 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DRD-Net: Detail-recovery Image Deraining via Context Aggregation Networks
Aug 28, 2019


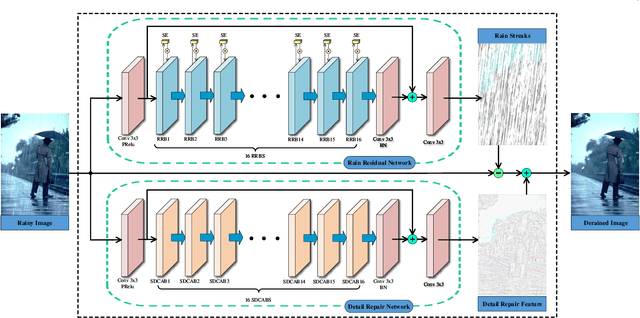
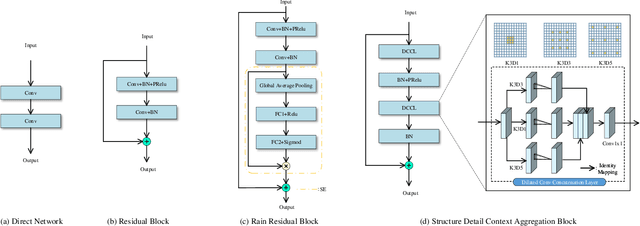
Image deraining is a fundamental, yet not well-solved problem in computer vision and graphics. The traditional image deraining approaches commonly behave ineffectively in medium and heavy rain removal, while the learning-based ones lead to image degradations such as the loss of image details, halo artifacts and/or color distortion. Unlike existing image deraining approaches that lack the detail-recovery mechanism, we propose an end-to-end detail-recovery image deraining network (termed a DRD-Net) for single images. We for the first time introduce two sub-networks with a comprehensive loss function which synergize to derain and recover the lost details caused by deraining. We have three key contributions. First, we present a rain residual network to remove rain streaks from the rainy images, which combines the squeeze-and-excitation (SE) operation with residual blocks to make full advantage of spatial contextual information. Second, we design a new connection style block, named structure detail context aggregation block (SDCAB), which aggregates context feature information and has a large reception field. Third, benefiting from the SDCAB, we construct a detail repair network to encourage the lost details to return for eliminating image degradations. We have validated our approach on four recognized datasets (three synthetic and one real-world). Both quantitative and qualitative comparisons show that our approach outperforms the state-of-the-art deraining methods in terms of the deraining robustness and detail accuracy. The source code has been available for public evaluation and use on GitHub.
Reliable Probability Intervals For Classification Using Inductive Venn Predictors Based on Distance Learning
Oct 07, 2021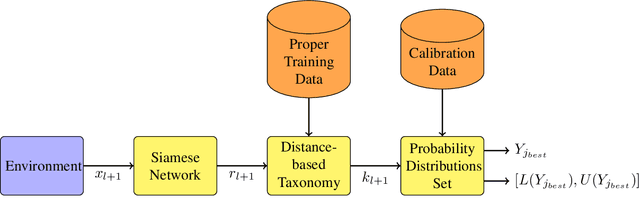
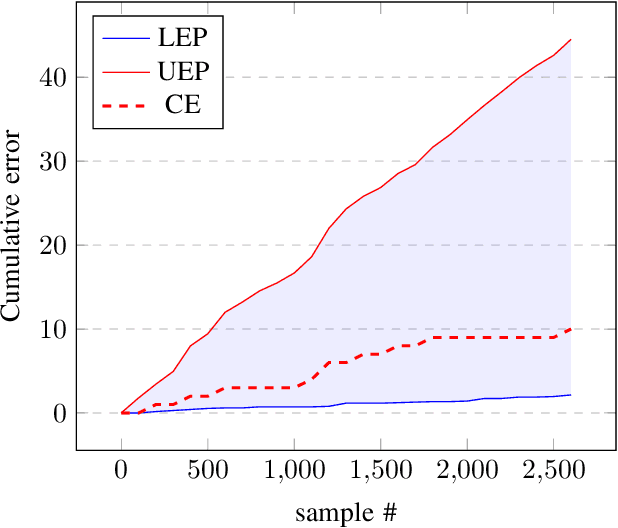

Deep neural networks are frequently used by autonomous systems for their ability to learn complex, non-linear data patterns and make accurate predictions in dynamic environments. However, their use as black boxes introduces risks as the confidence in each prediction is unknown. Different frameworks have been proposed to compute accurate confidence measures along with the predictions but at the same time introduce a number of limitations like execution time overhead or inability to be used with high-dimensional data. In this paper, we use the Inductive Venn Predictors framework for computing probability intervals regarding the correctness of each prediction in real-time. We propose taxonomies based on distance metric learning to compute informative probability intervals in applications involving high-dimensional inputs. Empirical evaluation on image classification and botnet attacks detection in Internet-of-Things (IoT) applications demonstrates improved accuracy and calibration. The proposed method is computationally efficient, and therefore, can be used in real-time.
* Published in IEEE International Conference on Omni-Layer Intelligent Systems (COINS), 2021
Crowdsourcing with Meta-Workers: A New Way to Save the Budget
Nov 07, 2021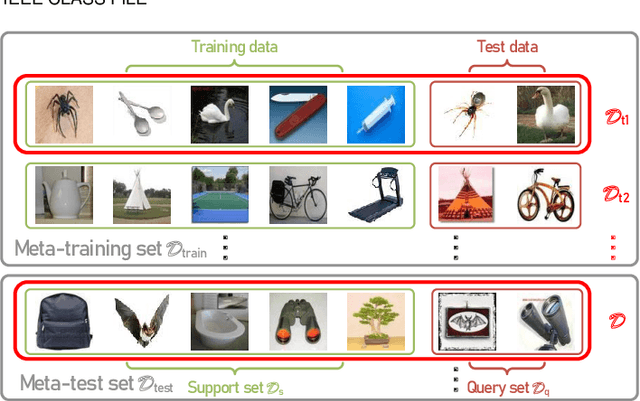
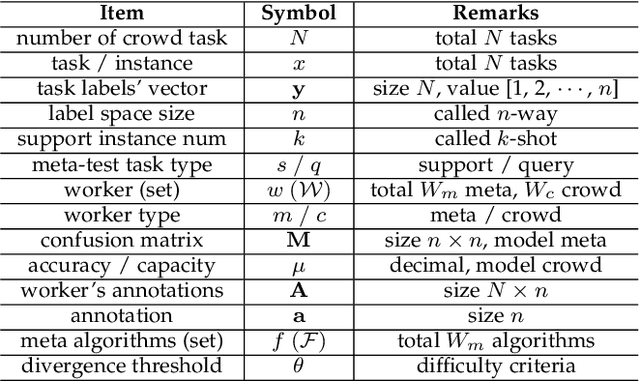
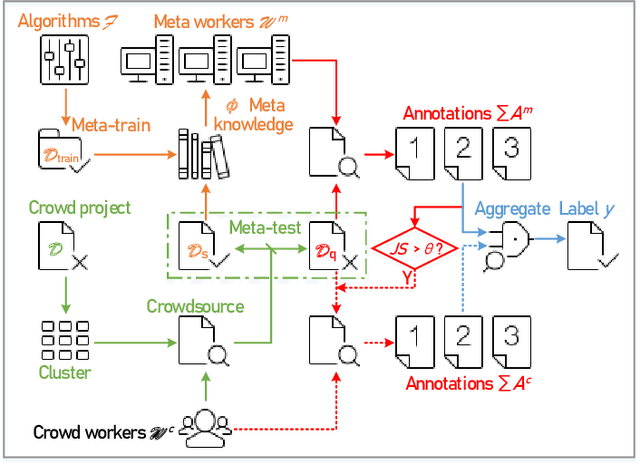

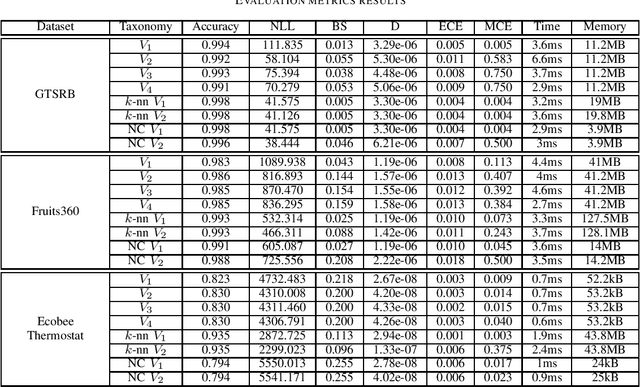
Due to the unreliability of Internet workers, it's difficult to complete a crowdsourcing project satisfactorily, especially when the tasks are multiple and the budget is limited. Recently, meta learning has brought new vitality to few-shot learning, making it possible to obtain a classifier with a fair performance using only a few training samples. Here we introduce the concept of \emph{meta-worker}, a machine annotator trained by meta learning for types of tasks (i.e., image classification) that are well-fit for AI. Unlike regular crowd workers, meta-workers can be reliable, stable, and more importantly, tireless and free. We first cluster unlabeled data and ask crowd workers to repeatedly annotate the instances nearby the cluster centers; we then leverage the annotated data and meta-training datasets to build a cluster of meta-workers using different meta learning algorithms. Subsequently, meta-workers are asked to annotate the remaining crowdsourced tasks. The Jensen-Shannon divergence is used to measure the disagreement among the annotations provided by the meta-workers, which determines whether or not crowd workers should be invited for further annotation of the same task. Finally, we model meta-workers' preferences and compute the consensus annotation by weighted majority voting. Our empirical study confirms that, by combining machine and human intelligence, we can accomplish a crowdsourcing project with a lower budget than state-of-the-art task assignment methods, while achieving a superior or comparable quality.
Who's Afraid of Adversarial Queries? The Impact of Image Modifications on Content-based Image Retrieval
Jan 29, 2019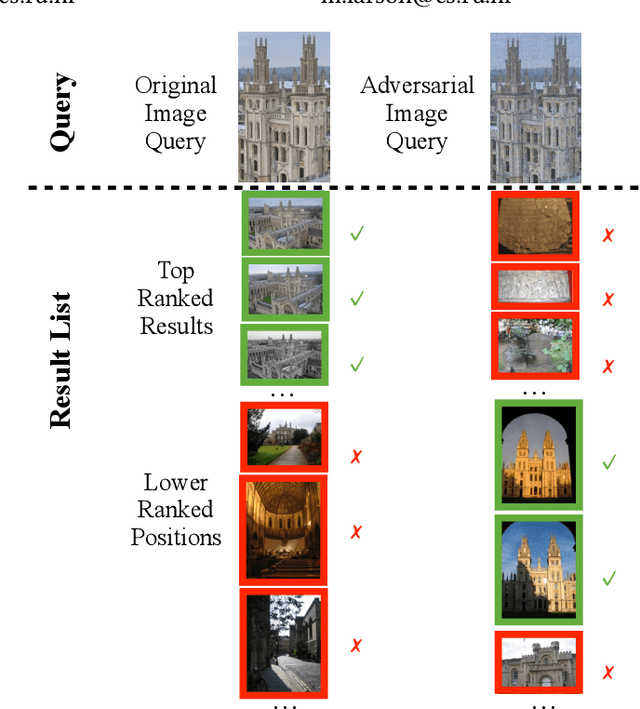
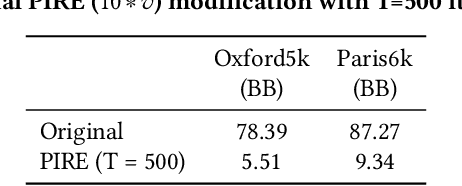
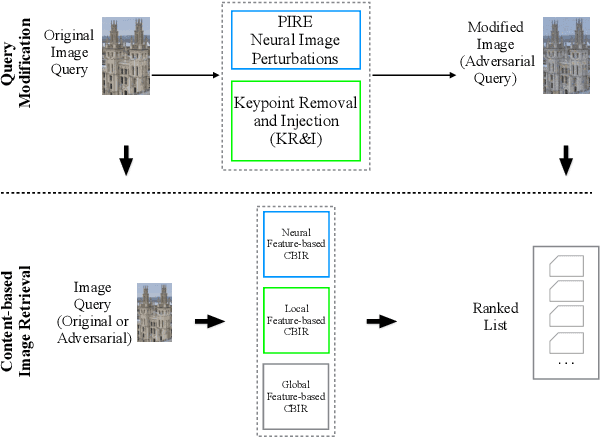
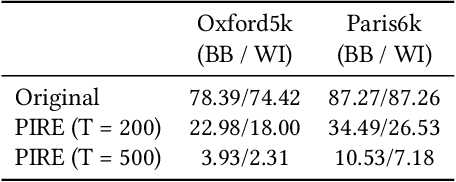
An adversarial query is an image that has been modified to disrupt content-based image retrieval (CBIR), while appearing nearly untouched to the human eye. This paper presents an analysis of adversarial queries for CBIR based on neural, local, and global features. We introduce an innovative neural image perturbation approach, called Perturbations for Image Retrieval Error (PIRE), that is capable of blocking neural-feature-based CBIR. To our knowledge PIRE is the first approach to creating neural adversarial examples for CBIR. PIRE differs significantly from existing approaches that create images adversarial with respect to CNN classifiers because it is unsupervised, i.e., it needs no labeled data from the data set to which it is applied. Our experimental analysis demonstrates the surprising effectiveness of PIRE in blocking CBIR, and also covers aspects of PIRE that must be taken into account in practical settings: saving images, image quality, image editing, and leaking adversarial queries into the background collection. Our experiments also compare PIRE (a neural approach) with existing keypoint removal and injection approaches (which modify local features). Finally, we discuss the challenges that face multimedia researchers in the future study of adversarial queries.
Data Augmentation for Scene Text Recognition
Aug 16, 2021


Scene text recognition (STR) is a challenging task in computer vision due to the large number of possible text appearances in natural scenes. Most STR models rely on synthetic datasets for training since there are no sufficiently big and publicly available labelled real datasets. Since STR models are evaluated using real data, the mismatch between training and testing data distributions results into poor performance of models especially on challenging text that are affected by noise, artifacts, geometry, structure, etc. In this paper, we introduce STRAug which is made of 36 image augmentation functions designed for STR. Each function mimics certain text image properties that can be found in natural scenes, caused by camera sensors, or induced by signal processing operations but poorly represented in the training dataset. When applied to strong baseline models using RandAugment, STRAug significantly increases the overall absolute accuracy of STR models across regular and irregular test datasets by as much as 2.10% on Rosetta, 1.48% on R2AM, 1.30% on CRNN, 1.35% on RARE, 1.06% on TRBA and 0.89% on GCRNN. The diversity and simplicity of API provided by STRAug functions enable easy replication and validation of existing data augmentation methods for STR. STRAug is available at https://github.com/roatienza/straug.
A Human Eye-based Text Color Scheme Generation Method for Image Synthesis
Oct 15, 2020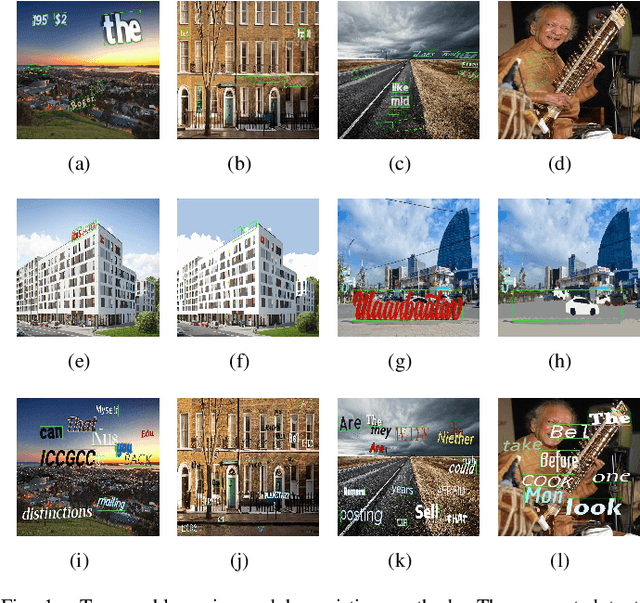
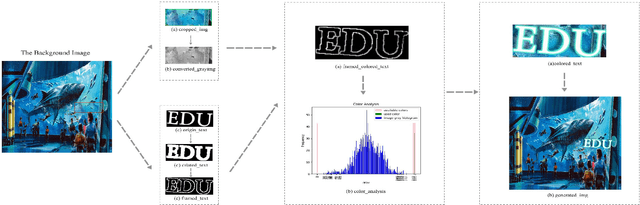
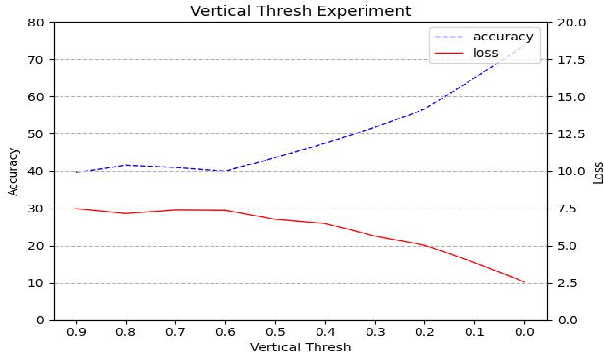

Synthetic data used for scene text detection and recognition tasks have proven effective. However, there are still two problems: First, the color schemes used for text coloring in the existing methods are relatively fixed color key-value pairs learned from real datasets. The dirty data in real datasets may cause the problem that the colors of text and background are too similar to be distinguished from each other. Second, the generated texts are uniformly limited to the same depth of a picture, while there are special cases in the real world that text may appear across depths. To address these problems, in this paper we design a novel method to generate color schemes, which are consistent with the characteristics of human eyes to observe things. The advantages of our method are as follows: (1) overcomes the color confusion problem between text and background caused by dirty data; (2) the texts generated are allowed to appear in most locations of any image, even across depths; (3) avoids analyzing the depth of background, such that the performance of our method exceeds the state-of-the-art methods; (4) the speed of generating images is fast, nearly one picture generated per three milliseconds. The effectiveness of our method is verified on several public datasets.
Do Images really do the Talking? Analysing the significance of Images in Tamil Troll meme classification
Aug 09, 2021

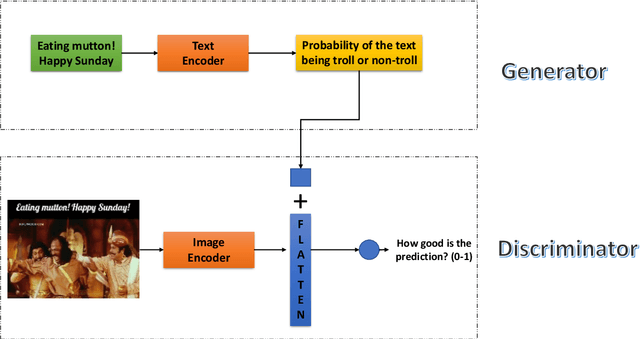
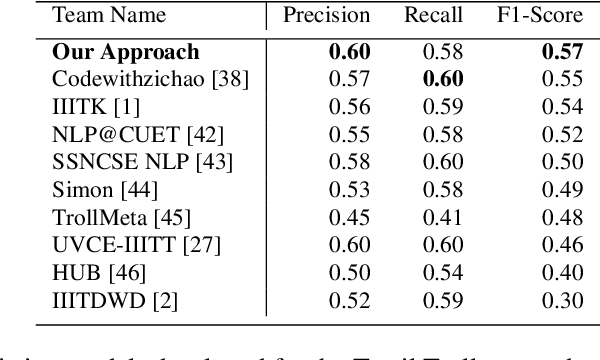
A meme is an part of media created to share an opinion or emotion across the internet. Due to its popularity, memes have become the new forms of communication on social media. However, due to its nature, they are being used in harmful ways such as trolling and cyberbullying progressively. Various data modelling methods create different possibilities in feature extraction and turning them into beneficial information. The variety of modalities included in data plays a significant part in predicting the results. We try to explore the significance of visual features of images in classifying memes. Memes are a blend of both image and text, where the text is embedded into the image. We try to incorporate the memes as troll and non-trolling memes based on the images and the text on them. However, the images are to be analysed and combined with the text to increase performance. Our work illustrates different textual analysis methods and contrasting multimodal methods ranging from simple merging to cross attention to utilising both worlds' - best visual and textual features. The fine-tuned cross-lingual language model, XLM, performed the best in textual analysis, and the multimodal transformer performs the best in multimodal analysis.
MFIF-GAN: A New Generative Adversarial Network for Multi-Focus Image Fusion
Sep 21, 2020
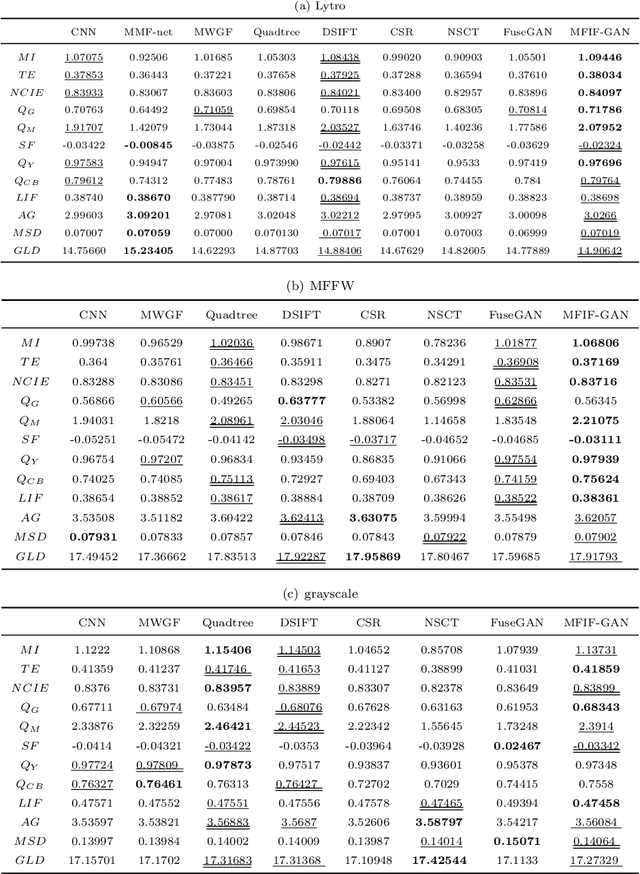

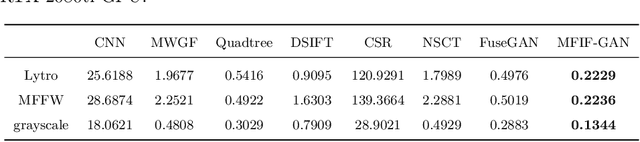
Multi-Focus Image Fusion (MFIF) is one of the promising techniques to obtain all-in-focus images to meet people's visual needs and it is a precondition of other computer vision tasks. One of the research trends of MFIF is to solve the defocus spread effect (DSE) around the focus/defocus boundary (FDB). In this paper, we present a novel generative adversarial network termed MFIF-GAN to translate multi-focus images into focus maps and to get the all-in-focus images further. The Squeeze and Excitation Residual Network (SE-ResNet) module as an attention mechanism is employed in the network. During the training, we propose reconstruction and gradient regularization loss functions to guarantee the accuracy of generated focus maps. In addition, by combining the prior knowledge of training conditon, this network is trained on a synthetic dataset with DSE by an {\alpha}-matte model. A series of experimental results demonstrate that the MFIF-GAN is superior to several representative state-of-the-art (SOTA) algorithms in visual perception, quantitative analysis as well as efficiency.
DiagSet: a dataset for prostate cancer histopathological image classification
May 09, 2021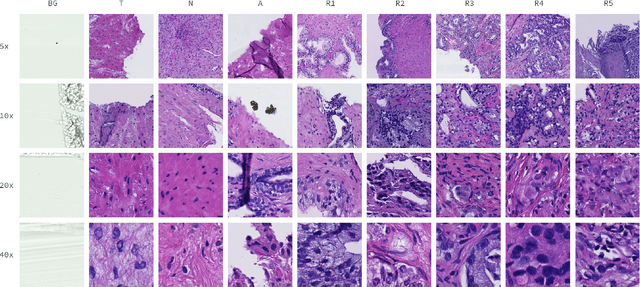

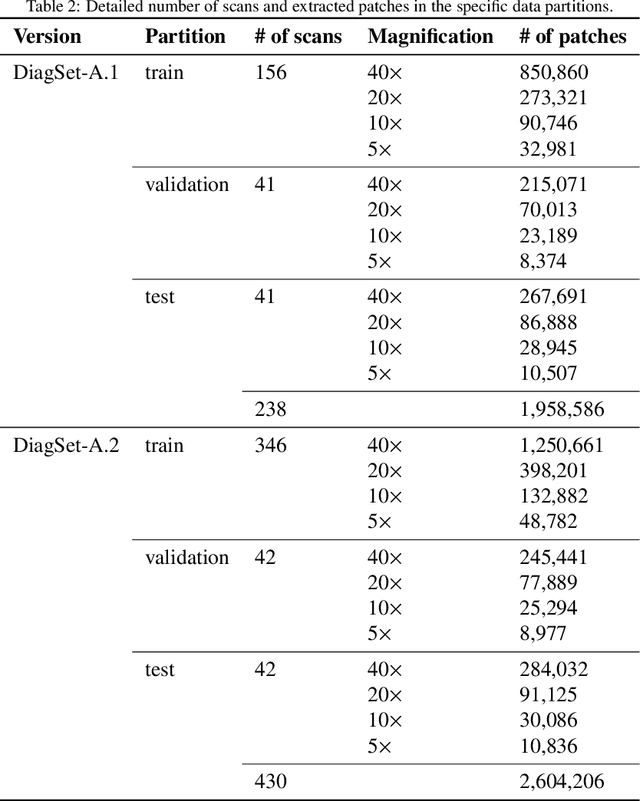
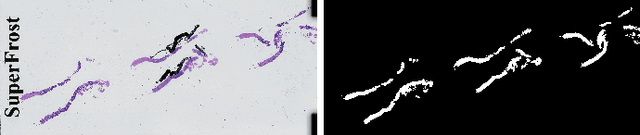
Cancer diseases constitute one of the most significant societal challenges. In this paper we introduce a novel histopathological dataset for prostate cancer detection. The proposed dataset, consisting of over 2.6 million tissue patches extracted from 430 fully annotated scans, 4675 scans with assigned binary diagnosis, and 46 scans with diagnosis given independently by a group of histopathologists, can be found at https://ai-econsilio.diag.pl. Furthermore, we propose a machine learning framework for detection of cancerous tissue regions and prediction of scan-level diagnosis, utilizing thresholding and statistical analysis to abstain from the decision in uncertain cases. During the experimental evaluation we identify several factors negatively affecting the performance of considered models, such as presence of label noise, data imbalance, and quantity of data, that can serve as a basis for further research. The proposed approach, composed of ensembles of deep neural networks operating on the histopathological scans at different scales, achieves 94.6% accuracy in patch-level recognition, and is compared in a scan-level diagnosis with 9 human histopathologists.
Edge Guided GANs with Semantic Preserving for Semantic Image Synthesis
Mar 31, 2020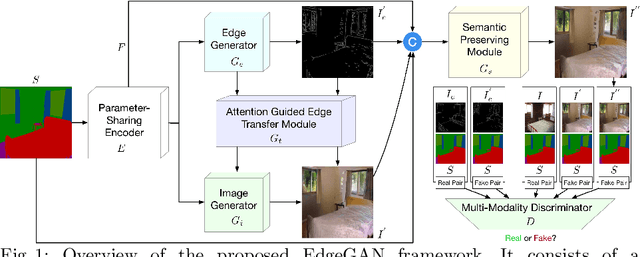
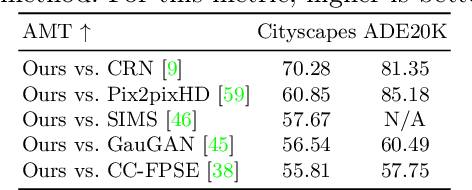
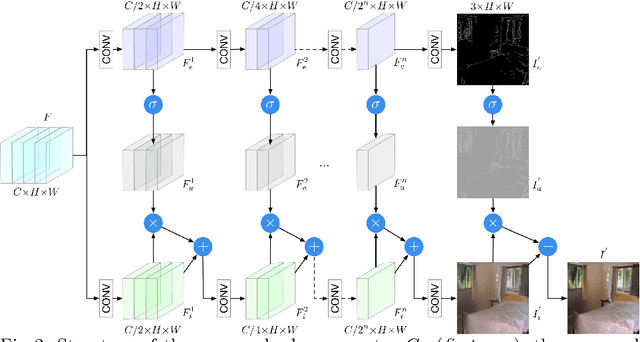
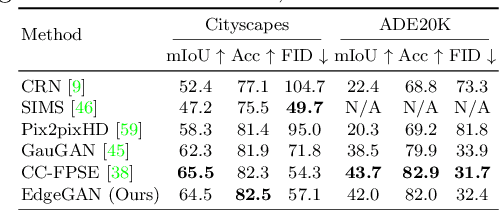
We propose a novel Edge guided Generative Adversarial Network (EdgeGAN) for photo-realistic image synthesis from semantic layouts. Although considerable improvement has been achieved, the quality of synthesized images is far from satisfactory due to two largely unresolved challenges. First, the semantic labels do not provide detailed structural information, making it difficult to synthesize local details and structures. Second, the widely adopted CNN operations such as convolution, down-sampling and normalization usually cause spatial resolution loss and thus are unable to fully preserve the original semantic information, leading to semantically inconsistent results (e.g., missing small objects). To tackle the first challenge, we propose to use the edge as an intermediate representation which is further adopted to guide image generation via a proposed attention guided edge transfer module. Edge information is produced by a convolutional generator and introduces detailed structure information. Further, to preserve the semantic information, we design an effective module to selectively highlight class-dependent feature maps according to the original semantic layout. Extensive experiments on two challenging datasets show that the proposed EdgeGAN can generate significantly better results than state-of-the-art methods. The source code and trained models are available at https://github.com/Ha0Tang/EdgeGAN.