 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Generation from a Single Video Made Possible
Paper and Code


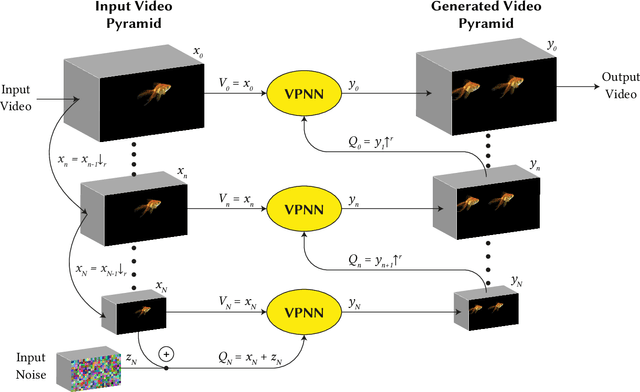
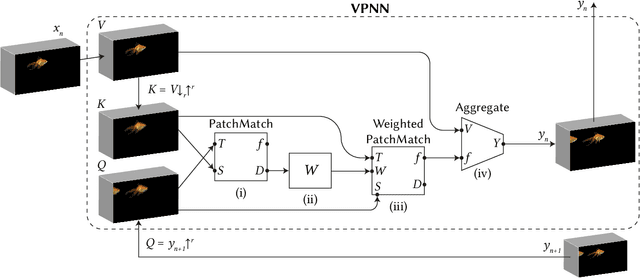
Most advanced video generation and manipulation methods train on a large collection of videos. As such, they are restricted to the types of video dynamics they train on. To overcome this limitation, GANs trained on a single video were recently proposed. While these provide more flexibility to a wide variety of video dynamics, they require days to train on a single tiny input video, rendering them impractical. In this paper we present a fast and practical method for video generation and manipulation from a single natural video, which generates diverse high-quality video outputs within seconds (for benchmark videos). Our method can be further applied to Full-HD video clips within minutes. Our approach is inspired by a recent advanced patch-nearest-neighbor based approach [Granot et al. 2021], which was shown to significantly outperform single-image GANs, both in run-time and in visual quality. Here we generalize this approach from images to videos, by casting classical space-time patch-based methods as a new generative video model. We adapt the generative image patch nearest neighbor approach to efficiently cope with the huge number of space-time patches in a single video. Our method generates more realistic and higher quality results than single-video GANs (confirmed by quantitative and qualitative evaluations). Moreover, it is disproportionally faster (runtime reduced from several days to seconds). Other than diverse video generation, we demonstrate several other challenging video applications, including spatio-temporal video retargeting, video structural analogies and conditional video-inpainting.