 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dual Adaptive Pyramid Network for Cross-Stain Histopathology Image Segmentation
Sep 25, 2019
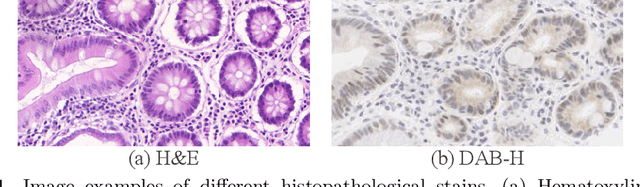
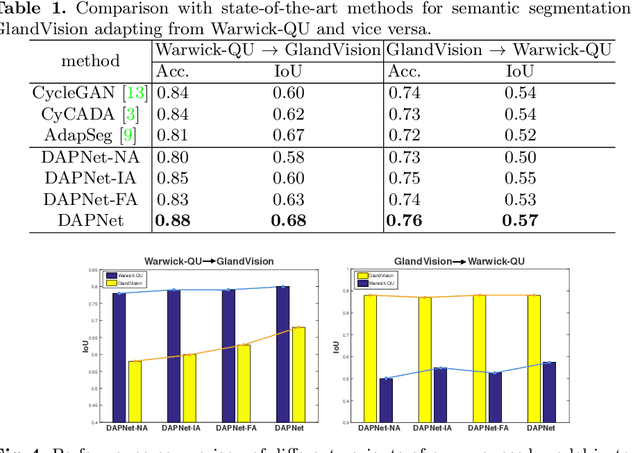
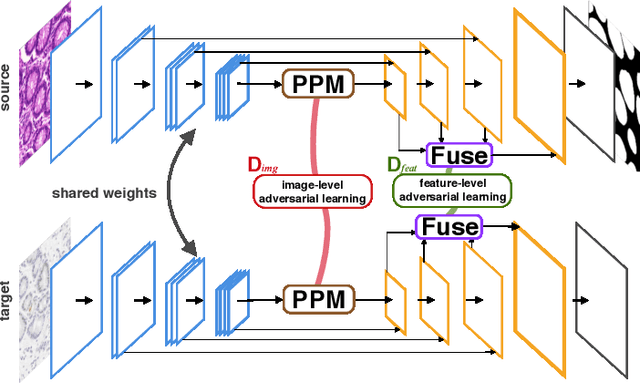
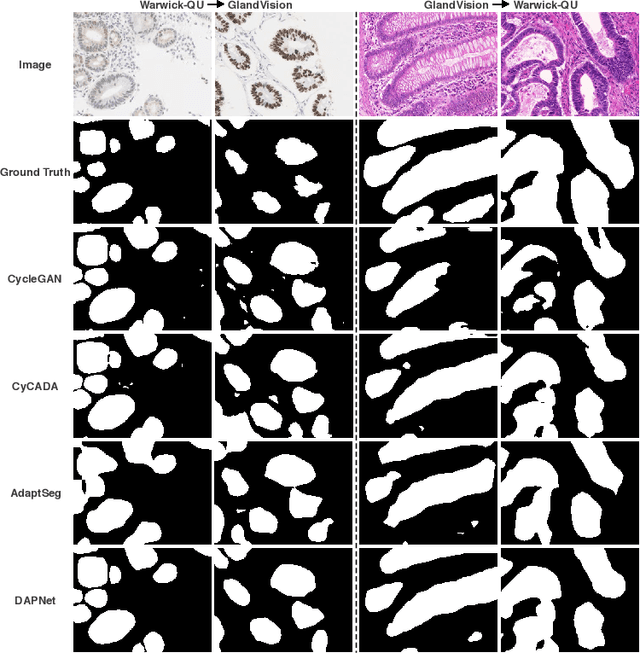
Supervised semantic segmentation normally assumes the test data being in a similar data domain as the training data. However, in practice, the domain mismatch between the training and unseen data could lead to a significant performance drop. Obtaining accurate pixel-wise label for images in different domains is tedious and labor intensive, especially for histopathology images. In this paper, we propose a dual adaptive pyramid network (DAPNet) for histopathological gland segmentation adapting from one stain domain to another. We tackle the domain adaptation problem on two levels: 1) the image-level considers the differences of image color and style; 2) the feature-level addresses the spatial inconsistency between two domains. The two components are implemented as domain classifiers with adversarial training. We evaluate our new approach using two gland segmentation datasets with H&E and DAB-H stains respectively. The extensive experiments and ablation study demonstrate the effectiveness of our approach on the domain adaptive segmentation task. We show that the proposed approach performs favorably against other state-of-the-art methods.
Stylizing 3D Scene via Implicit Representation and HyperNetwork
May 27, 2021
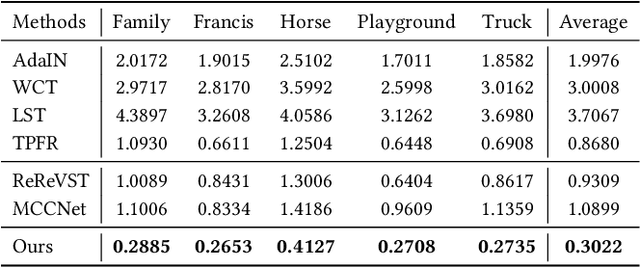
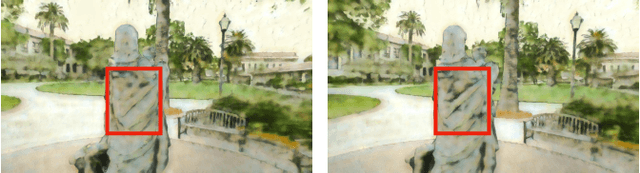
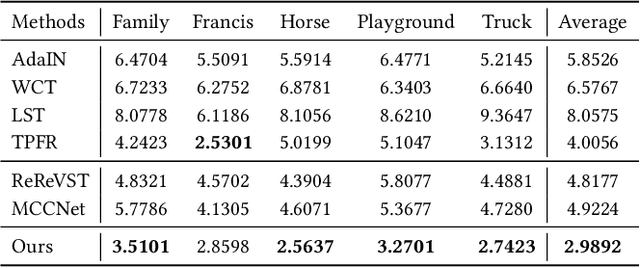
In this work, we aim to address the 3D scene stylization problem - generating stylized images of the scene at arbitrary novel view angles. A straightforward solution is to combine existing novel view synthesis and image/video style transfer approaches, which often leads to blurry results or inconsistent appearance. Inspired by the high quality results of the neural radiance fields (NeRF) method, we propose a joint framework to directly render novel views with the desired style. Our framework consists of two components: an implicit representation of the 3D scene with the neural radiance field model, and a hypernetwork to transfer the style information into the scene representation. In particular, our implicit representation model disentangles the scene into the geometry and appearance branches, and the hypernetwork learns to predict the parameters of the appearance branch from the reference style image. To alleviate the training difficulties and memory burden, we propose a two-stage training procedure and a patch sub-sampling approach to optimize the style and content losses with the neural radiance field model. After optimization, our model is able to render consistent novel views at arbitrary view angles with arbitrary style. Both quantitative evaluation and human subject study have demonstrated that the proposed method generates faithful stylization results with consistent appearance across different views.
Boosting Video Captioning with Dynamic Loss Network
Jul 25, 2021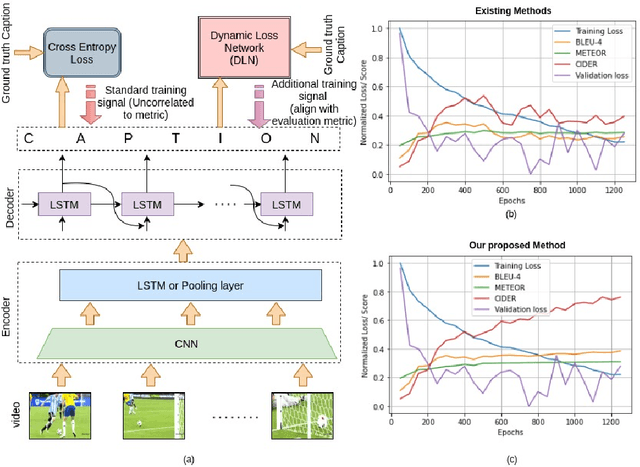
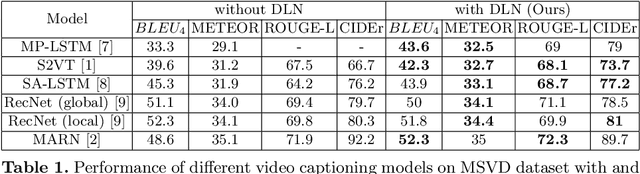
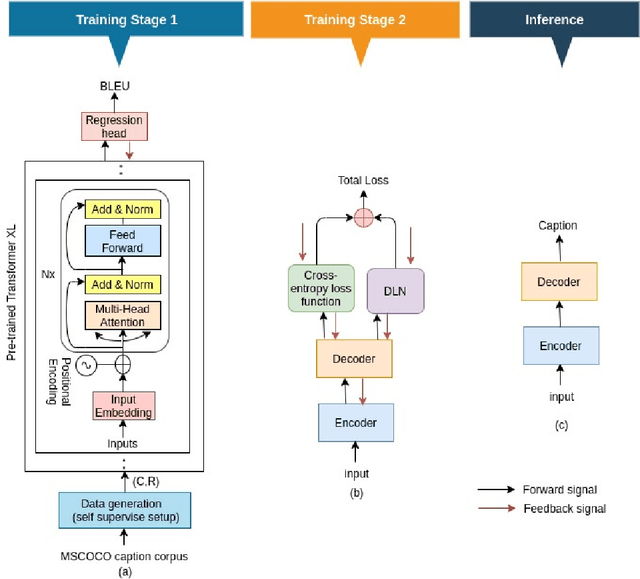
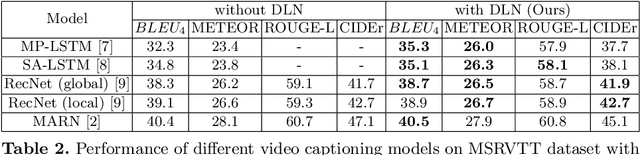
Video captioning is one of the challenging problems at the intersection of vision and language, having many real-life applications in video retrieval, video surveillance, assisting visually challenged people, Human-machine interface, and many more. Recent deep learning-based methods have shown promising results but are still on the lower side than other vision tasks (such as image classification, object detection). A significant drawback with existing video captioning methods is that they are optimized over cross-entropy loss function, which is uncorrelated to the de facto evaluation metrics (BLEU, METEOR, CIDER, ROUGE).In other words, cross-entropy is not a proper surrogate of the true loss function for video captioning. This paper addresses the drawback by introducing a dynamic loss network (DLN), which provides an additional feedback signal that directly reflects the evaluation metrics. Our results on Microsoft Research Video Description Corpus (MSVD) and MSR-Video to Text (MSRVTT) datasets outperform previous methods.
Scalable Neural Architecture Search for 3D Medical Image Segmentation
Jun 13, 2019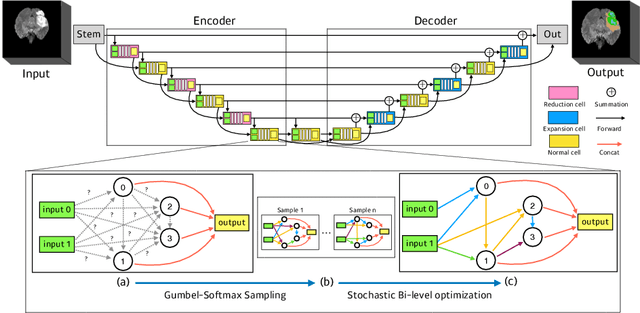
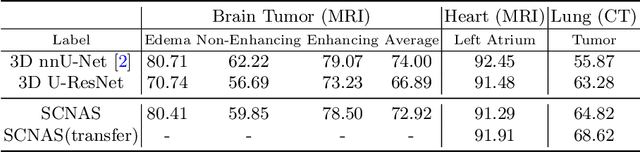
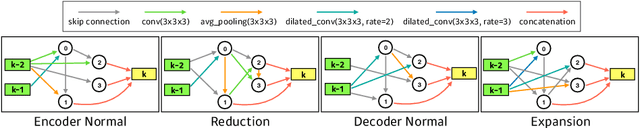
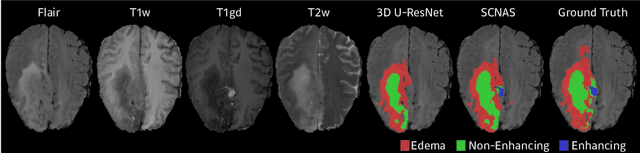
In this paper, a neural architecture search (NAS) framework is proposed for 3D medical image segmentation, to automatically optimize a neural architecture from a large design space. Our NAS framework searches the structure of each layer including neural connectivities and operation types in both of the encoder and decoder. Since optimizing over a large discrete architecture space is difficult due to high-resolution 3D medical images, a novel stochastic sampling algorithm based on a continuous relaxation is also proposed for scalable gradient based optimization. On the 3D medical image segmentation tasks with a benchmark dataset, an automatically designed architecture by the proposed NAS framework outperforms the human-designed 3D U-Net, and moreover this optimized architecture is well suited to be transferred for different tasks.
FaceShop: Deep Sketch-based Face Image Editing
Jun 07, 2018
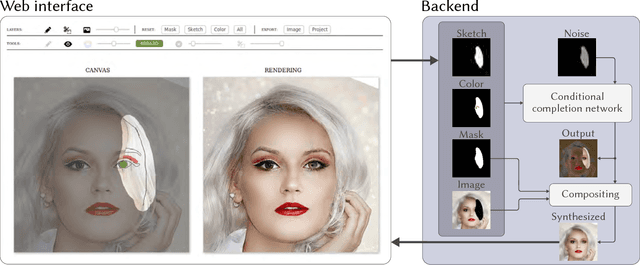
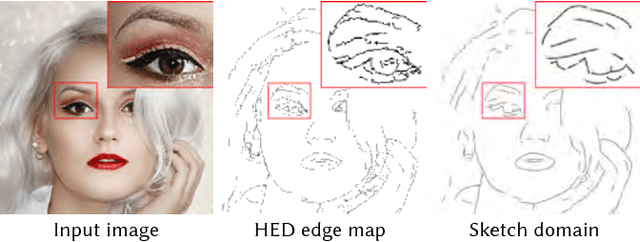

We present a novel system for sketch-based face image editing, enabling users to edit images intuitively by sketching a few strokes on a region of interest. Our interface features tools to express a desired image manipulation by providing both geometry and color constraints as user-drawn strokes. As an alternative to the direct user input, our proposed system naturally supports a copy-paste mode, which allows users to edit a given image region by using parts of another exemplar image without the need of hand-drawn sketching at all. The proposed interface runs in real-time and facilitates an interactive and iterative workflow to quickly express the intended edits. Our system is based on a novel sketch domain and a convolutional neural network trained end-to-end to automatically learn to render image regions corresponding to the input strokes. To achieve high quality and semantically consistent results we train our neural network on two simultaneous tasks, namely image completion and image translation. To the best of our knowledge, we are the first to combine these two tasks in a unified framework for interactive image editing. Our results show that the proposed sketch domain, network architecture, and training procedure generalize well to real user input and enable high quality synthesis results without additional post-processing.
Interpreting Face Inference Models using Hierarchical Network Dissection
Aug 23, 2021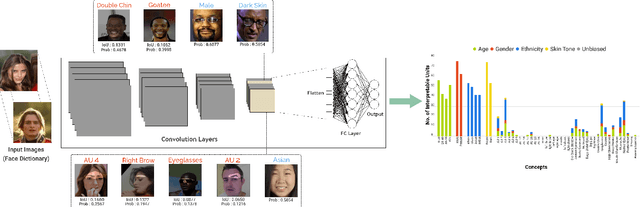

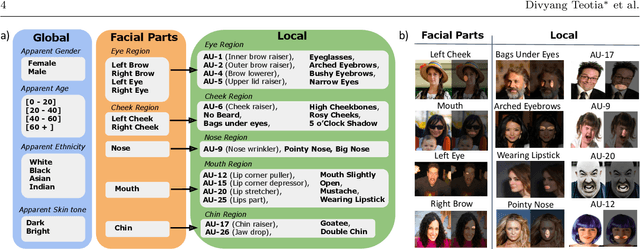
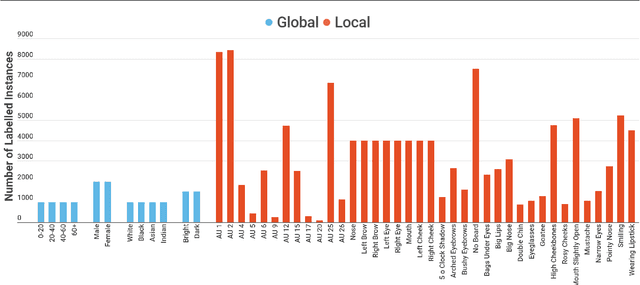
This paper presents Hierarchical Network Dissection, a general pipeline to interpret the internal representation of face-centric inference models. Using a probabilistic formulation, Hierarchical Network Dissection pairs units of the model with concepts in our "Face Dictionary" (a collection of facial concepts with corresponding sample images). Our pipeline is inspired by Network Dissection, a popular interpretability model for object-centric and scene-centric models. However, our formulation allows to deal with two important challenges of face-centric models that Network Dissection cannot address: (1) spacial overlap of concepts: there are different facial concepts that simultaneously occur in the same region of the image, like "nose" (facial part) and "pointy nose" (facial attribute); and (2) global concepts: there are units with affinity to concepts that do not refer to specific locations of the face (e.g. apparent age). To validate the effectiveness of our unit-concept pairing formulation, we first conduct controlled experiments on biased data. These experiments illustrate how Hierarchical Network Dissection can be used to discover bias in the training data. Then, we dissect different face-centric inference models trained on widely-used facial datasets. The results show models trained for different tasks have different internal representations. Furthermore, the interpretability results reveal some biases in the training data and some interesting characteristics of the face-centric inference tasks.
Learning by Aligning: Visible-Infrared Person Re-identification using Cross-Modal Correspondences
Aug 17, 2021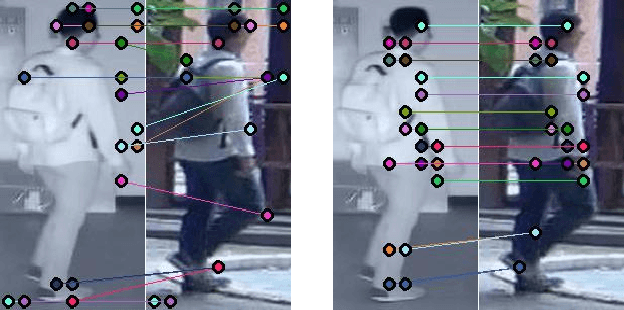
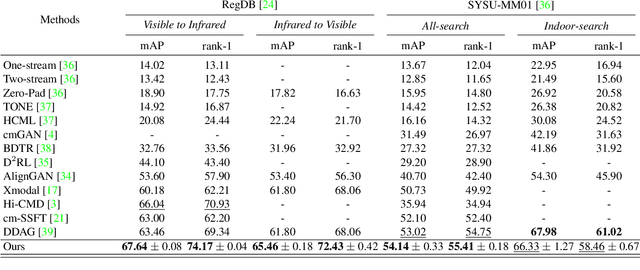
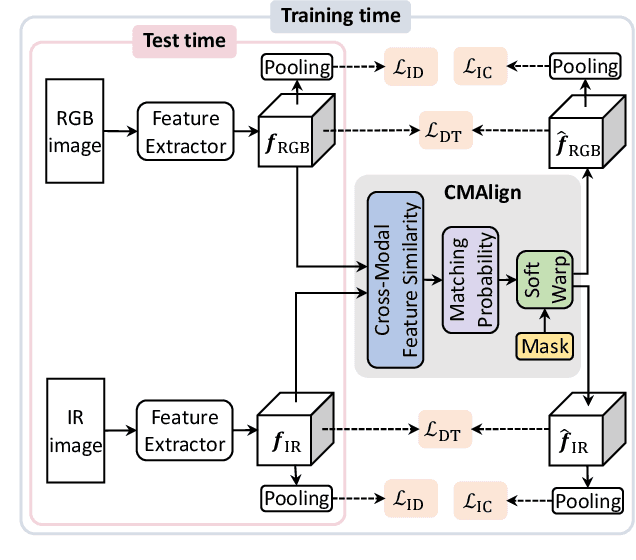
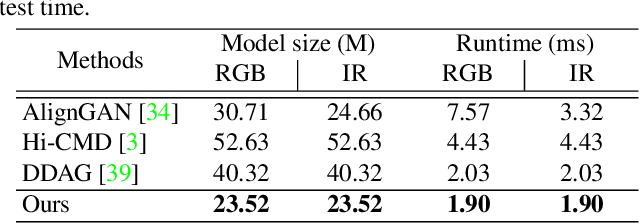
We address the problem of visible-infrared person re-identification (VI-reID), that is, retrieving a set of person images, captured by visible or infrared cameras, in a cross-modal setting. Two main challenges in VI-reID are intra-class variations across person images, and cross-modal discrepancies between visible and infrared images. Assuming that the person images are roughly aligned, previous approaches attempt to learn coarse image- or rigid part-level person representations that are discriminative and generalizable across different modalities. However, the person images, typically cropped by off-the-shelf object detectors, are not necessarily well-aligned, which distract discriminative person representation learning. In this paper, we introduce a novel feature learning framework that addresses these problems in a unified way. To this end, we propose to exploit dense correspondences between cross-modal person images. This allows to address the cross-modal discrepancies in a pixel-level, suppressing modality-related features from person representations more effectively. This also encourages pixel-wise associations between cross-modal local features, further facilitating discriminative feature learning for VI-reID. Extensive experiments and analyses on standard VI-reID benchmarks demonstrate the effectiveness of our approach, which significantly outperforms the state of the art.
PRNU Based Source Camera Identification for Webcam Videos
Jul 05, 2021
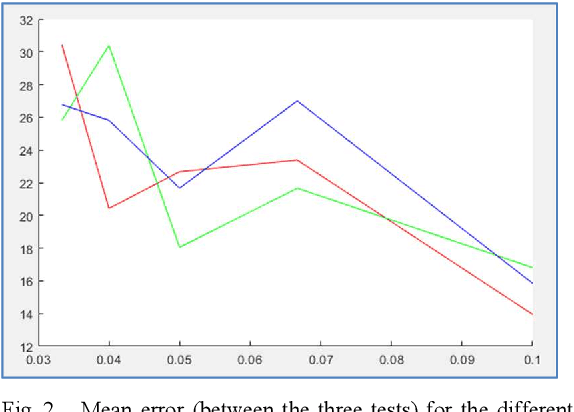
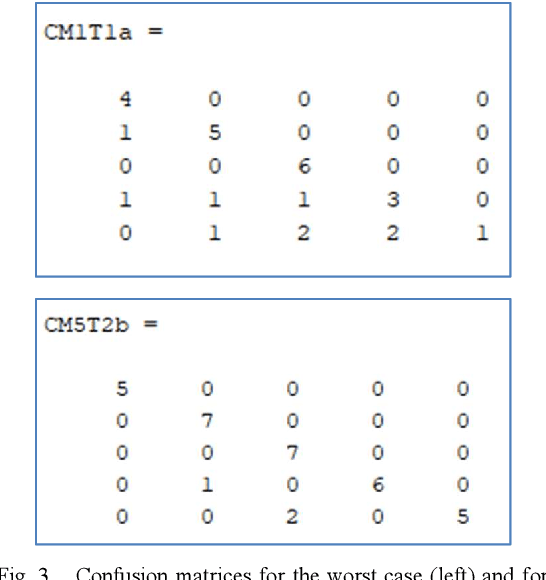
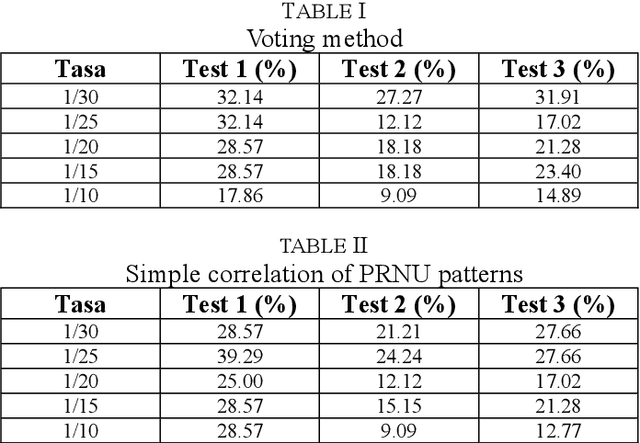
This communication is about an application of image forensics where we use camera sensor fingerprints to identify source camera (SCI: Source Camera Identification) in webcam videos. Sensor or camera fingerprints are based on computing the intrinsic noise that is always present in this kind of sensors due to manufacturing imperfections. This is an unavoidable characteristic that links each sensor with its noise pattern. PRNU (Photo Response Non-Uniformity) has become the default technique to compute a camera fingerprint. There are many applications nowadays dealing with PRNU patterns for camera identification using still images. In this work we focus on video, more specifically on webcam video, because of the great importance of webcam video nowadays. Three possible methods for SCI are implemented and assessed in this work.
Influence-guided Data Augmentation for Neural Tensor Completion
Aug 23, 2021
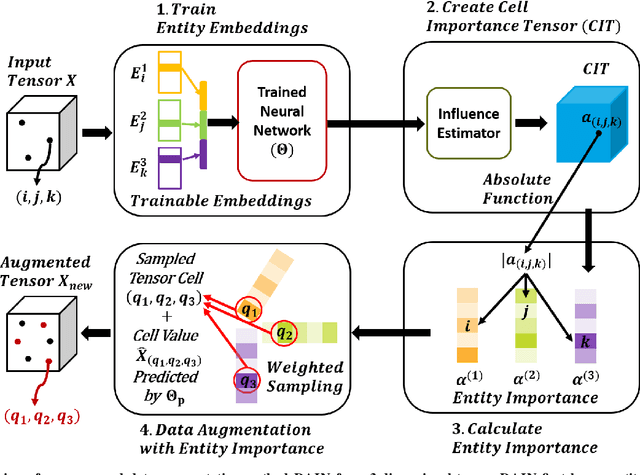

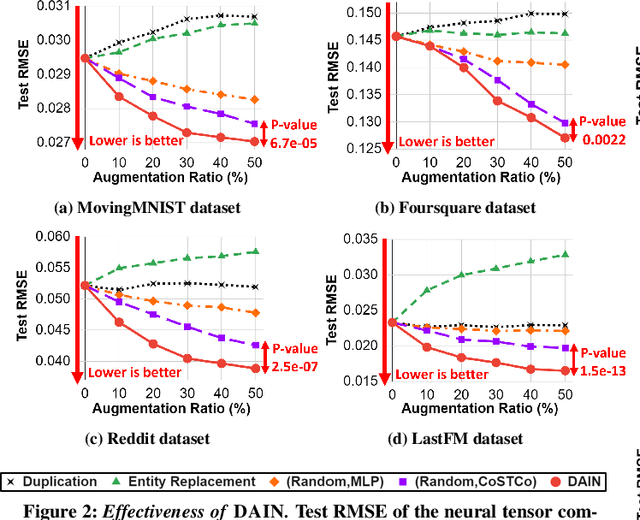
How can we predict missing values in multi-dimensional data (or tensors) more accurately? The task of tensor completion is crucial in many applications such as personalized recommendation, image and video restoration, and link prediction in social networks. Many tensor factorization and neural network-based tensor completion algorithms have been developed to predict missing entries in partially observed tensors. However, they can produce inaccurate estimations as real-world tensors are very sparse, and these methods tend to overfit on the small amount of data. Here, we overcome these shortcomings by presenting a data augmentation technique for tensors. In this paper, we propose DAIN, a general data augmentation framework that enhances the prediction accuracy of neural tensor completion methods. Specifically, DAIN first trains a neural model and finds tensor cell importances with influence functions. After that, DAIN aggregates the cell importance to calculate the importance of each entity (i.e., an index of a dimension). Finally, DAIN augments the tensor by weighted sampling of entity importances and a value predictor. Extensive experimental results show that DAIN outperforms all data augmentation baselines in terms of enhancing imputation accuracy of neural tensor completion on four diverse real-world tensors. Ablation studies of DAIN substantiate the effectiveness of each component of DAIN. Furthermore, we show that DAIN scales near linearly to large datasets.
Domain-Aware Universal Style Transfer
Aug 17, 2021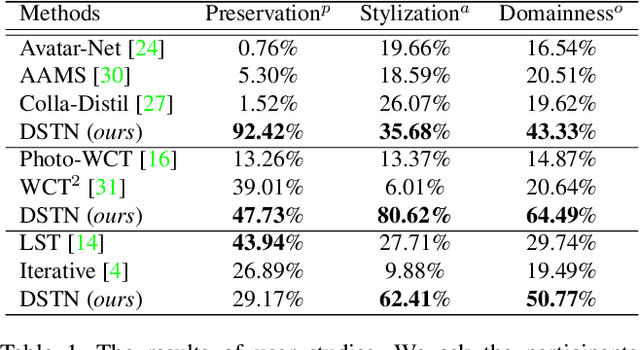
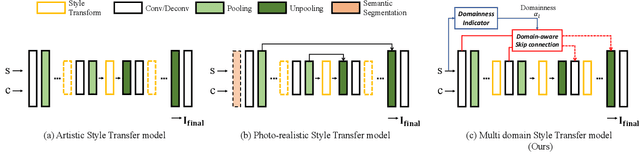
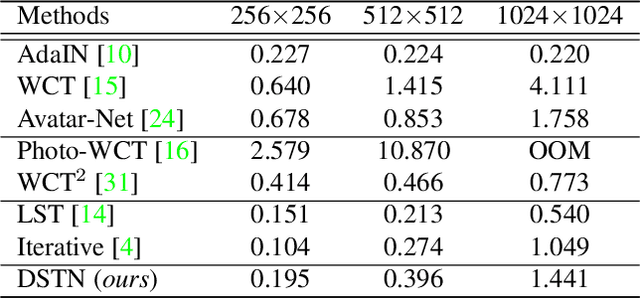
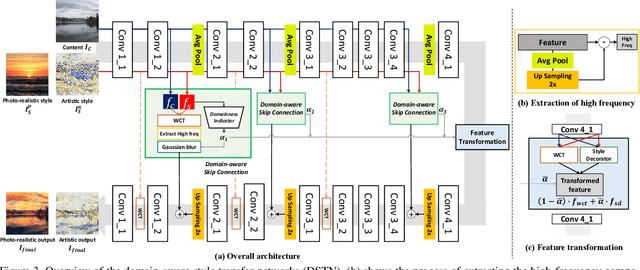
Style transfer aims to reproduce content images with the styles from reference images. Existing universal style transfer methods successfully deliver arbitrary styles to original images either in an artistic or a photo-realistic way. However, the range of 'arbitrary style' defined by existing works is bounded in the particular domain due to their structural limitation. Specifically, the degrees of content preservation and stylization are established according to a predefined target domain. As a result, both photo-realistic and artistic models have difficulty in performing the desired style transfer for the other domain. To overcome this limitation, we propose a unified architecture, Domain-aware Style Transfer Networks (DSTN) that transfer not only the style but also the property of domain (i.e., domainness) from a given reference image. To this end, we design a novel domainness indicator that captures the domainness value from the texture and structural features of reference images. Moreover, we introduce a unified framework with domain-aware skip connection to adaptively transfer the stroke and palette to the input contents guided by the domainness indicator. Our extensive experiments validate that our model produces better qualitative results and outperforms previous methods in terms of proxy metrics on both artistic and photo-realistic stylizations.