 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Few-Shot Segmentation with Global and Local Contrastive Learning
Aug 11, 2021
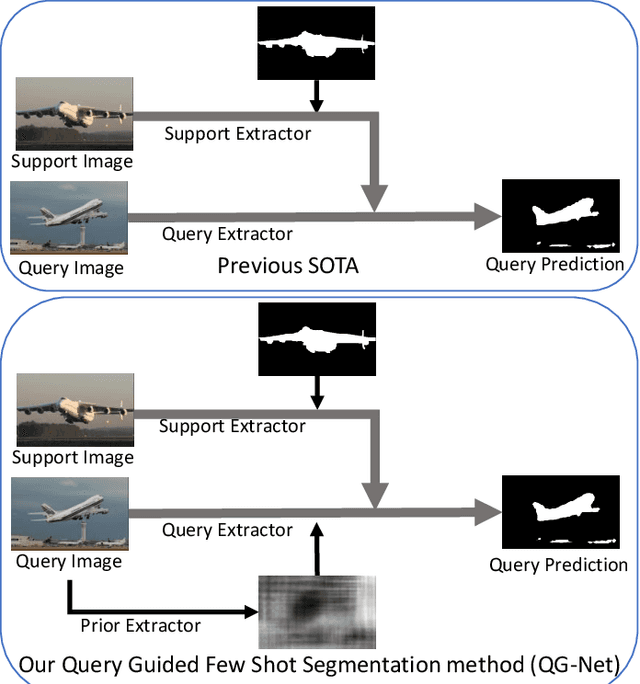
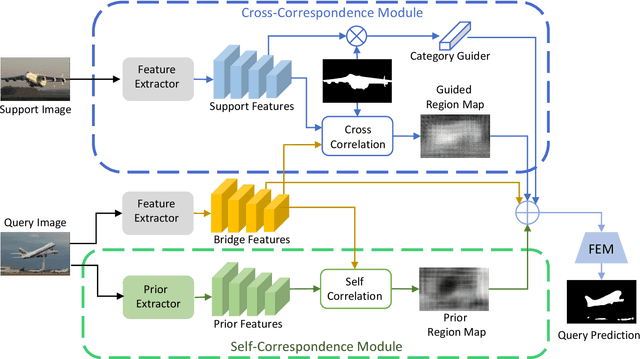
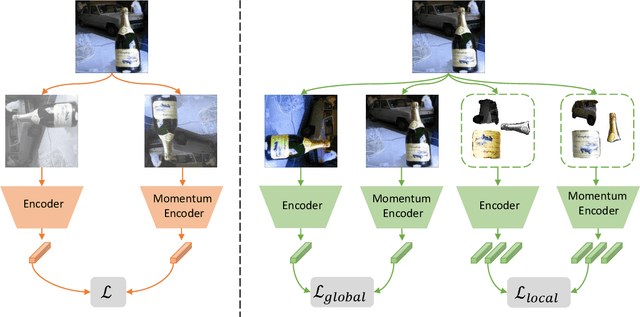

In this work, we address the challenging task of few-shot segmentation. Previous few-shot segmentation methods mainly employ the information of support images as guidance for query image segmentation. Although some works propose to build cross-reference between support and query images, their extraction of query information still depends on the support images. We here propose to extract the information from the query itself independently to benefit the few-shot segmentation task. To this end, we first propose a prior extractor to learn the query information from the unlabeled images with our proposed global-local contrastive learning. Then, we extract a set of predetermined priors via this prior extractor. With the obtained priors, we generate the prior region maps for query images, which locate the objects, as guidance to perform cross interaction with support features. In such a way, the extraction of query information is detached from the support branch, overcoming the limitation by support, and could obtain more informative query clues to achieve better interaction. Without bells and whistles, the proposed approach achieves new state-of-the-art performance for the few-shot segmentation task on PASCAL-5$^{i}$ and COCO datasets.
Teacher-Student chain for efficient semi-supervised histology image classification
Mar 20, 2020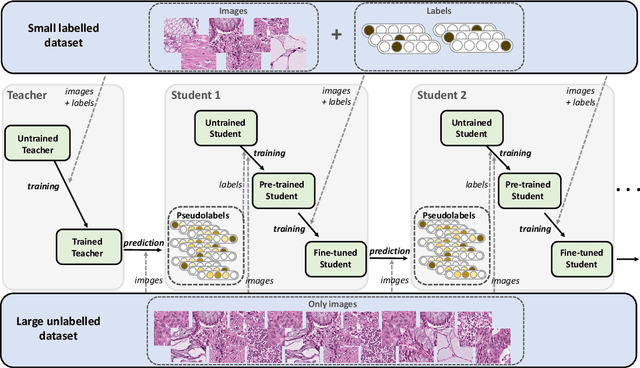

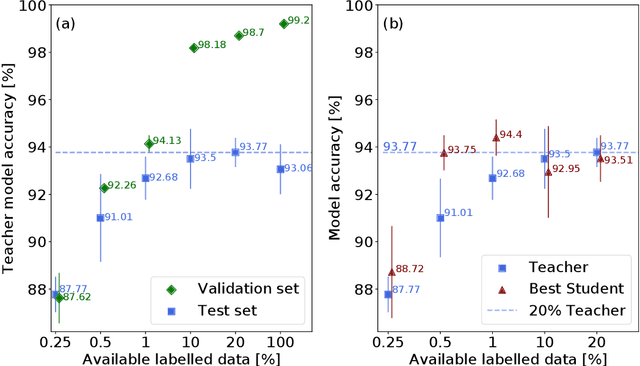
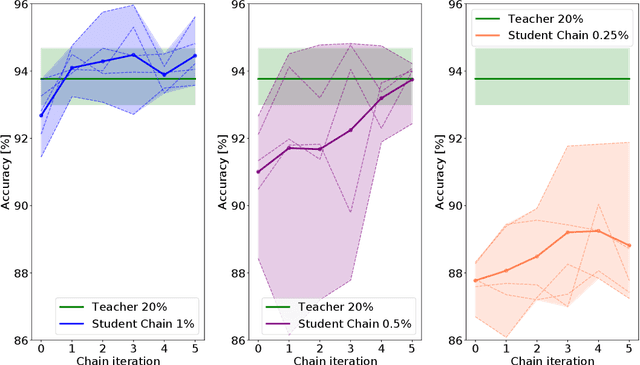
Deep learning shows great potential for the domain of digital pathology. An automated digital pathology system could serve as a second reader, perform initial triage in large screening studies, or assist in reporting. However, it is expensive to exhaustively annotate large histology image databases, since medical specialists are a scarce resource. In this paper, we apply the semi-supervised teacher-student knowledge distillation technique proposed by Yalniz et al. (2019) to the task of quantifying prognostic features in colorectal cancer. We obtain accuracy improvements through extending this approach to a chain of students, where each student's predictions are used to train the next student i.e. the student becomes the teacher. Using the chain approach, and only 0.5% labelled data (the remaining 99.5% in the unlabelled pool), we match the accuracy of training on 100% labelled data. At lower percentages of labelled data, similar gains in accuracy are seen, allowing some recovery of accuracy even from a poor initial choice of labelled training set. In conclusion, this approach shows promise for reducing the annotation burden, thus increasing the affordability of automated digital pathology systems.
JGR-P2O: Joint Graph Reasoning based Pixel-to-Offset Prediction Network for 3D Hand Pose Estimation from a Single Depth Image
Jul 09, 2020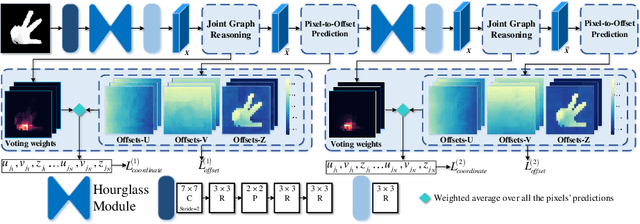
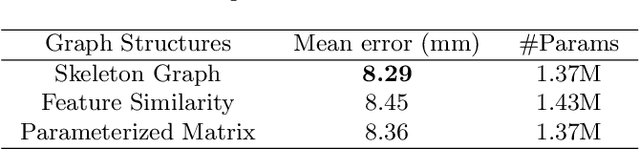
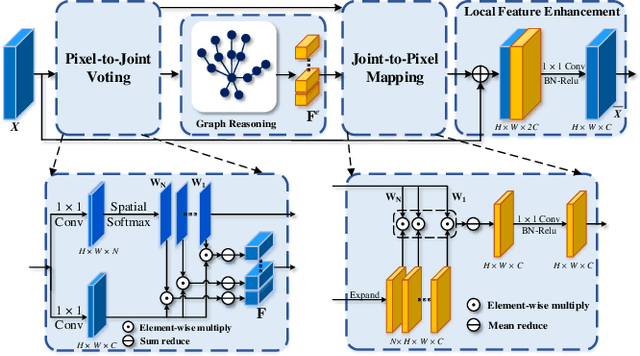

State-of-the-art single depth image-based 3D hand pose estimation methods are based on dense predictions, including voxel-to-voxel predictions, point-to-point regression, and pixel-wise estimations. Despite the good performance, those methods have a few issues in nature, such as the poor trade-off between accuracy and efficiency, and plain feature representation learning with local convolutions. In this paper, a novel pixel-wise prediction-based method is proposed to address the above issues. The key ideas are two-fold: a) explicitly modeling the dependencies among joints and the relations between the pixels and the joints for better local feature representation learning; b) unifying the dense pixel-wise offset predictions and direct joint regression for end-to-end training. Specifically, we first propose a graph convolutional network (GCN) based joint graph reasoning module to model the complex dependencies among joints and augment the representation capability of each pixel. Then we densely estimate all pixels' offsets to joints in both image plane and depth space and calculate the joints' positions by a weighted average over all pixels' predictions, totally discarding the complex postprocessing operations. The proposed model is implemented with an efficient 2D fully convolutional network (FCN) backbone and has only about 1.4M parameters. Extensive experiments on multiple 3D hand pose estimation benchmarks demonstrate that the proposed method achieves new state-of-the-art accuracy while running very efficiently with around a speed of 110fps on a single NVIDIA 1080Ti GPU.
Gated Context Aggregation Network for Image Dehazing and Deraining
Nov 21, 2018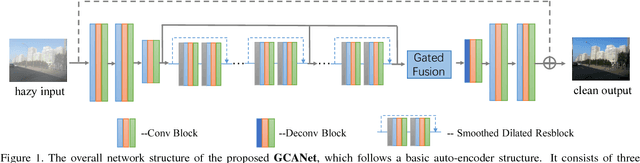

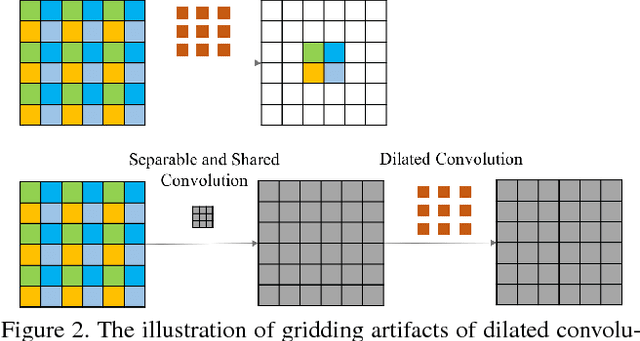

Image dehazing aims to recover the uncorrupted content from a hazy image. Instead of leveraging traditional low-level or handcrafted image priors as the restoration constraints, e.g., dark channels and increased contrast, we propose an end-to-end gated context aggregation network to directly restore the final haze-free image. In this network, we adopt the latest smoothed dilation technique to help remove the gridding artifacts caused by the widely-used dilated convolution with negligible extra parameters, and leverage a gated sub-network to fuse the features from different levels. Extensive experiments demonstrate that our method can surpass previous state-of-the-art methods by a large margin both quantitatively and qualitatively. In addition, to demonstrate the generality of the proposed method, we further apply it to the image deraining task, which also achieves the state-of-the-art performance.
Unrolled Wirtinger Flow with Deep Priors for Phaseless Imaging
Aug 03, 2021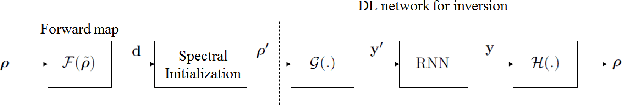
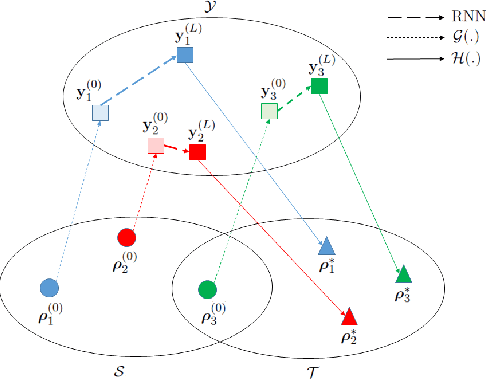

We introduce a deep learning (DL) based network for imaging from measurement intensities. The network architecture uses a recurrent structure that unrolls the Wirtinger Flow (WF) algorithm with a deep prior which enables performing the algorithm updates in a lower dimensional encoded image space. We use a separate deep network (DN), referred to as the encoding network, for transforming the spectral initialization used in the WF algorithm to an appropriate initial value for the encoded domain. The unrolling scheme that models a fixed number of iterations of the underlying algorithm into a recurrent neural network (RNN) enable us to simultaneously learn the parameters of the prior network, the encoding network and the RNN during training. We establish sufficient conditions on the network to guarantee exact recovery under deterministic forward models and demonstrate the relation between the Lipschitz constants of the trained prior and encoding networks to the convergence rate. We show the practical applicability of our method on synthetic aperture imaging using high fidelity simulation data from the PCSWAT software. Our numerical study shows that the deep prior facilitates improvements in sample complexity.
Gastric Cancer Detection from X-ray Images Using Effective Data Augmentation and Hard Boundary Box Training
Aug 18, 2021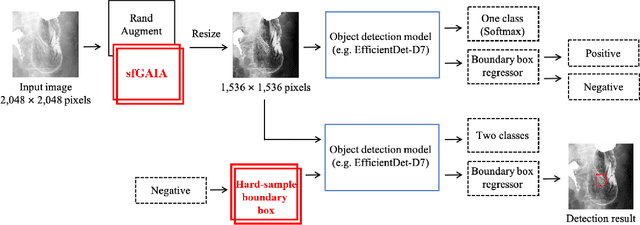
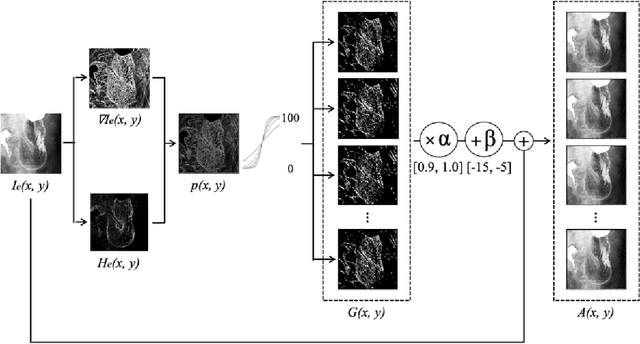
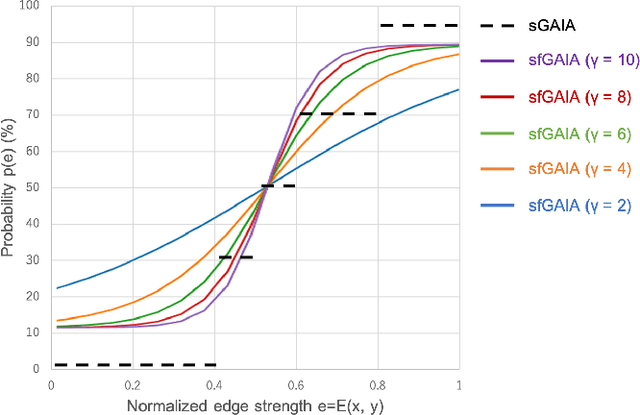
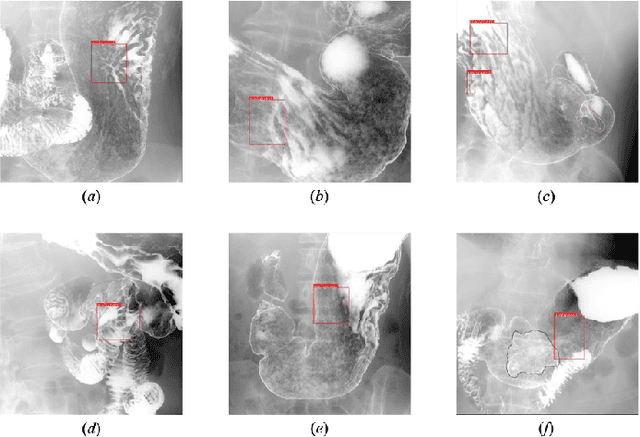
X-ray examination is suitable for screening of gastric cancer. Compared to endoscopy, which can only be performed by doctors, X-ray imaging can also be performed by radiographers, and thus, can treat more patients. However, the diagnostic accuracy of gastric radiographs is as low as 85%. To address this problem, highly accurate and quantitative automated diagnosis using machine learning needs to be performed. This paper proposes a diagnostic support method for detecting gastric cancer sites from X-ray images with high accuracy. The two new technical proposal of the method are (1) stochastic functional gastric image augmentation (sfGAIA), and (2) hard boundary box training (HBBT). The former is a probabilistic enhancement of gastric folds in X-ray images based on medical knowledge, whereas the latter is a recursive retraining technique to reduce false positives. We use 4,724 gastric radiographs of 145 patients in clinical practice and evaluate the cancer detection performance of the method in a patient-based five-group cross-validation. The proposed sfGAIA and HBBT significantly enhance the performance of the EfficientDet-D7 network by 5.9% in terms of the F1-score, and our screening method reaches a practical screening capability for gastric cancer (F1: 57.8%, recall: 90.2%, precision: 42.5%).
Dense Deformation Network for High Resolution Tissue Cleared Image Registration
Jun 13, 2019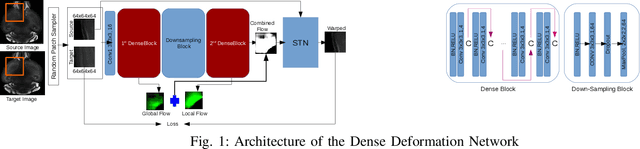
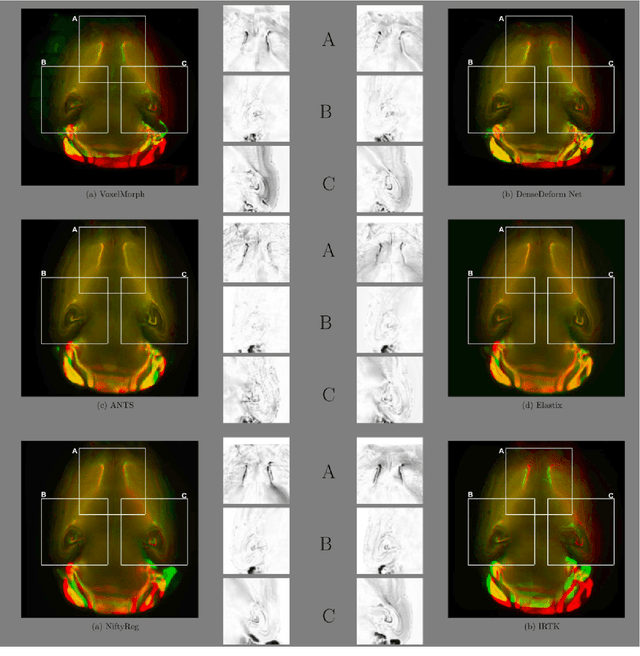
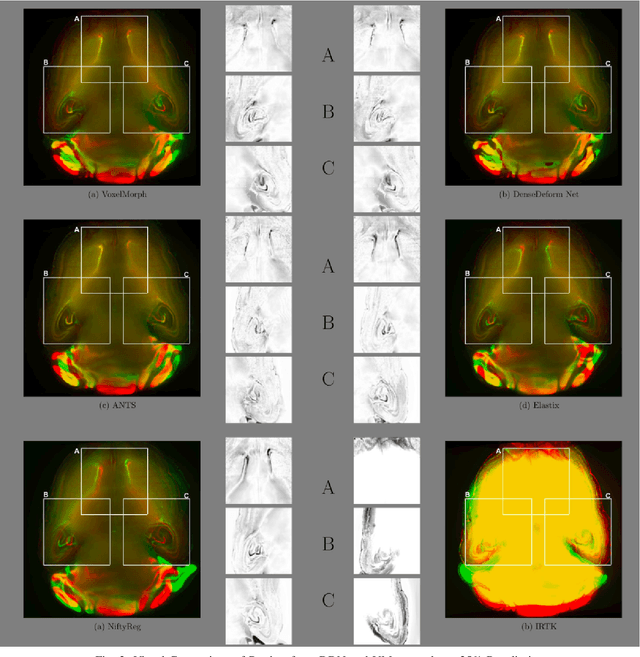
The recent application of Deep Learning in various areas of medical image analysis has brought excellent performance gain. The application of deep learning technologies in medical image registration successfully outperformed traditional optimization based registration algorithms both in registration time and accuracy. In this paper, we present a densely connected convolutional architecture for deformable image registration. The training of the network is unsupervised and does not require ground-truth deformation or any synthetic deformation as a label. The proposed architecture is trained and tested on two different version of tissue cleared data, 10\% and 25\% resolution of high resolution dataset respectively and demonstrated comparable registration performance with the state-of-the-art ANTS registration method. The proposed method is also compared with the deep-learning based Voxelmorph registration method. Due to the memory limitation, original voxelmorph can work at most 15\% resolution of Tissue cleared data. For rigorous experimental comparison we developed a patch-based version of Voxelmorph network, and trained it on 10\% and 25\% resolution. In both resolution, proposed DenseDeformation network outperformed Voxelmorph in registration accuracy.
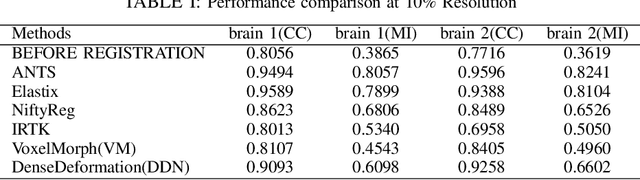
Nonconvex Nonsmooth Low-Rank Minimization for Generalized Image Compressed Sensing via Group Sparse Representation
Nov 18, 2019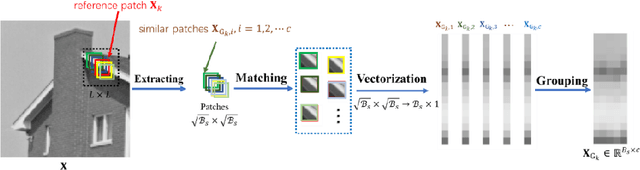



Group sparse representation (GSR) based method has led to great successes in various image recovery tasks, which can be converted into a low-rank matrix minimization problem. As a widely used surrogate function of low-rank, the nuclear norm based convex surrogate usually leads to over-shrinking problem, since the standard soft-thresholding operator shrinks all singular values equally. To improve traditional sparse representation based image compressive sensing (CS) performance, we propose a generalized CS framework based on GSR model, leading to a nonconvex nonsmooth low-rank minimization problem. The popular L_2-norm and M-estimator are employed for standard image CS and robust CS problem to fit the data respectively. For the better approximation of the rank of group-matrix, a family of nuclear norms are employed to address the over-shrinking problem. Moreover, we also propose a flexible and effective iteratively-weighting strategy to control the weighting and contribution of each singular value. Then we develop an iteratively reweighted nuclear norm algorithm for our generalized framework via an alternating direction method of multipliers framework, namely, GSR-ADMM-IRNN. Experimental results demonstrate that our proposed CS framework can achieve favorable reconstruction performance compared with current state-of-the-art methods and the RCS framework can suppress the outliers effectively.
Scalable Certified Segmentation via Randomized Smoothing
Jul 01, 2021
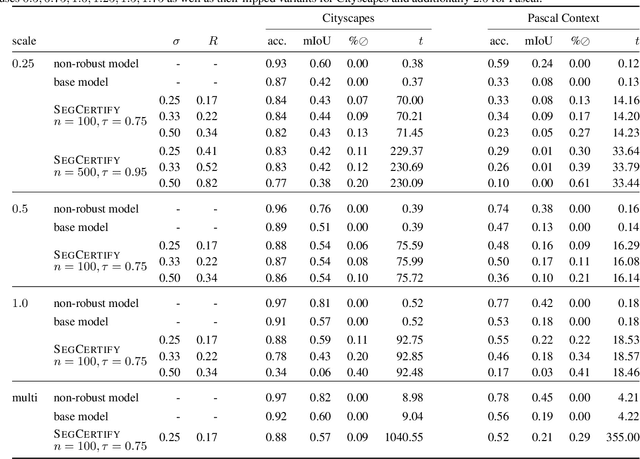
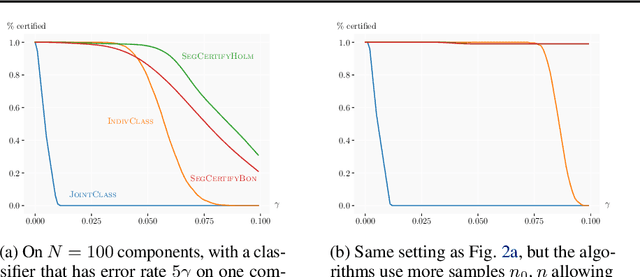
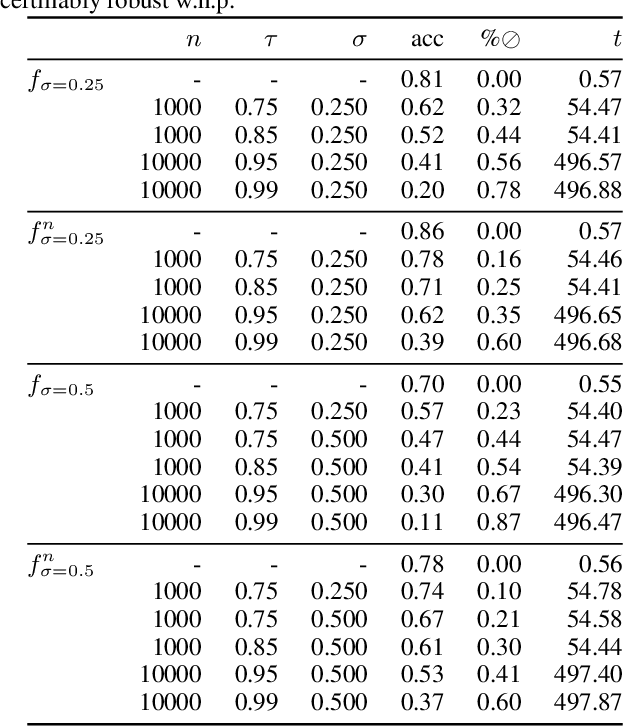
We present a new certification method for image and point cloud segmentation based on randomized smoothing. The method leverages a novel scalable algorithm for prediction and certification that correctly accounts for multiple testing, necessary for ensuring statistical guarantees. The key to our approach is reliance on established multiple-testing correction mechanisms as well as the ability to abstain from classifying single pixels or points while still robustly segmenting the overall input. Our experimental evaluation on synthetic data and challenging datasets, such as Pascal Context, Cityscapes, and ShapeNet, shows that our algorithm can achieve, for the first time, competitive accuracy and certification guarantees on real-world segmentation tasks. We provide an implementation at https://github.com/eth-sri/segmentation-smoothing.
Abstractive Sentence Summarization with Guidance of Selective Multimodal Reference
Aug 11, 2021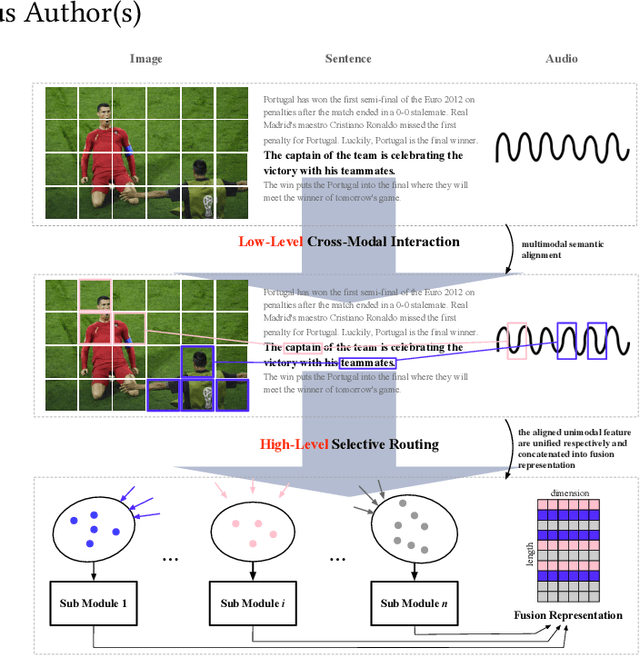

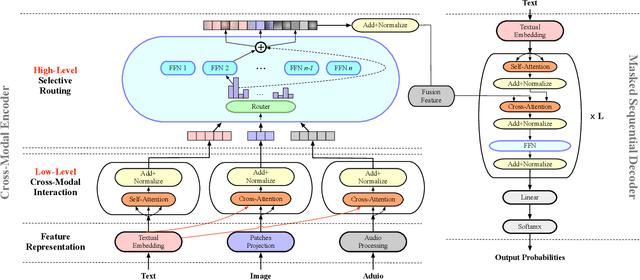
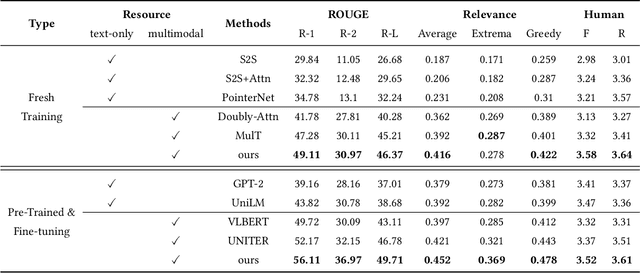
Multimodal abstractive summarization with sentence output is to generate a textual summary given a multimodal triad -- sentence, image and audio, which has been proven to improve users satisfaction and convenient our life. Existing approaches mainly focus on the enhancement of multimodal fusion, while ignoring the unalignment among multiple inputs and the emphasis of different segments in feature, which has resulted in the superfluity of multimodal interaction. To alleviate these problems, we propose a Multimodal Hierarchical Selective Transformer (mhsf) model that considers reciprocal relationships among modalities (by low-level cross-modal interaction module) and respective characteristics within single fusion feature (by high-level selective routing module). In details, it firstly aligns the inputs from different sources and then adopts a divide and conquer strategy to highlight or de-emphasize multimodal fusion representation, which can be seen as a sparsely feed-forward model - different groups of parameters will be activated facing different segments in feature. We evaluate the generalism of proposed mhsf model with the pre-trained+fine-tuning and fresh training strategies. And Further experimental results on MSMO demonstrate that our model outperforms SOTA baselines in terms of ROUGE, relevance scores and human evaluation.