 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Structured Denoising Diffusion Models in Discrete State-Spaces
Jul 13, 2021
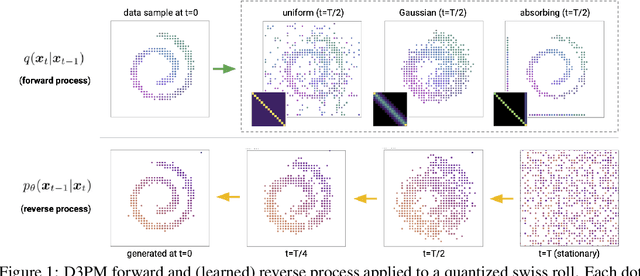
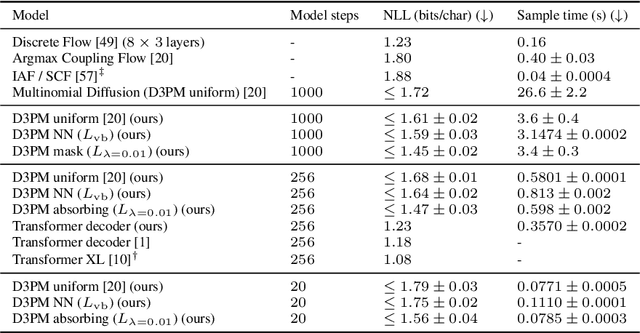

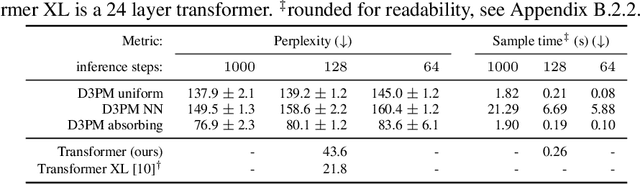
Denoising diffusion probabilistic models (DDPMs) (Ho et al. 2020) have shown impressive results on image and waveform generation in continuous state spaces. Here, we introduce Discrete Denoising Diffusion Probabilistic Models (D3PMs), diffusion-like generative models for discrete data that generalize the multinomial diffusion model of Hoogeboom et al. 2021, by going beyond corruption processes with uniform transition probabilities. This includes corruption with transition matrices that mimic Gaussian kernels in continuous space, matrices based on nearest neighbors in embedding space, and matrices that introduce absorbing states. The third allows us to draw a connection between diffusion models and autoregressive and mask-based generative models. We show that the choice of transition matrix is an important design decision that leads to improved results in image and text domains. We also introduce a new loss function that combines the variational lower bound with an auxiliary cross entropy loss. For text, this model class achieves strong results on character-level text generation while scaling to large vocabularies on LM1B. On the image dataset CIFAR-10, our models approach the sample quality and exceed the log-likelihood of the continuous-space DDPM model.
Diverse Generation from a Single Video Made Possible
Sep 17, 2021

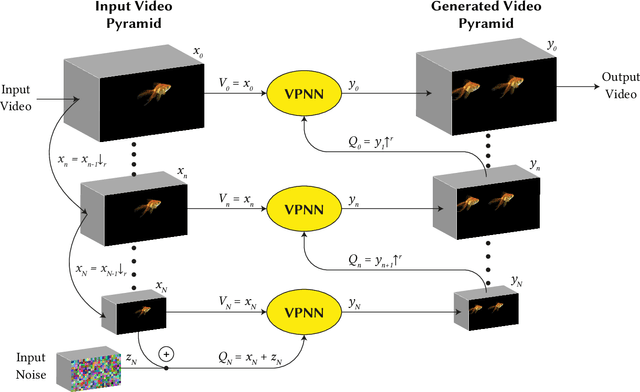
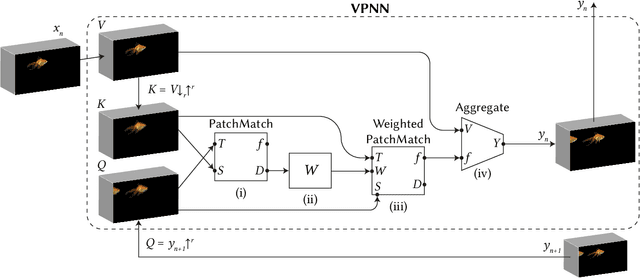
Most advanced video generation and manipulation methods train on a large collection of videos. As such, they are restricted to the types of video dynamics they train on. To overcome this limitation, GANs trained on a single video were recently proposed. While these provide more flexibility to a wide variety of video dynamics, they require days to train on a single tiny input video, rendering them impractical. In this paper we present a fast and practical method for video generation and manipulation from a single natural video, which generates diverse high-quality video outputs within seconds (for benchmark videos). Our method can be further applied to Full-HD video clips within minutes. Our approach is inspired by a recent advanced patch-nearest-neighbor based approach [Granot et al. 2021], which was shown to significantly outperform single-image GANs, both in run-time and in visual quality. Here we generalize this approach from images to videos, by casting classical space-time patch-based methods as a new generative video model. We adapt the generative image patch nearest neighbor approach to efficiently cope with the huge number of space-time patches in a single video. Our method generates more realistic and higher quality results than single-video GANs (confirmed by quantitative and qualitative evaluations). Moreover, it is disproportionally faster (runtime reduced from several days to seconds). Other than diverse video generation, we demonstrate several other challenging video applications, including spatio-temporal video retargeting, video structural analogies and conditional video-inpainting.
Noise and dose reduction in CT brain perfusion acquisition by projecting time attenuation curves onto lower dimensional spaces
Nov 02, 2021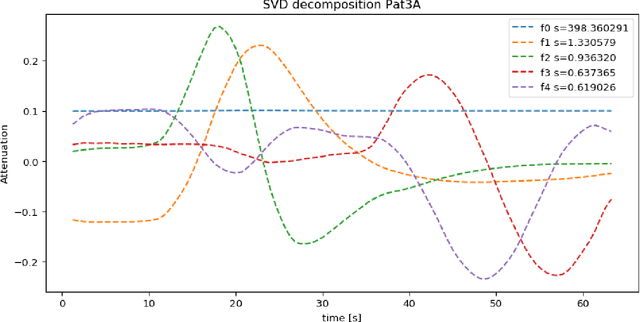
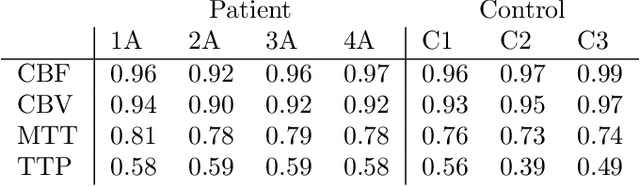
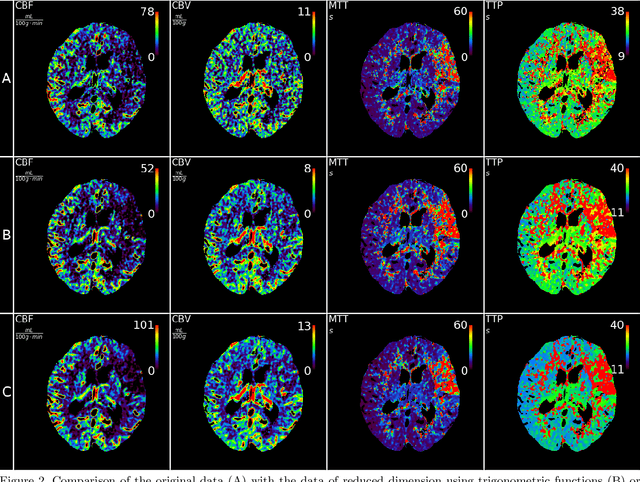

CT perfusion imaging (CTP) plays an important role in decision making for the treatment of acute ischemic stroke with large vessel occlusion. Since the CT perfusion scan time is approximately one minute, the patient is exposed to a non-negligible dose of ionizing radiation. However, further dose reduction increases the level of noise in the data and the resulting perfusion maps. We present a method for reducing noise in perfusion data based on dimension reduction of time attenuation curves. For dimension reduction, we use either the fit of the first five terms of the trigonometric polynomial or the first five terms of the SVD decomposition of the time attenuation profiles. CTP data from four patients with large vessel occlusion and three control subjects were studied. To compare the noise level in the perfusion maps, we use the wavelet estimation of the noise standard deviation implemented in the scikit-image package. We show that both methods significantly reduce noise in the data while preserving important information about the perfusion deficits. These methods can be used to further reduce the dose in CT perfusion protocols or in perfusion studies using C-arm CT, which are burdened by high noise levels.
Self-Supervised Fine-tuning for Image Enhancement of Super-Resolution Deep Neural Networks
Dec 30, 2019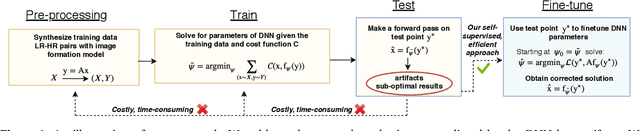



While Deep Neural Networks (DNNs) trained for image and video super-resolution regularly achieve new state-of-the-art performance, they also suffer from significant drawbacks. One of their limitations is their tendency to generate strong artifacts in their solution. This may occur when the low-resolution image formation model does not match that seen during training. Artifacts also regularly arise when training Generative Adversarial Networks for inverse imaging problems. In this paper, we propose an efficient, fully self-supervised approach to remove the observed artifacts. More specifically, at test time, given an image and its known image formation model, we fine-tune the parameters of the trained network and iteratively update them using a data consistency loss. We apply our method to image and video super-resolution neural networks and show that our proposed framework consistently enhances the solution originally provided by the neural network.
Superpixel Image Classification with Graph Attention Networks
Feb 13, 2020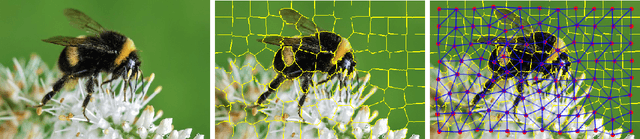
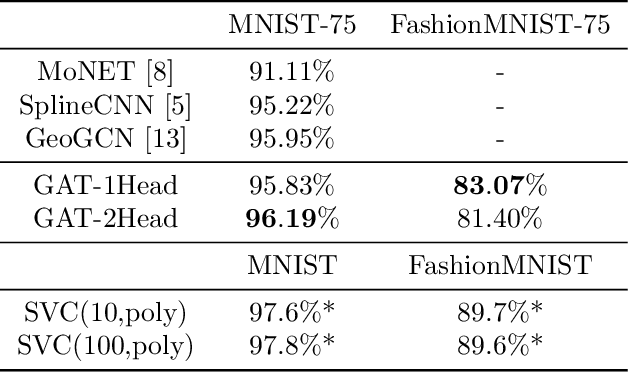
This document reports the use of Graph Attention Networks for classifying oversegmented images, as well as a general procedure for generating oversegmented versions of image-based datasets. The code and learnt models for/from the experiments are available on github. The experiments were ran from June 2019 until December 2019. We obtained better results than the baseline models that uses geometric distance-based attention by using instead self attention, in a more sparsely connected graph network.
Text-to-image synthesis method evaluation based on visual patterns
Oct 31, 2019
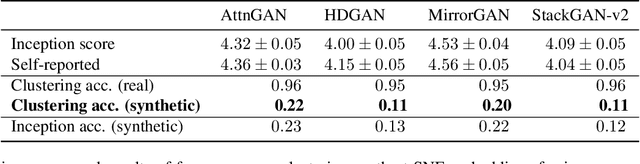
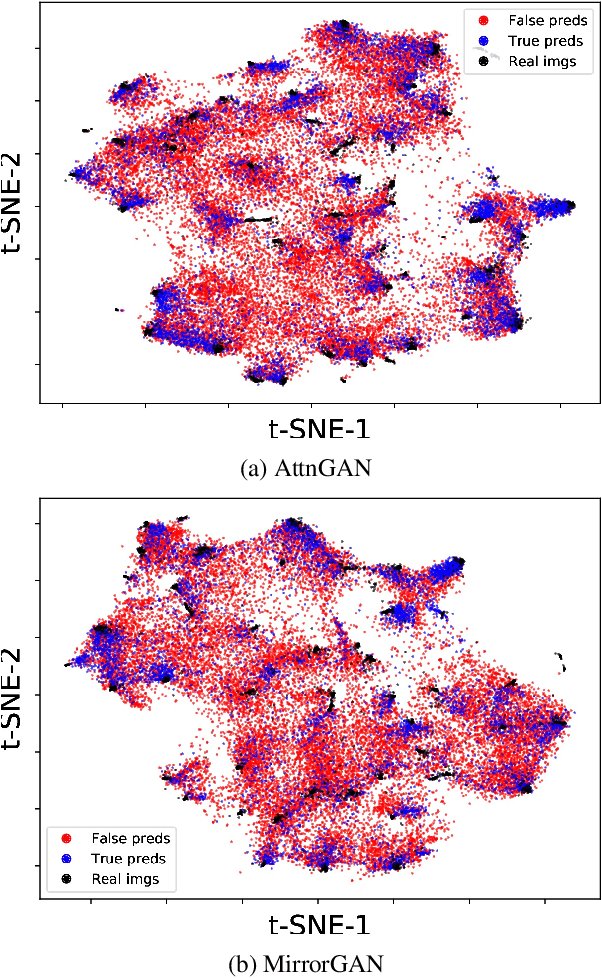
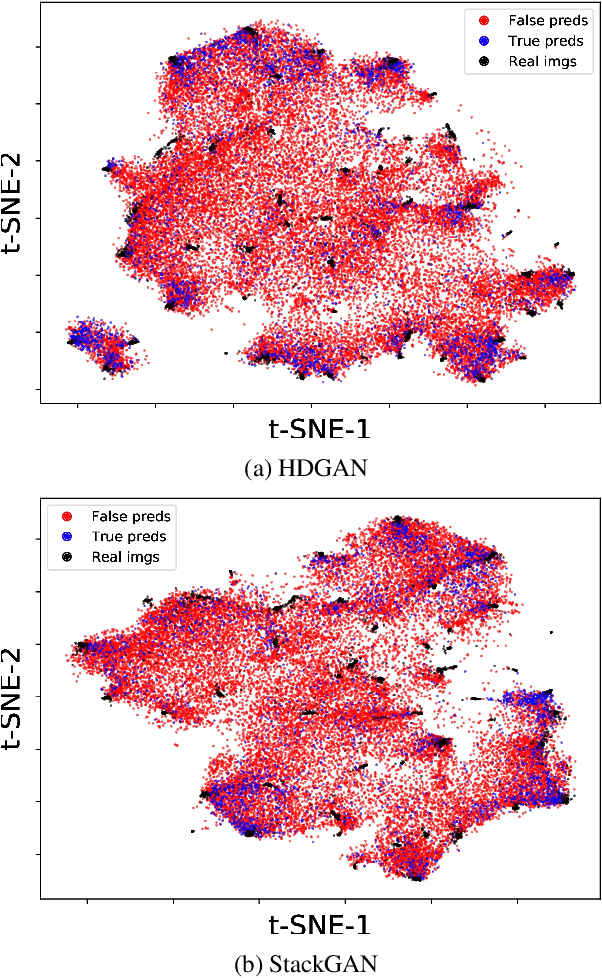
A commonly used evaluation metric for text-to-image synthesis is the Inception score (IS) \cite{inceptionscore}, which has been shown to be a quality metric that correlates well with human judgment. However, IS does not reveal properties of the generated images indicating the ability of a text-to-image synthesis method to correctly convey semantics of the input text descriptions. In this paper, we introduce an evaluation metric and a visual evaluation method allowing for the simultaneous estimation of the realism, variety and semantic accuracy of generated images. The proposed method uses a pre-trained Inception network \cite{inceptionnet} to produce high dimensional representations for both real and generated images. These image representations are then visualized in a $2$-dimensional feature space defined by the t-distributed Stochastic Neighbor Embedding (t-SNE) \cite{tsne}. Visual concepts are determined by clustering the real image representations, and are subsequently used to evaluate the similarity of the generated images to the real ones by classifying them to the closest visual concept. The resulting classification accuracy is shown to be a effective gauge for the semantic accuracy of text-to-image synthesis methods.
TESDA: Transform Enabled Statistical Detection of Attacks in Deep Neural Networks
Oct 16, 2021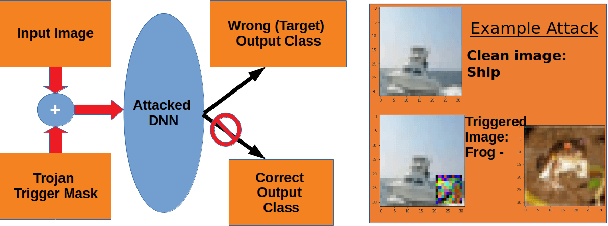
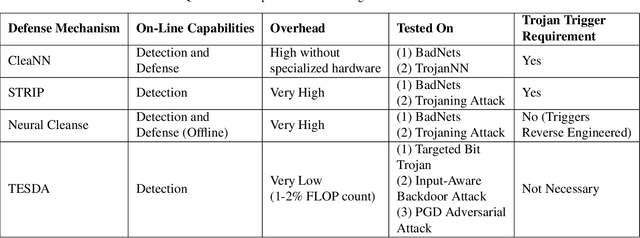
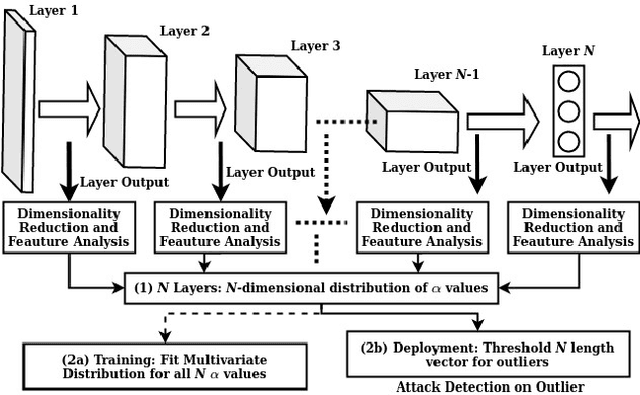
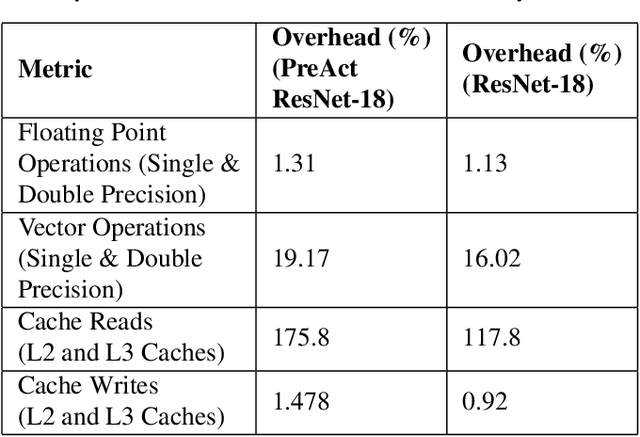
Deep neural networks (DNNs) are now the de facto choice for computer vision tasks such as image classification. However, their complexity and "black box" nature often renders the systems they're deployed in vulnerable to a range of security threats. Successfully identifying such threats, especially in safety-critical real-world applications is thus of utmost importance, but still very much an open problem. We present TESDA, a low-overhead, flexible, and statistically grounded method for {online detection} of attacks by exploiting the discrepancies they cause in the distributions of intermediate layer features of DNNs. Unlike most prior work, we require neither dedicated hardware to run in real-time, nor the presence of a Trojan trigger to detect discrepancies in behavior. We empirically establish our method's usefulness and practicality across multiple architectures, datasets and diverse attacks, consistently achieving detection coverages of above 95% with operation count overheads as low as 1-2%.
CTSpine1K: A Large-Scale Dataset for Spinal Vertebrae Segmentation in Computed Tomography
Jun 10, 2021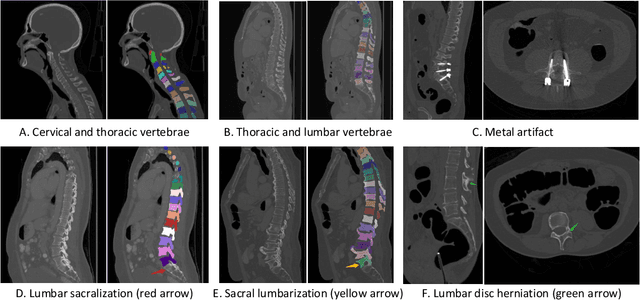

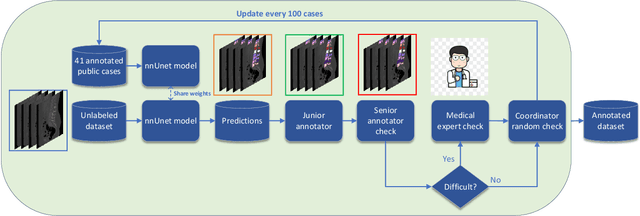
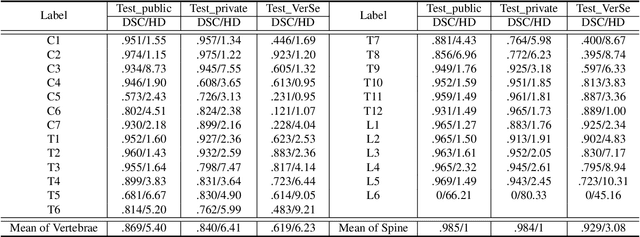
Spine-related diseases have high morbidity and cause a huge burden of social cost. Spine imaging is an essential tool for noninvasively visualizing and assessing spinal pathology. Segmenting vertebrae in computed tomography (CT) images is the basis of quantitative medical image analysis for clinical diagnosis and surgery planning of spine diseases. Current publicly available annotated datasets on spinal vertebrae are small in size. Due to the lack of a large-scale annotated spine image dataset, the mainstream deep learning-based segmentation methods, which are data-driven, are heavily restricted. In this paper, we introduce a large-scale spine CT dataset, called CTSpine1K, curated from multiple sources for vertebra segmentation, which contains 1,005 CT volumes with over 11,100 labeled vertebrae belonging to different spinal conditions. Based on this dataset, we conduct several spinal vertebrae segmentation experiments to set the first benchmark. We believe that this large-scale dataset will facilitate further research in many spine-related image analysis tasks, including but not limited to vertebrae segmentation, labeling, 3D spine reconstruction from biplanar radiographs, image super-resolution, and enhancement.
Momentum Contrastive Autoencoder: Using Contrastive Learning for Latent Space Distribution Matching in WAE
Oct 19, 2021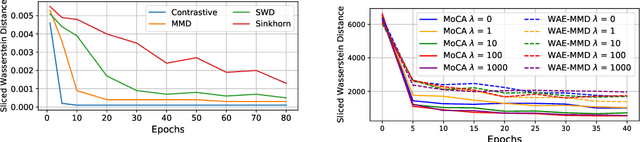
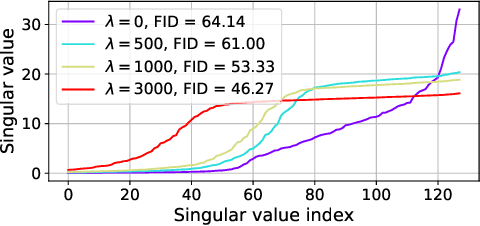
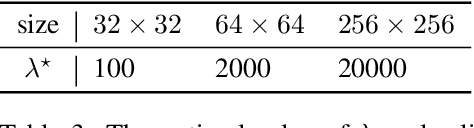
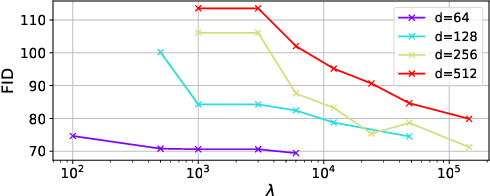
Wasserstein autoencoder (WAE) shows that matching two distributions is equivalent to minimizing a simple autoencoder (AE) loss under the constraint that the latent space of this AE matches a pre-specified prior distribution. This latent space distribution matching is a core component of WAE, and a challenging task. In this paper, we propose to use the contrastive learning framework that has been shown to be effective for self-supervised representation learning, as a means to resolve this problem. We do so by exploiting the fact that contrastive learning objectives optimize the latent space distribution to be uniform over the unit hyper-sphere, which can be easily sampled from. We show that using the contrastive learning framework to optimize the WAE loss achieves faster convergence and more stable optimization compared with existing popular algorithms for WAE. This is also reflected in the FID scores on CelebA and CIFAR-10 datasets, and the realistic generated image quality on the CelebA-HQ dataset.
Learning Rich Nearest Neighbor Representations from Self-supervised Ensembles
Oct 19, 2021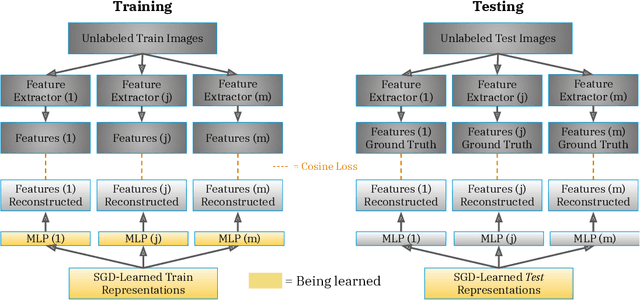
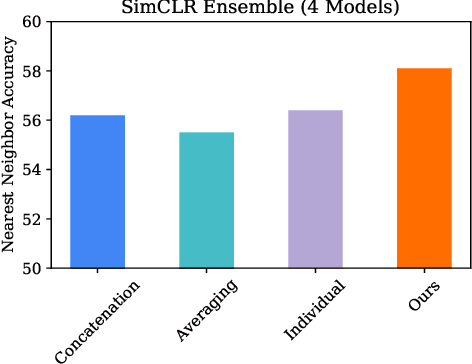
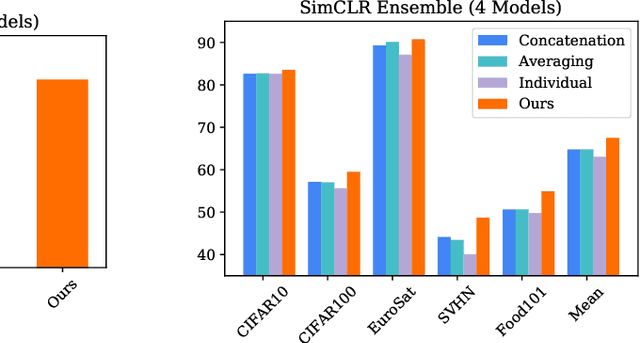
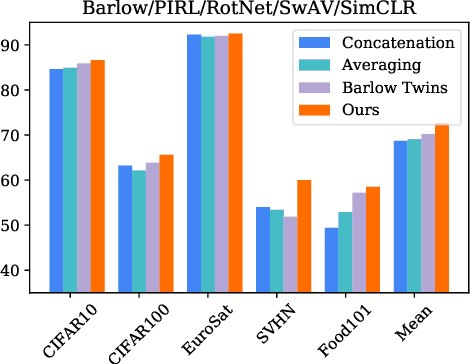
Pretraining convolutional neural networks via self-supervision, and applying them in transfer learning, is an incredibly fast-growing field that is rapidly and iteratively improving performance across practically all image domains. Meanwhile, model ensembling is one of the most universally applicable techniques in supervised learning literature and practice, offering a simple solution to reliably improve performance. But how to optimally combine self-supervised models to maximize representation quality has largely remained unaddressed. In this work, we provide a framework to perform self-supervised model ensembling via a novel method of learning representations directly through gradient descent at inference time. This technique improves representation quality, as measured by k-nearest neighbors, both on the in-domain dataset and in the transfer setting, with models transferable from the former setting to the latter. Additionally, this direct learning of feature through backpropagation improves representations from even a single model, echoing the improvements found in self-distillation.