 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Little Robustness Goes a Long Way: Leveraging Universal Features for Targeted Transfer Attacks
Jun 03, 2021
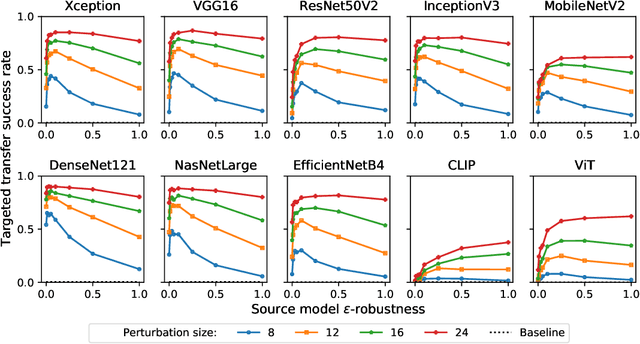
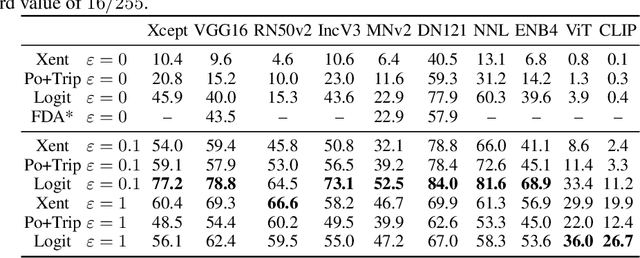
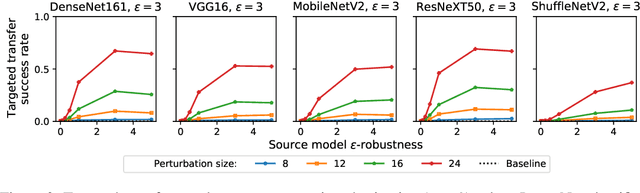
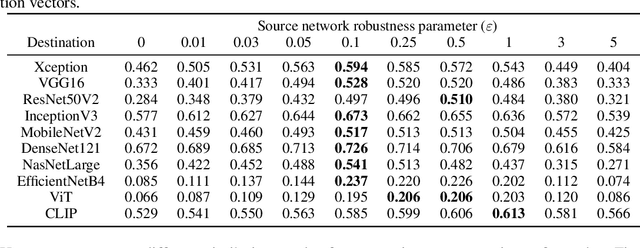
Adversarial examples for neural network image classifiers are known to be transferable: examples optimized to be misclassified by a source classifier are often misclassified as well by classifiers with different architectures. However, targeted adversarial examples -- optimized to be classified as a chosen target class -- tend to be less transferable between architectures. While prior research on constructing transferable targeted attacks has focused on improving the optimization procedure, in this work we examine the role of the source classifier. Here, we show that training the source classifier to be "slightly robust" -- that is, robust to small-magnitude adversarial examples -- substantially improves the transferability of targeted attacks, even between architectures as different as convolutional neural networks and transformers. We argue that this result supports a non-intuitive hypothesis: on the spectrum from non-robust (standard) to highly robust classifiers, those that are only slightly robust exhibit the most universal features -- ones that tend to overlap with the features learned by other classifiers trained on the same dataset. The results we present provide insight into the nature of adversarial examples as well as the mechanisms underlying so-called "robust" classifiers.
Efficient Deep Learning Architectures for Fast Identification of Bacterial Strains in Resource-Constrained Devices
Jun 11, 2021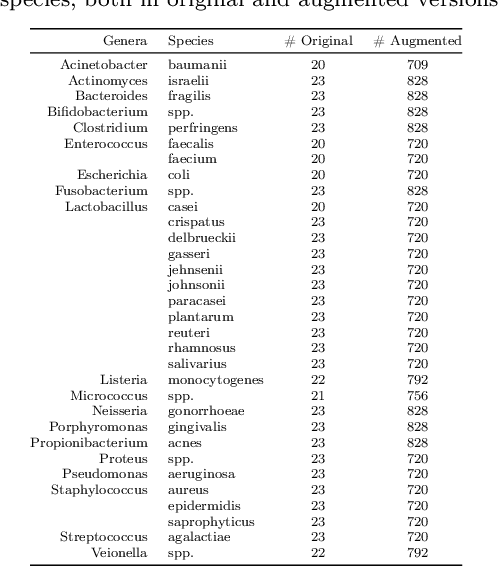

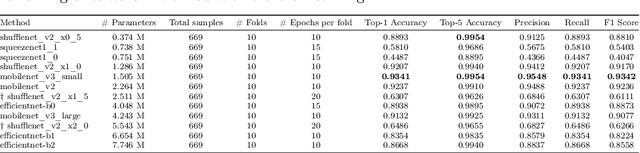
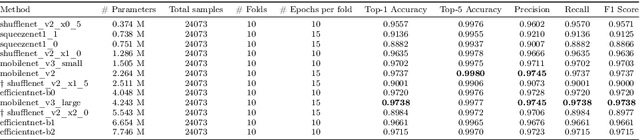
This work presents twelve fine-tuned deep learning architectures to solve the bacterial classification problem over the Digital Image of Bacterial Species Dataset. The base architectures were mainly published as mobile or efficient solutions to the ImageNet challenge, and all experiments presented in this work consisted of making several modifications to the original designs, in order to make them able to solve the bacterial classification problem by using fine-tuning and transfer learning techniques. This work also proposes a novel data augmentation technique for this dataset, which is based on the idea of artificial zooming, strongly increasing the performance of every tested architecture, even doubling it in some cases. In order to get robust and complete evaluations, all experiments were performed with 10-fold cross-validation and evaluated with five different metrics: top-1 and top-5 accuracy, precision, recall, and F1 score. This paper presents a complete comparison of the twelve different architectures, cross-validated with the original and the augmented version of the dataset, the results are also compared with several literature methods. Overall, eight of the eleven architectures surpassed the 0.95 scores in top-1 accuracy with our data augmentation method, being 0.9738 the highest top-1 accuracy. The impact of the data augmentation technique is reported with relative improvement scores.
The Contextual Loss for Image Transformation with Non-Aligned Data
Jul 18, 2018

Feed-forward CNNs trained for image transformation problems rely on loss functions that measure the similarity between the generated image and a target image. Most of the common loss functions assume that these images are spatially aligned and compare pixels at corresponding locations. However, for many tasks, aligned training pairs of images will not be available. We present an alternative loss function that does not require alignment, thus providing an effective and simple solution for a new space of problems. Our loss is based on both context and semantics -- it compares regions with similar semantic meaning, while considering the context of the entire image. Hence, for example, when transferring the style of one face to another, it will translate eyes-to-eyes and mouth-to-mouth. Our code can be found at https://www.github.com/roimehrez/contextualLoss
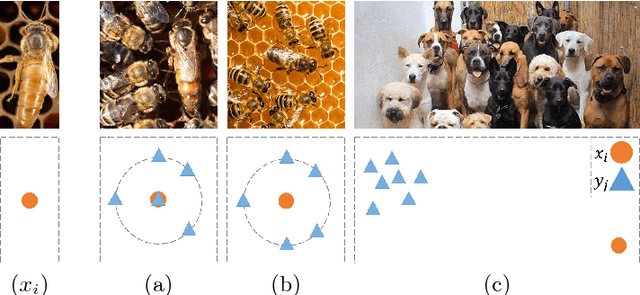
The Earth Mover's Pinball Loss: Quantiles for Histogram-Valued Regression
Jun 03, 2021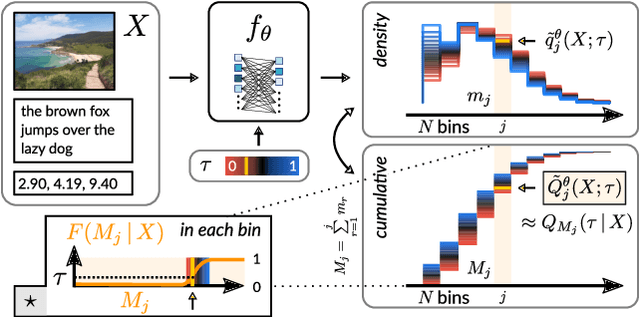
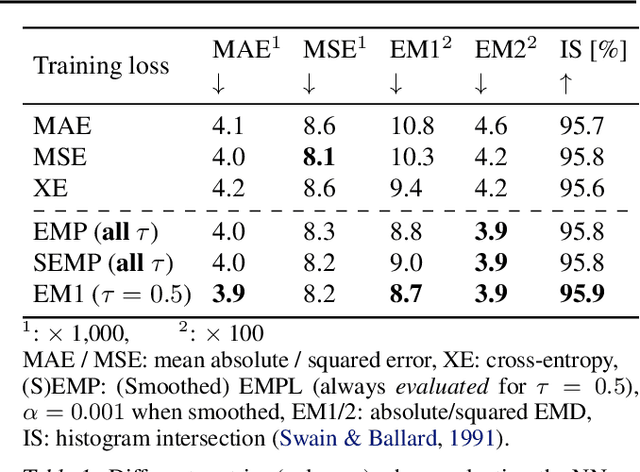
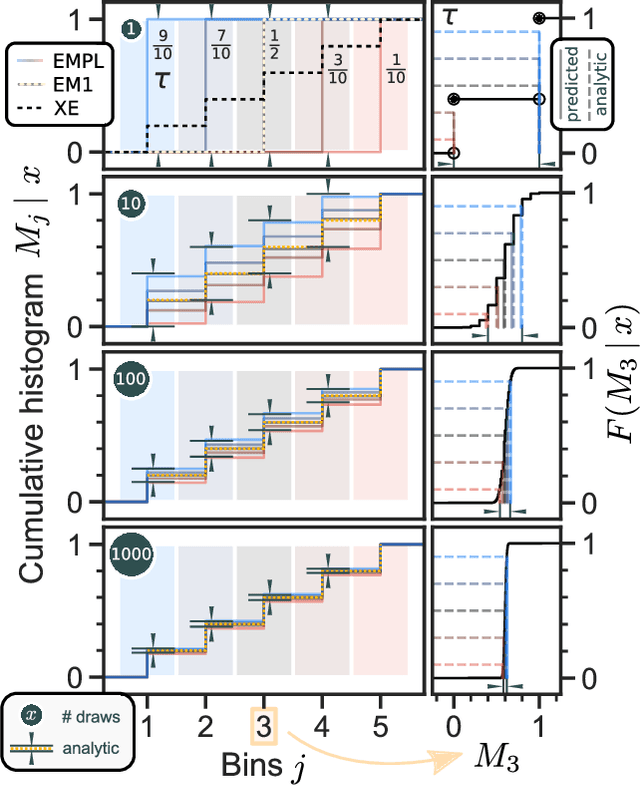
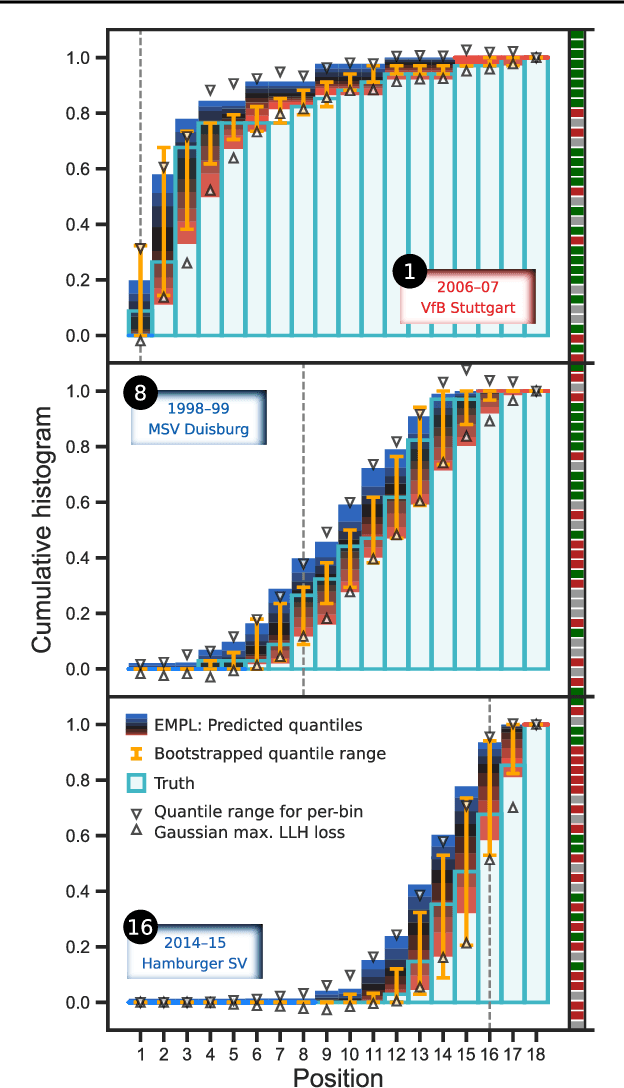
Although ubiquitous in the sciences, histogram data have not received much attention by the Deep Learning community. Whilst regression and classification tasks for scalar and vector data are routinely solved by neural networks, a principled approach for estimating histogram labels as a function of an input vector or image is lacking in the literature. We present a dedicated method for Deep Learning-based histogram regression, which incorporates cross-bin information and yields distributions over possible histograms, expressed by $\tau$-quantiles of the cumulative histogram in each bin. The crux of our approach is a new loss function obtained by applying the pinball loss to the cumulative histogram, which for 1D histograms reduces to the Earth Mover's distance (EMD) in the special case of the median ($\tau = 0.5$), and generalizes it to arbitrary quantiles. We validate our method with an illustrative toy example, a football-related task, and an astrophysical computer vision problem. We show that with our loss function, the accuracy of the predicted median histograms is very similar to the standard EMD case (and higher than for per-bin loss functions such as cross-entropy), while the predictions become much more informative at almost no additional computational cost.
Successive Subspace Learning: An Overview
Feb 27, 2021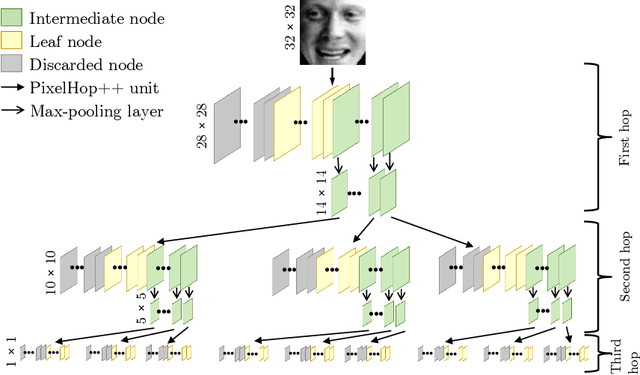
Successive Subspace Learning (SSL) offers a light-weight unsupervised feature learning method based on inherent statistical properties of data units (e.g. image pixels and points in point cloud sets). It has shown promising results, especially on small datasets. In this paper, we intuitively explain this method, provide an overview of its development, and point out some open questions and challenges for future research.
CADDA: Class-wise Automatic Differentiable Data Augmentation for EEG Signals
Jun 25, 2021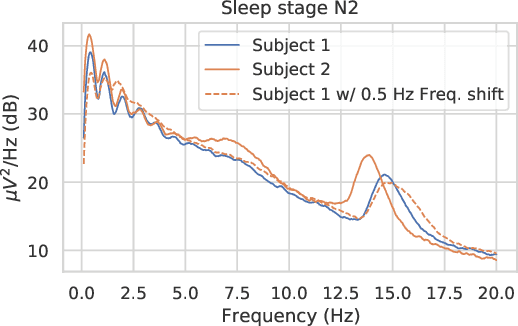
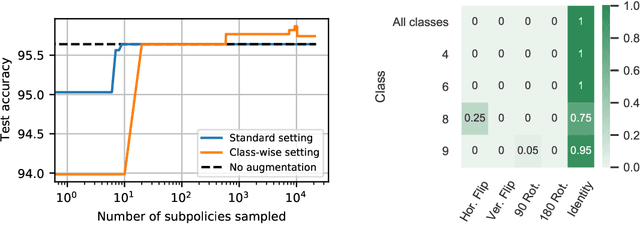
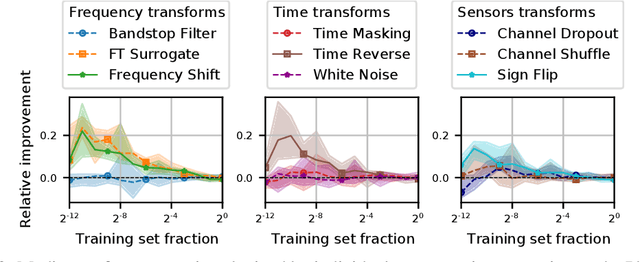
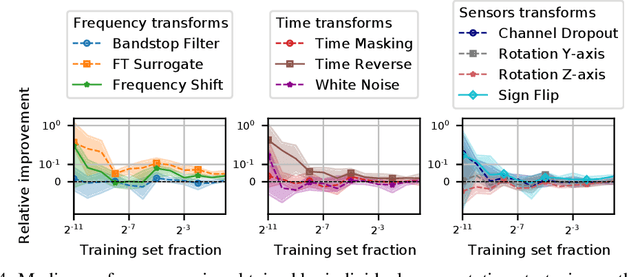
Data augmentation is a key element of deep learning pipelines, as it informs the network during training about transformations of the input data that keep the label unchanged. Manually finding adequate augmentation methods and parameters for a given pipeline is however rapidly cumbersome. In particular, while intuition can guide this decision for images, the design and choice of augmentation policies remains unclear for more complex types of data, such as neuroscience signals. Moreover, label independent strategies might not be suitable for such structured data and class-dependent augmentations might be necessary. This idea has been surprisingly unexplored in the literature, while it is quite intuitive: changing the color of a car image does not change the object class to be predicted, but doing the same to the picture of an orange does. This paper aims to increase the generalization power added through class-wise data augmentation. Yet, as seeking transformations depending on the class largely increases the complexity of the task, using gradient-free optimization techniques as done by most existing automatic approaches becomes intractable for real-world datasets. For this reason we propose to use differentiable data augmentation amenable to gradient-based learning. EEG signals are a perfect example of data for which good augmentation policies are mostly unknown. In this work, we demonstrate the relevance of our approach on the clinically relevant sleep staging classification task, for which we also propose differentiable transformations.
XCloud-pFISTA: A Medical Intelligence Cloud for Accelerated MRI
Apr 18, 2021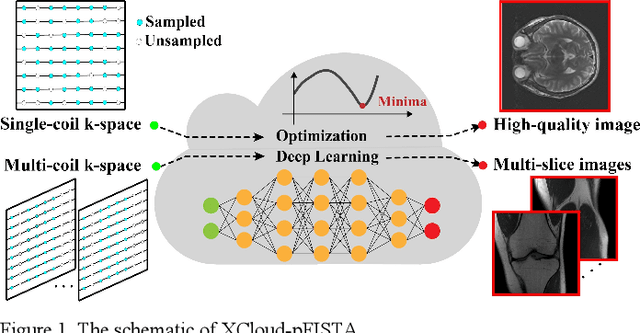
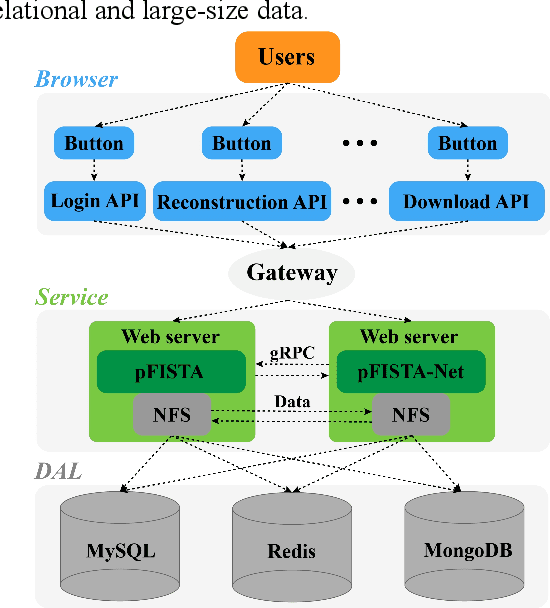
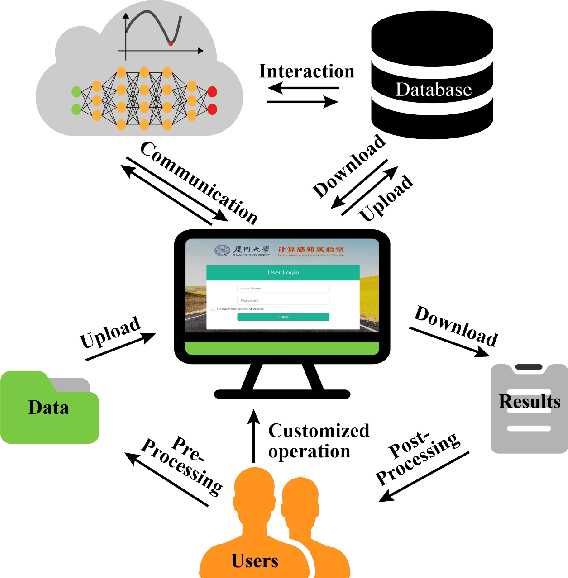
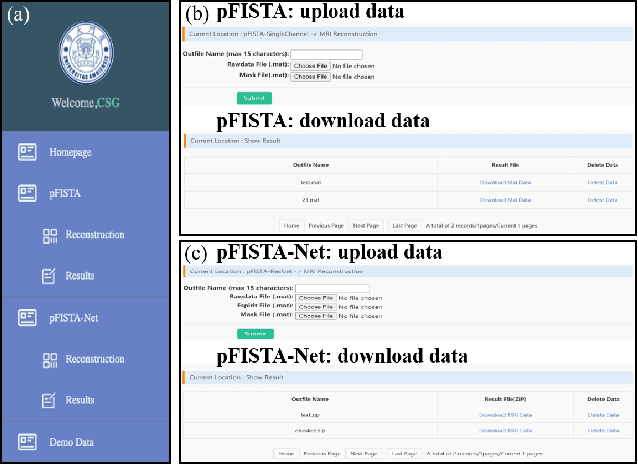
Machine learning and artificial intelligence have shown remarkable performance in accelerated magnetic resonance imaging (MRI). Cloud computing technologies have great advantages in building an easily accessible platform to deploy advanced algorithms. In this work, we develop an open-access, easy-to-use and high-performance medical intelligence cloud computing platform (XCloud-pFISTA) to reconstruct MRI images from undersampled k-space data. Two state-of-the-art approaches of the Projected Fast Iterative Soft-Thresholding Algorithm (pFISTA) family have been successfully implemented on the cloud. This work can be considered as a good example of cloud-based medical image reconstruction and may benefit the future development of integrated reconstruction and online diagnosis system.
Time-Dependent Deep Image Prior for Dynamic MRI
Oct 03, 2019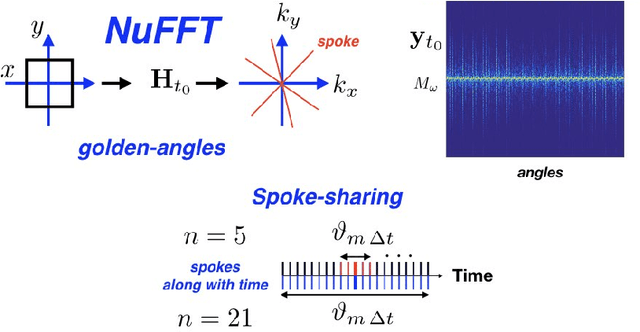


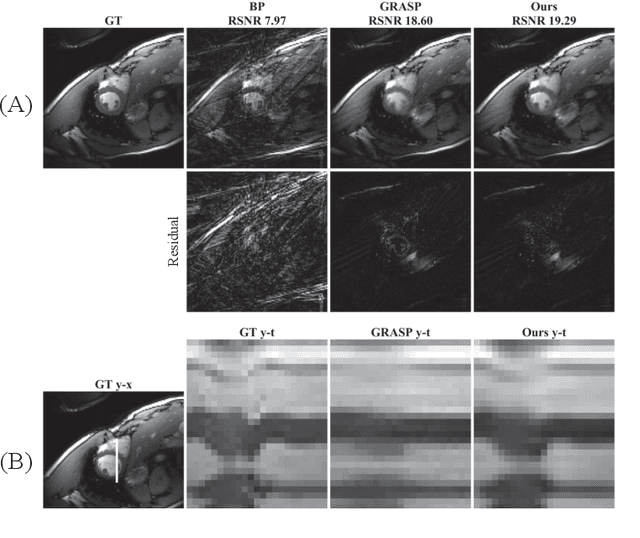
We propose a novel unsupervised deep-learning-based algorithm to solve the inverse problem found in dynamic magnetic resonance imaging (MRI). Our method needs neither prior training nor additional data; in particular, it does not require either electrocardiogram or spokes-reordering in the context of cardiac images. It generalizes to sequences of images the recently introduced deep-image-prior approach. The essence of the proposed algorithm is to proceed in two steps to fit k-space synthetic measurements to sparsely acquired dynamic MRI data. In the first step, we deploy a convolutional neural network (CNN) driven by a sequence of low-dimensional latent variables to generate a dynamic series of MRI images. In the second step, we submit the generated images to a nonuniform fast Fourier transform that represents the forward model of the MRI system. By manipulating the weights of the CNN, we fit our synthetic measurements to the acquired MRI data. The corresponding images from the CNN then provide the output of our system; their evolution through time is driven by controlling the sequence of latent variables whose interpolation gives access to the sub-frame---or even continuous---temporal control of reconstructed dynamic images. We perform experiments on simulated and real cardiac images of a fetus acquired through 5-spoke-based golden-angle measurements. Our results show improvement over the current state-of-the-art.
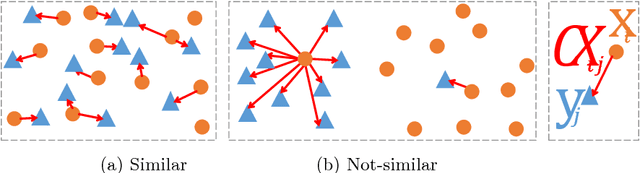
Generalized Contrastive Optimization of Siamese Networks for Place Recognition
Mar 11, 2021
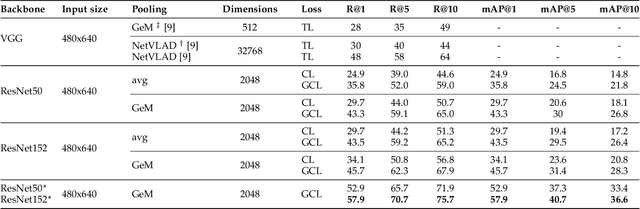
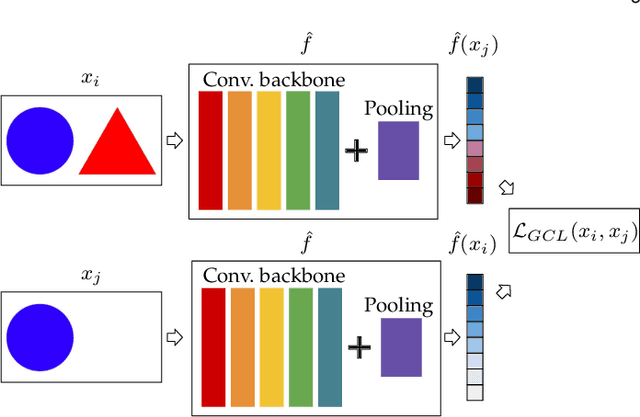
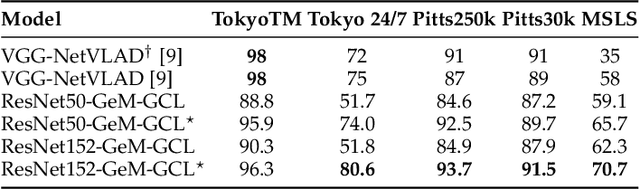
Visual place recognition is a challenging task in computer vision and a key component of camera-based localization and navigation systems. Recently, Convolutional Neural Networks (CNNs) achieved high results and good generalization capabilities. They are usually trained using pairs or triplets of images labeled as either similar or dissimilar, in a binary fashion. In practice, the similarity between two images is not binary, but rather continuous. Furthermore, training these CNNs is computationally complex and involves costly pair and triplet mining strategies. We propose a Generalized Contrastive loss (GCL) function that relies on image similarity as a continuous measure, and use it to train a siamese CNN. Furthermore, we propose three techniques for automatic annotation of image pairs with labels indicating their degree of similarity, and deploy them to re-annotate the MSLS, TB-Places, and 7Scenes datasets. We demonstrate that siamese CNNs trained using the GCL function and the improved annotations consistently outperform their binary counterparts. Our models trained on MSLS outperform the state-of-the-art methods, including NetVLAD, and generalize well on the Pittsburgh, TokyoTM and Tokyo 24/7 datasets. Furthermore, training a siamese network using the GCL function does not require complex pair mining. We release the source code at https://github.com/marialeyvallina/generalized_contrastive_loss.
Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer
May 06, 2021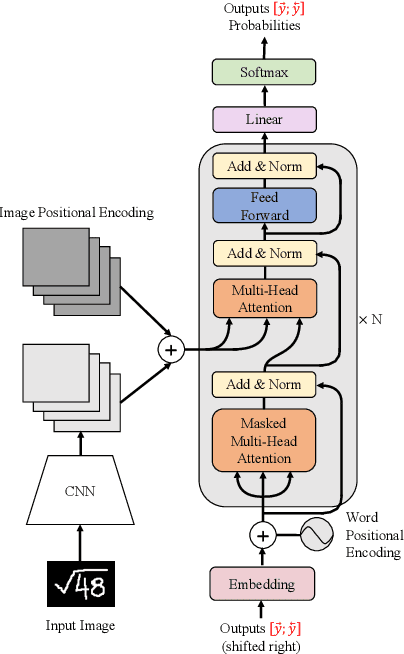
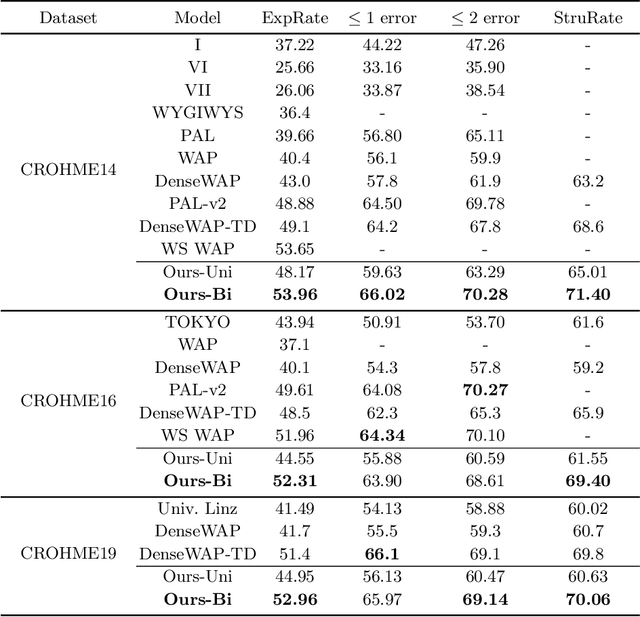
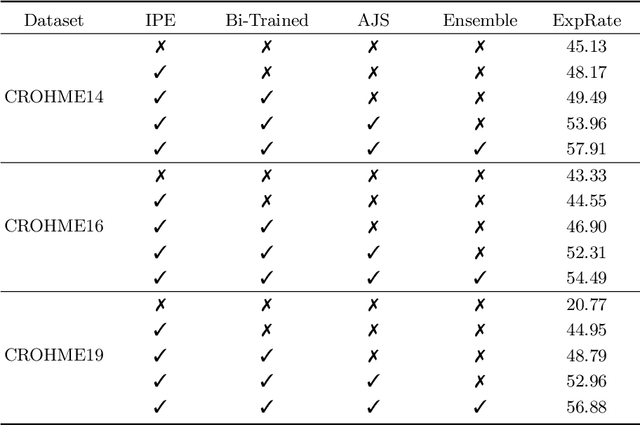
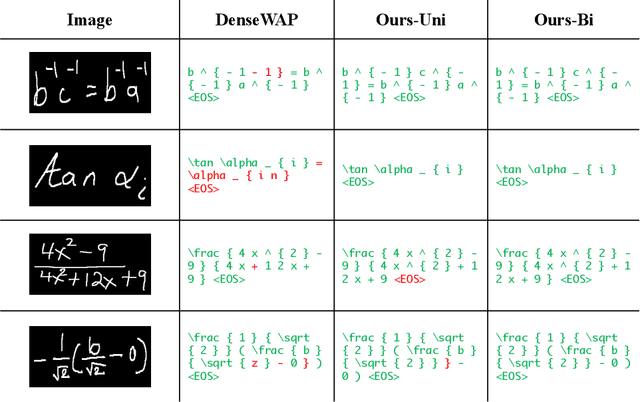
Encoder-decoder models have made great progress on handwritten mathematical expression recognition recently. However, it is still a challenge for existing methods to assign attention to image features accurately. Moreover, those encoder-decoder models usually adopt RNN-based models in their decoder part, which makes them inefficient in processing long $\LaTeX{}$ sequences. In this paper, a transformer-based decoder is employed to replace RNN-based ones, which makes the whole model architecture very concise. Furthermore, a novel training strategy is introduced to fully exploit the potential of the transformer in bidirectional language modeling. Compared to several methods that do not use data augmentation, experiments demonstrate that our model improves the ExpRate of current state-of-the-art methods on CROHME 2014 by 2.23%. Similarly, on CROHME 2016 and CROHME 2019, we improve the ExpRate by 1.92% and 2.28% respectively.