 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Disentangling Latent Hands for Image Synthesis and Pose Estimation
Dec 03, 2018
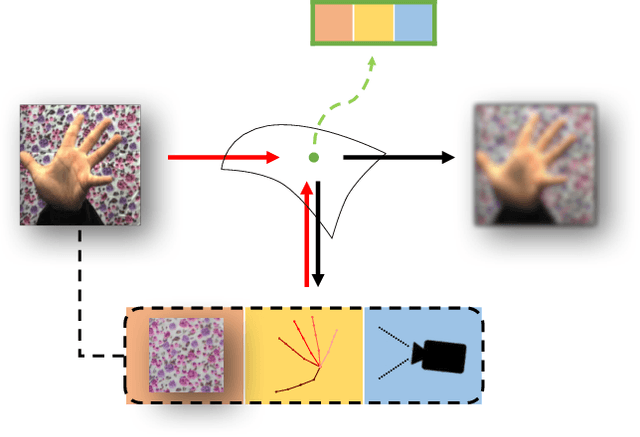
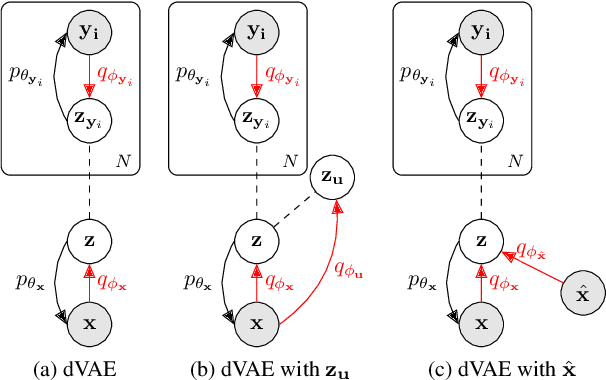
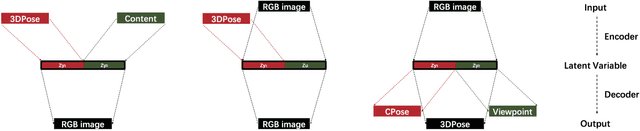

Hand image synthesis and pose estimation from RGB images are both highly challenging tasks due to the large discrepancy between factors of variation ranging from image background content to camera viewpoint. To better analyze these factors of variation, we propose the use of disentangled representations and propose a disentangled variational autoencoder (dVAE) that allows for specific sampling and inference of these factors. The derived objective from the variational lower bound as well as the proposed training strategy are highly flexible, allowing us to handle cross-modal encoders and decoders as well as semi-supervised learning scenarios. Experiments show that our dVAE can synthesize highly realistic images of the hand specifiable by both pose and image background content and also estimate 3D hand poses from RGB images with accuracy competitive with state-of-the-art on two public benchmarks.
End-to-End Trainable Multi-Instance Pose Estimation with Transformers
Mar 22, 2021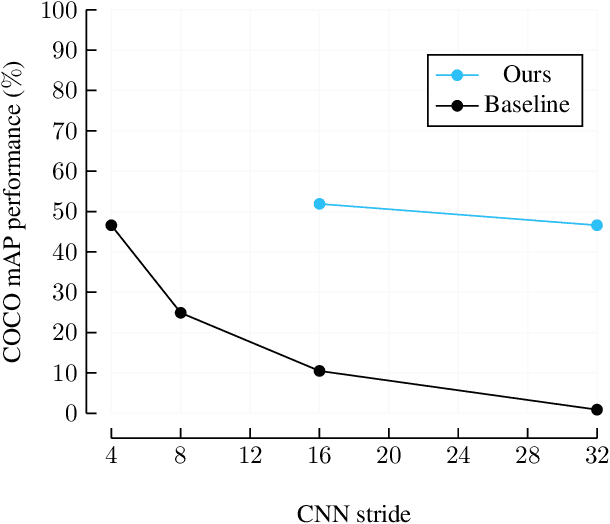
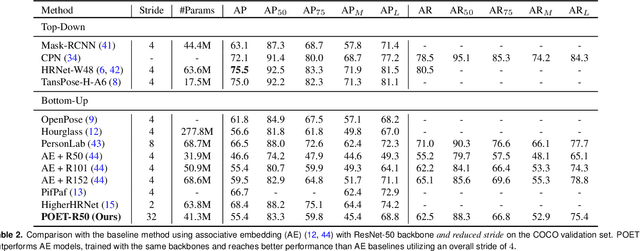
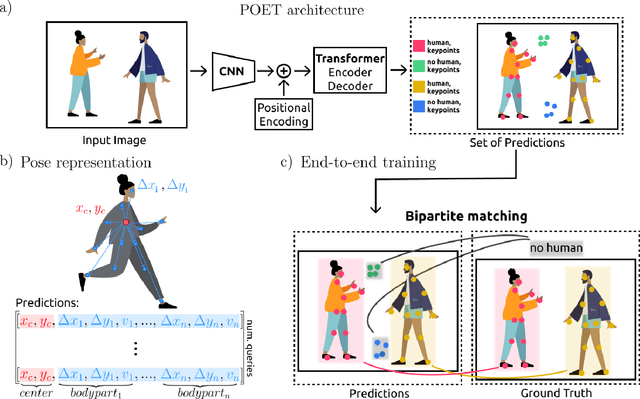

We propose a new end-to-end trainable approach for multi-instance pose estimation by combining a convolutional neural network with a transformer. We cast multi-instance pose estimation from images as a direct set prediction problem. Inspired by recent work on end-to-end trainable object detection with transformers, we use a transformer encoder-decoder architecture together with a bipartite matching scheme to directly regress the pose of all individuals in a given image. Our model, called POse Estimation Transformer (POET), is trained using a novel set-based global loss that consists of a keypoint loss, a keypoint visibility loss, a center loss and a class loss. POET reasons about the relations between detected humans and the full image context to directly predict the poses in parallel. We show that POET can achieve high accuracy on the challenging COCO keypoint detection task. To the best of our knowledge, this model is the first end-to-end trainable multi-instance human pose estimation method.
Parallel Medical Imaging: A New Data-Knowledge-Driven Evolutionary Framework for Medical Image Analysis
Mar 12, 2019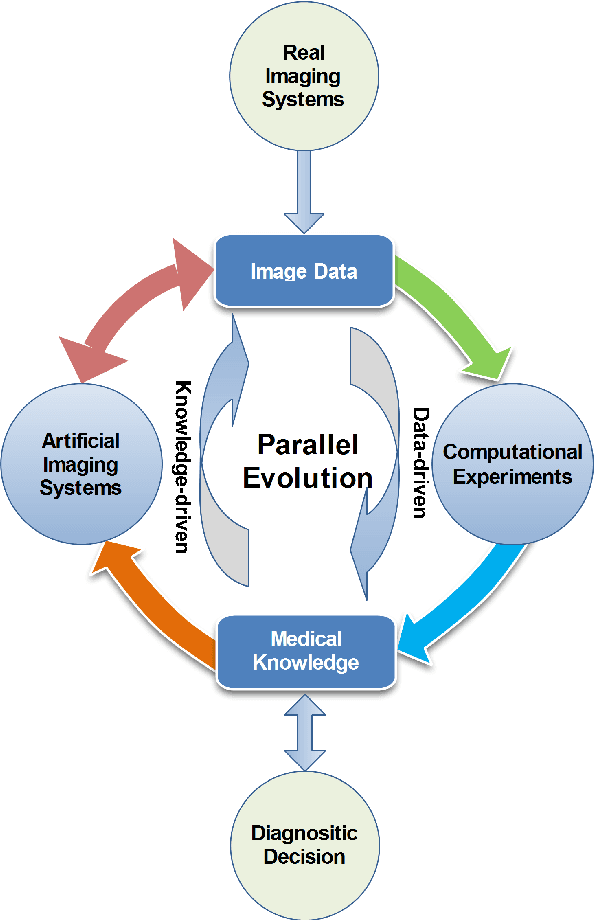
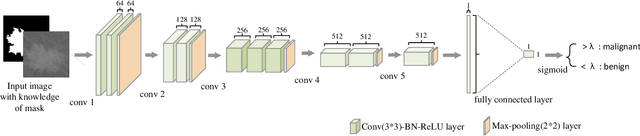
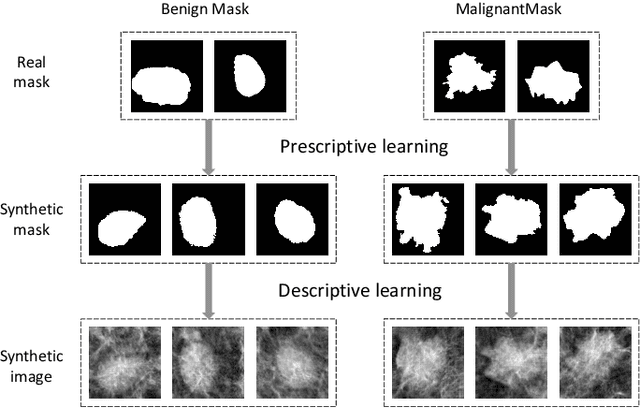
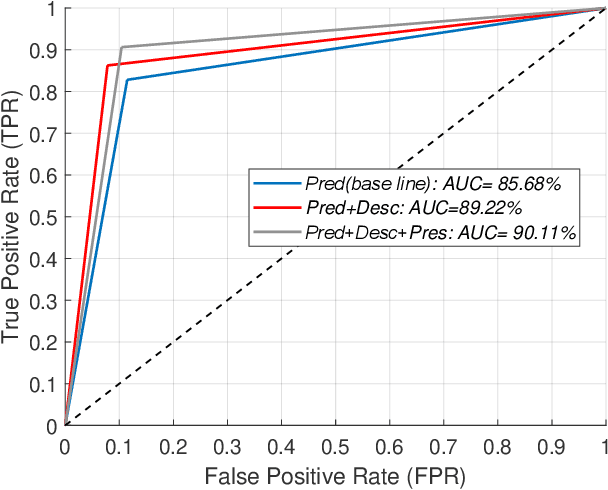
There has been much progress in data-driven artificial intelligence technology for medical image analysis in last decades. However, it still remains a challenge due to its distinctive complexity of acquiring and annotating image data, extracting medical domain knowledge, and explaining the diagnostic decision for medical image analysis. In this paper, we propose a data-knowledge-driven evolutionary framework termed as Parallel Medical Imaging (PMI) for medical image analysis based on the methodology of interactive ACP-based parallel intelligence. In the PMI framework, computational experiments with predictive learning in a data-driven way are conducted to extract medical knowledge for diagnostic decision support. Artificial imaging systems are introduced to select and prescriptively generate medical image data in a knowledge-driven way to utilize medical domain knowledge. Through the parallel evolutionary optimization, our proposed PMI framework can boost the generalization ability and alleviate the limitation of medical interpretation for diagnostic decision. A GANs-based PMI framework for case studies of mammogram analysis is demonstrated in this work.
Punny Captions: Witty Wordplay in Image Descriptions
May 31, 2018
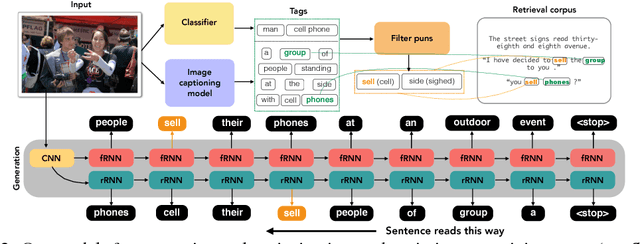
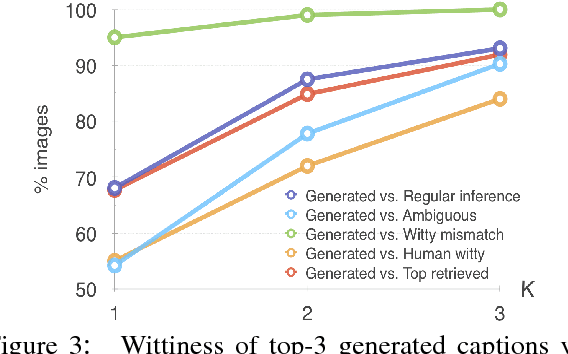

Wit is a form of rich interaction that is often grounded in a specific situation (e.g., a comment in response to an event). In this work, we attempt to build computational models that can produce witty descriptions for a given image. Inspired by a cognitive account of humor appreciation, we employ linguistic wordplay, specifically puns, in image descriptions. We develop two approaches which involve retrieving witty descriptions for a given image from a large corpus of sentences, or generating them via an encoder-decoder neural network architecture. We compare our approach against meaningful baseline approaches via human studies and show substantial improvements. We find that when a human is subject to similar constraints as the model regarding word usage and style, people vote the image descriptions generated by our model to be slightly wittier than human-written witty descriptions. Unsurprisingly, humans are almost always wittier than the model when they are free to choose the vocabulary, style, etc.
Hierarchical Random Walker Segmentation for Large Volumetric Biomedical Data
Mar 17, 2021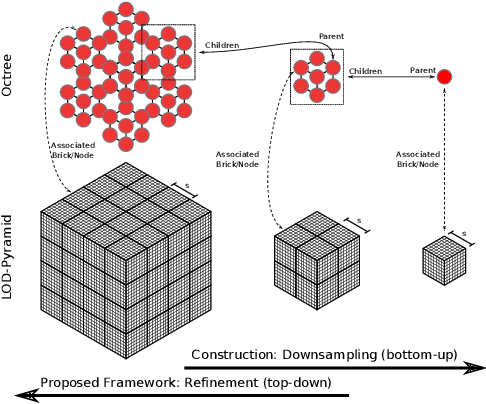
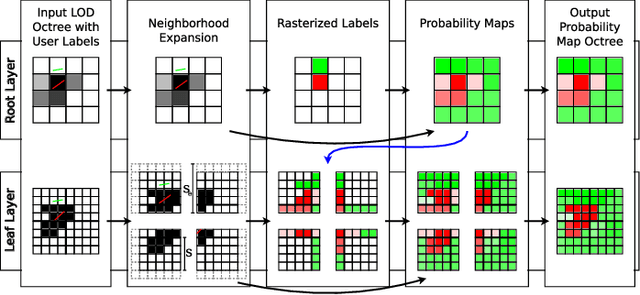
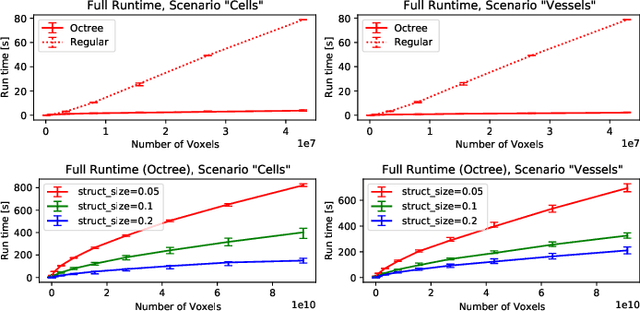
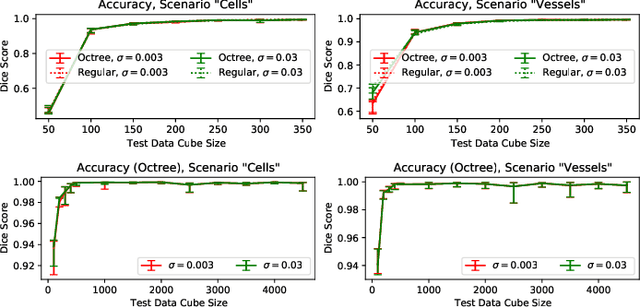
The random walker method for image segmentation is a popular tool for semi-automatic image segmentation, especially in the biomedical field. However, its linear asymptotic run time and memory requirements make application to 3D datasets of increasing sizes impractical. We propose a hierarchical framework that, to the best of our knowledge, is the first attempt to overcome these restrictions for the random walker algorithm and achieves sublinear run time and constant memory complexity. The method is evaluated on synthetic data and real data from current biomedical research, where high segmentation quality is quantitatively confirmed and visually observed, respectively. The incremental (i.e., interaction update) run time is demonstrated to be in seconds on a standard PC even for volumes of hundreds of Gigabytes in size. An implementation of the presented method is publicly available in version 5.2 of the widely used volume rendering and processing software Voreen (https://www.uni-muenster.de/Voreen/).
Poly-NL: Linear Complexity Non-local Layers with Polynomials
Jul 06, 2021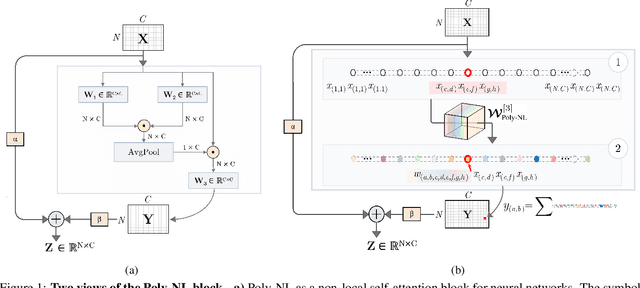
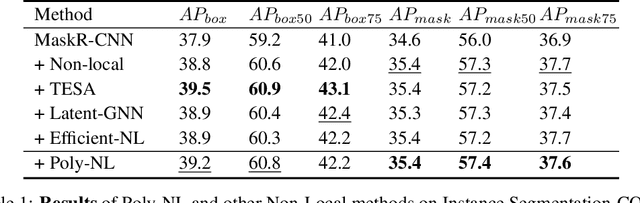
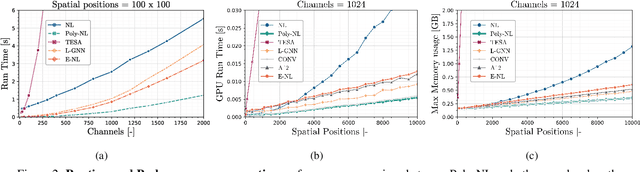
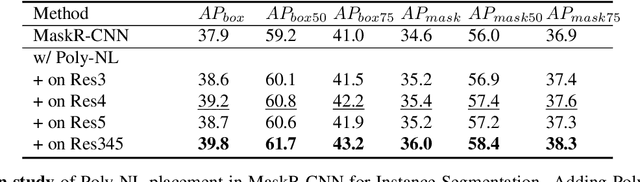
Spatial self-attention layers, in the form of Non-Local blocks, introduce long-range dependencies in Convolutional Neural Networks by computing pairwise similarities among all possible positions. Such pairwise functions underpin the effectiveness of non-local layers, but also determine a complexity that scales quadratically with respect to the input size both in space and time. This is a severely limiting factor that practically hinders the applicability of non-local blocks to even moderately sized inputs. Previous works focused on reducing the complexity by modifying the underlying matrix operations, however in this work we aim to retain full expressiveness of non-local layers while keeping complexity linear. We overcome the efficiency limitation of non-local blocks by framing them as special cases of 3rd order polynomial functions. This fact enables us to formulate novel fast Non-Local blocks, capable of reducing the complexity from quadratic to linear with no loss in performance, by replacing any direct computation of pairwise similarities with element-wise multiplications. The proposed method, which we dub as "Poly-NL", is competitive with state-of-the-art performance across image recognition, instance segmentation, and face detection tasks, while having considerably less computational overhead.
Calibrated and Partially Calibrated Semi-Generalized Homographies
Mar 17, 2021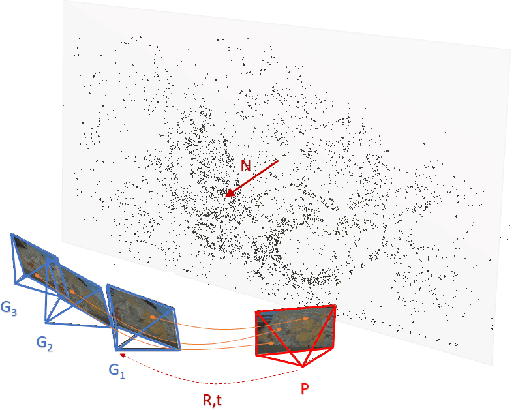
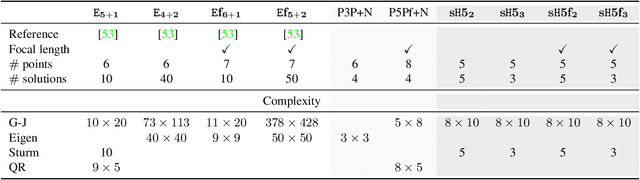
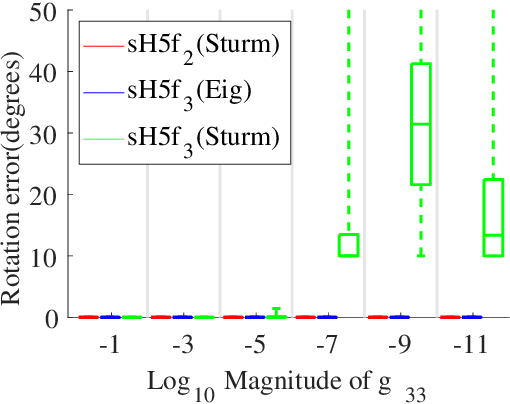
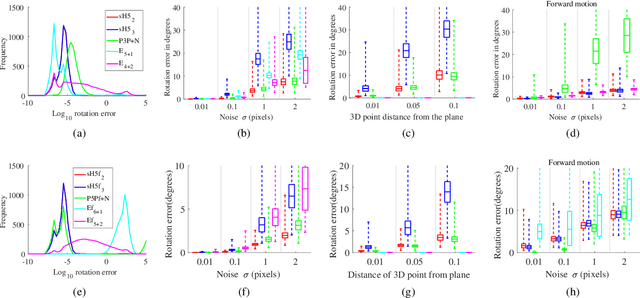
In this paper, we propose the first minimal solutions for estimating the semi-generalized homography given a perspective and a generalized camera. The proposed solvers use five 2D-2D image point correspondences induced by a scene plane. One of them assumes the perspective camera to be fully calibrated, while the other solver estimates the unknown focal length together with the absolute pose parameters. This setup is particularly important in structure-from-motion and image-based localization pipelines, where a new camera is localized in each step with respect to a set of known cameras and 2D-3D correspondences might not be available. As a consequence of a clever parametrization and the elimination ideal method, our approach only needs to solve a univariate polynomial of degree five or three. The proposed solvers are stable and efficient as demonstrated by a number of synthetic and real-world experiments.
ICodeNet -- A Hierarchical Neural Network Approach for Source Code Author Identification
Jan 30, 2021
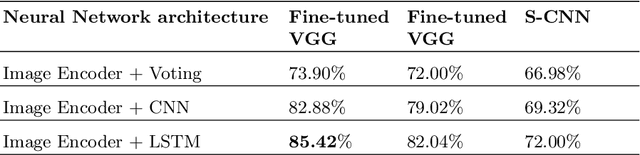
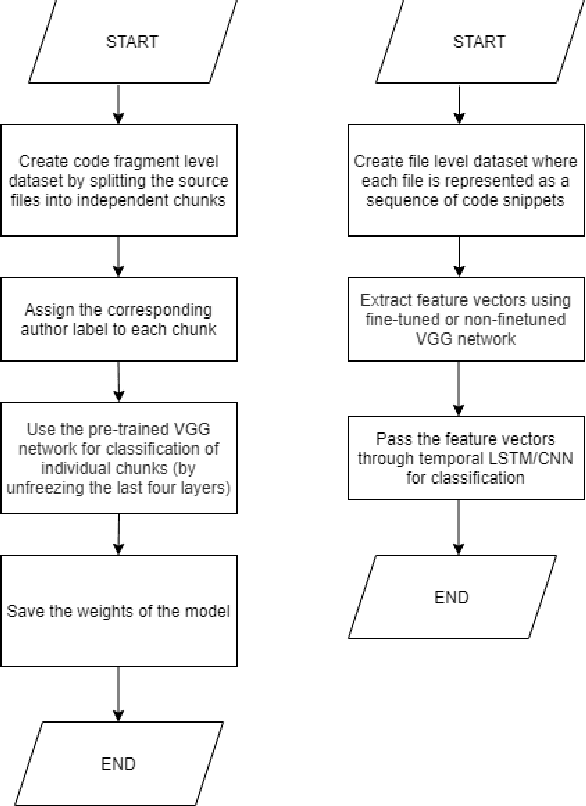
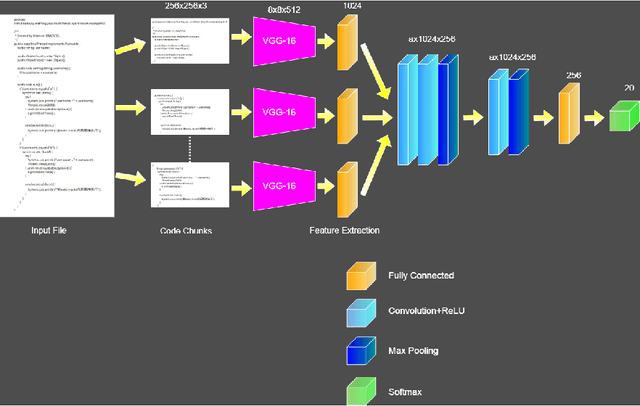
With the open-source revolution, source codes are now more easily accessible than ever. This has, however, made it easier for malicious users and institutions to copy the code without giving regards to the license, or credit to the original author. Therefore, source code author identification is a critical task with paramount importance. In this paper, we propose ICodeNet - a hierarchical neural network that can be used for source code file-level tasks. The ICodeNet processes source code in image format and is employed for the task of per file author identification. The ICodeNet consists of an ImageNet trained VGG encoder followed by a shallow neural network. The shallow network is based either on CNN or LSTM. Different variations of models are evaluated on a source code author classification dataset. We have also compared our image-based hierarchical neural network model with simple image-based CNN architecture and text-based CNN and LSTM models to highlight its novelty and efficiency.
A Low-Cost Neural ODE with Depthwise Separable Convolution for Edge Domain Adaptation on FPGAs
Jul 27, 2021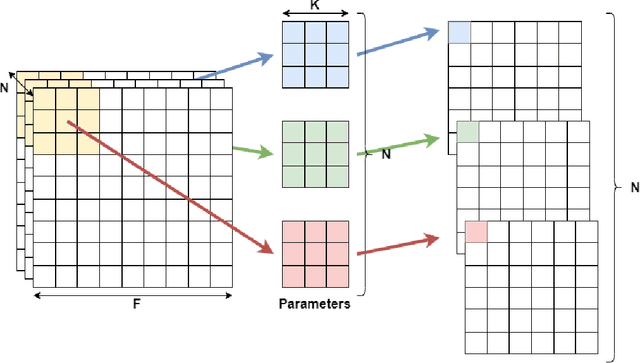

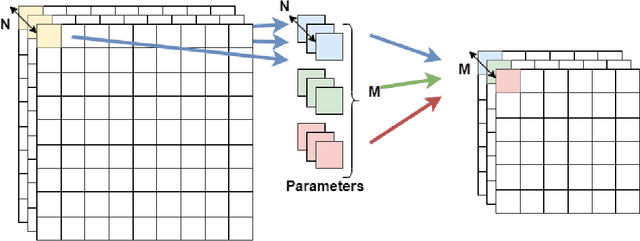
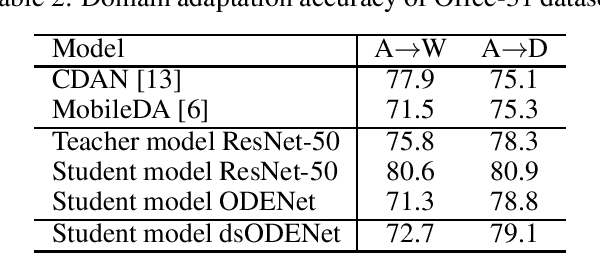
Although high-performance deep neural networks are in high demand in edge environments, computation resources are strictly limited in edge devices, and light-weight neural network techniques, such as Depthwise Separable Convolution (DSC), have been developed. ResNet is one of conventional deep neural network models that stack a lot of layers and parameters for a higher accuracy. To reduce the parameter size of ResNet, by utilizing a similarity to ODE (Ordinary Differential Equation), Neural ODE repeatedly uses most of weight parameters instead of having a lot of different parameters. Thus, Neural ODE becomes significantly small compared to that of ResNet so that it can be implemented in resource-limited edge devices. In this paper, a combination of Neural ODE and DSC, called dsODENet, is designed and implemented for FPGAs (Field-Programmable Gate Arrays). dsODENet is then applied to edge domain adaptation as a practical use case and evaluated with image classification datasets. It is implemented on Xilinx ZCU104 board and evaluated in terms of domain adaptation accuracy, training speed, FPGA resource utilization, and speedup rate compared to a software execution. The results demonstrate that dsODENet is comparable to or slightly better than our baseline Neural ODE implementation in terms of domain adaptation accuracy, while the total parameter size without pre- and post-processing layers is reduced by 54.2% to 79.8%. The FPGA implementation accelerates the prediction tasks by 27.9 times faster than a software implementation.
Generative Zero-shot Network Quantization
Jan 21, 2021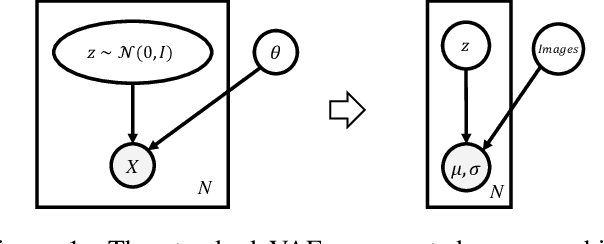
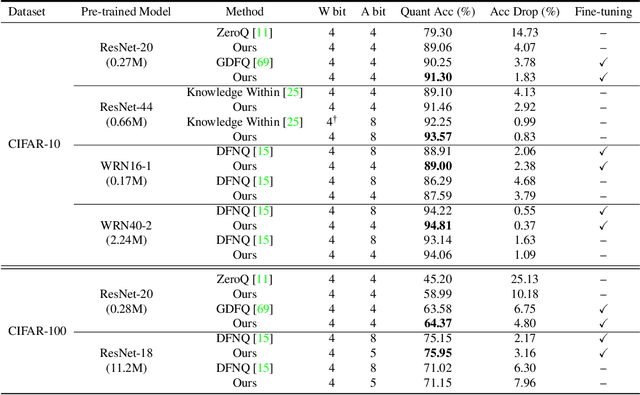
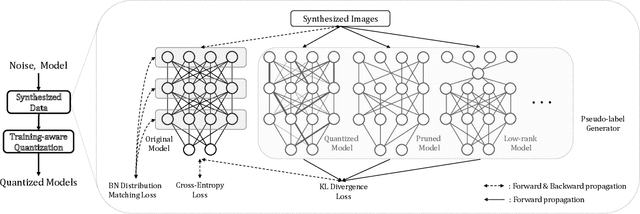
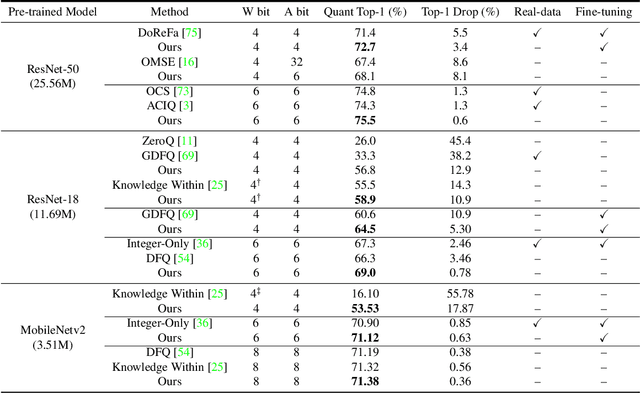
Convolutional neural networks are able to learn realistic image priors from numerous training samples in low-level image generation and restoration. We show that, for high-level image recognition tasks, we can further reconstruct "realistic" images of each category by leveraging intrinsic Batch Normalization (BN) statistics without any training data. Inspired by the popular VAE/GAN methods, we regard the zero-shot optimization process of synthetic images as generative modeling to match the distribution of BN statistics. The generated images serve as a calibration set for the following zero-shot network quantizations. Our method meets the needs for quantizing models based on sensitive information, \textit{e.g.,} due to privacy concerns, no data is available. Extensive experiments on benchmark datasets show that, with the help of generated data, our approach consistently outperforms existing data-free quantization methods.