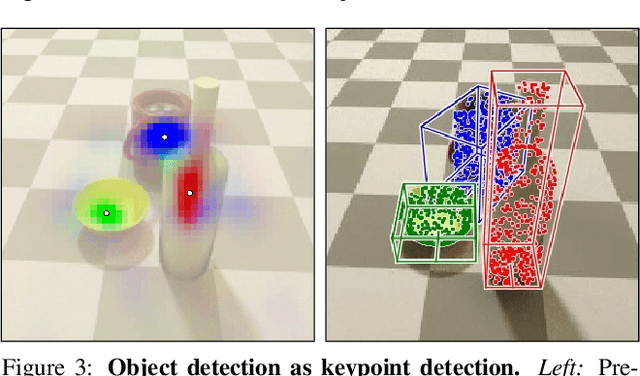
We propose a method to detect and reconstruct multiple 3D objects from a single RGB image. The key idea is to optimize for detection, alignment and shape jointly over all objects in the RGB image, while focusing on realistic and physically plausible reconstructions. To this end, we propose a keypoint detector that localizes objects as center points and directly predicts all object properties, including 9-DoF bounding boxes and 3D shapes -- all in a single forward pass. The proposed method formulates 3D shape reconstruction as a shape selection problem, i.e. it selects among exemplar shapes from a given database. This makes it agnostic to shape representations, which enables a lightweight reconstruction of realistic and visually-pleasing shapes based on CAD-models, while the training objective is formulated around point clouds and voxel representations. A collision-loss promotes non-intersecting objects, further increasing the reconstruction realism. Given the RGB image, the presented approach performs lightweight reconstruction in a single-stage, it is real-time capable, fully differentiable and end-to-end trainable. Our experiments compare multiple approaches for 9-DoF bounding box estimation, evaluate the novel shape-selection mechanism and compare to recent methods in terms of 3D bounding box estimation and 3D shape reconstruction quality.
TextureWGAN: Texture Preserving WGAN with MLE Regularizer for Inverse Problems
Aug 11, 2020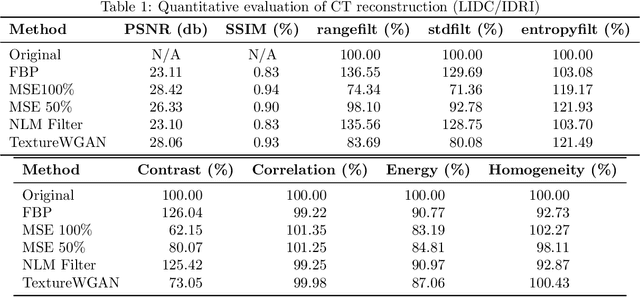
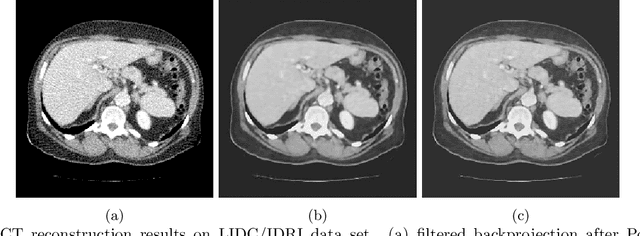
Many algorithms and methods have been proposed for inverse problems particularly with the recent surge of interest in machine learning and deep learning methods. Among all proposed methods, the most popular and effective method is the convolutional neural network (CNN) with mean square error (MSE). This method has been proven effective in super-resolution, image de-noising, and image reconstruction. However, this method is known to over-smooth images due to the nature of MSE. MSE based methods minimize Euclidean distance for all pixels between a baseline image and a generated image by CNN and ignore the spatial information of the pixels such as image texture. In this paper, we proposed a new method based on Wasserstein GAN (WGAN) for inverse problems. We showed that the WGAN-based method was effective to preserve image texture. It also used a maximum likelihood estimation (MLE) regularizer to preserve pixel fidelity. Maintaining image texture and pixel fidelity is the most important requirement for medical imaging. We used Peak Signal to Noise Ratio (PSNR) and Structure Similarity (SSIM) to evaluate the proposed method quantitatively. We also conducted first-order and second-order statistical image texture analysis to assess image texture.
Fast ultrasonic imaging using end-to-end deep learning
Sep 04, 2020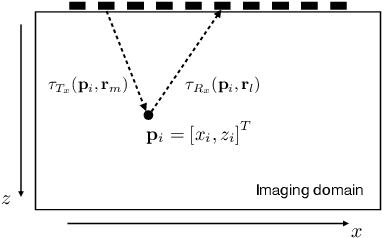
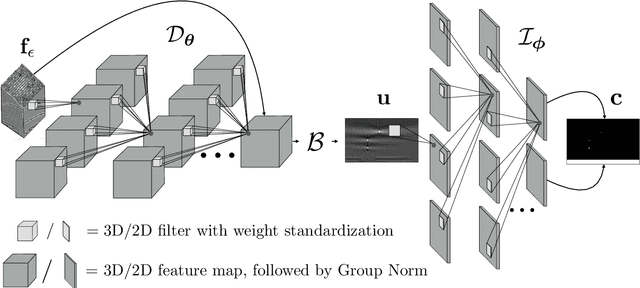
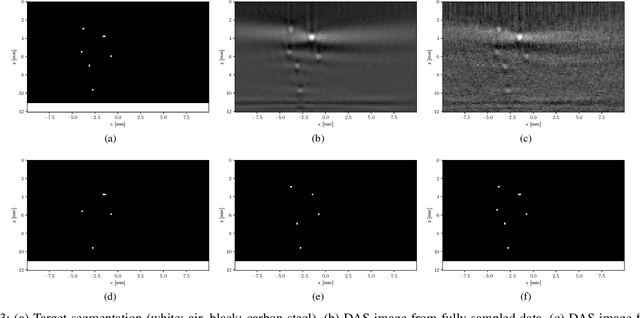
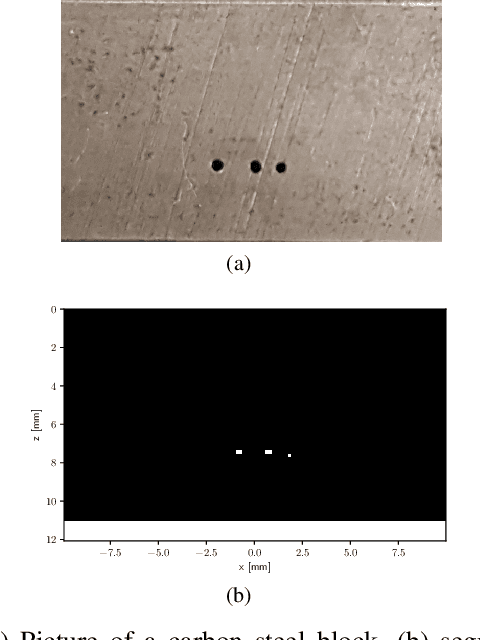
Ultrasonic imaging algorithms used in many clinical and industrial applications consist of three steps: A data pre-processing, an image formation and an image post-processing step. For efficiency, image formation often relies on an approximation of the underlying wave physics. A prominent example is the Delay-And-Sum (DAS) algorithm used in reflectivity-based ultrasonic imaging. Recently, deep neural networks (DNNs) are being used for the data pre-processing and the image post-processing steps separately. In this work, we propose a novel deep learning architecture that integrates all three steps to enable end-to-end training. We examine turning the DAS image formation method into a network layer that connects data pre-processing layers with image post-processing layers that perform segmentation. We demonstrate that this integrated approach clearly outperforms sequential approaches that are trained separately. While network training and evaluation is performed only on simulated data, we also showcase the potential of our approach on real data from a non-destructive testing scenario.
Visualizing Missing Surfaces In Colonoscopy Videos using Shared Latent Space Representations
Jan 18, 2021
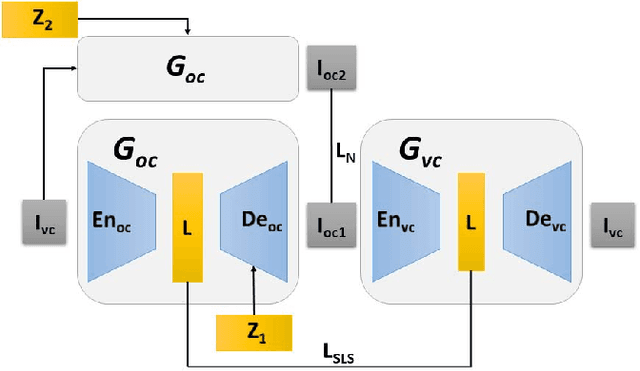
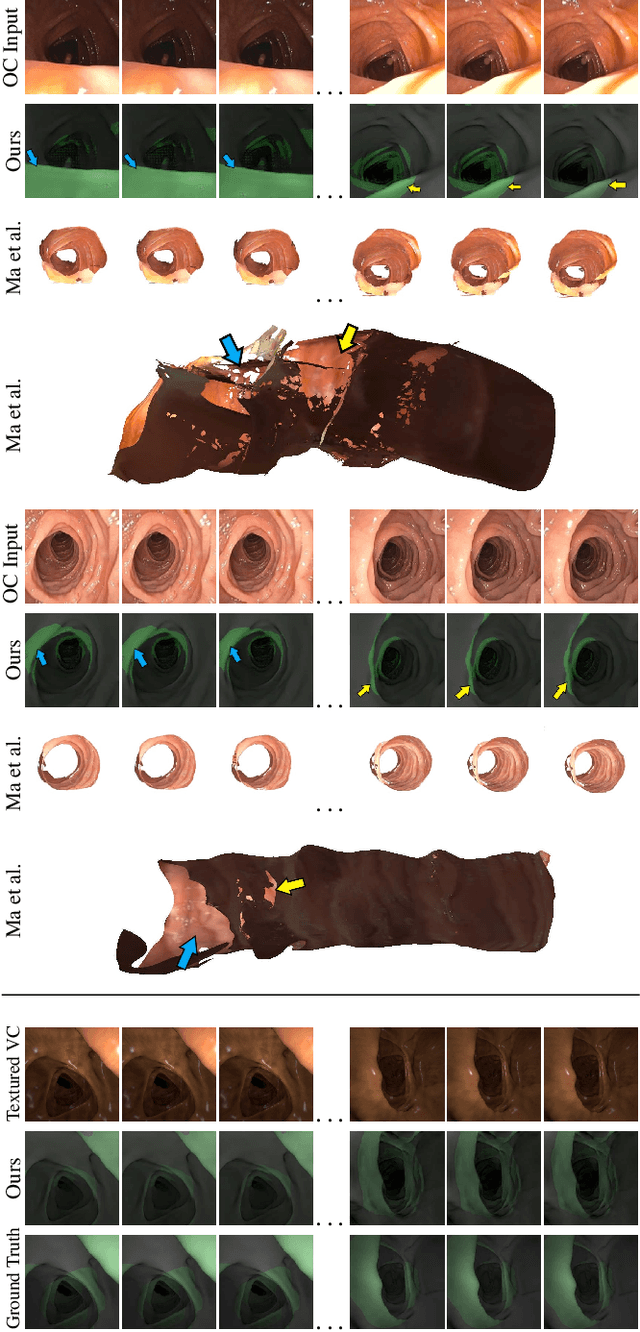
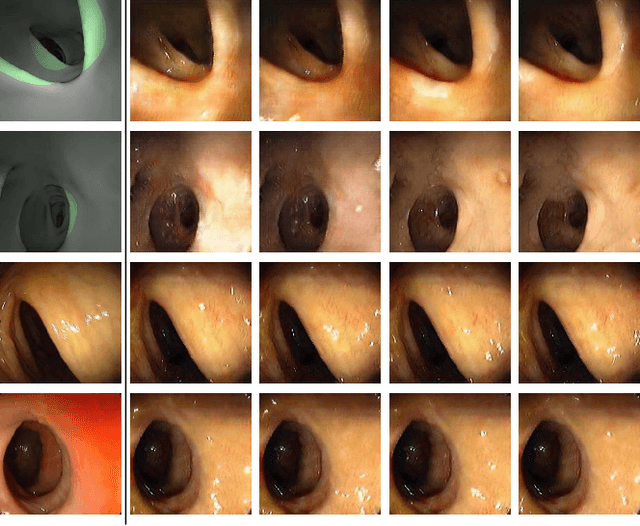
Optical colonoscopy (OC), the most prevalent colon cancer screening tool, has a high miss rate due to a number of factors, including the geometry of the colon (haustral fold and sharp bends occlusions), endoscopist inexperience or fatigue, endoscope field of view, etc. We present a framework to visualize the missed regions per-frame during the colonoscopy, and provides a workable clinical solution. Specifically, we make use of 3D reconstructed virtual colonoscopy (VC) data and the insight that VC and OC share the same underlying geometry but differ in color, texture and specular reflections, embedded in the OC domain. A lossy unpaired image-to-image translation model is introduced with enforced shared latent space for OC and VC. This shared latent space captures the geometric information while deferring the color, texture, and specular information creation to additional Gaussian noise input. This additional noise input can be utilized to generate one-to-many mappings from VC to OC and OC to OC.
Cross-modal Learning for Domain Adaptation in 3D Semantic Segmentation
Jan 18, 2021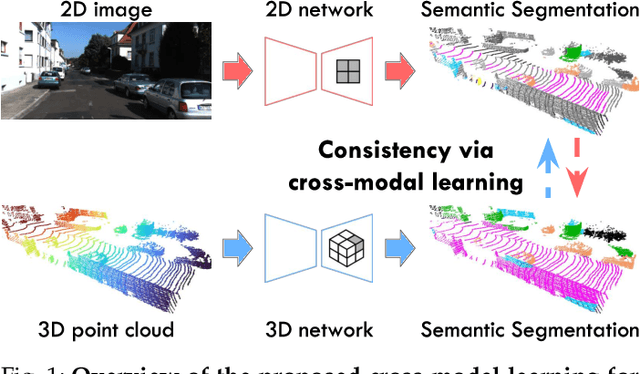
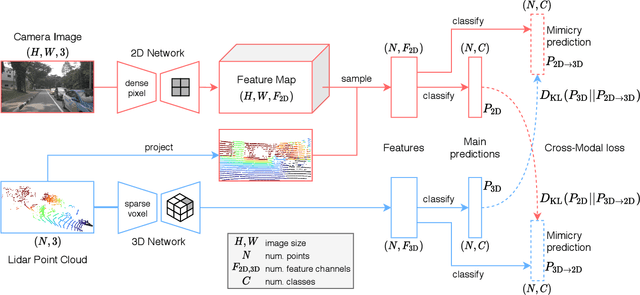
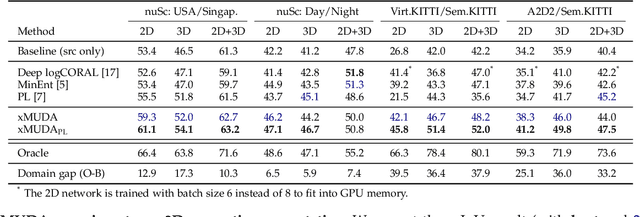
Domain adaptation is an important task to enable learning when labels are scarce. While most works focus only on the image modality, there are many important multi-modal datasets. In order to leverage multi-modality for domain adaptation, we propose cross-modal learning, where we enforce consistency between the predictions of two modalities via mutual mimicking. We constrain our network to make correct predictions on labeled data and consistent predictions across modalities on unlabeled target-domain data. Experiments in unsupervised and semi-supervised domain adaptation settings prove the effectiveness of this novel domain adaptation strategy. Specifically, we evaluate on the task of 3D semantic segmentation using the image and point cloud modality. We leverage recent autonomous driving datasets to produce a wide variety of domain adaptation scenarios including changes in scene layout, lighting, sensor setup and weather, as well as the synthetic-to-real setup. Our method significantly improves over previous uni-modal adaptation baselines on all adaption scenarios. Code will be made available.
Designing Adaptive Neural Networks for Energy-Constrained Image Classification
Aug 07, 2018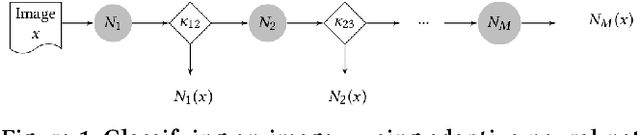
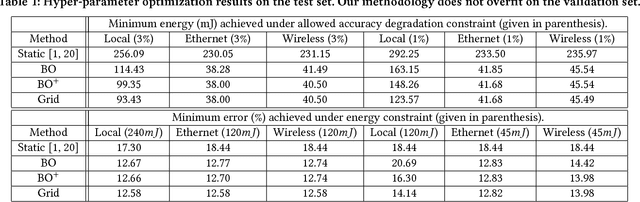
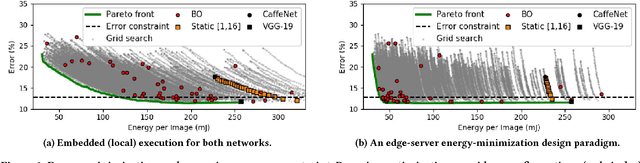
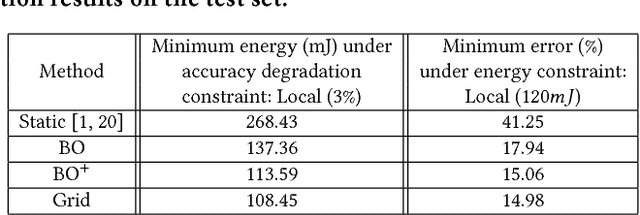
As convolutional neural networks (CNNs) enable state-of-the-art computer vision applications, their high energy consumption has emerged as a key impediment to their deployment on embedded and mobile devices. Towards efficient image classification under hardware constraints, prior work has proposed adaptive CNNs, i.e., systems of networks with different accuracy and computation characteristics, where a selection scheme adaptively selects the network to be evaluated for each input image. While previous efforts have investigated different network selection schemes, we find that they do not necessarily result in energy savings when deployed on mobile systems. The key limitation of existing methods is that they learn only how data should be processed among the CNNs and not the network architectures, with each network being treated as a blackbox. To address this limitation, we pursue a more powerful design paradigm where the architecture settings of the CNNs are treated as hyper-parameters to be globally optimized. We cast the design of adaptive CNNs as a hyper-parameter optimization problem with respect to energy, accuracy, and communication constraints imposed by the mobile device. To efficiently solve this problem, we adapt Bayesian optimization to the properties of the design space, reaching near-optimal configurations in few tens of function evaluations. Our method reduces the energy consumed for image classification on a mobile device by up to 6x, compared to the best previously published work that uses CNNs as blackboxes. Finally, we evaluate two image classification practices, i.e., classifying all images locally versus over the cloud under energy and communication constraints.
Adaptive Deconvolution-based stereo matching Net for Local Stereo Matching
Jan 01, 2021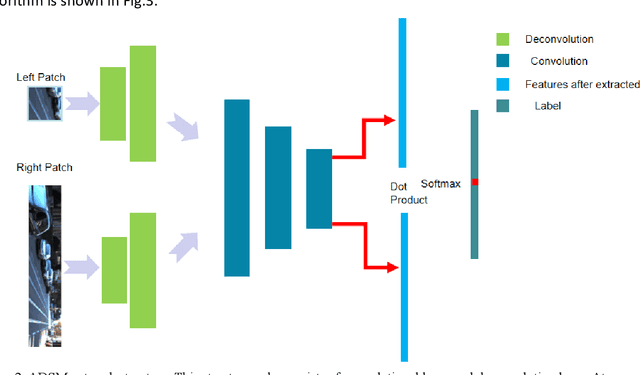
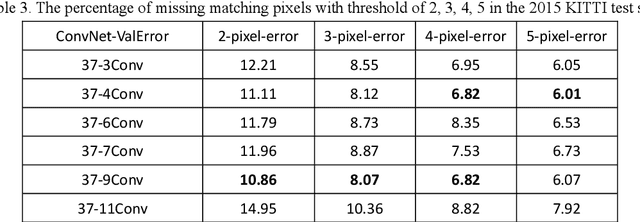
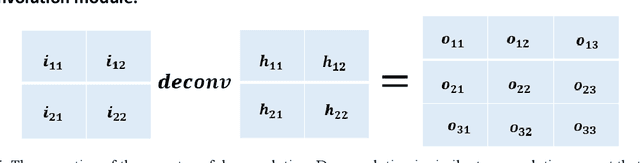
In deep learning-based local stereo matching methods, larger image patches usually bring better stereo matching accuracy. However, it is unrealistic to increase the size of the image patch size without restriction. Arbitrarily extending the patch size will change the local stereo matching method into the global stereo matching method, and the matching accuracy will be saturated. We simplified the existing Siamese convolutional network by reducing the number of network parameters and propose an efficient CNN based structure, namely Adaptive Deconvolution-based disparity matching Net (ADSM net) by adding deconvolution layers to learn how to enlarge the size of input feature map for the following convolution layers. Experimental results on the KITTI 2012 and 2015 datasets demonstrate that the proposed method can achieve a good trade-off between accuracy and complexity.
A Boosting Method to Face Image Super-resolution
May 04, 2018
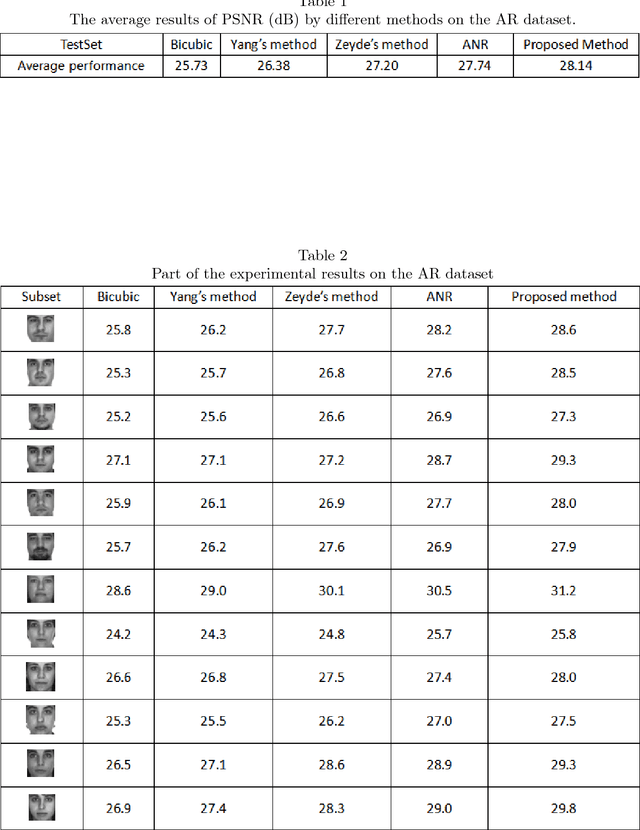
Recently sparse representation has gained great success in face image super-resolution. The conventional sparsity-based methods enforce sparse coding on face image patches and the representation fidelity is measured by $\ell_{2}$-norm. Such a sparse coding model regularizes all facial patches equally, which however ignores distinct natures of different facial patches for image reconstruction. In this paper, we propose a new weighted-patch super-resolution method based on AdaBoost. Specifically, in each iteration of the AdaBoost operation, each facial patch is weighted automatically according to the performance of the model on it, so as to highlight those patches that are more critical for improving the reconstruction power in next step. In this way, through the AdaBoost training procedure, we can focus more on the patches (face regions) with richer information. Various experimental results on standard face database show that our proposed method outperforms state-of-the-art methods in terms of both objective metrics and visual quality.