 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Shared Certificates for Neural Network Verification
Sep 14, 2021
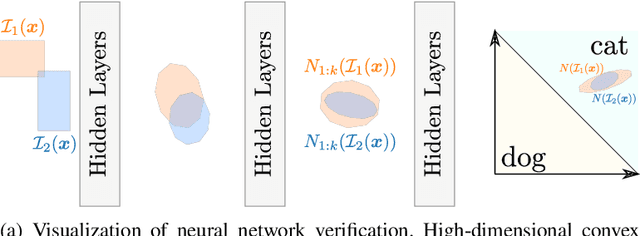

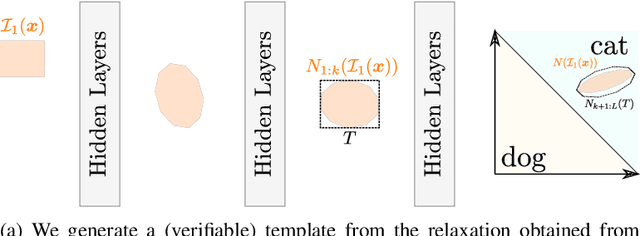
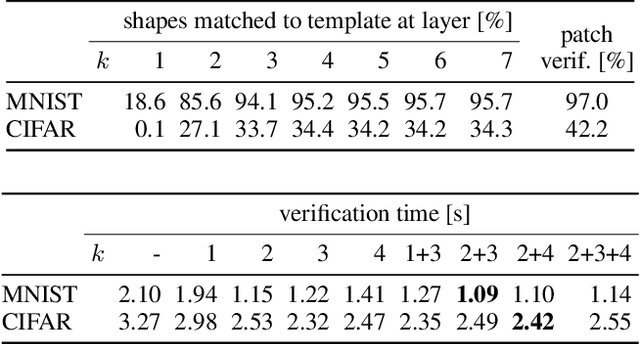
Existing neural network verifiers compute a proof that each input is handled correctly under a given perturbation by propagating a convex set of reachable values at each layer. This process is repeated independently for each input (e.g., image) and perturbation (e.g., rotation), leading to an expensive overall proof effort when handling an entire dataset. In this work we introduce a new method for reducing this verification cost based on the key insight that convex sets obtained at intermediate layers can overlap across different inputs and perturbations. Leveraging this insight, we introduce the general concept of shared certificates, enabling proof effort reuse across multiple inputs and driving down overall verification costs. We validate our insight via an extensive experimental evaluation and demonstrate the effectiveness of shared certificates on a range of datasets and attack specifications including geometric, patch and $\ell_\infty$ input perturbations.
Subspace Regularizers for Few-Shot Class Incremental Learning
Oct 13, 2021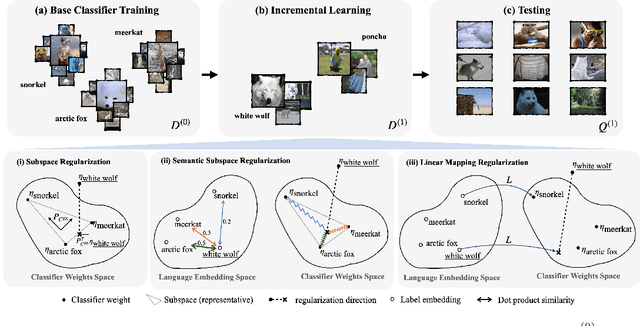
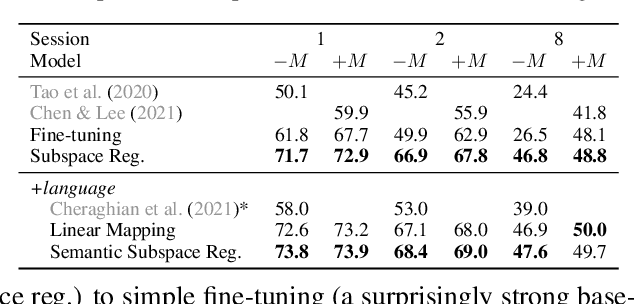
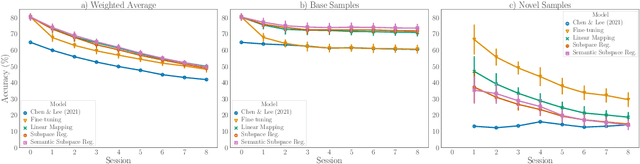
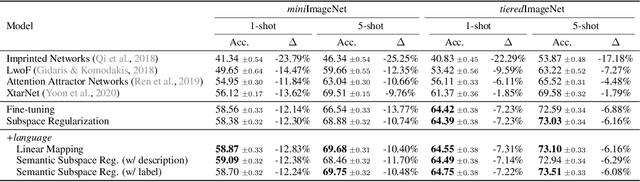
Few-shot class incremental learning -- the problem of updating a trained classifier to discriminate among an expanded set of classes with limited labeled data -- is a key challenge for machine learning systems deployed in non-stationary environments. Existing approaches to the problem rely on complex model architectures and training procedures that are difficult to tune and re-use. In this paper, we present an extremely simple approach that enables the use of ordinary logistic regression classifiers for few-shot incremental learning. The key to this approach is a new family of subspace regularization schemes that encourage weight vectors for new classes to lie close to the subspace spanned by the weights of existing classes. When combined with pretrained convolutional feature extractors, logistic regression models trained with subspace regularization outperform specialized, state-of-the-art approaches to few-shot incremental image classification by up to 22% on the miniImageNet dataset. Because of its simplicity, subspace regularization can be straightforwardly extended to incorporate additional background information about the new classes (including class names and descriptions specified in natural language); these further improve accuracy by up to 2%. Our results show that simple geometric regularization of class representations offers an effective tool for continual learning.
Mean Shift for Self-Supervised Learning
May 15, 2021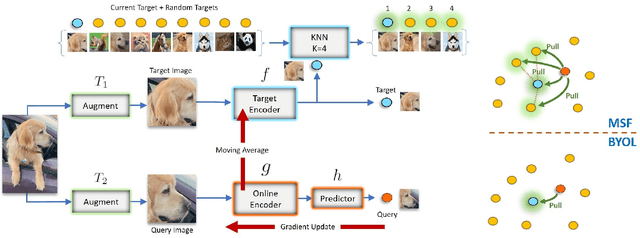
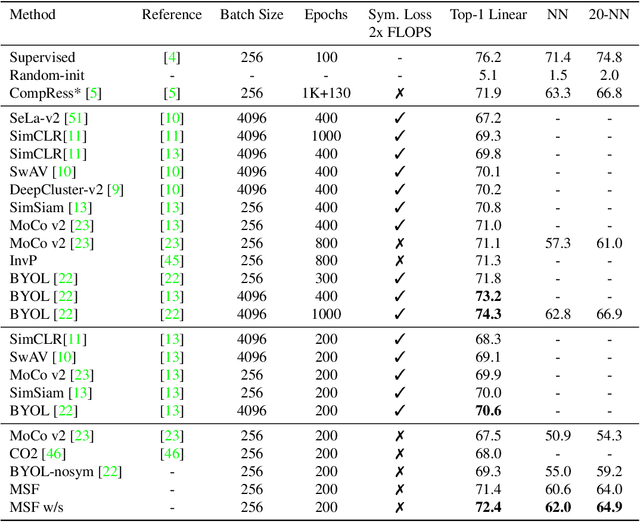

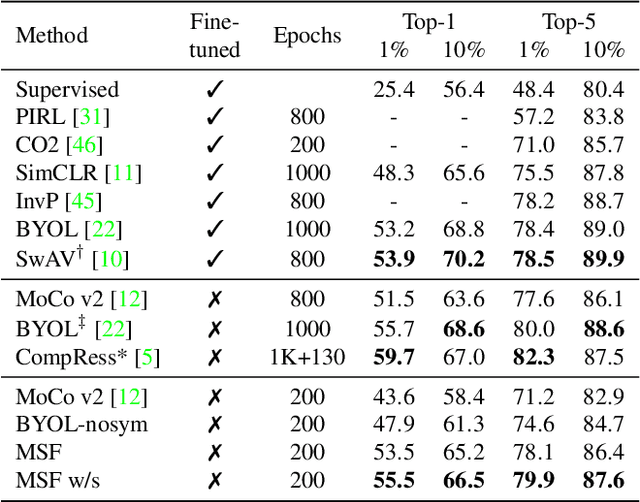
Most recent self-supervised learning (SSL) algorithms learn features by contrasting between instances of images or by clustering the images and then contrasting between the image clusters. We introduce a simple mean-shift algorithm that learns representations by grouping images together without contrasting between them or adopting much of prior on the structure of the clusters. We simply "shift" the embedding of each image to be close to the "mean" of its neighbors. Since in our setting, the closest neighbor is always another augmentation of the same image, our model will be identical to BYOL when using only one nearest neighbor instead of 5 as used in our experiments. Our model achieves 72.4% on ImageNet linear evaluation with ResNet50 at 200 epochs outperforming BYOL. Our code is available here: https://github.com/UMBCvision/MSF
Learning Global and Local Consistent Representations for Unsupervised Image Retrieval via Deep Graph Diffusion Networks
Jan 05, 2020
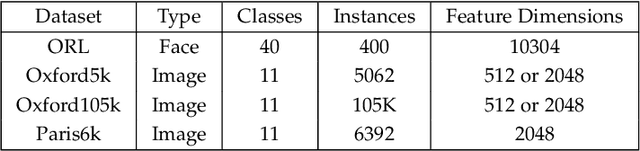


Diffusion has shown great success in improving accuracy of unsupervised image retrieval systems by utilizing high-order structures of image manifold. However, existing diffusion methods suffer from three major limitations: 1) they usually rely on local structures without considering global manifold information; 2) they focus on improving pair-wise similarities within existing images input output transductively while lacking flexibility to learn representations for novel unseen instances inductively; 3) they fail to scale to large datasets due to prohibitive memory consumption and computational burden due to intrinsic high-order operations on the whole graph. In this paper, to address these limitations, we propose a novel method,Graph Diffusion Networks (GRAD-Net), that adopts graph neural networks (GNNs), a novel variant of deep learning algorithms on irregular graphs. GRAD-Net learns semantic representations by exploiting both local and global structures of image manifold in an unsupervised fashion. By utilizing sparse coding techniques, GRAD-Net not only preserves global information on the image manifold, but also enables scalable training and efficient querying. Experiments on several large benchmark datasets demonstrate effectiveness of our method over state-of-the-art diffusion algorithms for unsupervised image retrieval.
Does Face Recognition Error Echo Gender Classification Error?
Apr 28, 2021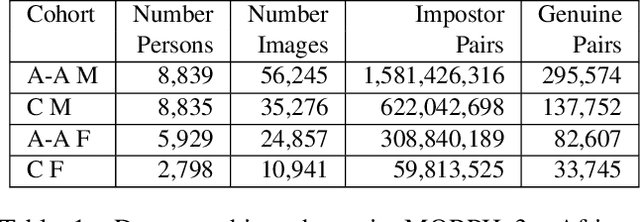

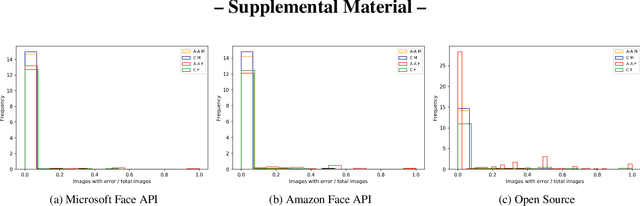
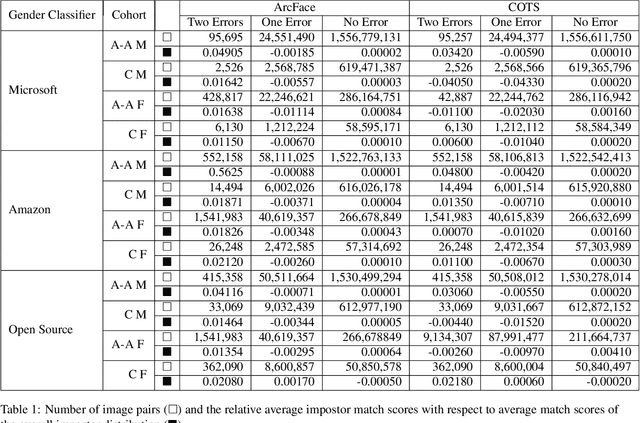
This paper is the first to explore the question of whether images that are classified incorrectly by a face analytics algorithm (e.g., gender classification) are any more or less likely to participate in an image pair that results in a face recognition error. We analyze results from three different gender classification algorithms (one open-source and two commercial), and two face recognition algorithms (one open-source and one commercial), on image sets representing four demographic groups (African-American female and male, Caucasian female and male). For impostor image pairs, our results show that pairs in which one image has a gender classification error have a better impostor distribution than pairs in which both images have correct gender classification, and so are less likely to generate a false match error. For genuine image pairs, our results show that individuals whose images have a mix of correct and incorrect gender classification have a worse genuine distribution (increased false non-match rate) compared to individuals whose images all have correct gender classification. Thus, compared to images that generate correct gender classification, images that generate gender classification errors do generate a different pattern of recognition errors, both better (false match) and worse (false non-match).
hidden markov random fields and cuckoo search method for medical image segmentation
May 19, 2020
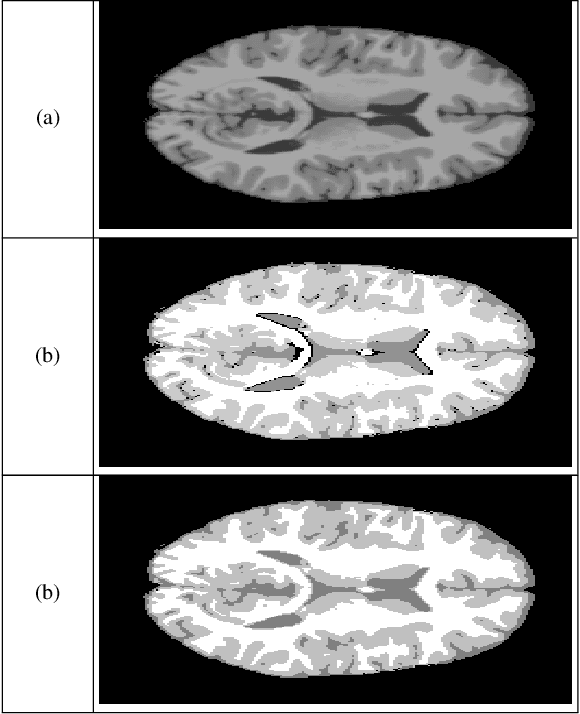
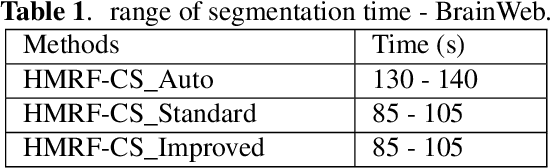

Segmentation of medical images is an essential part in the process of diagnostics. Physicians require an automatic, robust and valid results. Hidden Markov Random Fields (HMRF) provide powerful model. This latter models the segmentation problem as the minimization of an energy function. Cuckoo search (CS) algorithm is one of the recent nature-inspired meta-heuristic algorithms. It has shown its efficiency in many engineering optimization problems. In this paper, we use three cuckoo search algorithm to achieve medical image segmentation.
T6D-Direct: Transformers for Multi-Object 6D Pose Direct Regression
Sep 22, 2021
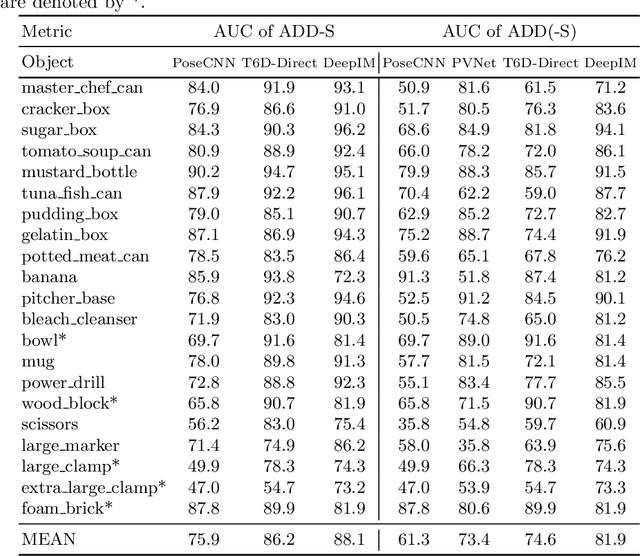
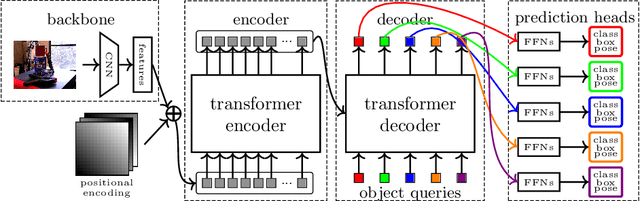
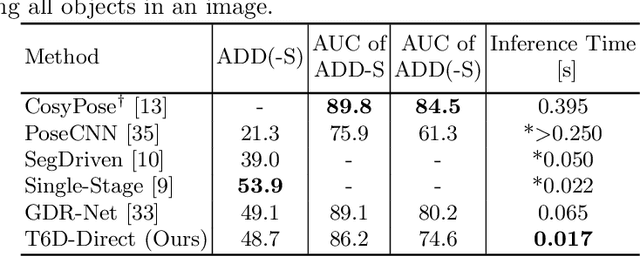
6D pose estimation is the task of predicting the translation and orientation of objects in a given input image, which is a crucial prerequisite for many robotics and augmented reality applications. Lately, the Transformer Network architecture, equipped with a multi-head self-attention mechanism, is emerging to achieve state-of-the-art results in many computer vision tasks. DETR, a Transformer-based model, formulated object detection as a set prediction problem and achieved impressive results without standard components like region of interest pooling, non-maximal suppression, and bounding box proposals. In this work, we propose T6D-Direct, a real-time single-stage direct method with a transformer-based architecture built on DETR to perform 6D multi-object pose direct estimation. We evaluate the performance of our method on the YCB-Video dataset. Our method achieves the fastest inference time, and the pose estimation accuracy is comparable to state-of-the-art methods.
SuperCaptioning: Image Captioning Using Two-dimensional Word Embedding
Jun 04, 2019
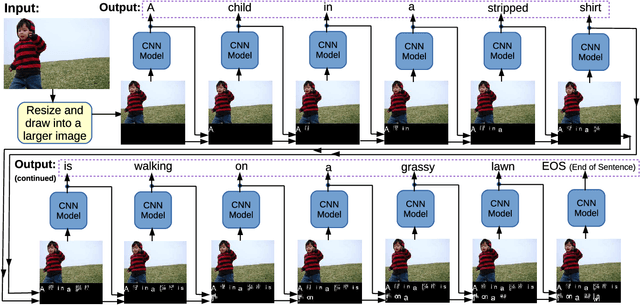
Language and vision are processed as two different modal in current work for image captioning. However, recent work on Super Characters method shows the effectiveness of two-dimensional word embedding, which converts text classification problem into image classification problem. In this paper, we propose the SuperCaptioning method, which borrows the idea of two-dimensional word embedding from Super Characters method, and processes the information of language and vision together in one single CNN model. The experimental results on Flickr30k data shows the proposed method gives high quality image captions. An interactive demo is ready to show at the workshop.
CAMPARI: Camera-Aware Decomposed Generative Neural Radiance Fields
Mar 31, 2021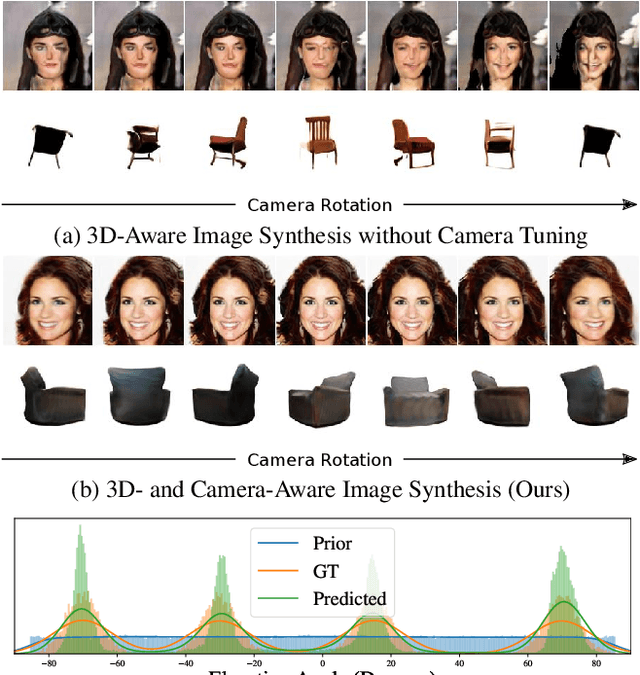
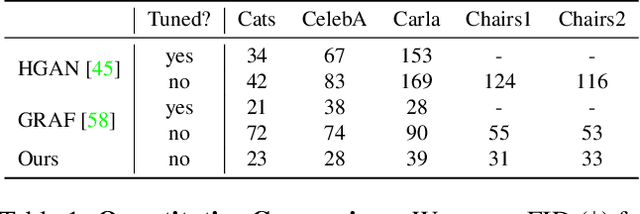
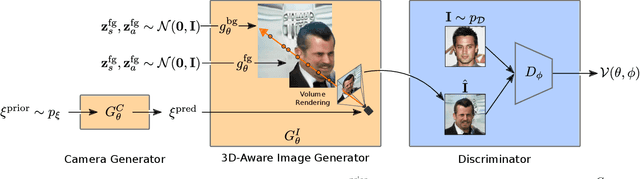

Tremendous progress in deep generative models has led to photorealistic image synthesis. While achieving compelling results, most approaches operate in the two-dimensional image domain, ignoring the three-dimensional nature of our world. Several recent works therefore propose generative models which are 3D-aware, i.e., scenes are modeled in 3D and then rendered differentiably to the image plane. This leads to impressive 3D consistency, but incorporating such a bias comes at a price: the camera needs to be modeled as well. Current approaches assume fixed intrinsics and a predefined prior over camera pose ranges. As a result, parameter tuning is typically required for real-world data, and results degrade if the data distribution is not matched. Our key hypothesis is that learning a camera generator jointly with the image generator leads to a more principled approach to 3D-aware image synthesis. Further, we propose to decompose the scene into a background and foreground model, leading to more efficient and disentangled scene representations. While training from raw, unposed image collections, we learn a 3D- and camera-aware generative model which faithfully recovers not only the image but also the camera data distribution. At test time, our model generates images with explicit control over the camera as well as the shape and appearance of the scene.
Multi-Contrast MRI Super-Resolution via a Multi-Stage Integration Network
May 19, 2021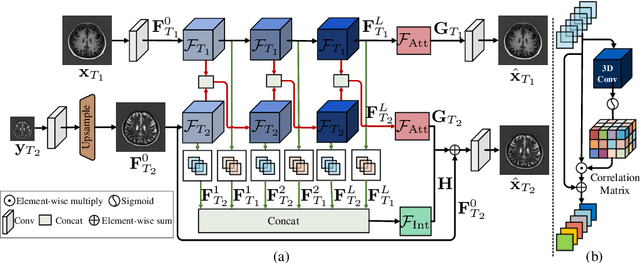
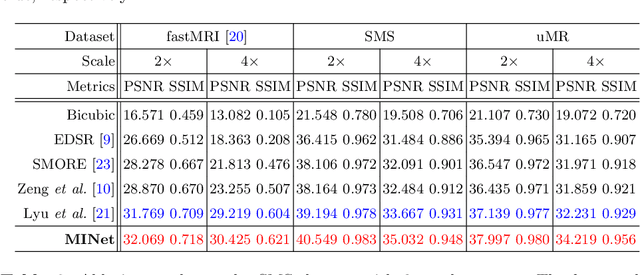
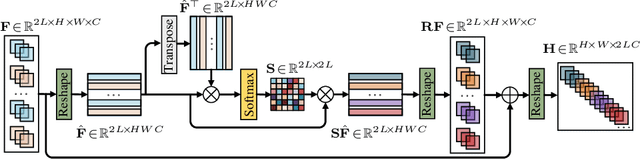
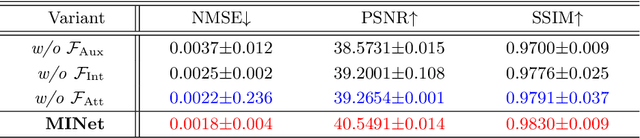
Super-resolution (SR) plays a crucial role in improving the image quality of magnetic resonance imaging (MRI). MRI produces multi-contrast images and can provide a clear display of soft tissues. However, current super-resolution methods only employ a single contrast, or use a simple multi-contrast fusion mechanism, ignoring the rich relations among different contrasts, which are valuable for improving SR. In this work, we propose a multi-stage integration network (i.e., MINet) for multi-contrast MRI SR, which explicitly models the dependencies between multi-contrast images at different stages to guide image SR. In particular, our MINet first learns a hierarchical feature representation from multiple convolutional stages for each of different-contrast image. Subsequently, we introduce a multi-stage integration module to mine the comprehensive relations between the representations of the multi-contrast images. Specifically, the module matches each representation with all other features, which are integrated in terms of their similarities to obtain an enriched representation. Extensive experiments on fastMRI and real-world clinical datasets demonstrate that 1) our MINet outperforms state-of-the-art multi-contrast SR methods in terms of various metrics and 2) our multi-stage integration module is able to excavate complex interactions among multi-contrast features at different stages, leading to improved target-image quality.