 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Transferable Sparse Adversarial Attack
May 31, 2021
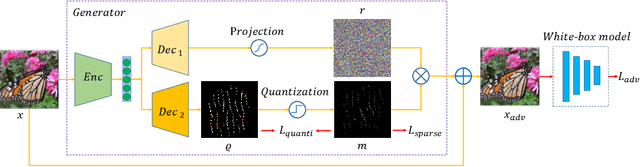
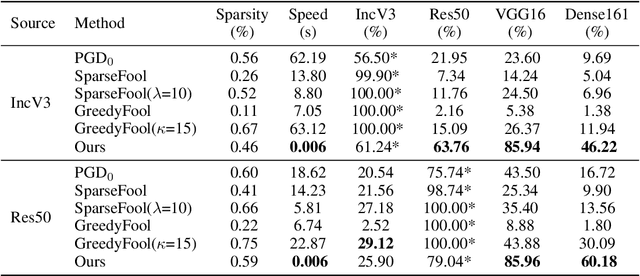
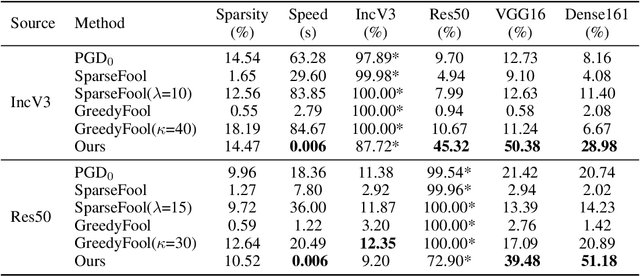
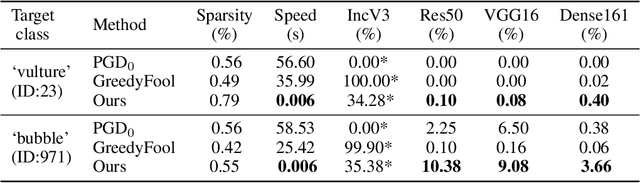
Deep neural networks have shown their vulnerability to adversarial attacks. In this paper, we focus on sparse adversarial attack based on the $\ell_0$ norm constraint, which can succeed by only modifying a few pixels of an image. Despite a high attack success rate, prior sparse attack methods achieve a low transferability under the black-box protocol due to overfitting the target model. Therefore, we introduce a generator architecture to alleviate the overfitting issue and thus efficiently craft transferable sparse adversarial examples. Specifically, the generator decouples the sparse perturbation into amplitude and position components. We carefully design a random quantization operator to optimize these two components jointly in an end-to-end way. The experiment shows that our method has improved the transferability by a large margin under a similar sparsity setting compared with state-of-the-art methods. Moreover, our method achieves superior inference speed, 700$\times$ faster than other optimization-based methods. The code is available at https://github.com/shaguopohuaizhe/TSAA.
Bayesian Kernelised Test of (In)dependence with Mixed-type Variables
May 09, 2021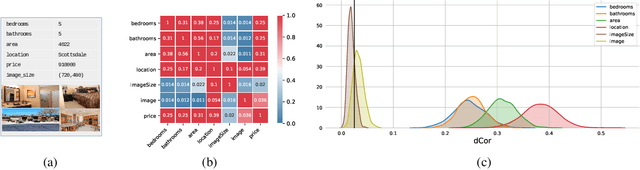
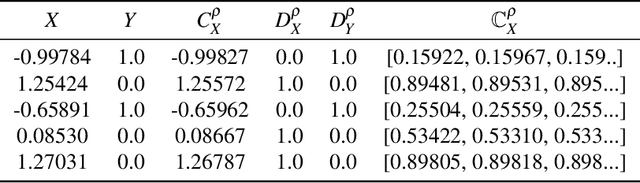
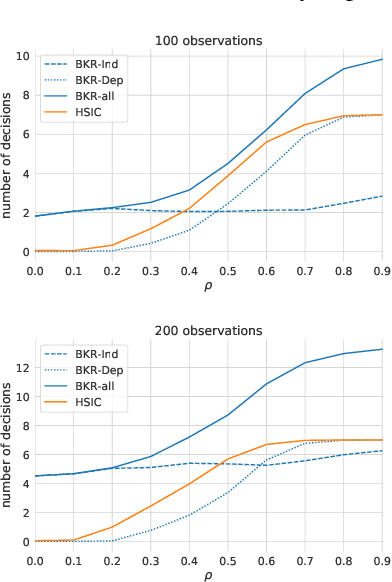
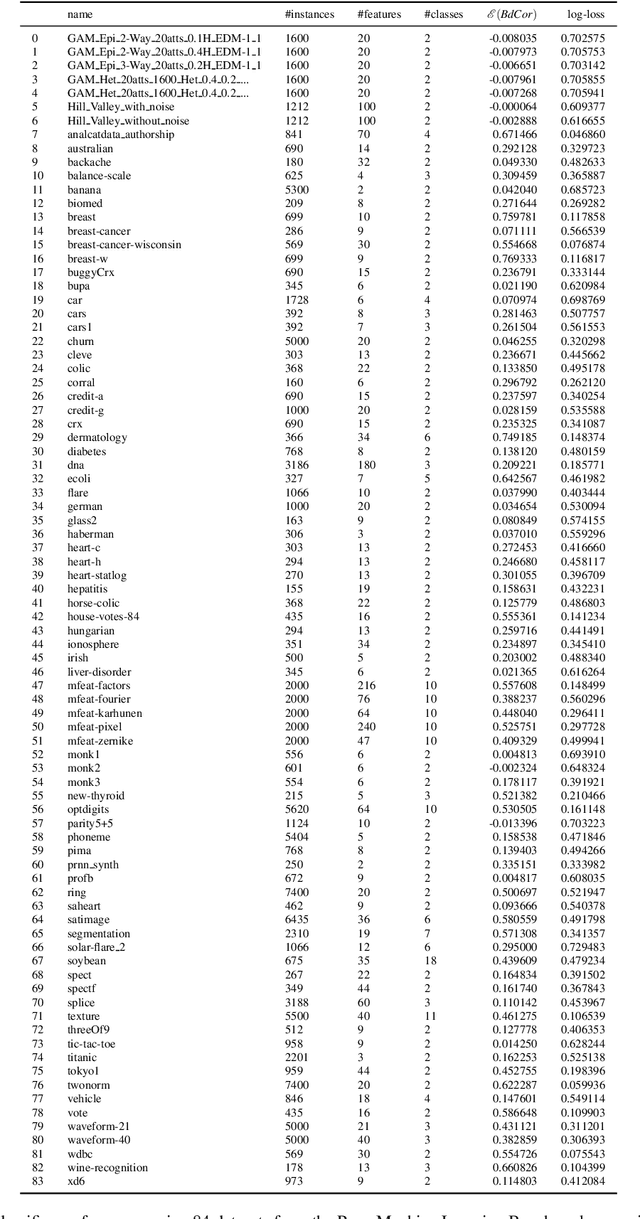
A fundamental task in AI is to assess (in)dependence between mixed-type variables (text, image, sound). We propose a Bayesian kernelised correlation test of (in)dependence using a Dirichlet process model. The new measure of (in)dependence allows us to answer some fundamental questions: Based on data, are (mixed-type) variables independent? How likely is dependence/independence to hold? How high is the probability that two mixed-type variables are more than just weakly dependent? We theoretically show the properties of the approach, as well as algorithms for fast computation with it. We empirically demonstrate the effectiveness of the proposed method by analysing its performance and by comparing it with other frequentist and Bayesian approaches on a range of datasets and tasks with mixed-type variables.
Pyramid-Focus-Augmentation: Medical Image Segmentation with Step-Wise Focus
Dec 14, 2020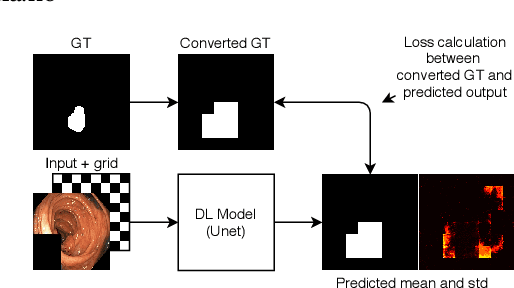
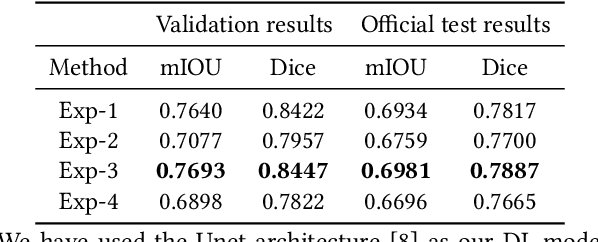

Segmentation of findings in the gastrointestinal tract is a challenging but also an important task which is an important building stone for sufficient automatic decision support systems. In this work, we present our solution for the Medico 2020 task, which focused on the problem of colon polyp segmentation. We present our simple but efficient idea of using an augmentation method that uses grids in a pyramid-like manner (large to small) for segmentation. Our results show that the proposed methods work as indented and can also lead to comparable results when competing with other methods.
Single-shot Compressed 3D Imaging by Exploiting Random Scattering and Astigmatism
May 21, 2021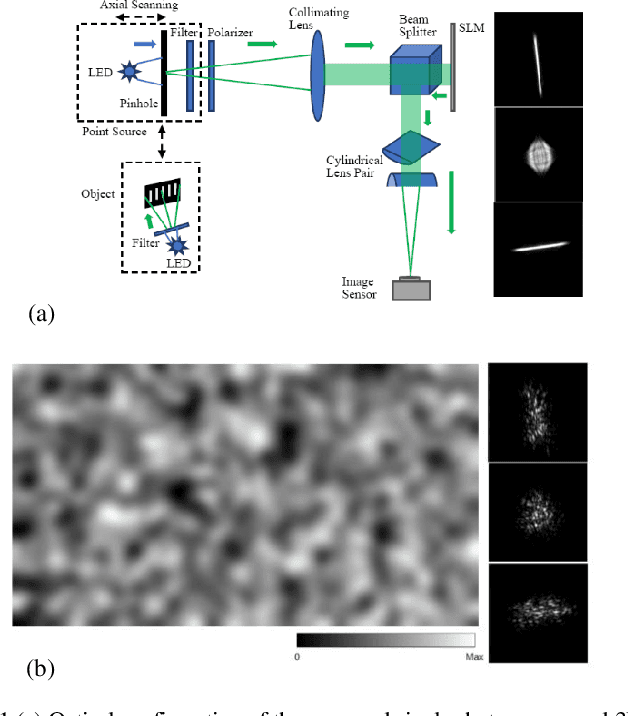
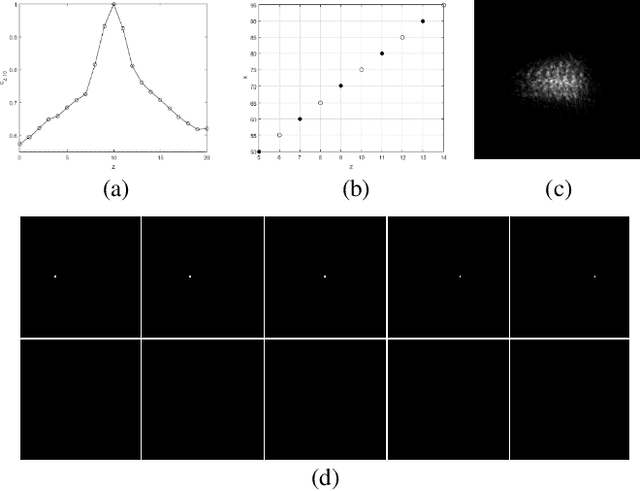

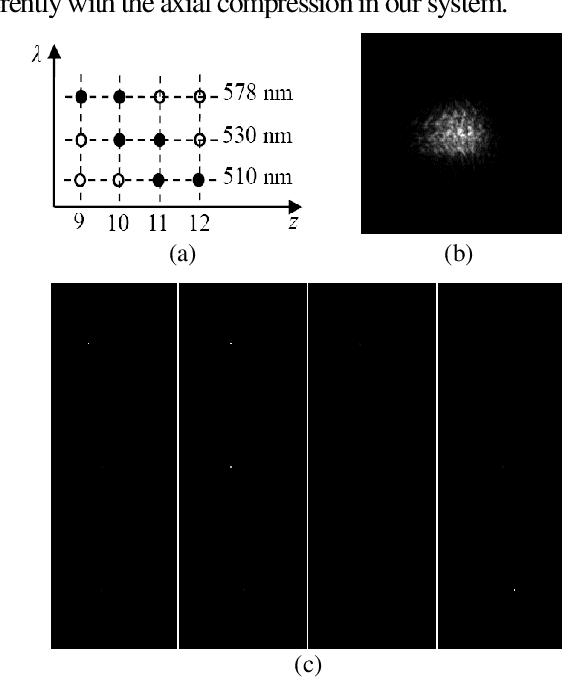
Based on point spread function (PSF) engineering and astigmatism due to a pair of cylindrical lenses, a novel compressed imaging mechanism is proposed to achieve single-shot incoherent 3D imaging. The speckle-like PSF of the imaging system is sensitive to axial shift, which makes it feasible to reconstruct a 3D image by solving an optimization problem with sparsity constraint. With the experimentally calibrated PSFs, the proposed method is demonstrated by a synthetic 3D point object and real 3D object, and the images in different axial slices can be reconstructed faithfully. Moreover, 3D multispectral compressed imaging is explored with the same system, and the result is rather satisfactory with a synthetic point object. Because of the inherent compatibility between the compression in spectral and axial dimensions, the proposed mechanism has the potential to be a unified framework for multi-dimensional compressed imaging.
Synthesizing brain tumor images and annotations by combining progressive growing GAN and SPADE
Sep 13, 2020
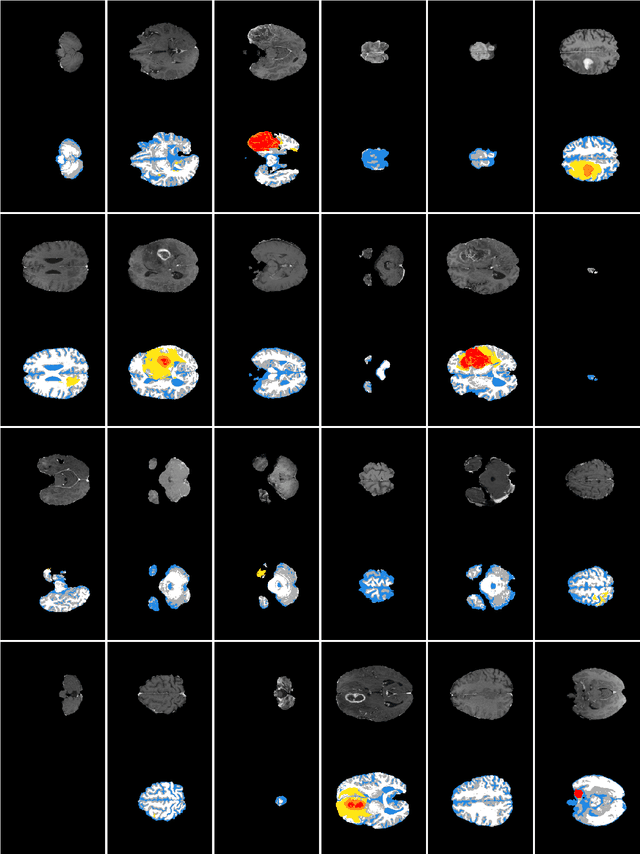

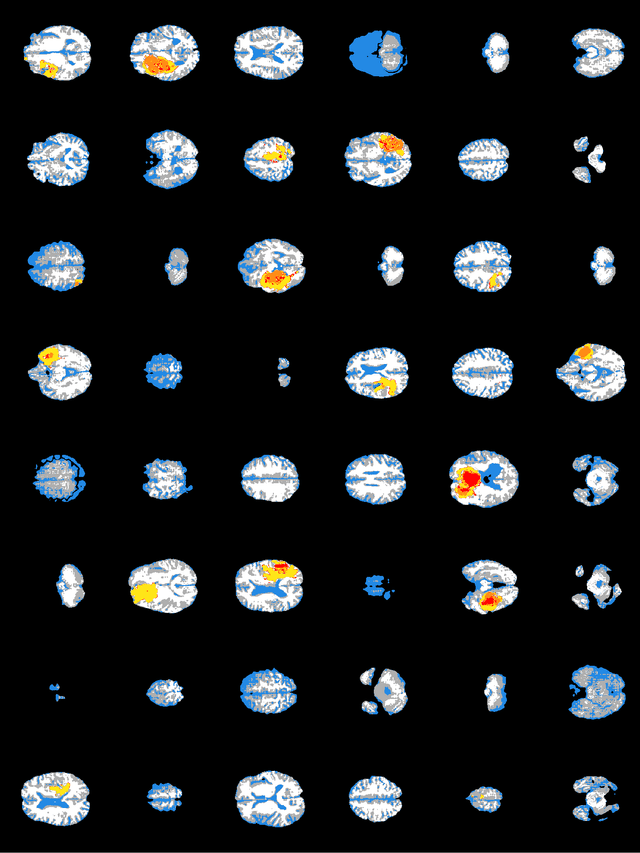
Training segmentation networks requires large annotated datasets, but manual annotation is time consuming and costly. We here investigate if the combination of a noise-to-image GAN and an image-to-image GAN can be used to synthesize realistic brain tumor images as well as the corresponding tumor annotations (labels), to substantially increase the number of training images. The noise-to-image GAN is used to synthesize new label images, while the image-to-image GAN generates the corresponding MR image from the label image. Our results indicate that the two GANs can synthesize label images and MR images that look realistic, and that adding synthetic images improves the segmentation performance, although the effect is small.
ImVoteNet: Boosting 3D Object Detection in Point Clouds with Image Votes
Jan 29, 2020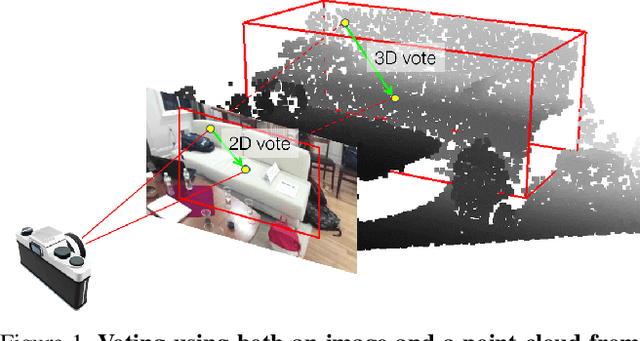
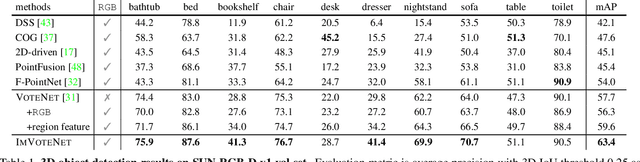
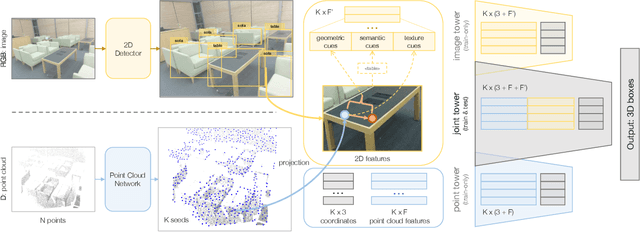
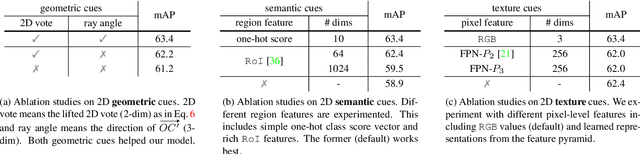
3D object detection has seen quick progress thanks to advances in deep learning on point clouds. A few recent works have even shown state-of-the-art performance with just point clouds input (e.g. VoteNet). However, point cloud data have inherent limitations. They are sparse, lack color information and often suffer from sensor noise. Images, on the other hand, have high resolution and rich texture. Thus they can complement the 3D geometry provided by point clouds. Yet how to effectively use image information to assist point cloud based detection is still an open question. In this work, we build on top of VoteNet and propose a 3D detection architecture called ImVoteNet specialized for RGB-D scenes. ImVoteNet is based on fusing 2D votes in images and 3D votes in point clouds. Compared to prior work on multi-modal detection, we explicitly extract both geometric and semantic features from the 2D images. We leverage camera parameters to lift these features to 3D. To improve the synergy of 2D-3D feature fusion, we also propose a multi-tower training scheme. We validate our model on the challenging SUN RGB-D dataset, advancing state-of-the-art results by 5.7 mAP. We also provide rich ablation studies to analyze the contribution of each design choice.
Know Your Surroundings: Panoramic Multi-Object Tracking by Multimodality Collaboration
May 31, 2021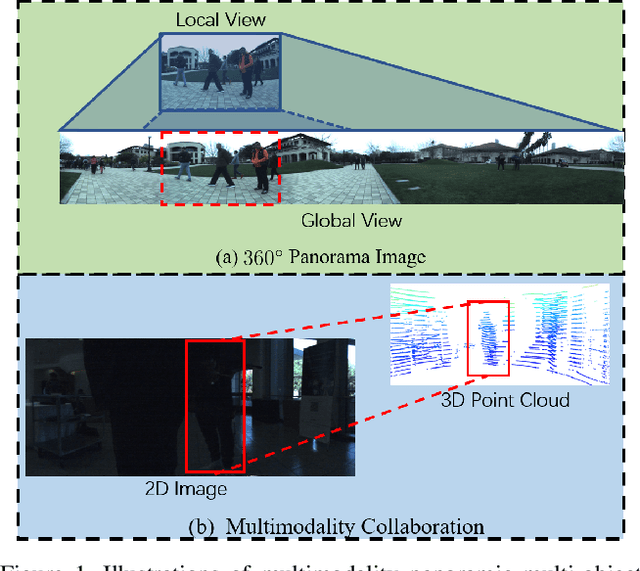
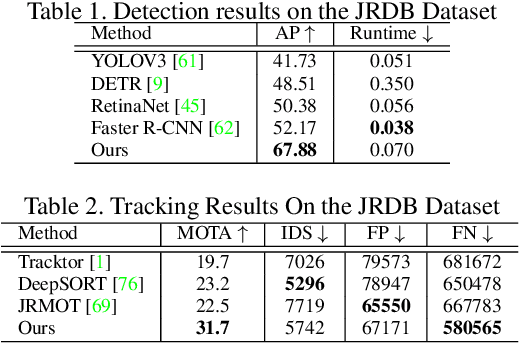


In this paper, we focus on the multi-object tracking (MOT) problem of automatic driving and robot navigation. Most existing MOT methods track multiple objects using a singular RGB camera, which are prone to camera field-of-view and suffer tracking failures in complex scenarios due to background clutters and poor light conditions. To meet these challenges, we propose a MultiModality PAnoramic multi-object Tracking framework (MMPAT), which takes both 2D panorama images and 3D point clouds as input and then infers target trajectories using the multimodality data. The proposed method contains four major modules, a panorama image detection module, a multimodality data fusion module, a data association module and a trajectory inference model. We evaluate the proposed method on the JRDB dataset, where the MMPAT achieves the top performance in both the detection and tracking tasks and significantly outperforms state-of-the-art methods by a large margin (15.7 and 8.5 improvement in terms of AP and MOTA, respectively).
Text-to-image Synthesis via Symmetrical Distillation Networks
Aug 21, 2018
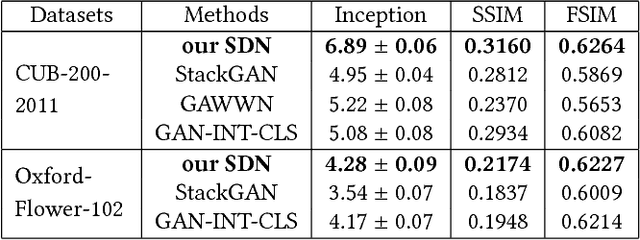
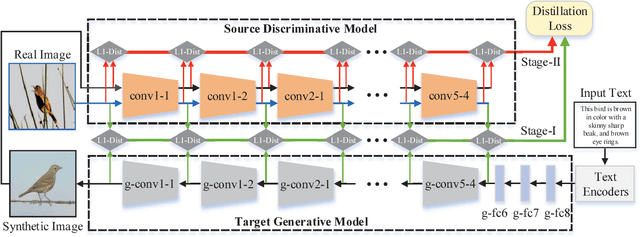
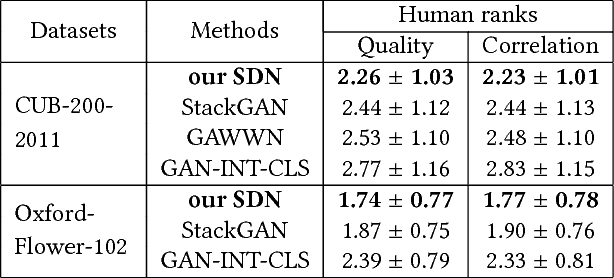
Text-to-image synthesis aims to automatically generate images according to text descriptions given by users, which is a highly challenging task. The main issues of text-to-image synthesis lie in two gaps: the heterogeneous and homogeneous gaps. The heterogeneous gap is between the high-level concepts of text descriptions and the pixel-level contents of images, while the homogeneous gap exists between synthetic image distributions and real image distributions. For addressing these problems, we exploit the excellent capability of generic discriminative models (e.g. VGG19), which can guide the training process of a new generative model on multiple levels to bridge the two gaps. The high-level representations can teach the generative model to extract necessary visual information from text descriptions, which can bridge the heterogeneous gap. The mid-level and low-level representations can lead it to learn structures and details of images respectively, which relieves the homogeneous gap. Therefore, we propose Symmetrical Distillation Networks (SDN) composed of a source discriminative model as "teacher" and a target generative model as "student". The target generative model has a symmetrical structure with the source discriminative model, in order to transfer hierarchical knowledge accessibly. Moreover, we decompose the training process into two stages with different distillation paradigms for promoting the performance of the target generative model. Experiments on two widely-used datasets are conducted to verify the effectiveness of our proposed SDN.
Multi-Agent Image Classification via Reinforcement Learning
May 13, 2019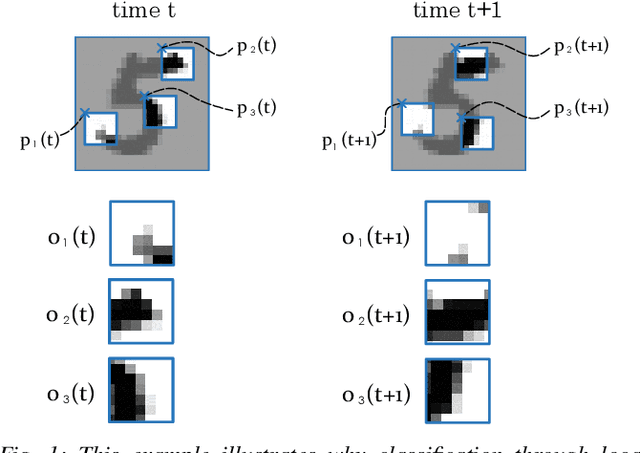
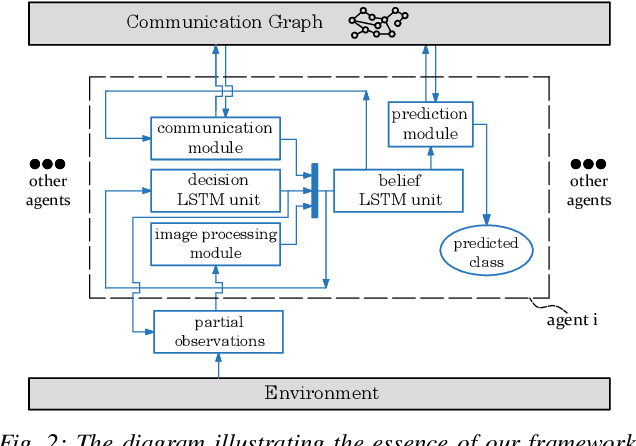
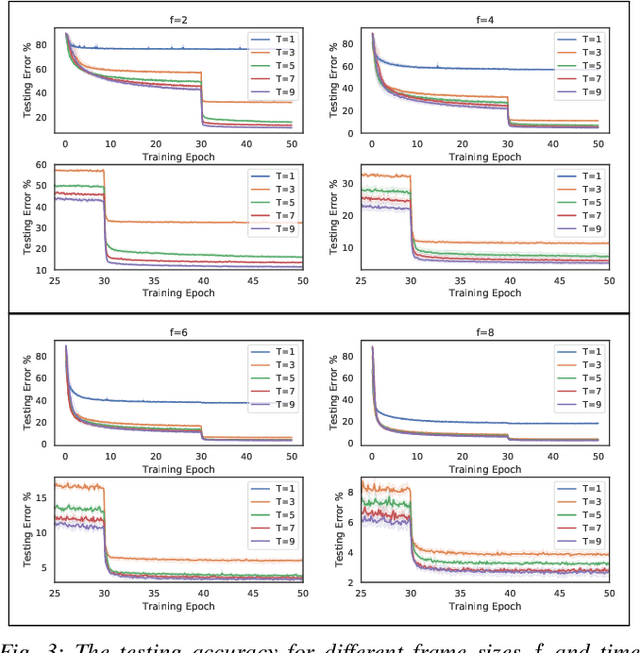
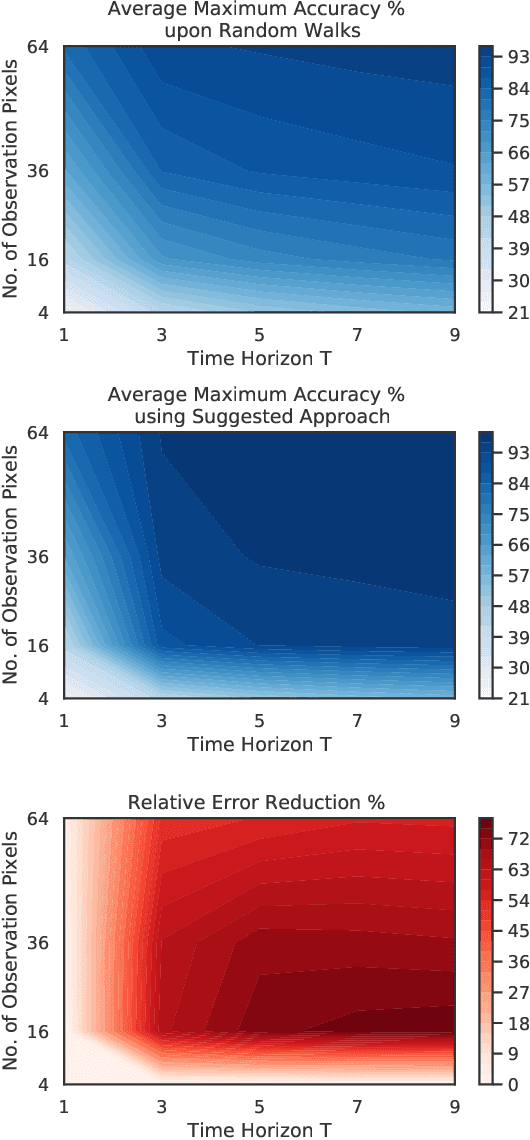
We investigate a classification problem using multiple mobile agents that are capable of collecting (partial) pose-dependent observations of an unknown environment. The objective is to classify an image (e.g, map of a large area) over a finite time horizon. We propose a network architecture on how agents should form a local belief, take local actions, extract relevant features and specification from their raw partial observations. Agents are allowed to exchange information with their neighboring agents and run a decentralized consensus protocol to update their own beliefs. It is shown how reinforcement learning techniques can be utilized to achieve decentralized implementation of the classification problem. Our experimental results on MNIST handwritten digit dataset demonstrates the effectiveness of our proposed framework.
Cross Chest Graph for Disease Diagnosis with Structural Relational Reasoning
Feb 01, 2021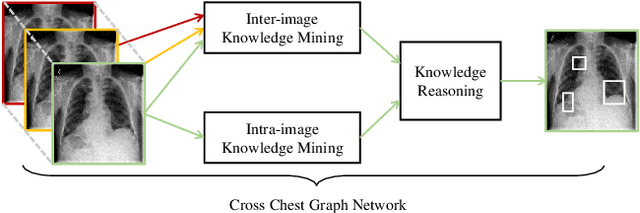
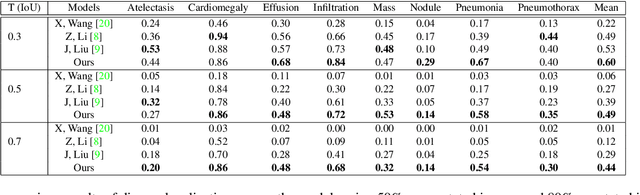
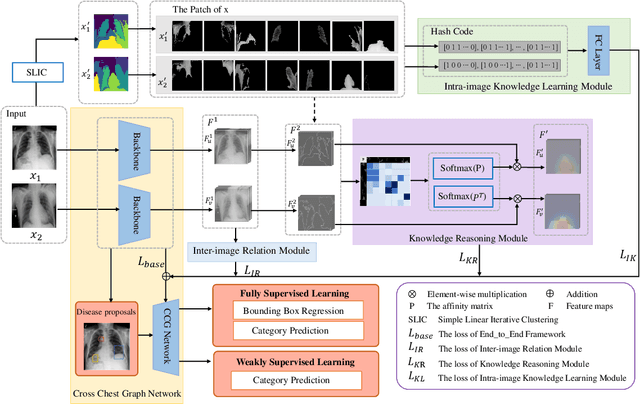
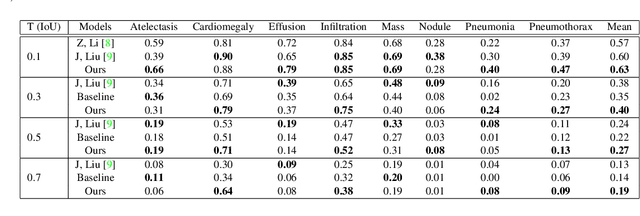
Locating lesions is important in the computer-aided diagnosis of X-ray images. However, box-level annotation is time-consuming and laborious. How to locate lesions accurately with few, or even without careful annotations is an urgent problem. Although several works have approached this problem with weakly-supervised methods, the performance needs to be improved. One obstacle is that general weakly-supervised methods have failed to consider the characteristics of X-ray images, such as the highly-structural attribute. We therefore propose the Cross-chest Graph (CCG), which improves the performance of automatic lesion detection by imitating doctor's training and decision-making process. CCG models the intra-image relationship between different anatomical areas by leveraging the structural information to simulate the doctor's habit of observing different areas. Meanwhile, the relationship between any pair of images is modeled by a knowledge-reasoning module to simulate the doctor's habit of comparing multiple images. We integrate intra-image and inter-image information into a unified end-to-end framework. Experimental results on the NIH Chest-14 database (112,120 frontal-view X-ray images with 14 diseases) demonstrate that the proposed method achieves state-of-the-art performance in weakly-supervised localization of lesions by absorbing professional knowledge in the medical field.