 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Influence of Age and Gender Information on the Diagnosis of Diabetic Retinopathy: Based on Neural Networks
Aug 06, 2021
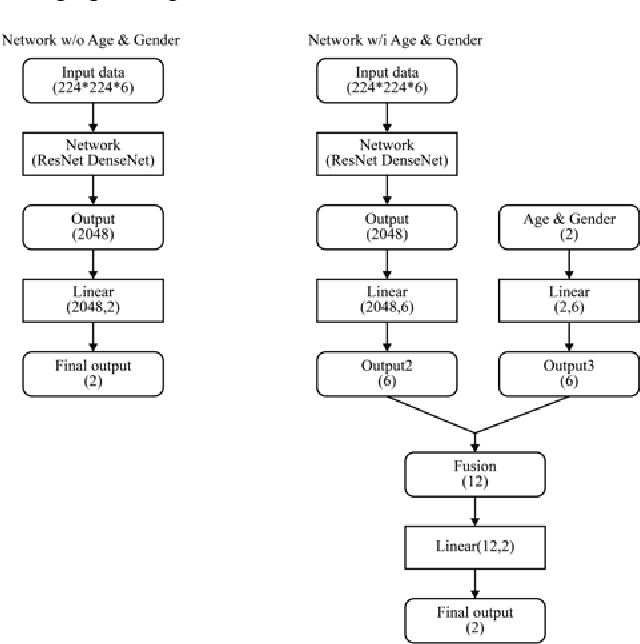
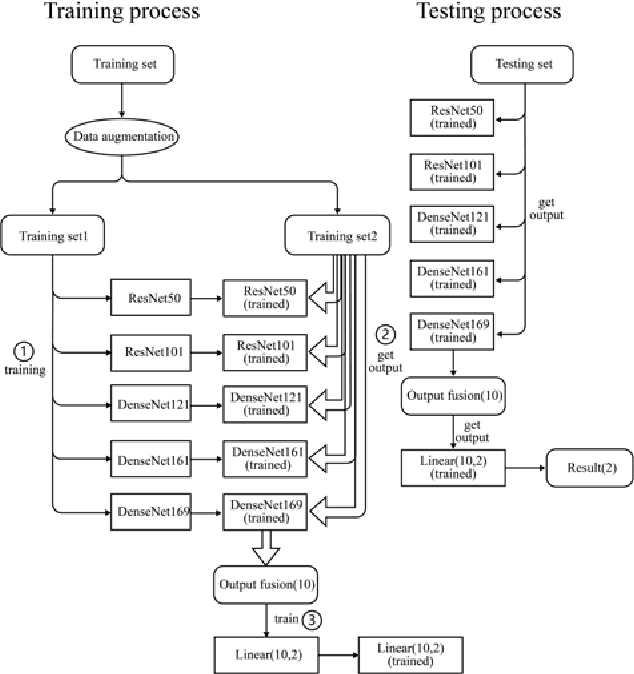
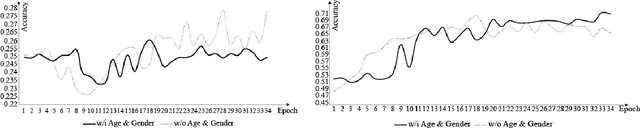
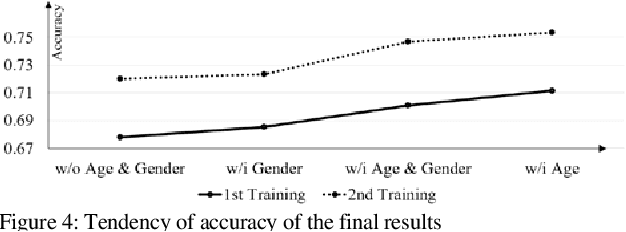
This paper proposes the importance of age and gender information in the diagnosis of diabetic retinopathy. We utilized Deep Residual Neural Networks (ResNet) and Densely Connected Convolutional Networks (DenseNet), which are proven effective on image classification problems and the diagnosis of diabetic retinopathy using the retinal fundus images. We used the ensemble of several classical networks and decentralized the training so that the network was simple and avoided overfitting. To observe whether the age and gender information could help enhance the performance, we added the information before the dense layer and compared the results with the results that did not add age and gender information. We found that the test accuracy of the network with age and gender information was 2.67% higher than that of the network without age and gender information. Meanwhile, compared with gender information, age information had a better help for the results.
AirLab: Autograd Image Registration Laboratory
Jun 26, 2018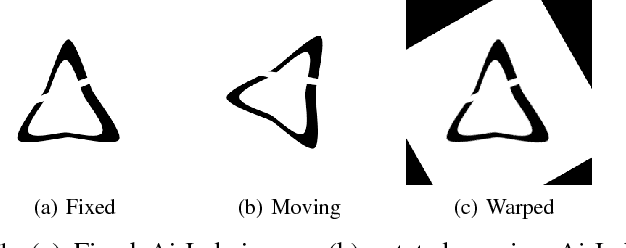
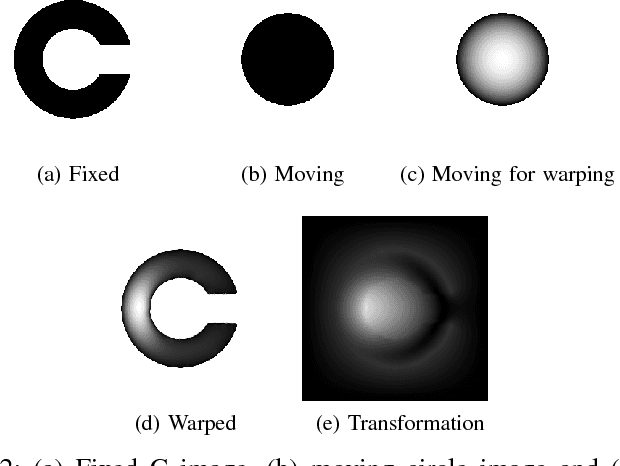
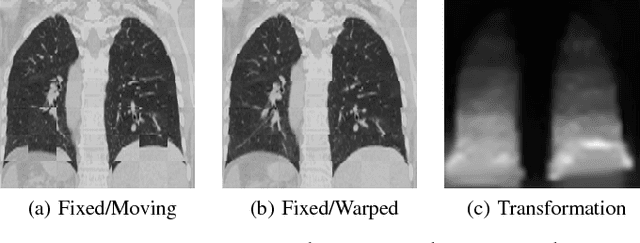
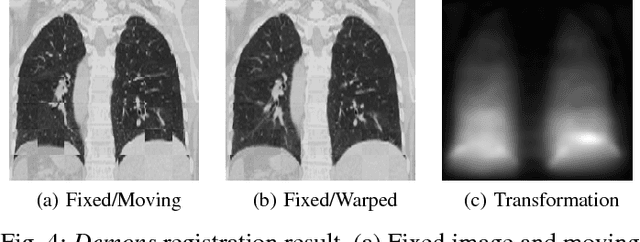
Medical image registration is an active research topic and forms a basis for many medical image analysis tasks. Although image registration is a rather general concept specialized methods are usually required to target a specific registration problem. The development and implementation of such methods has been tough so far as the gradient of the objective has to be computed. Also, its evaluation has to be performed preferably on a GPU for larger images and for more complex transformation models and regularization terms. This hinders researchers from rapid prototyping and poses hurdles to reproduce research results. There is a clear need for an environment which hides this complexity to put the modeling and the experimental exploration of registration methods into the foreground. With the "Autograd Image Registration Laboratory" (AirLab), we introduce an open laboratory for image registration tasks, where the analytic gradients of the objective function are computed automatically and the device where the computations are performed, on a CPU or a GPU, is transparent. It is meant as a laboratory for researchers and developers enabling them to rapidly try out new ideas for registering images and to reproduce registration results which have already been published. AirLab is implemented in Python using PyTorch as tensor and optimization library and SimpleITK for basic image IO. Therefore, it profits from recent advances made by the machine learning community concerning optimization and deep neural network models. The present draft of this paper roughly outlines AirLab with first code snippets and performance analyses. A more exhaustive introduction will follow as a final version soon.
Regional Image Perturbation Reduces $L_p$ Norms of Adversarial Examples While Maintaining Model-to-model Transferability
Jul 07, 2020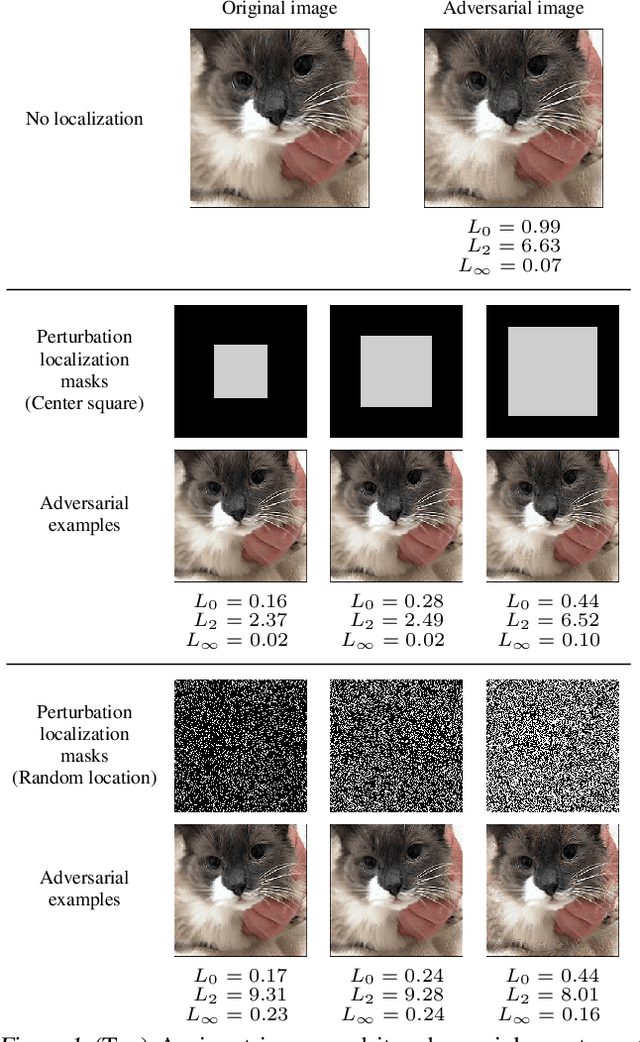
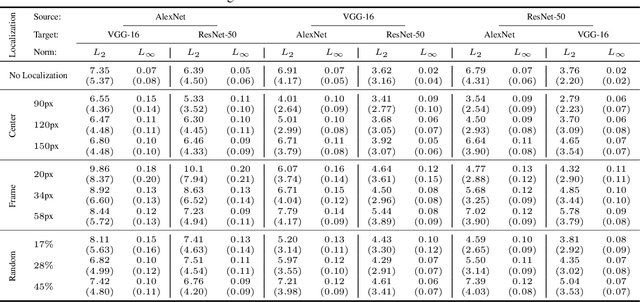

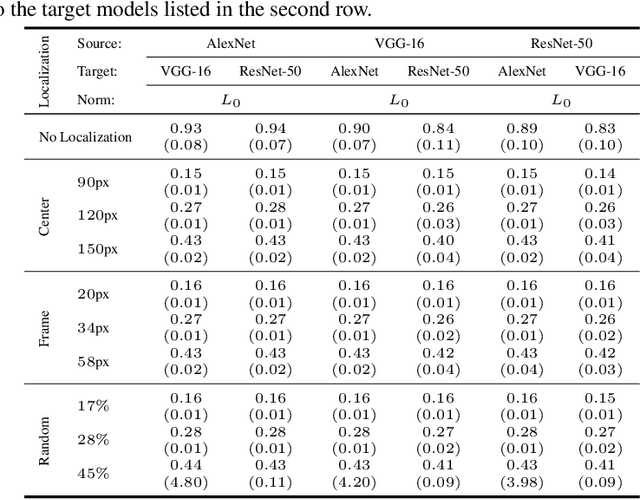
Regional adversarial attacks often rely on complicated methods for generating adversarial perturbations, making it hard to compare their efficacy against well-known attacks. In this study, we show that effective regional perturbations can be generated without resorting to complex methods. We develop a very simple regional adversarial perturbation attack method using cross-entropy sign, one of the most commonly used losses in adversarial machine learning. Our experiments on ImageNet with multiple models reveal that, on average, $76\%$ of the generated adversarial examples maintain model-to-model transferability when the perturbation is applied to local image regions. Depending on the selected region, these localized adversarial examples require significantly less $L_p$ norm distortion (for $p \in \{0, 2, \infty\}$) compared to their non-local counterparts. These localized attacks therefore have the potential to undermine defenses that claim robustness under the aforementioned norms.
Unsupervised learning of text line segmentation by differentiating coarse patterns
May 21, 2021

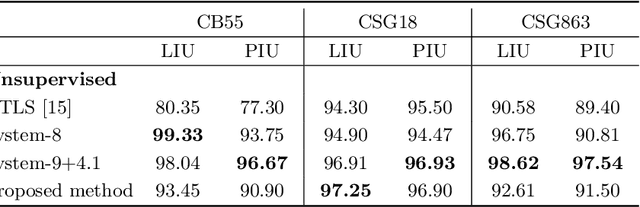
Despite recent advances in the field of supervised deep learning for text line segmentation, unsupervised deep learning solutions are beginning to gain popularity. In this paper, we present an unsupervised deep learning method that embeds document image patches to a compact Euclidean space where distances correspond to a coarse text line pattern similarity. Once this space has been produced, text line segmentation can be easily implemented using standard techniques with the embedded feature vectors. To train the model, we extract random pairs of document image patches with the assumption that neighbour patches contain a similar coarse trend of text lines, whereas if one of them is rotated, they contain different coarse trends of text lines. Doing well on this task requires the model to learn to recognize the text lines and their salient parts. The benefit of our approach is zero manual labelling effort. We evaluate the method qualitatively and quantitatively on several variants of text line segmentation datasets to demonstrate its effectivity.
Model-Based and Data-Driven Strategies in Medical Image Computing
Sep 24, 2019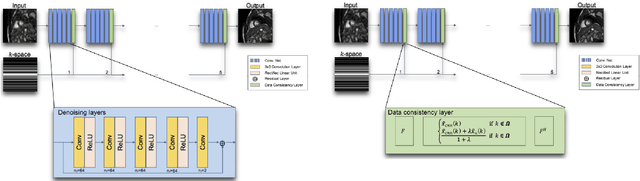
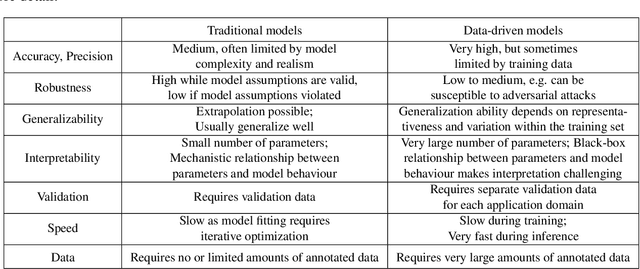
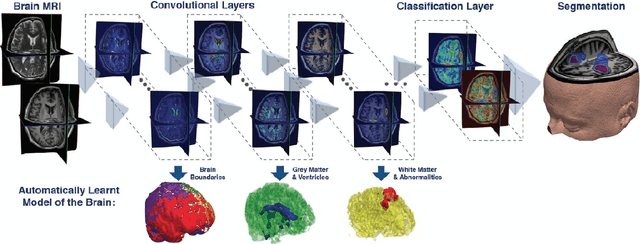
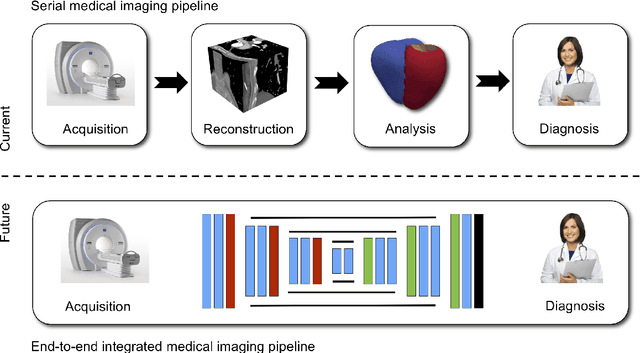
Model-based approaches for image reconstruction, analysis and interpretation have made significant progress over the last decades. Many of these approaches are based on either mathematical, physical or biological models. A challenge for these approaches is the modelling of the underlying processes (e.g. the physics of image acquisition or the patho-physiology of a disease) with appropriate levels of detail and realism. With the availability of large amounts of imaging data and machine learning (in particular deep learning) techniques, data-driven approaches have become more widespread for use in different tasks in reconstruction, analysis and interpretation. These approaches learn statistical models directly from labelled or unlabeled image data and have been shown to be very powerful for extracting clinically useful information from medical imaging. While these data-driven approaches often outperform traditional model-based approaches, their clinical deployment often poses challenges in terms of robustness, generalization ability and interpretability. In this article, we discuss what developments have motivated the shift from model-based approaches towards data-driven strategies and what potential problems are associated with the move towards purely data-driven approaches, in particular deep learning. We also discuss some of the open challenges for data-driven approaches, e.g. generalization to new unseen data (e.g. transfer learning), robustness to adversarial attacks and interpretability. Finally, we conclude with a discussion on how these approaches may lead to the development of more closely coupled imaging pipelines that are optimized in an end-to-end fashion.
Realistic River Image Synthesis using Deep Generative Adversarial Networks
Mar 03, 2020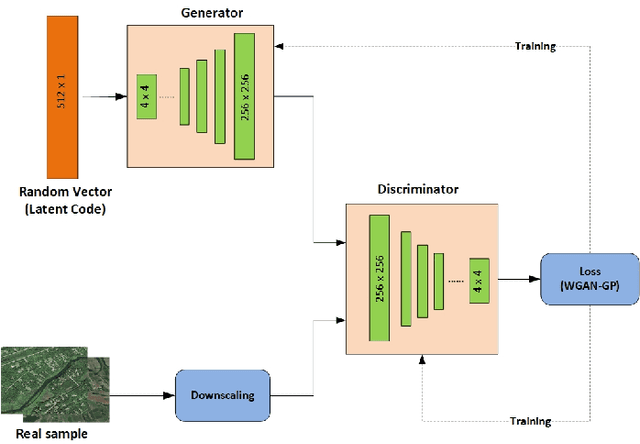


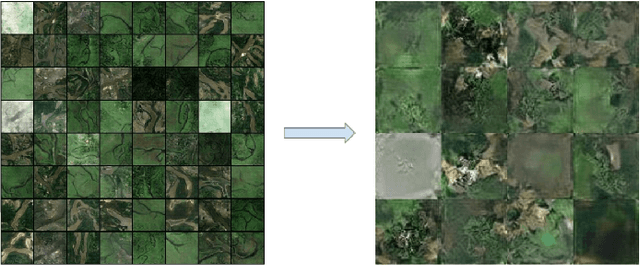
In this paper, we investigate an application of image generation for river satellite imagery. Specifically, we propose a generative adversarial network (GAN) model capable of generating high-resolution and realistic river images that can be used to support models in surface water estimation, river meandering, wetland loss and other hydrological research studies. First, we summarized an augmented, diverse repository of overhead river images to be used in training. Second, we incorporate the Progressive Growing GAN (PGGAN), a network architecture that iteratively trains smaller-resolution GANs to gradually build up to a very high resolution, to generate 256x256 river satellite imagery. With conventional GAN architectures, difficulties soon arise in terms of exponential increase of training time and vanishing/exploding gradient issues, which the PGGAN implementation seems to significantly reduce. Our preliminary results show great promise in capturing the detail of river flow and green areas present in river satellite images that can be used for supporting hydroinformatics studies.
Learning to Collocate Neural Modules for Image Captioning
Apr 18, 2019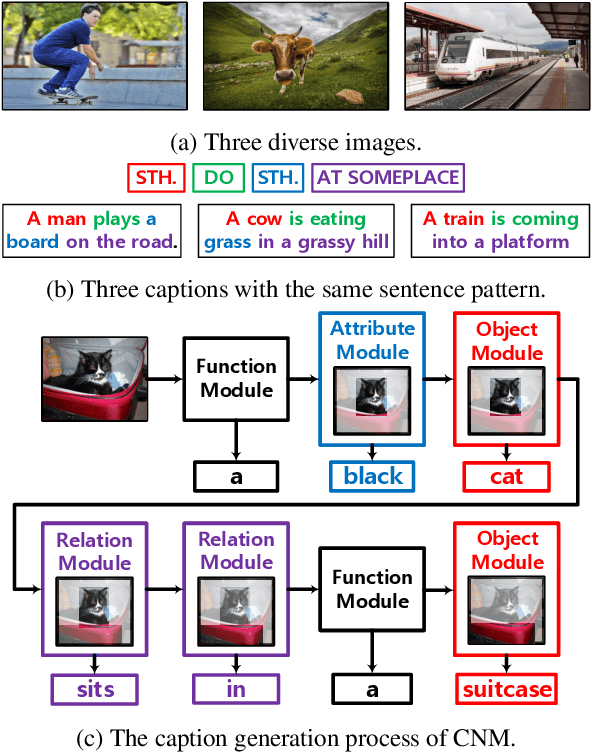
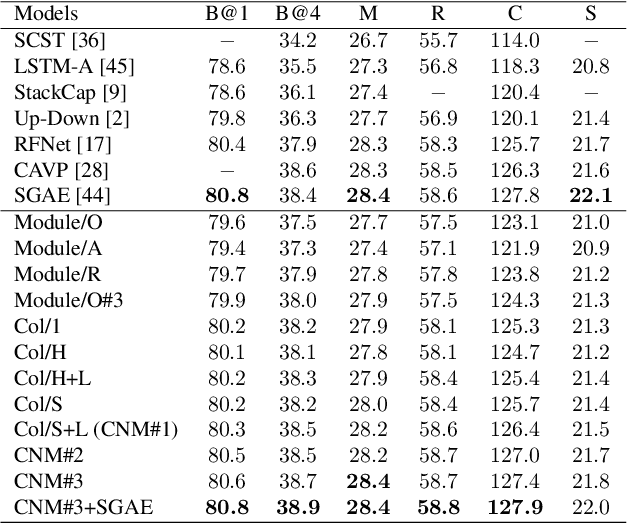

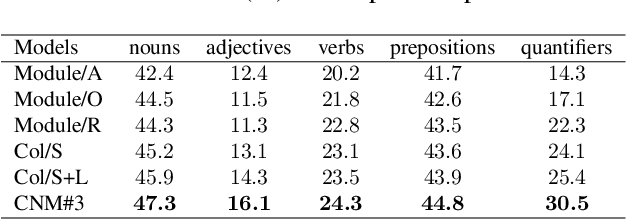
We do not speak word by word from scratch; our brain quickly structures a pattern like \textsc{sth do sth at someplace} and then fill in the detailed descriptions. To render existing encoder-decoder image captioners such human-like reasoning, we propose a novel framework: learning to Collocate Neural Modules (CNM), to generate the `inner pattern' connecting visual encoder and language decoder. Unlike the widely-used neural module networks in visual Q\&A, where the language (ie, question) is fully observable, CNM for captioning is more challenging as the language is being generated and thus is partially observable. To this end, we make the following technical contributions for CNM training: 1) compact module design --- one for function words and three for visual content words (eg, noun, adjective, and verb), 2) soft module fusion and multi-step module execution, robustifying the visual reasoning in partial observation, 3) a linguistic loss for module controller being faithful to part-of-speech collocations (eg, adjective is before noun). Extensive experiments on the challenging MS-COCO image captioning benchmark validate the effectiveness of our CNM image captioner. In particular, CNM achieves a new state-of-the-art 127.9 CIDEr-D on Karpathy split and a single-model 126.0 c40 on the official server. CNM is also robust to few training samples, eg, by training only one sentence per image, CNM can halve the performance loss compared to a strong baseline.
Rethinking BiSeNet For Real-time Semantic Segmentation
Apr 27, 2021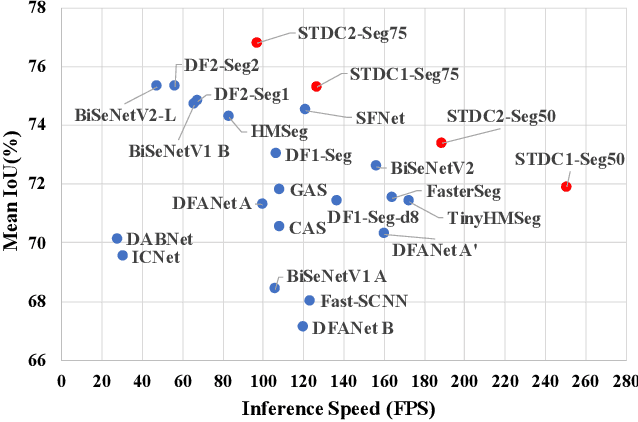
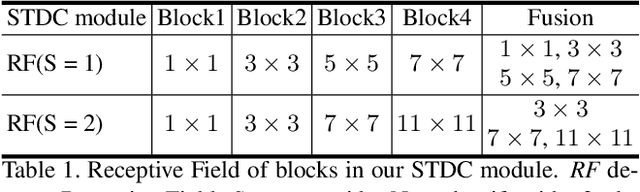
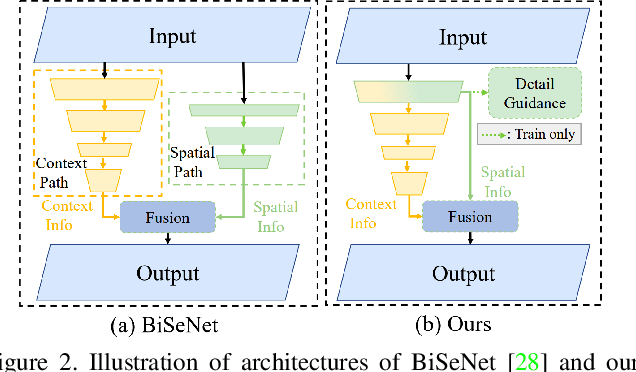
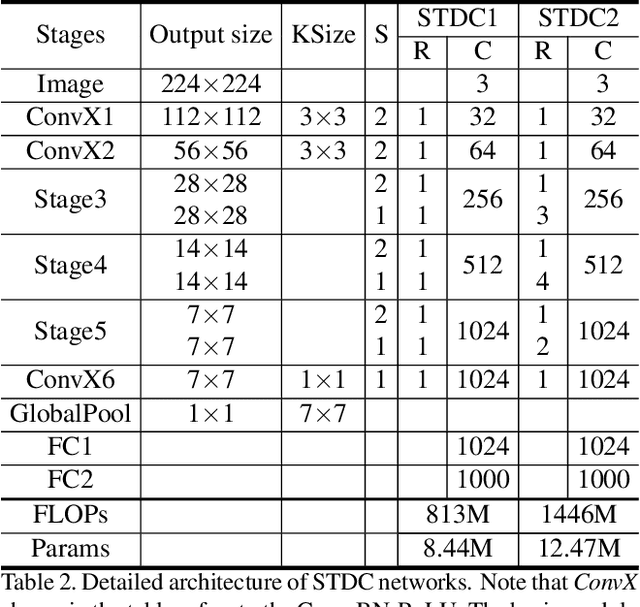
BiSeNet has been proved to be a popular two-stream network for real-time segmentation. However, its principle of adding an extra path to encode spatial information is time-consuming, and the backbones borrowed from pretrained tasks, e.g., image classification, may be inefficient for image segmentation due to the deficiency of task-specific design. To handle these problems, we propose a novel and efficient structure named Short-Term Dense Concatenate network (STDC network) by removing structure redundancy. Specifically, we gradually reduce the dimension of feature maps and use the aggregation of them for image representation, which forms the basic module of STDC network. In the decoder, we propose a Detail Aggregation module by integrating the learning of spatial information into low-level layers in single-stream manner. Finally, the low-level features and deep features are fused to predict the final segmentation results. Extensive experiments on Cityscapes and CamVid dataset demonstrate the effectiveness of our method by achieving promising trade-off between segmentation accuracy and inference speed. On Cityscapes, we achieve 71.9% mIoU on the test set with a speed of 250.4 FPS on NVIDIA GTX 1080Ti, which is 45.2% faster than the latest methods, and achieve 76.8% mIoU with 97.0 FPS while inferring on higher resolution images.
Mode Seeking Generative Adversarial Networks for Diverse Image Synthesis
Apr 03, 2019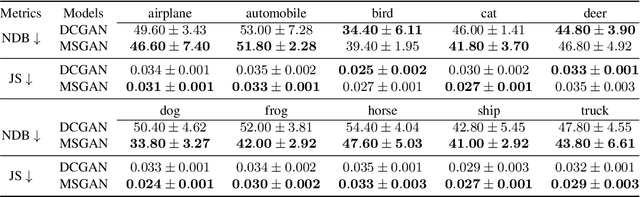
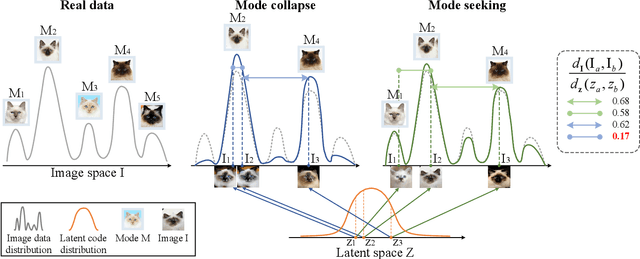

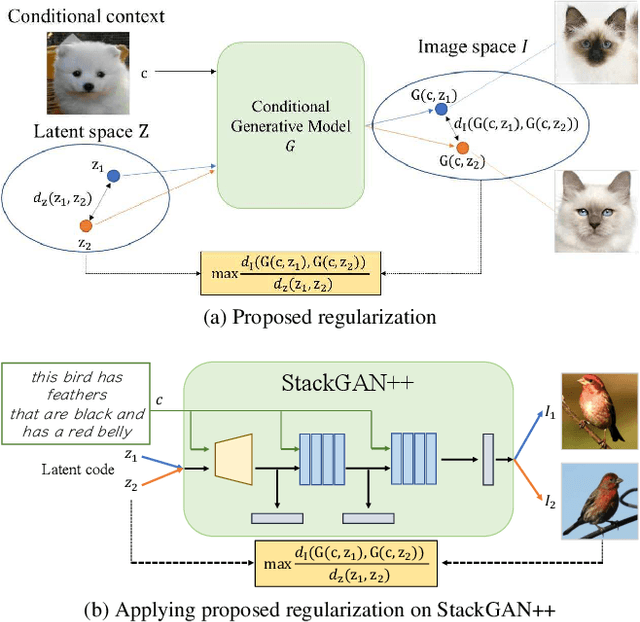
Most conditional generation tasks expect diverse outputs given a single conditional context. However, conditional generative adversarial networks (cGANs) often focus on the prior conditional information and ignore the input noise vectors, which contribute to the output variations. Recent attempts to resolve the mode collapse issue for cGANs are usually task-specific and computationally expensive. In this work, we propose a simple yet effective regularization term to address the mode collapse issue for cGANs. The proposed method explicitly maximizes the ratio of the distance between generated images with respect to the corresponding latent codes, thus encouraging the generators to explore more minor modes during training. This mode seeking regularization term is readily applicable to various conditional generation tasks without imposing training overhead or modifying the original network structures. We validate the proposed algorithm on three conditional image synthesis tasks including categorical generation, image-to-image translation, and text-to-image synthesis with different baseline models. Both qualitative and quantitative results demonstrate the effectiveness of the proposed regularization method for improving diversity without loss of quality.
Boosted Attention: Leveraging Human Attention for Image Captioning
Mar 18, 2019
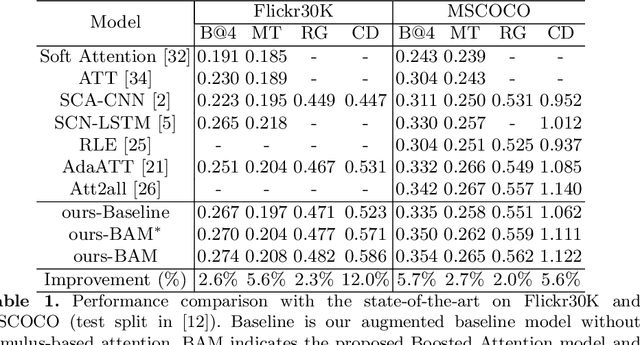

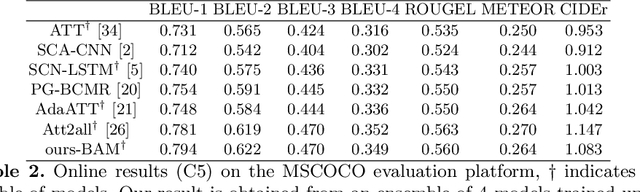
Visual attention has shown usefulness in image captioning, with the goal of enabling a caption model to selectively focus on regions of interest. Existing models typically rely on top-down language information and learn attention implicitly by optimizing the captioning objectives. While somewhat effective, the learned top-down attention can fail to focus on correct regions of interest without direct supervision of attention. Inspired by the human visual system which is driven by not only the task-specific top-down signals but also the visual stimuli, we in this work propose to use both types of attention for image captioning. In particular, we highlight the complementary nature of the two types of attention and develop a model (Boosted Attention) to integrate them for image captioning. We validate the proposed approach with state-of-the-art performance across various evaluation metrics.