 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Biphasic Learning of GANs for High-Resolution Image-to-Image Translation
Apr 14, 2019
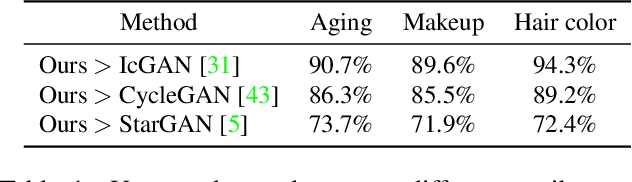
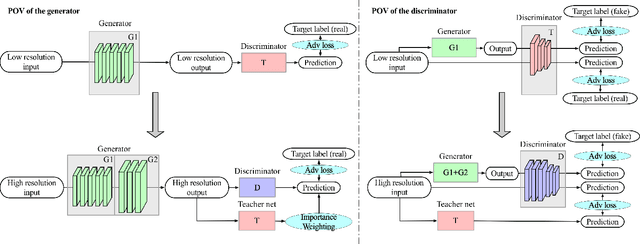
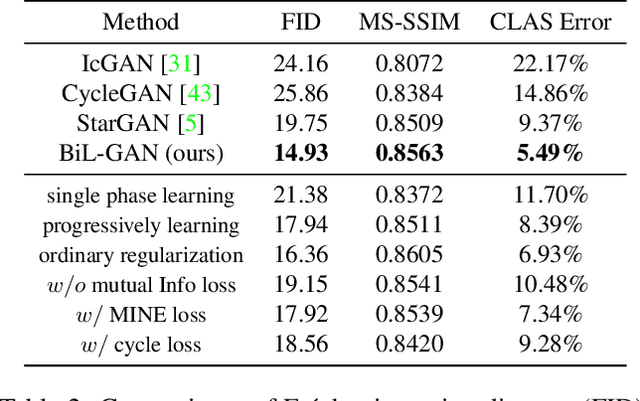

Despite that the performance of image-to-image translation has been significantly improved by recent progress in generative models, current methods still suffer from severe degradation in training stability and sample quality when applied to the high-resolution situation. In this work, we present a novel training framework for GANs, namely biphasic learning, to achieve image-to-image translation in multiple visual domains at $1024^2$ resolution. Our core idea is to design an adjustable objective function that varies across training phases. Within the biphasic learning framework, we propose a novel inherited adversarial loss to achieve the enhancement of model capacity and stabilize the training phase transition. Furthermore, we introduce a perceptual-level consistency loss through mutual information estimation and maximization. To verify the superiority of the proposed method, we apply it to a wide range of face-related synthesis tasks and conduct experiments on multiple large-scale datasets. Through comprehensive quantitative analyses, we demonstrate that our method significantly outperforms existing methods.
Modality-aware Mutual Learning for Multi-modal Medical Image Segmentation
Jul 21, 2021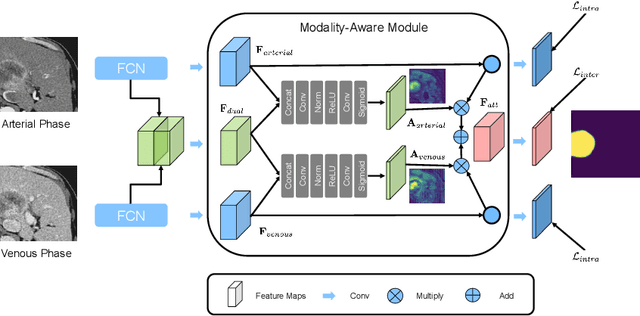
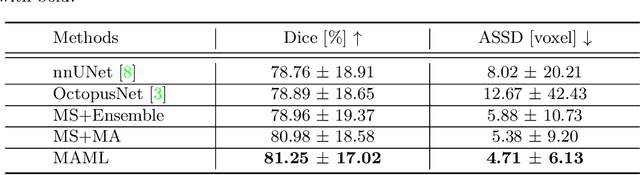
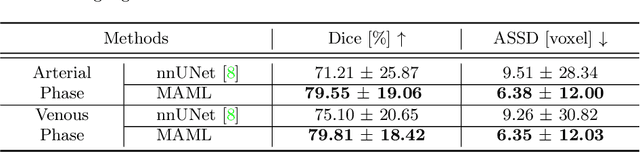
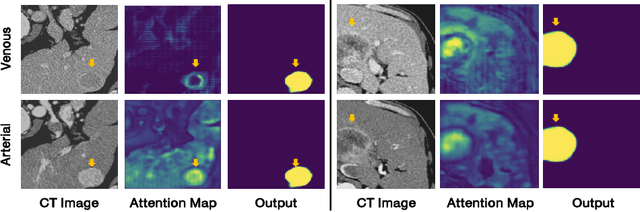
Liver cancer is one of the most common cancers worldwide. Due to inconspicuous texture changes of liver tumor, contrast-enhanced computed tomography (CT) imaging is effective for the diagnosis of liver cancer. In this paper, we focus on improving automated liver tumor segmentation by integrating multi-modal CT images. To this end, we propose a novel mutual learning (ML) strategy for effective and robust multi-modal liver tumor segmentation. Different from existing multi-modal methods that fuse information from different modalities by a single model, with ML, an ensemble of modality-specific models learn collaboratively and teach each other to distill both the characteristics and the commonality between high-level representations of different modalities. The proposed ML not only enables the superiority for multi-modal learning but can also handle missing modalities by transferring knowledge from existing modalities to missing ones. Additionally, we present a modality-aware (MA) module, where the modality-specific models are interconnected and calibrated with attention weights for adaptive information exchange. The proposed modality-aware mutual learning (MAML) method achieves promising results for liver tumor segmentation on a large-scale clinical dataset. Moreover, we show the efficacy and robustness of MAML for handling missing modalities on both the liver tumor and public brain tumor (BRATS 2018) datasets. Our code is available at https://github.com/YaoZhang93/MAML.
Image super-resolution reconstruction based on attention mechanism and feature fusion
Apr 08, 2020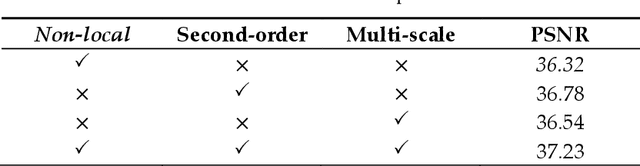
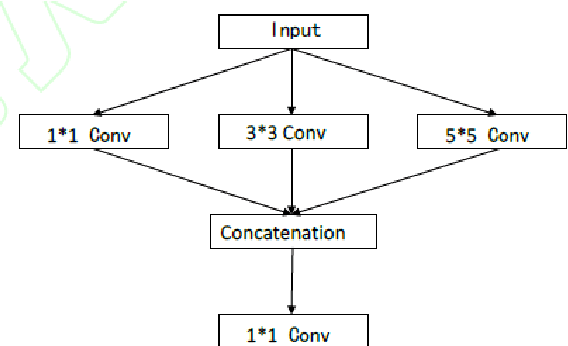
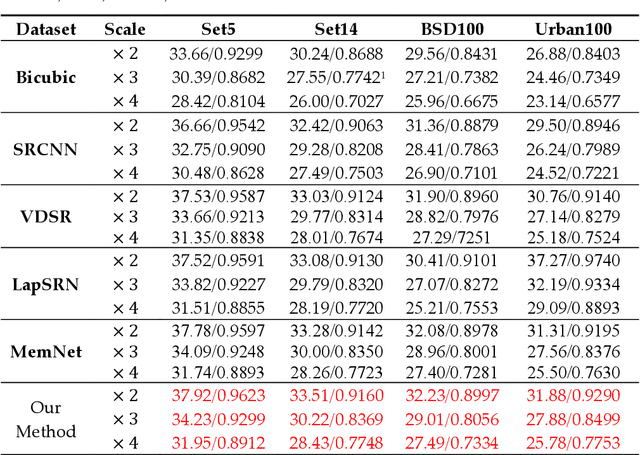
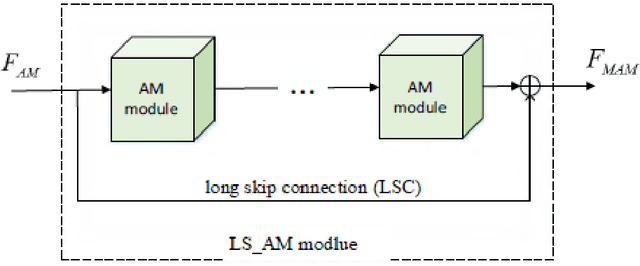
Aiming at the problems that the convolutional neural networks neglect to capture the inherent attributes of natural images and extract features only in a single scale in the field of image super-resolution reconstruction, a network structure based on attention mechanism and multi-scale feature fusion is proposed. By using the attention mechanism, the network can effectively integrate the non-local information and second-order features of the image, so as to improve the feature expression ability of the network. At the same time, the convolution kernel of different scales is used to extract the multi-scale information of the image, so as to preserve the complete information characteristics at different scales. Experimental results show that the proposed method can achieve better performance over other representative super-resolution reconstruction algorithms in objective quantitative metrics and visual quality.
Robust Image Retrieval-based Visual Localization using Kapture
Jul 27, 2020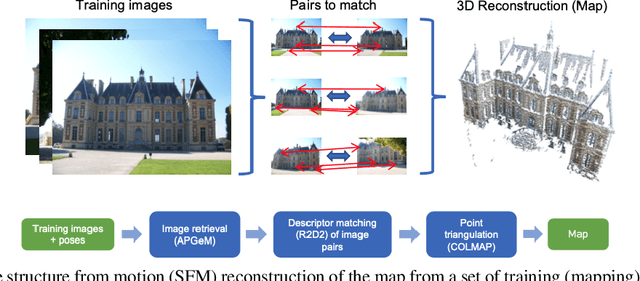
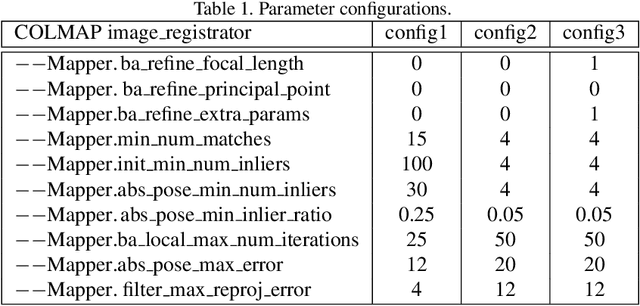
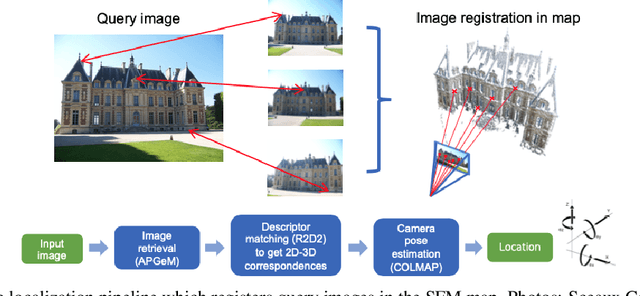

In this paper, we present a versatile method for visual localization. It is based on robust image retrieval for coarse camera pose estimation and robust local features for accurate pose refinement. Our method is top ranked on various public datasets showing its ability of generalization and its great variety of applications. To facilitate experiments, we introduce kapture, a flexible data format and processing pipeline for structure from motion and visual localization that is released open source. We furthermore provide all datasets used in this paper in the kapture format to facilitate research and data processing. The code can be found at https://github.com/naver/kapture, the datasets as well as more information, updates, and news can be found at https://europe.naverlabs.com/research/3d-vision/kapture.
Deep Unfolding with Normalizing Flow Priors for Inverse Problems
Jul 06, 2021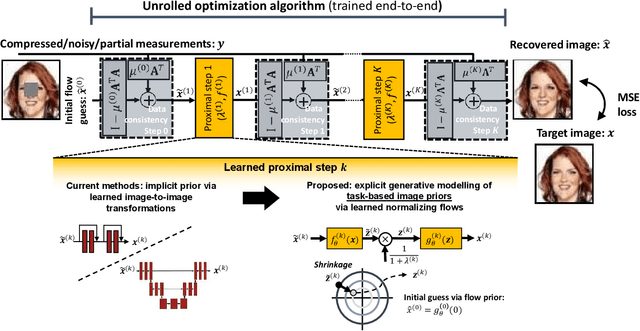


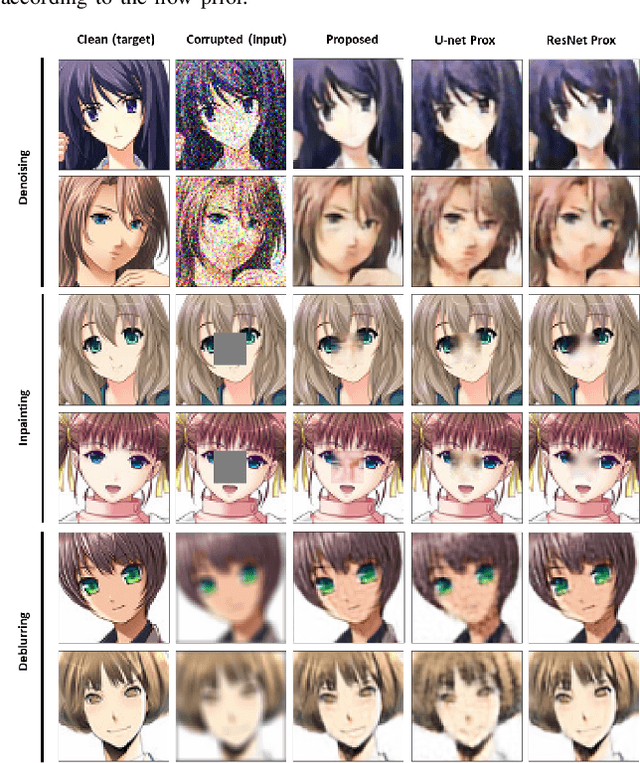
Many application domains, spanning from computational photography to medical imaging, require recovery of high-fidelity images from noisy, incomplete or partial/compressed measurements. State of the art methods for solving these inverse problems combine deep learning with iterative model-based solvers, a concept known as deep algorithm unfolding. By combining a-priori knowledge of the forward measurement model with learned (proximal) mappings based on deep networks, these methods yield solutions that are both physically feasible (data-consistent) and perceptually plausible. However, current proximal mappings only implicitly learn such image priors. In this paper, we propose to make these image priors fully explicit by embedding deep generative models in the form of normalizing flows within the unfolded proximal gradient algorithm. We demonstrate that the proposed method outperforms competitive baselines on various image recovery tasks, spanning from image denoising to inpainting and deblurring.
B-Splines
Aug 14, 2021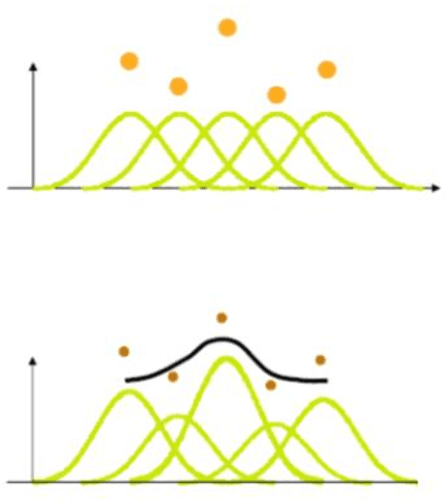
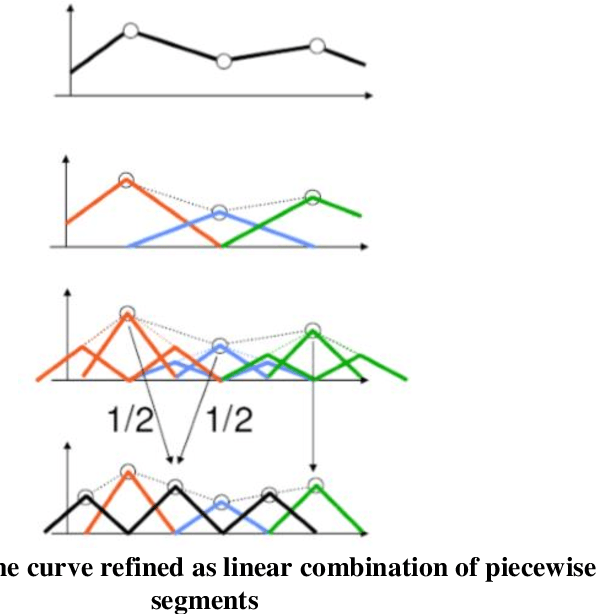
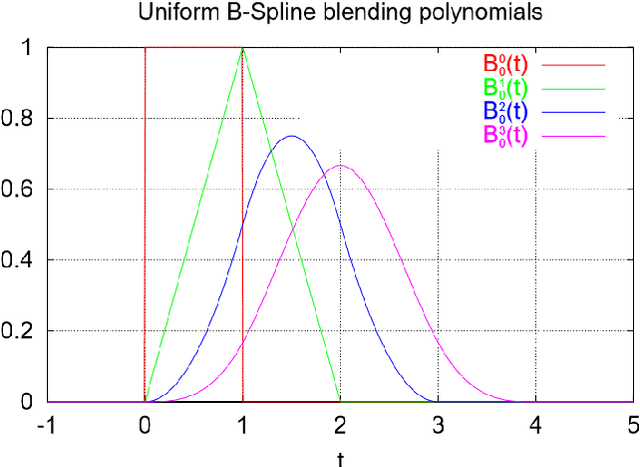

BSplines are one of the most promising curves in computer graphics. They are blessed with some superior geometric properties which make them an ideal candidate for several applications in computer aided design industry. In this article, some basic properties of B-Spline curves are presented. Two significant B-Spline properties viz convex hull property and repeated points effects are discussed. The BSplines computation in computational devices is also illustrated. An industry application based on image processing where B-Spline curve reconstructs the 3D surfaces for CT image datasets of inner organs further highlights the strength of these curves
FIS-Nets: Full-image Supervised Networks for Monocular Depth Estimation
Jan 19, 2020
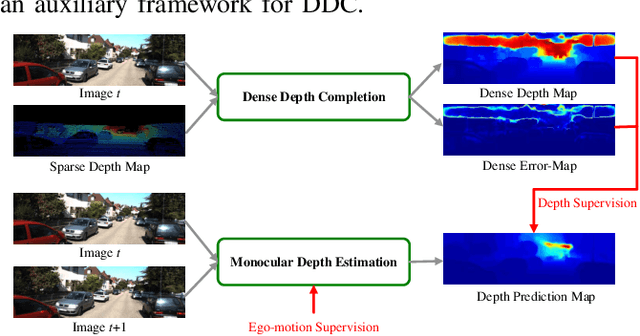
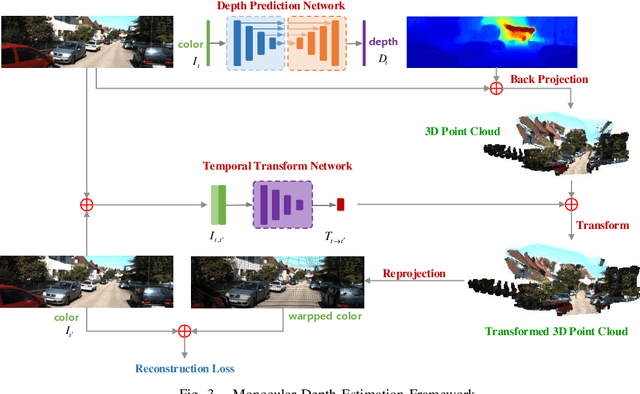
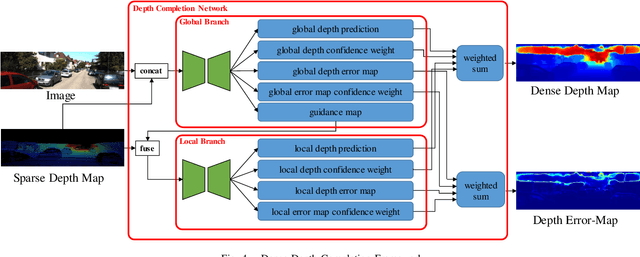
This paper addresses the importance of full-image supervision for monocular depth estimation. We propose a semi-supervised architecture, which combines both unsupervised framework of using image consistency and supervised framework of dense depth completion. The latter provides full-image depth as supervision for the former. Ego-motion from navigation system is also embedded into the unsupervised framework as output supervision of an inner temporal transform network, making monocular depth estimation better. In the evaluation, we show that our proposed model outperforms other approaches on depth estimation.
Predição da Idade Cerebral a partir de Imagens de Ressonância Magnética utilizando Redes Neurais Convolucionais
Dec 23, 2021In this work, deep learning techniques for brain age prediction from magnetic resonance images are investigated, aiming to assist in the identification of biomarkers of the natural aging process. The identification of biomarkers is useful for detecting an early-stage neurodegenerative process, as well as for predicting age-related or non-age-related cognitive decline. Two techniques are implemented and compared in this work: a 3D Convolutional Neural Network applied to the volumetric image and a 2D Convolutional Neural Network applied to slices from the axial plane, with subsequent fusion of individual predictions. The best result was obtained by the 2D model, which achieved a mean absolute error of 3.83 years. -- Neste trabalho s\~ao investigadas t\'ecnicas de aprendizado profundo para a predi\c{c}\~ao da idade cerebral a partir de imagens de resson\^ancia magn\'etica, visando auxiliar na identifica\c{c}\~ao de biomarcadores do processo natural de envelhecimento. A identifica\c{c}\~ao de biomarcadores \'e \'util para a detec\c{c}\~ao de um processo neurodegenerativo em est\'agio inicial, al\'em de possibilitar prever um decl\'inio cognitivo relacionado ou n\~ao \`a idade. Duas t\'ecnicas s\~ao implementadas e comparadas neste trabalho: uma Rede Neural Convolucional 3D aplicada na imagem volum\'etrica e uma Rede Neural Convolucional 2D aplicada a fatias do plano axial, com posterior fus\~ao das predi\c{c}\~oes individuais. O melhor resultado foi obtido pelo modelo 2D, que alcan\c{c}ou um erro m\'edio absoluto de 3.83 anos.
KD-MRI: A knowledge distillation framework for image reconstruction and image restoration in MRI workflow
Apr 11, 2020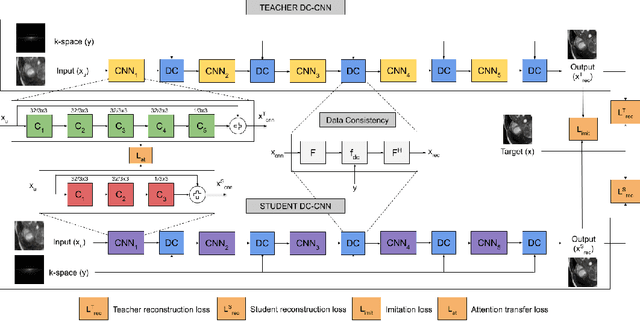
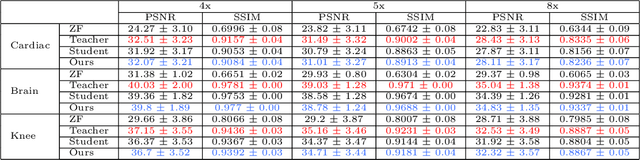
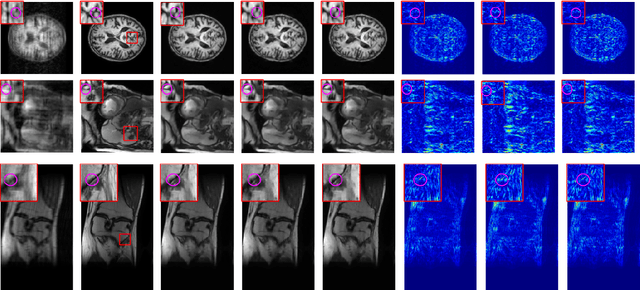
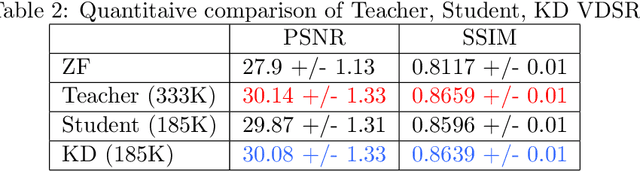
Deep learning networks are being developed in every stage of the MRI workflow and have provided state-of-the-art results. However, this has come at the cost of increased computation requirement and storage. Hence, replacing the networks with compact models at various stages in the MRI workflow can significantly reduce the required storage space and provide considerable speedup. In computer vision, knowledge distillation is a commonly used method for model compression. In our work, we propose a knowledge distillation (KD) framework for the image to image problems in the MRI workflow in order to develop compact, low-parameter models without a significant drop in performance. We propose a combination of the attention-based feature distillation method and imitation loss and demonstrate its effectiveness on the popular MRI reconstruction architecture, DC-CNN. We conduct extensive experiments using Cardiac, Brain, and Knee MRI datasets for 4x, 5x and 8x accelerations. We observed that the student network trained with the assistance of the teacher using our proposed KD framework provided significant improvement over the student network trained without assistance across all the datasets and acceleration factors. Specifically, for the Knee dataset, the student network achieves $65\%$ parameter reduction, 2x faster CPU running time, and 1.5x faster GPU running time compared to the teacher. Furthermore, we compare our attention-based feature distillation method with other feature distillation methods. We also conduct an ablative study to understand the significance of attention-based distillation and imitation loss. We also extend our KD framework for MRI super-resolution and show encouraging results.
Compositional Affinity Propagation: When Clusters Have Compositional Structure
Sep 09, 2021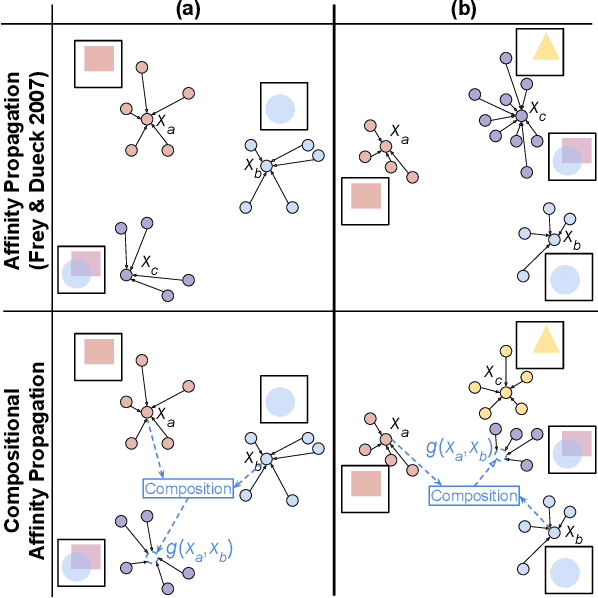
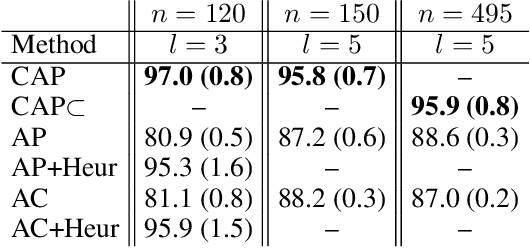
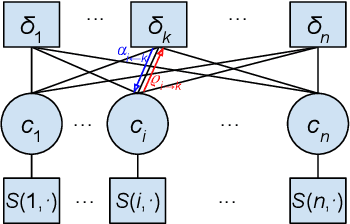
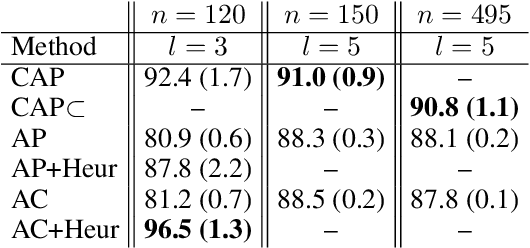
We consider a new kind of clustering problem in which clusters need not be independent of each other, but rather can have compositional relationships with other clusters (e.g., an image set consists of rectangles, circles, as well as combinations of rectangles and circles). This task is motivated by recent work in few-shot learning on compositional embedding models that structure the embedding space to distinguish the label sets, not just the individual labels, assigned to the examples. To tackle this clustering problem, we propose a new algorithm called Compositional Affinity Propagation (CAP). In contrast to standard Affinity Propagation as well as other algorithms for multi-view and hierarchical clustering, CAP can deduce compositionality among clusters automatically. We show promising results, compared to several existing clustering algorithms, on the MultiMNIST, OmniGlot, and LibriSpeech datasets. Our work has applications to multi-object image recognition and speaker diarization with simultaneous speech from multiple speakers.