 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Dialogue Dodecathlon: Open-Domain Knowledge and Image Grounded Conversational Agents
Nov 09, 2019
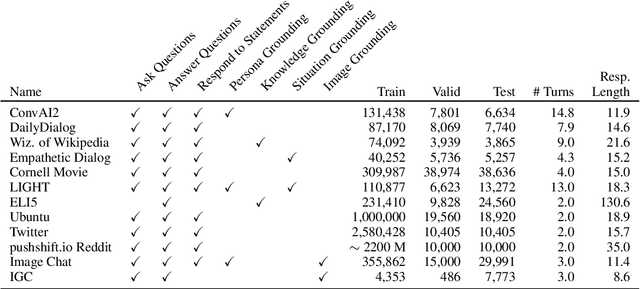
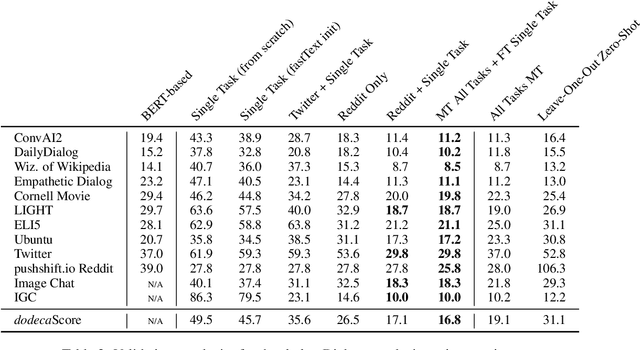
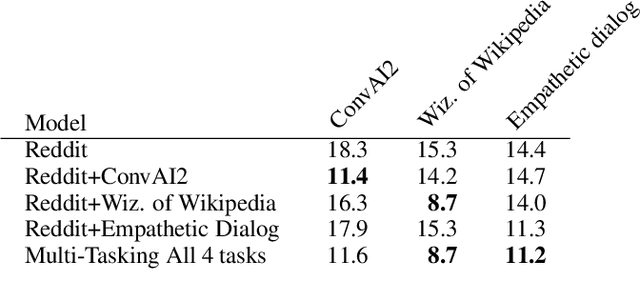

We introduce dodecaDialogue: a set of 12 tasks that measures if a conversational agent can communicate engagingly with personality and empathy, ask questions, answer questions by utilizing knowledge resources, discuss topics and situations, and perceive and converse about images. By multi-tasking on such a broad large-scale set of data, we hope to both move towards and measure progress in producing a single unified agent that can perceive, reason and converse with humans in an open-domain setting. We show that such multi-tasking improves over a BERT pre-trained baseline, largely due to multi-tasking with very large dialogue datasets in a similar domain, and that the multi-tasking in general provides gains to both text and image-based tasks using several metrics in both the fine-tune and task transfer settings. We obtain state-of-the-art results on many of the tasks, providing a strong baseline for this challenge.
MEG: Multi-Evidence GNN for Multimodal Semantic Forensics
Nov 23, 2020
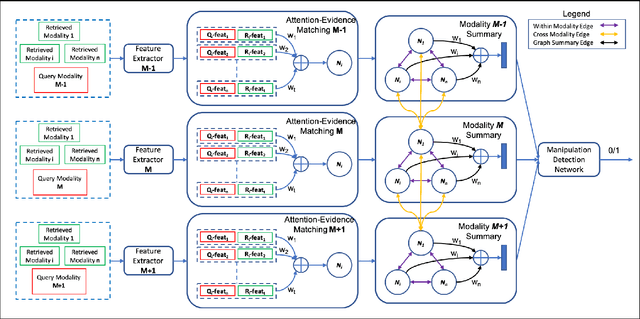


Fake news often involves semantic manipulations across modalities such as image, text, location etc and requires the development of multimodal semantic forensics for its detection. Recent research has centered the problem around images, calling it image repurposing -- where a digitally unmanipulated image is semantically misrepresented by means of its accompanying multimodal metadata such as captions, location, etc. The image and metadata together comprise a multimedia package. The problem setup requires algorithms to perform multimodal semantic forensics to authenticate a query multimedia package using a reference dataset of potentially related packages as evidences. Existing methods are limited to using a single evidence (retrieved package), which ignores potential performance improvement from the use of multiple evidences. In this work, we introduce a novel graph neural network based model for multimodal semantic forensics, which effectively utilizes multiple retrieved packages as evidences and is scalable with the number of evidences. We compare the scalability and performance of our model against existing methods. Experimental results show that the proposed model outperforms existing state-of-the-art algorithms with an error reduction of up to 25%.
Computer-Aided Design as Language
May 06, 2021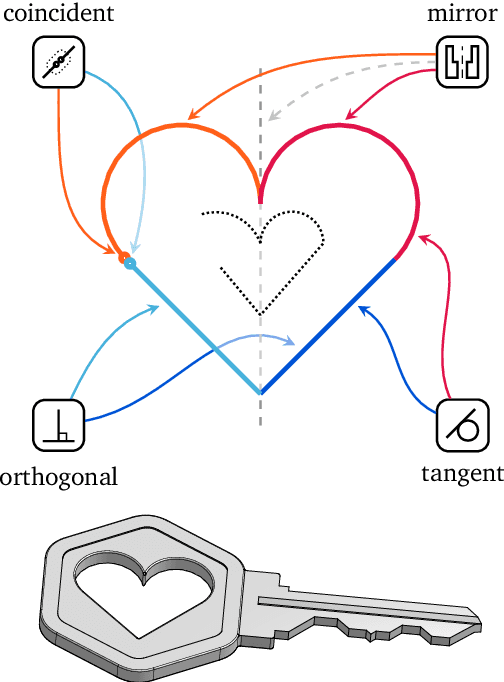
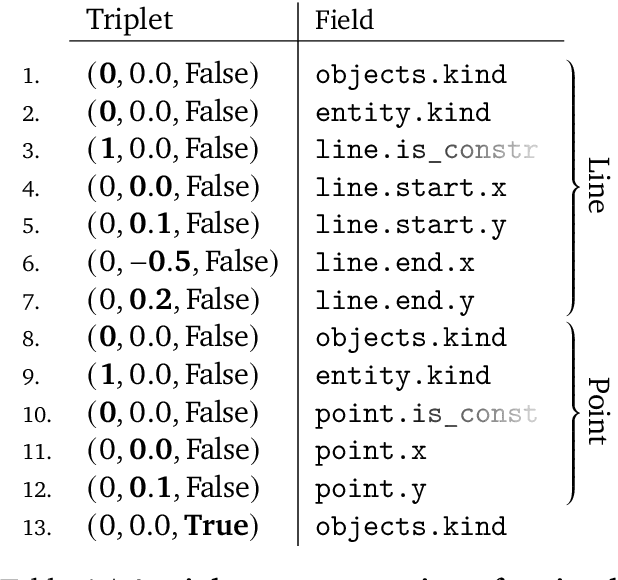
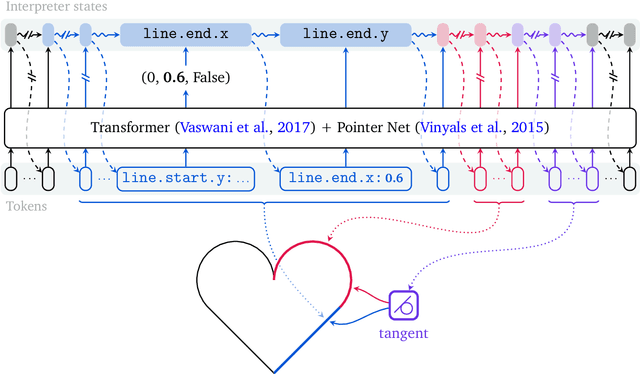
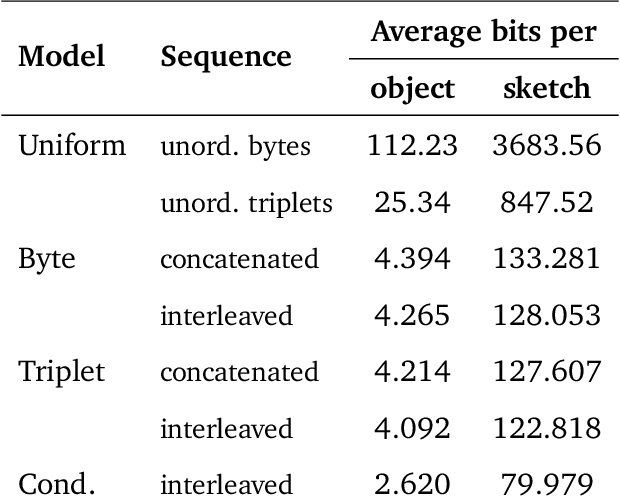
Computer-Aided Design (CAD) applications are used in manufacturing to model everything from coffee mugs to sports cars. These programs are complex and require years of training and experience to master. A component of all CAD models particularly difficult to make are the highly structured 2D sketches that lie at the heart of every 3D construction. In this work, we propose a machine learning model capable of automatically generating such sketches. Through this, we pave the way for developing intelligent tools that would help engineers create better designs with less effort. Our method is a combination of a general-purpose language modeling technique alongside an off-the-shelf data serialization protocol. We show that our approach has enough flexibility to accommodate the complexity of the domain and performs well for both unconditional synthesis and image-to-sketch translation.
Volume and leaf area calculation of cabbage with a neural network-based instance segmentation
Apr 12, 2021
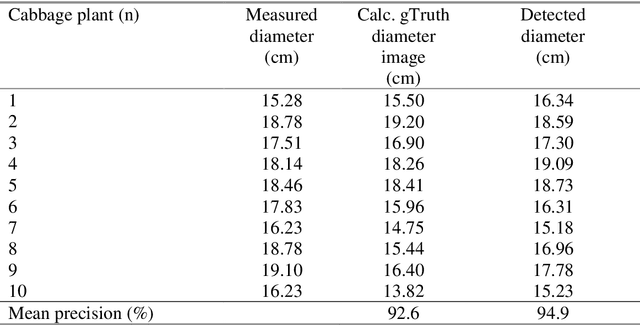
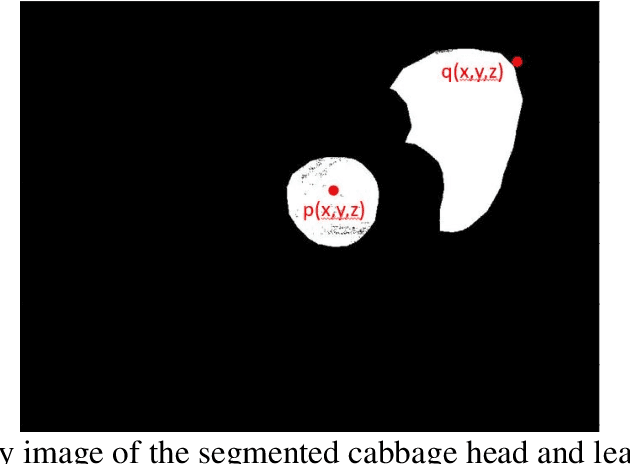
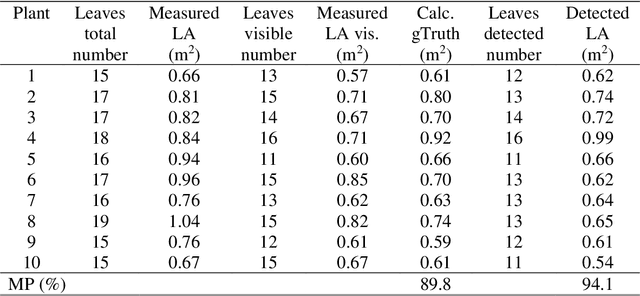
Fruit size and leaf area are important indicators for plant health and are of interest for plant nutrient management, plant protection and harvest. In this research, an image-based method for measuring the fruit volume as well as the leaf area for cabbage is presented. For this purpose, a mask region-based convolutional neural network (Mask R-CNN) was trained to segment the cabbage fruit from the leaves and assign it to the corresponding plant. The results indicated that even with a single camera, the developed method can provide a calculation accuracy of fruit size of 92.6% and an accuracy of leaf area of 89.8% on individual plant level.
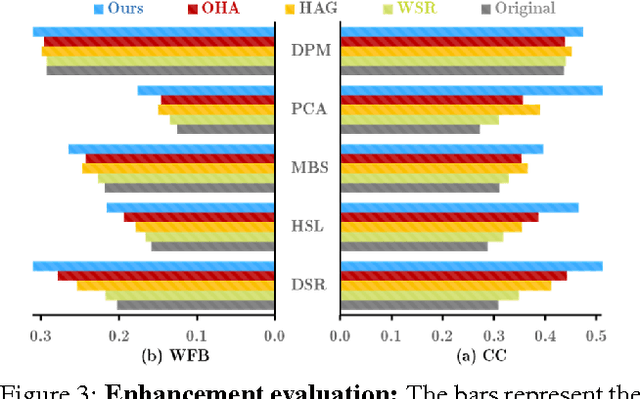
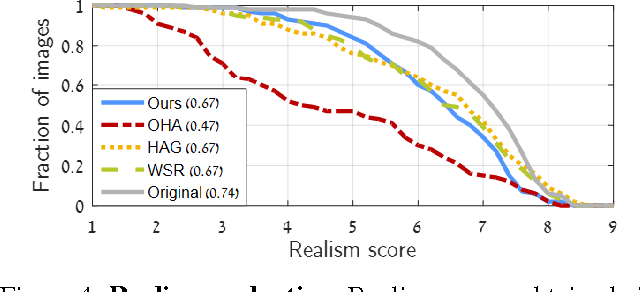
Legibility Enhancement of Papyri Using Color Processing and Visual Illusions: A Case Study in Critical Vision
Mar 11, 2021
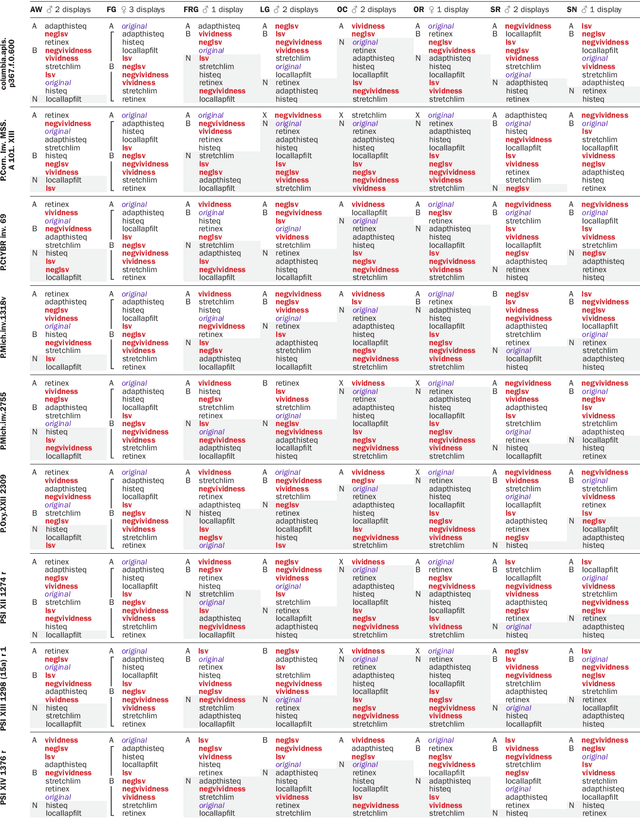

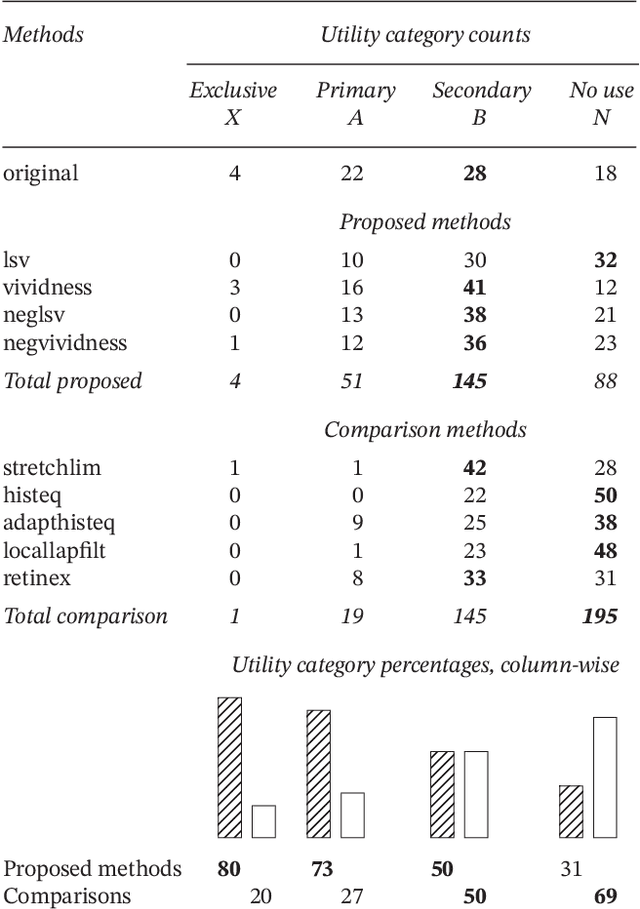
Purpose: This article develops theoretical, algorithmic, perceptual, and interaction aspects of script legibility enhancement in the visible light spectrum for the purpose of scholarly editing of papyri texts. - Methods: Novel legibility enhancement algorithms based on color processing and visual illusions are proposed and compared to classic methods. A user experience experiment was carried out to evaluate the solutions and better understand the problem on an empirical basis. - Results: (1) The proposed methods outperformed the comparison methods. (2) The methods that most successfully enhanced script legibility were those that leverage human perception. (3) Users exhibited a broad behavioral spectrum of text-deciphering strategies, under the influence of factors such as personality and social conditioning, tasks and application domains, expertise level and image quality, and affordances of software, hardware, and interfaces. No single method satisfied all factor configurations. Therefore, using synergetically a range of enhancement methods and interaction modalities is suggested for optimal results and user satisfaction. (4) A paradigm of legibility enhancement for critical applications is outlined, comprising the following criteria: interpreting images skeptically; approaching enhancement as a system problem; considering all image structures as potential information; deriving interpretations from connections across distinct spatial locations; and making uncertainty and alternative interpretations explicit, both visually and numerically.
Block-optimized Variable Bit Rate Neural Image Compression
May 28, 2018
In this work, we propose an end-to-end block-based auto-encoder system for image compression. We introduce novel contributions to neural-network based image compression, mainly in achieving binarization simulation, variable bit rates with multiple networks, entropy-friendly representations, inference-stage code optimization and performance-improving normalization layers in the auto-encoder. We evaluate and show the incremental performance increase of each of our contributions.
Empty Cities: Image Inpainting for a Dynamic-Object-Invariant Space
Sep 20, 2018
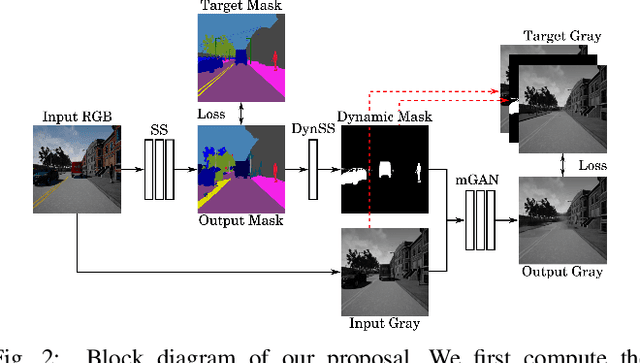

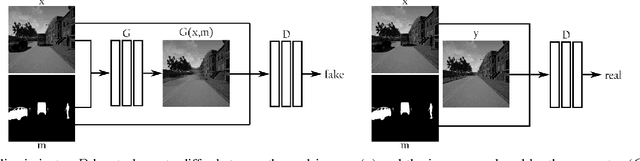
In this paper we present an end-to-end deep learning framework to turn images that show dynamic content, such as vehicles or pedestrians, into realistic static frames. This objective encounters two main challenges: detecting the dynamic objects, and inpainting the static occluded background. The second challenge is approached with a conditional generative adversarial model that, taking as input the original dynamic image and the computed dynamic/static binary mask, is capable of generating the final static image. The former challenge is addressed by the use of a convolutional network that learns a multi-class semantic segmentation of the image. The objective of this network is producing an accurate segmentation and helping the previous generative model to output a realistic static image. These generated images can be used for applications such as virtual reality or vision-based robot localization purposes. To validate our approach, we show both qualitative and quantitative comparisons against other inpainting methods by removing the dynamic objects and hallucinating the static structure behind them. Furthermore, to demonstrate the potential of our results, we conduct pilot experiments showing the benefits of our proposal for visual place recognition. Code has been made available on https://github.com/bertabescos/EmptyCities.
Saliency Driven Image Manipulation
Jan 17, 2018
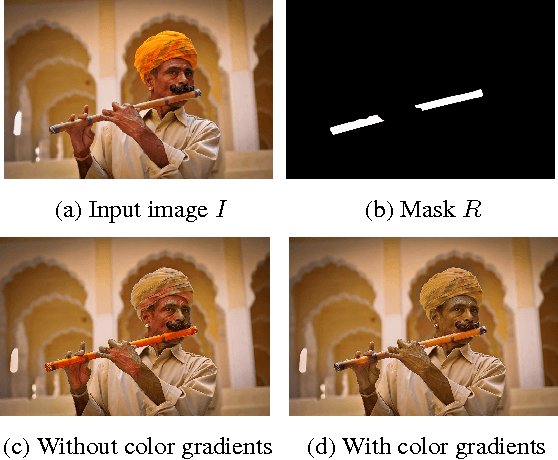
Have you ever taken a picture only to find out that an unimportant background object ended up being overly salient? Or one of those team sports photos where your favorite player blends with the rest? Wouldn't it be nice if you could tweak these pictures just a little bit so that the distractor would be attenuated and your favorite player will stand-out among her peers? Manipulating images in order to control the saliency of objects is the goal of this paper. We propose an approach that considers the internal color and saliency properties of the image. It changes the saliency map via an optimization framework that relies on patch-based manipulation using only patches from within the same image to achieve realistic looking results. Applications include object enhancement, distractors attenuation and background decluttering. Comparing our method to previous ones shows significant improvement, both in the achieved saliency manipulation and in the realistic appearance of the resulting images.
Uncertainty guided semi-supervised segmentation of retinal layers in OCT images
Mar 02, 2021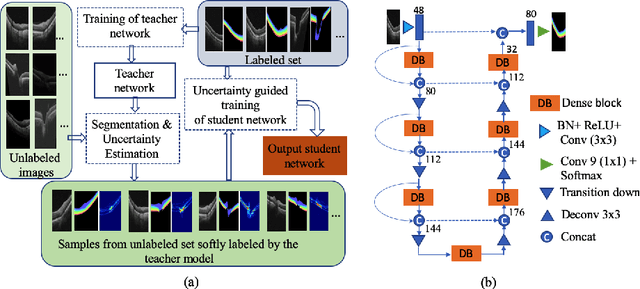
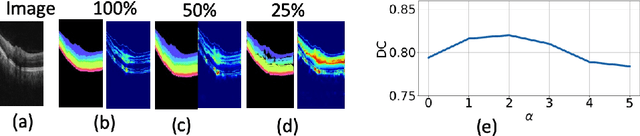
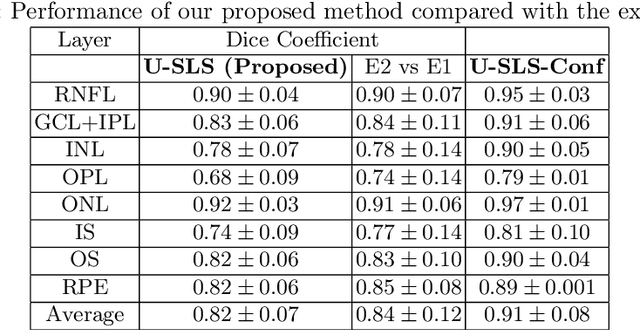
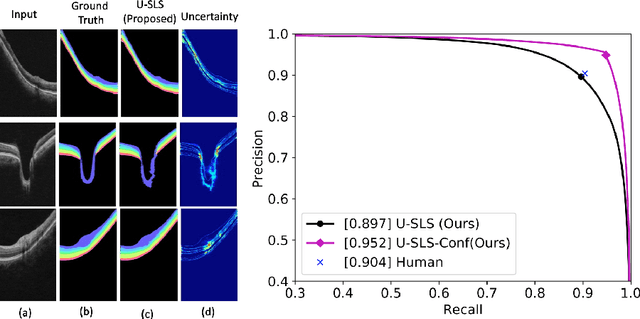
Deep convolutional neural networks have shown outstanding performance in medical image segmentation tasks. The usual problem when training supervised deep learning methods is the lack of labeled data which is time-consuming and costly to obtain. In this paper, we propose a novel uncertainty-guided semi-supervised learning based on a student-teacher approach for training the segmentation network using limited labeled samples and a large number of unlabeled images. First, a teacher segmentation model is trained from the labeled samples using Bayesian deep learning. The trained model is used to generate soft segmentation labels and uncertainty maps for the unlabeled set. The student model is then updated using the softly segmented samples and the corresponding pixel-wise confidence of the segmentation quality estimated from the uncertainty of the teacher model using a newly designed loss function. Experimental results on a retinal layer segmentation task show that the proposed method improves the segmentation performance in comparison to the fully supervised approach and is on par with the expert annotator. The proposed semi-supervised segmentation framework is a key contribution and applicable for biomedical image segmentation across various imaging modalities where access to annotated medical images is challenging
* MICCAI,19
The Contextual Loss for Image Transformation with Non-Aligned Data
Jul 18, 2018

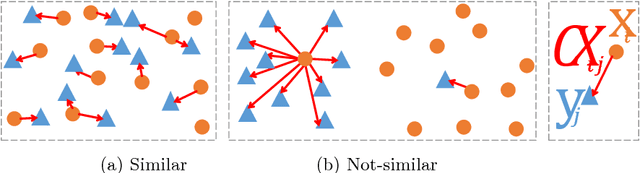
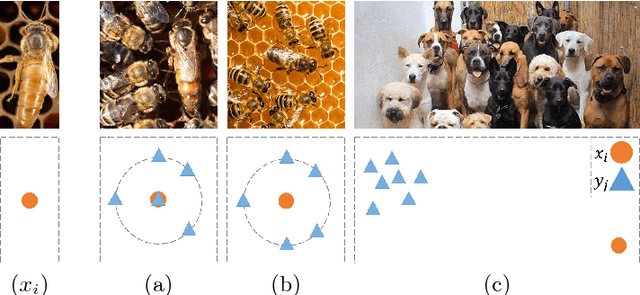
Feed-forward CNNs trained for image transformation problems rely on loss functions that measure the similarity between the generated image and a target image. Most of the common loss functions assume that these images are spatially aligned and compare pixels at corresponding locations. However, for many tasks, aligned training pairs of images will not be available. We present an alternative loss function that does not require alignment, thus providing an effective and simple solution for a new space of problems. Our loss is based on both context and semantics -- it compares regions with similar semantic meaning, while considering the context of the entire image. Hence, for example, when transferring the style of one face to another, it will translate eyes-to-eyes and mouth-to-mouth. Our code can be found at https://www.github.com/roimehrez/contextualLoss