 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal 3D Foundation Model for Light Sheet Fluorescence Microscopy Enables Few-Shot Segmentation, Classification, and Deblurring
May 25, 2026Light sheet fluorescence microscopy (LSM) enables high-resolution, three-dimensional (3D) imaging of biological specimens, providing rich volumetric data for studying cellular organization, pathology, and vascular networks. However, the size, dimensionality, and annotation burden of LSM data make supervised deep learning approaches costly and difficult to scale. Additionally, despite the abundance of unannotated LSM volumes, foundation models for this modality remain underexplored due to computational challenges and the complexity of volumetric representation learning. In this work, we introduce a 3D foundation model for LSM data, pretrained on a large curated collection of 3D images spanning multiple organisms, stains, and imaging protocols. We learn transferable volumetric representations by jointly optimizing for masked reconstruction and image-text alignment. The pretrained backbone drastically reduces the annotation burden, enabling efficient, few-shot adaptation for varied downstream tasks. We evaluate this approach on downstream segmentation, classification, and deblurring. Our results demonstrate consistent improvements over baselines, (1) when measured using standard evaluation metrics and (2) when rigorously assessed by domain experts. This highlights the potential of foundation model pretraining to reduce annotation requirements while improving performance across diverse LSM analysis tasks. Pretrained model weights and code for pretraining and finetuning are publicly available: https://github.com/AdinaScheinfeld/lsm_fm_public_repo.git.
MUSt3R: Multi-view Network for Stereo 3D Reconstruction
Mar 03, 2025DUSt3R introduced a novel paradigm in geometric computer vision by proposing a model that can provide dense and unconstrained Stereo 3D Reconstruction of arbitrary image collections with no prior information about camera calibration nor viewpoint poses. Under the hood, however, DUSt3R processes image pairs, regressing local 3D reconstructions that need to be aligned in a global coordinate system. The number of pairs, growing quadratically, is an inherent limitation that becomes especially concerning for robust and fast optimization in the case of large image collections. In this paper, we propose an extension of DUSt3R from pairs to multiple views, that addresses all aforementioned concerns. Indeed, we propose a Multi-view Network for Stereo 3D Reconstruction, or MUSt3R, that modifies the DUSt3R architecture by making it symmetric and extending it to directly predict 3D structure for all views in a common coordinate frame. Second, we entail the model with a multi-layer memory mechanism which allows to reduce the computational complexity and to scale the reconstruction to large collections, inferring thousands of 3D pointmaps at high frame-rates with limited added complexity. The framework is designed to perform 3D reconstruction both offline and online, and hence can be seamlessly applied to SfM and visual SLAM scenarios showing state-of-the-art performance on various 3D downstream tasks, including uncalibrated Visual Odometry, relative camera pose, scale and focal estimation, 3D reconstruction and multi-view depth estimation.
Could ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
Rethinking pose estimation in crowds: overcoming the detection information-bottleneck and ambiguity
Jun 13, 2023



Frequent interactions between individuals are a fundamental challenge for pose estimation algorithms. Current pipelines either use an object detector together with a pose estimator (top-down approach), or localize all body parts first and then link them to predict the pose of individuals (bottom-up). Yet, when individuals closely interact, top-down methods are ill-defined due to overlapping individuals, and bottom-up methods often falsely infer connections to distant body parts. Thus, we propose a novel pipeline called bottom-up conditioned top-down pose estimation (BUCTD) that combines the strengths of bottom-up and top-down methods. Specifically, we propose to use a bottom-up model as the detector, which in addition to an estimated bounding box provides a pose proposal that is fed as condition to an attention-based top-down model. We demonstrate the performance and efficiency of our approach on animal and human pose estimation benchmarks. On CrowdPose and OCHuman, we outperform previous state-of-the-art models by a significant margin. We achieve 78.5 AP on CrowdPose and 47.2 AP on OCHuman, an improvement of 8.6% and 4.9% over the prior art, respectively. Furthermore, we show that our method has excellent performance on non-crowded datasets such as COCO, and strongly improves the performance on multi-animal benchmarks involving mice, fish and monkeys.
End-to-End Trainable Multi-Instance Pose Estimation with Transformers
Mar 22, 2021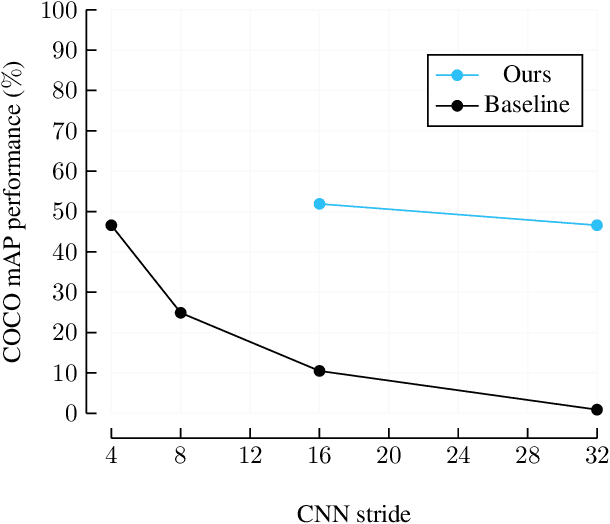
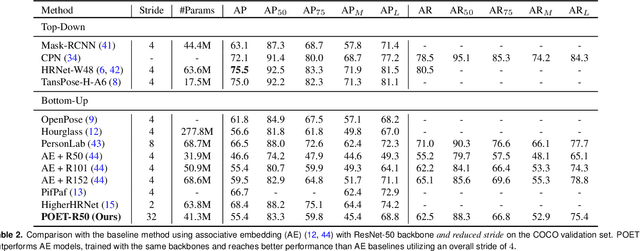
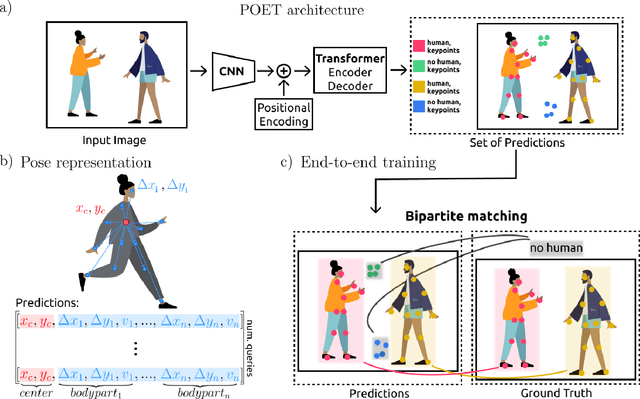

We propose a new end-to-end trainable approach for multi-instance pose estimation by combining a convolutional neural network with a transformer. We cast multi-instance pose estimation from images as a direct set prediction problem. Inspired by recent work on end-to-end trainable object detection with transformers, we use a transformer encoder-decoder architecture together with a bipartite matching scheme to directly regress the pose of all individuals in a given image. Our model, called POse Estimation Transformer (POET), is trained using a novel set-based global loss that consists of a keypoint loss, a keypoint visibility loss, a center loss and a class loss. POET reasons about the relations between detected humans and the full image context to directly predict the poses in parallel. We show that POET can achieve high accuracy on the challenging COCO keypoint detection task. To the best of our knowledge, this model is the first end-to-end trainable multi-instance human pose estimation method.