 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
IEGAN: Multi-purpose Perceptual Quality Image Enhancement Using Generative Adversarial Network
Nov 22, 2018

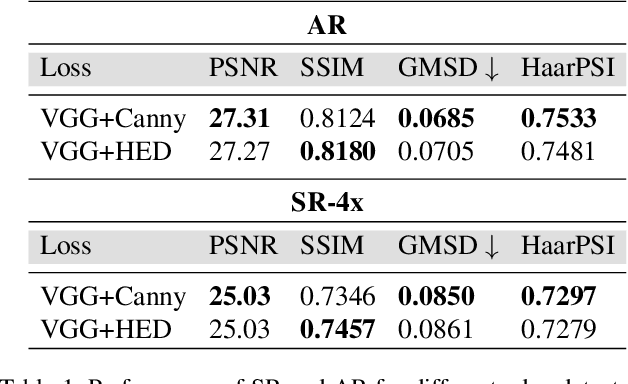
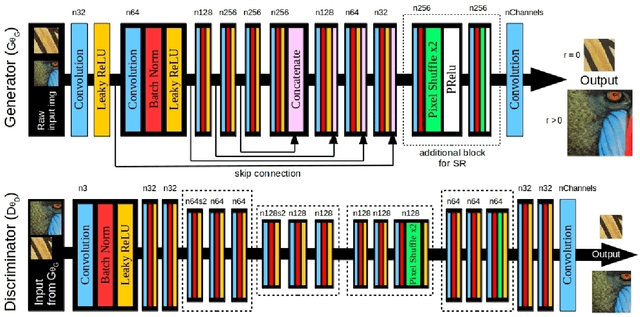
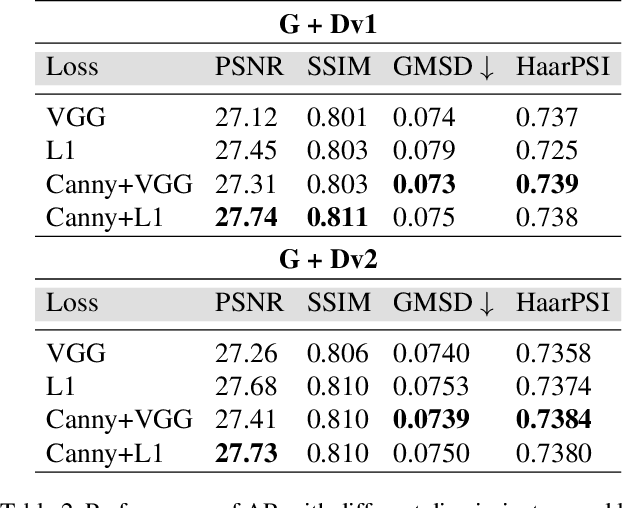
Despite the breakthroughs in quality of image enhancement, an end-to-end solution for simultaneous recovery of the finer texture details and sharpness for degraded images with low resolution is still unsolved. Some existing approaches focus on minimizing the pixel-wise reconstruction error which results in a high peak signal-to-noise ratio. The enhanced images fail to provide high-frequency details and are perceptually unsatisfying, i.e., they fail to match the quality expected in a photo-realistic image. In this paper, we present Image Enhancement Generative Adversarial Network (IEGAN), a versatile framework capable of inferring photo-realistic natural images for both artifact removal and super-resolution simultaneously. Moreover, we propose a new loss function consisting of a combination of reconstruction loss, feature loss and an edge loss counterpart. The feature loss helps to push the output image to the natural image manifold and the edge loss preserves the sharpness of the output image. The reconstruction loss provides low-level semantic information to the generator regarding the quality of the generated images compared to the original. Our approach has been experimentally proven to recover photo-realistic textures from heavily compressed low-resolution images on public benchmarks and our proposed high-resolution World100 dataset.
Deep Neural Networks are Surprisingly Reversible: A Baseline for Zero-Shot Inversion
Jul 13, 2021



Understanding the behavior and vulnerability of pre-trained deep neural networks (DNNs) can help to improve them. Analysis can be performed via reversing the network's flow to generate inputs from internal representations. Most existing work relies on priors or data-intensive optimization to invert a model, yet struggles to scale to deep architectures and complex datasets. This paper presents a zero-shot direct model inversion framework that recovers the input to the trained model given only the internal representation. The crux of our method is to inverse the DNN in a divide-and-conquer manner while re-syncing the inverted layers via cycle-consistency guidance with the help of synthesized data. As a result, we obtain a single feed-forward model capable of inversion with a single forward pass without seeing any real data of the original task. With the proposed approach, we scale zero-shot direct inversion to deep architectures and complex datasets. We empirically show that modern classification models on ImageNet can, surprisingly, be inverted, allowing an approximate recovery of the original 224x224px images from a representation after more than 20 layers. Moreover, inversion of generators in GANs unveils latent code of a given synthesized face image at 128x128px, which can even, in turn, improve defective synthesized images from GANs.
Self-supervised Body Image Acquisition Using a Deep Neural Network for Sensorimotor Prediction
Jun 03, 2019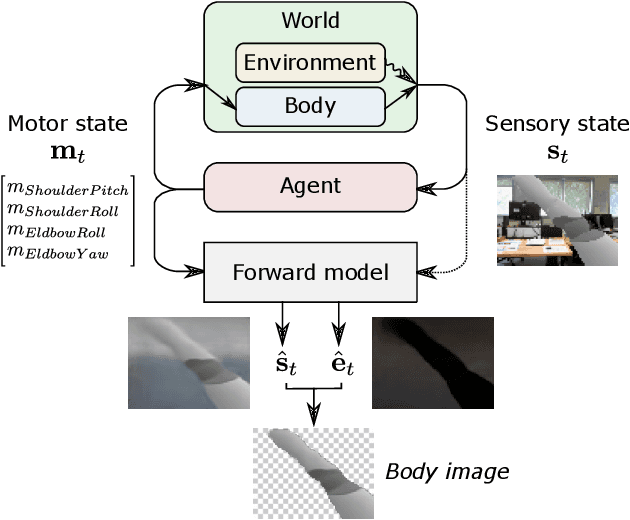
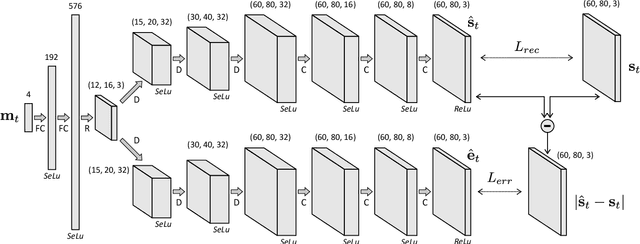


This work investigates how a naive agent can acquire its own body image in a self-supervised way, based on the predictability of its sensorimotor experience. Our working hypothesis is that, due to its temporal stability, an agent's body produces more consistent sensory experiences than the environment, which exhibits a greater variability. Given its motor experience, an agent can thus reliably predict what appearance its body should have. This intrinsic predictability can be used to automatically isolate the body image from the rest of the environment. We propose a two-branches deconvolutional neural network to predict the visual sensory state associated with an input motor state, as well as the prediction error associated with this input. We train the network on a dataset of first-person images collected with a simulated Pepper robot, and show how the network outputs can be used to automatically isolate its visible arm from the rest of the environment. Finally, the quality of the body image produced by the network is evaluated.
Multi-Modal Multi-Scale Deep Learning for Large-Scale Image Annotation
Oct 19, 2018
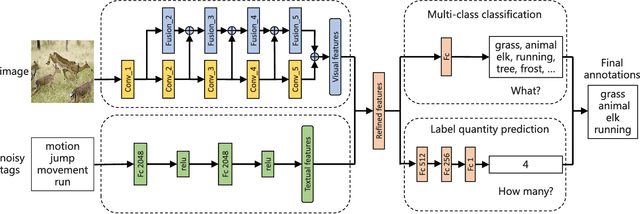
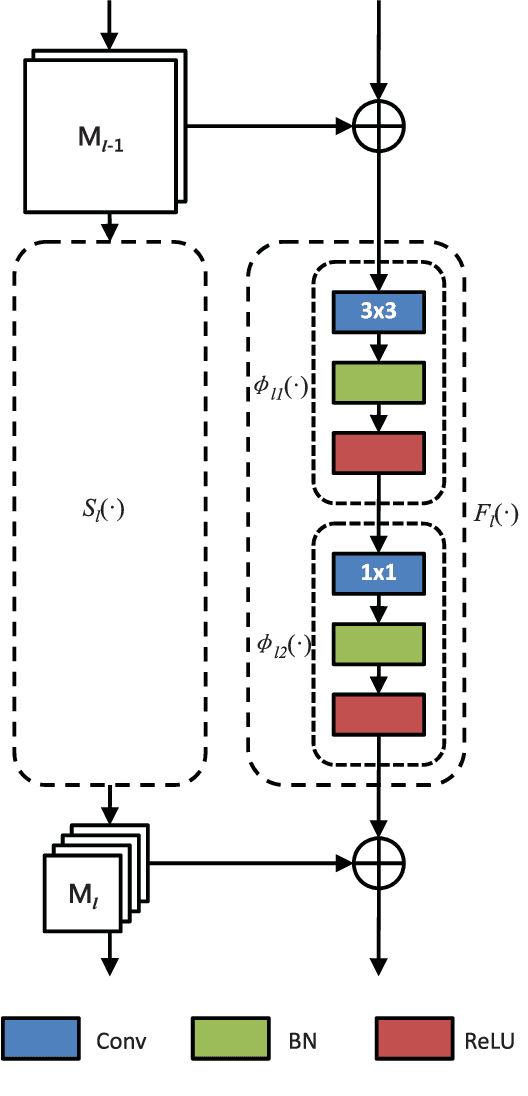
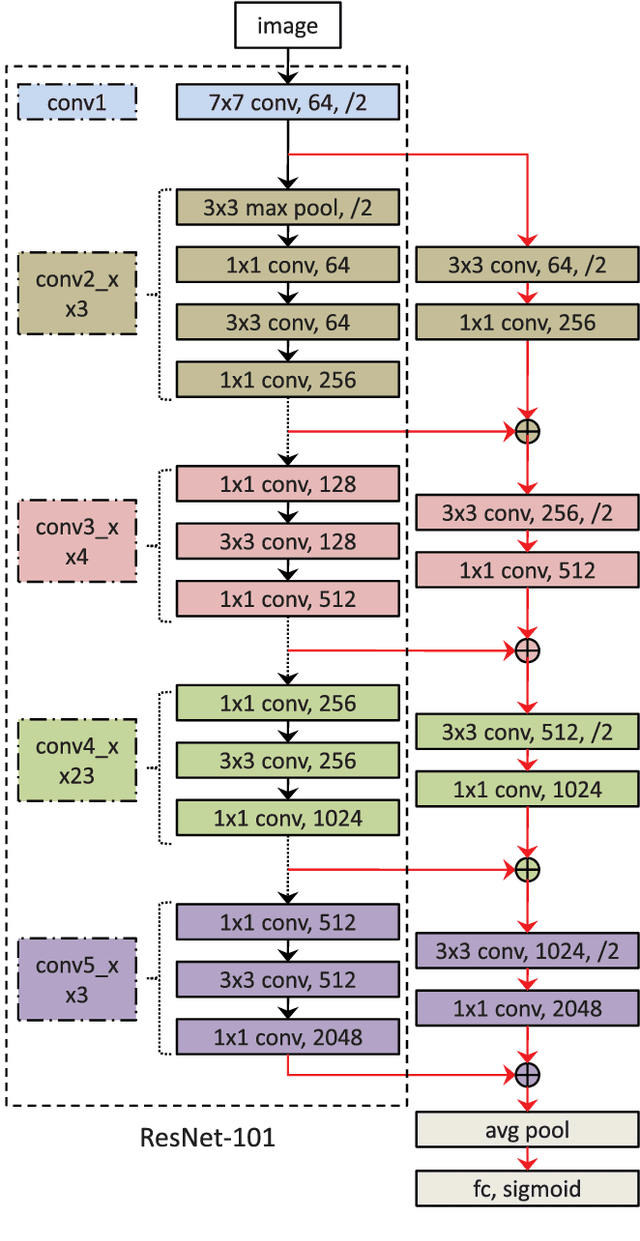
Image annotation aims to annotate a given image with a variable number of class labels corresponding to diverse visual concepts. In this paper, we address two main issues in large-scale image annotation: 1) how to learn a rich feature representation suitable for predicting a diverse set of visual concepts ranging from object, scene to abstract concept; 2) how to annotate an image with the optimal number of class labels. To address the first issue, we propose a novel multi-scale deep model for extracting rich and discriminative features capable of representing a wide range of visual concepts. Specifically, a novel two-branch deep neural network architecture is proposed which comprises a very deep main network branch and a companion feature fusion network branch designed for fusing the multi-scale features computed from the main branch. The deep model is also made multi-modal by taking noisy user-provided tags as model input to complement the image input. For tackling the second issue, we introduce a label quantity prediction auxiliary task to the main label prediction task to explicitly estimate the optimal label number for a given image. Extensive experiments are carried out on two large-scale image annotation benchmark datasets and the results show that our method significantly outperforms the state-of-the-art.
What classifiers know what they don't?
Jul 13, 2021
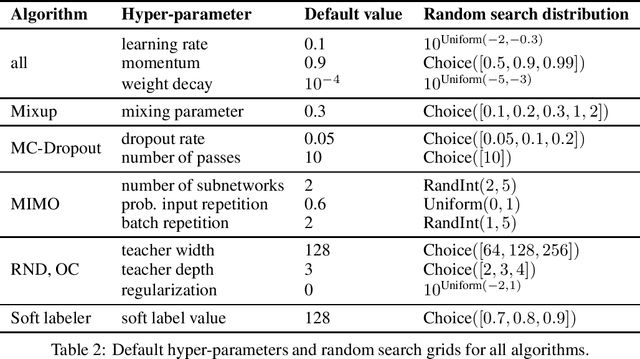
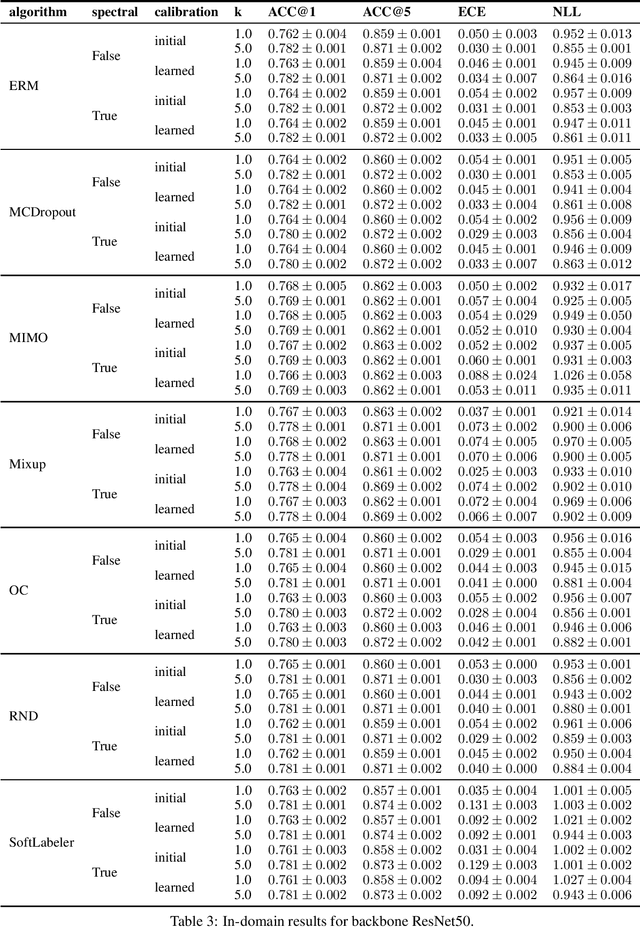
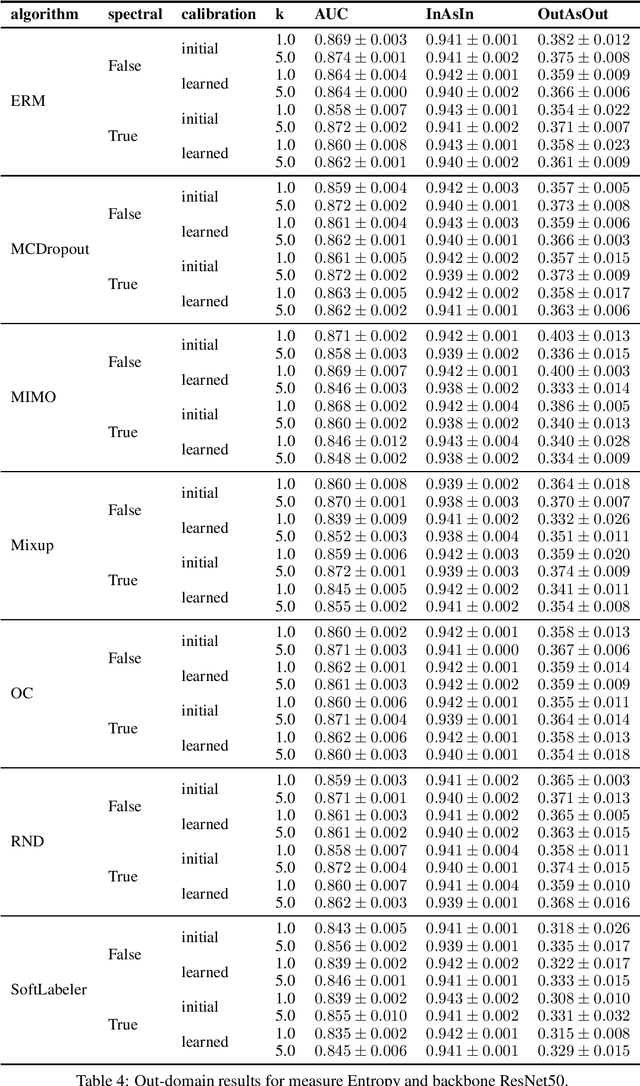
Being uncertain when facing the unknown is key to intelligent decision making. However, machine learning algorithms lack reliable estimates about their predictive uncertainty. This leads to wrong and overly-confident decisions when encountering classes unseen during training. Despite the importance of equipping classifiers with uncertainty estimates ready for the real world, prior work has focused on small datasets and little or no class discrepancy between training and testing data. To close this gap, we introduce UIMNET: a realistic, ImageNet-scale test-bed to evaluate predictive uncertainty estimates for deep image classifiers. Our benchmark provides implementations of eight state-of-the-art algorithms, six uncertainty measures, four in-domain metrics, three out-domain metrics, and a fully automated pipeline to train, calibrate, ensemble, select, and evaluate models. Our test-bed is open-source and all of our results are reproducible from a fixed commit in our repository. Adding new datasets, algorithms, measures, or metrics is a matter of a few lines of code-in so hoping that UIMNET becomes a stepping stone towards realistic, rigorous, and reproducible research in uncertainty estimation. Our results show that ensembles of ERM classifiers as well as single MIMO classifiers are the two best alternatives currently available to measure uncertainty about both in-domain and out-domain classes.
'CADSketchNet' -- An Annotated Sketch dataset for 3D CAD Model Retrieval with Deep Neural Networks
Jul 13, 2021
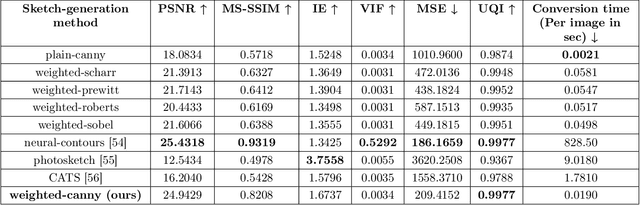
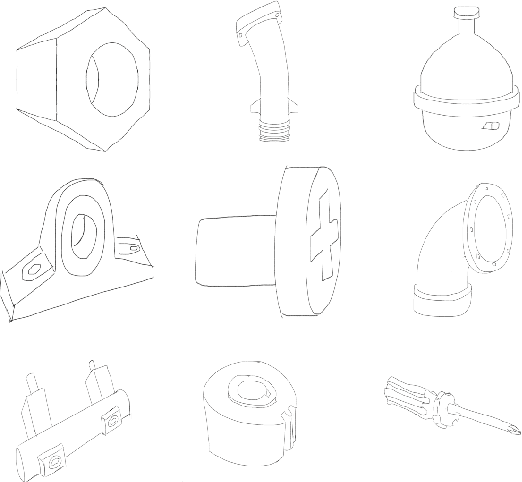

Ongoing advancements in the fields of 3D modelling and digital archiving have led to an outburst in the amount of data stored digitally. Consequently, several retrieval systems have been developed depending on the type of data stored in these databases. However, unlike text data or images, performing a search for 3D models is non-trivial. Among 3D models, retrieving 3D Engineering/CAD models or mechanical components is even more challenging due to the presence of holes, volumetric features, presence of sharp edges etc., which make CAD a domain unto itself. The research work presented in this paper aims at developing a dataset suitable for building a retrieval system for 3D CAD models based on deep learning. 3D CAD models from the available CAD databases are collected, and a dataset of computer-generated sketch data, termed 'CADSketchNet', has been prepared. Additionally, hand-drawn sketches of the components are also added to CADSketchNet. Using the sketch images from this dataset, the paper also aims at evaluating the performance of various retrieval system or a search engine for 3D CAD models that accepts a sketch image as the input query. Many experimental models are constructed and tested on CADSketchNet. These experiments, along with the model architecture, choice of similarity metrics are reported along with the search results.
An Implementation of Vector Quantization using the Genetic Algorithm Approach
Feb 16, 2021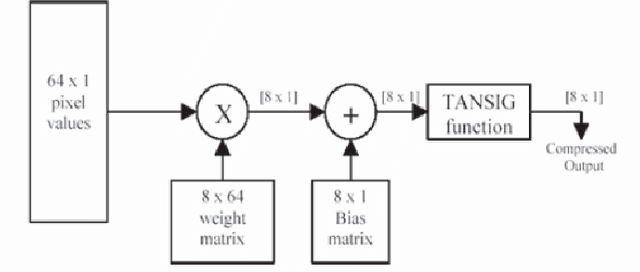
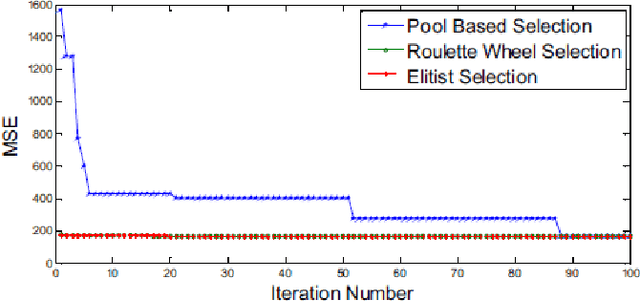


The application of machine learning(ML) and genetic programming(GP) to the image compression domain has produced promising results in many cases. The need for compression arises due to the exorbitant size of data shared on the internet. Compression is required for text, videos, or images, which are used almost everywhere on web be it news articles, social media posts, blogs, educational platforms, medical domain, government services, and many other websites, need packets for transmission and hence compression is necessary to avoid overwhelming the network. This paper discusses some of the implementations of image compression algorithms that use techniques such as Artificial Neural Networks, Residual Learning, Fuzzy Neural Networks, Convolutional Neural Nets, Deep Learning, Genetic Algorithms. The paper also describes an implementation of Vector Quantization using GA to generate codebook which is used for Lossy image compression. All these approaches prove to be very contrasting to the standard approaches to processing images due to the highly parallel and computationally extensive nature of machine learning algorithms. Such non-linear abilities of ML and GP make it widely popular for use in multiple domains. Traditional approaches are also combined with artificially intelligent systems, leading to hybrid systems, to achieve better results.
Deep learning based low-dose synchrotron radiation CT reconstruction
Jun 09, 2021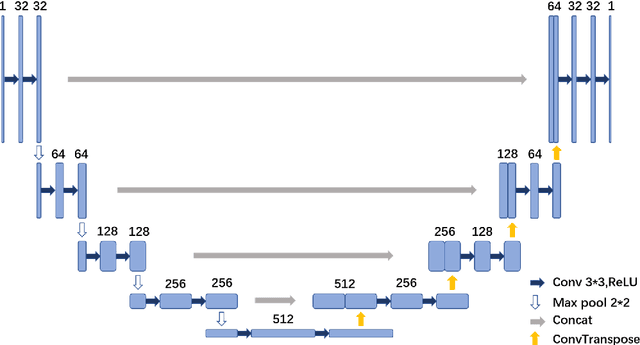
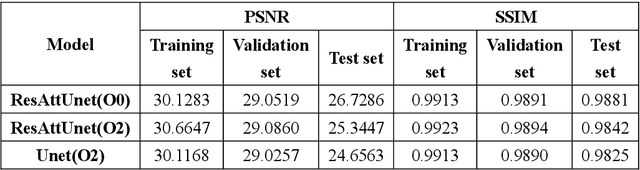
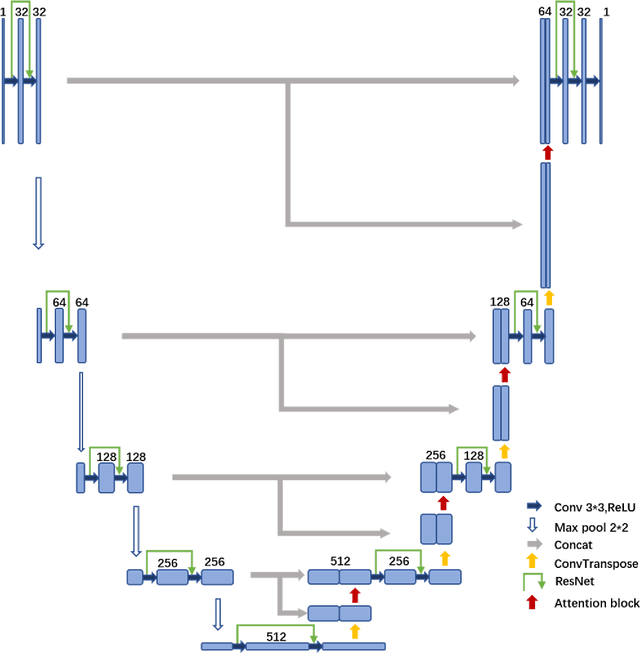
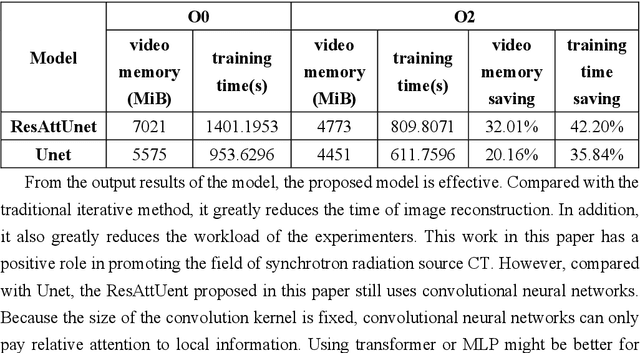
Synchrotron radiation sources are widely used in various fields, among which computed tomography (CT) is one of the most important. The amount of effort expended by the operator varies depending on the subject. If the number of angles needed to be used can be greatly reduced under the condition of similar imaging effects, the working time and workload of the experimentalists will be greatly reduced. However, decreasing the sampling angle can produce serious artifacts and blur the details. We try to use a deep learning model which can build high quality reconstruction sparse data sampling from the angle of the image and ResAttUnet are put forward. ResAttUnet is roughly a symmetrical U-shaped network that incorporates similar mechanisms to ResNet and attention. In addition, the mixed precision is adopted to reduce the demand for video memory of the model and training time.
SpectGRASP: Robotic Grasping by Spectral Correlation
Jul 26, 2021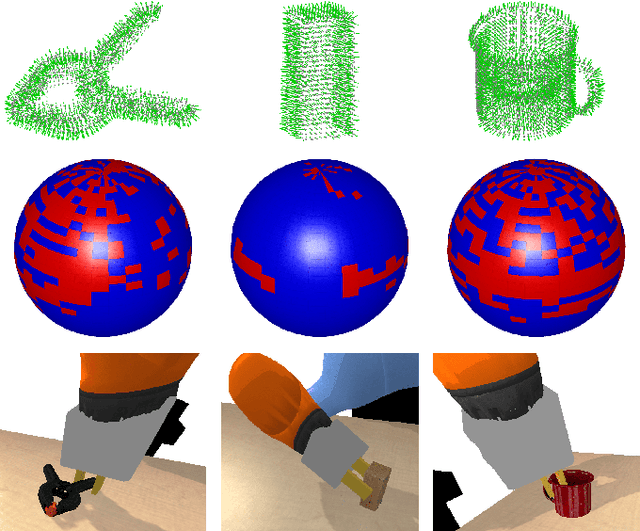
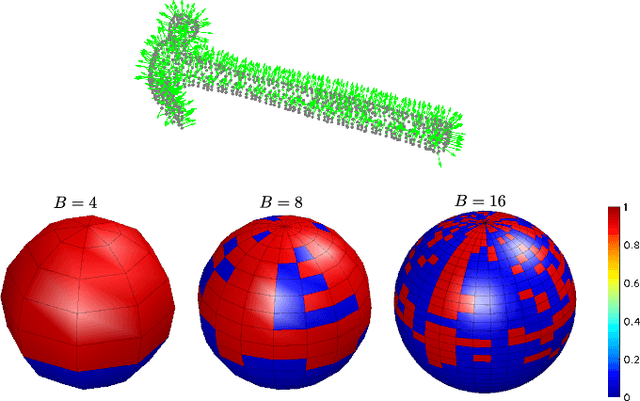
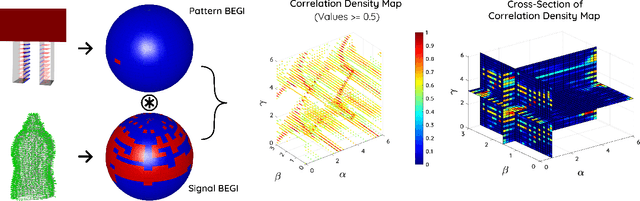

This paper presents a spectral correlation-based method (SpectGRASP) for robotic grasping of arbitrarily shaped, unknown objects. Given a point cloud of an object, SpectGRASP extracts contact points on the object's surface matching the hand configuration. It neither requires offline training nor a-priori object models. We propose a novel Binary Extended Gaussian Image (BEGI), which represents the point cloud surface normals of both object and robot fingers as signals on a 2-sphere. Spherical harmonics are then used to estimate the correlation between fingers and object BEGIs. The resulting spectral correlation density function provides a similarity measure of gripper and object surface normals. This is highly efficient in that it is simultaneously evaluated at all possible finger rotations in SO(3). A set of contact points are then extracted for each finger using rotations with high correlation values. We then use our previous work, Local Contact Moment (LoCoMo) similarity metric, to sequentially rank the generated grasps such that the one with maximum likelihood is executed. We evaluate the performance of SpectGRASP by conducting experiments with a 7-axis robot fitted with a parallel-jaw gripper, in a physics simulation environment. Obtained results indicate that the method not only can grasp individual objects, but also can successfully clear randomly organized groups of objects. The SpectGRASP method also outperforms the closest state-of-the-art method in terms of grasp generation time and grasp-efficiency.
eGAN: Unsupervised approach to class imbalance using transfer learning
Apr 09, 2021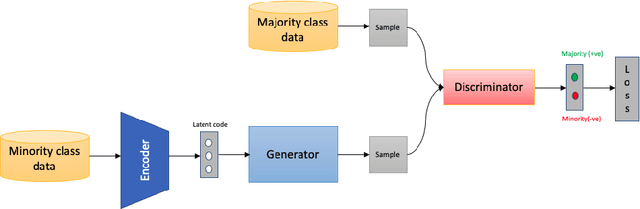


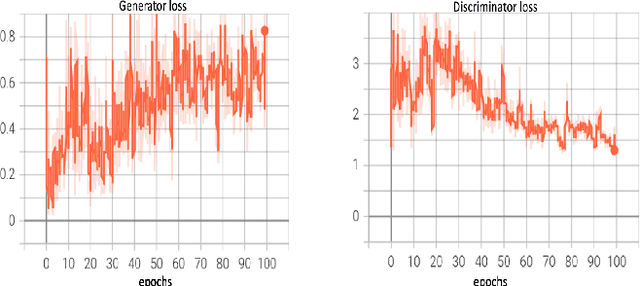
Class imbalance is an inherent problem in many machine learning classification tasks. This often leads to trained models that are unusable for any practical purpose. In this study we explore an unsupervised approach to address these imbalances by leveraging transfer learning from pre-trained image classification models to encoder-based Generative Adversarial Network (eGAN). To the best of our knowledge, this is the first work to tackle this problem using GAN without needing to augment with synthesized fake images. In the proposed approach we use the discriminator network to output a negative or positive score. We classify as minority, test samples with negative scores and as majority those with positive scores. Our approach eliminates epistemic uncertainty in model predictions, as the P(minority) + P(majority) need not sum up to 1. The impact of transfer learning and combinations of different pre-trained image classification models at the generator and discriminator is also explored. Best result of 0.69 F1-score was obtained on CIFAR-10 classification task with imbalance ratio of 1:2500. Our approach also provides a mechanism of thresholding the specificity or sensitivity of our machine learning system. Keywords: Class imbalance, Transfer Learning, GAN, nash equilibrium