 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Translate from Soft to Hard LLM Prompts
May 26, 2026Soft prompt tuning is a parameter-efficient method for adapting LLMs to specific tasks, but suffers from a lack of interpretability. Building on recent work on interpreting soft prompts (Ramati et al., 2024), we explore how training a dedicated soft prompt to natural language translation model can yield higher translation quality. In particular, in both quantitative and qualitative comparisons on multiple Datasets of Datasets (DoDs), we demonstrate that our translator produces fluent, accurate verbalizations that outperforms existing training-free methods like InSPEcT. In addition to advancing interpretability, our work suggests a promising downstream application: soft prompts optimized on small, open-source models can be translated into portable text prompts that, when deployed on larger closed-API models, exceed the performance of the original soft prompt and, in some cases, even few-shot learning.
Quantization of Spiking Neural Networks Beyond Accuracy
Apr 15, 2026Quantization is a natural complement to the sparse, event-driven computation of Spiking Neural Networks, reducing memory bandwidth and arithmetic cost for deployment on resource-constrained hardware. However, existing SNN quantization evaluation focuses almost exclusively on accuracy, overlooking whether a quantized network preserves the firing behavior of its full-precision counterpart. We demonstrate that quantization method, clipping range, and bit-width can produce substantially different firing distributions at equivalent accuracy, differences invisible to standard metrics but relevant to deployment, where firing activity governs effective sparsity, state storage, and event-processing load. To capture this gap, we propose Earth Mover's Distance as a diagnostic metric for firing distribution divergence, and apply it systematically across weight and membrane quantization on SEW-ResNet architectures trained on CIFAR-10 and CIFAR-100. We find that uniform quantization induces distributional drift even when accuracy is preserved, while LQ-Net style learned quantization maintains firing behavior close to the full-precision baseline. Our results suggest that behavior preservation should be treated as an evaluation criterion alongside accuracy, and that EMD provides a principled tool for assessing it.
The CHASM-SWPC Dataset for Coronal Hole Detection & Analysis
Nov 18, 2025



Coronal holes (CHs) are low-activity, low-density solar coronal regions with open magnetic field lines (Cranmer 2009). In the extreme ultraviolet (EUV) spectrum, CHs appear as dark patches. Using daily hand-drawn maps from the Space Weather Prediction Center (SWPC), we developed a semi-automated pipeline to digitize the SWPC maps into binary segmentation masks. The resulting masks constitute the CHASM-SWPC dataset, a high-quality dataset to train and test automated CH detection models, which is released with this paper. We developed CHASM (Coronal Hole Annotation using Semi-automatic Methods), a software tool for semi-automatic annotation that enables users to rapidly and accurately annotate SWPC maps. The CHASM tool enabled us to annotate 1,111 CH masks, comprising the CHASM-SWPC-1111 dataset. We then trained multiple CHRONNOS (Coronal Hole RecOgnition Neural Network Over multi-Spectral-data) architecture (Jarolim et al. 2021) neural networks using the CHASM-SWPC dataset and compared their performance. Training the CHRONNOS neural network on these data achieved an accuracy of 0.9805, a True Skill Statistic (TSS) of 0.6807, and an intersection-over-union (IoU) of 0.5668, which is higher than the original pretrained CHRONNOS model Jarolim et al. (2021) achieved an accuracy of 0.9708, a TSS of 0.6749, and an IoU of 0.4805, when evaluated on the CHASM-SWPC-1111 test set.
Improving Named Entity Transcription with Contextual LLM-based Revision
Jun 12, 2025



With recent advances in modeling and the increasing amount of supervised training data, automatic speech recognition (ASR) systems have achieved remarkable performance on general speech. However, the word error rate (WER) of state-of-the-art ASR remains high for named entities. Since named entities are often the most critical keywords, misrecognizing them can affect all downstream applications, especially when the ASR system functions as the front end of a complex system. In this paper, we introduce a large language model (LLM) revision mechanism to revise incorrect named entities in ASR predictions by leveraging the LLM's reasoning ability as well as local context (e.g., lecture notes) containing a set of correct named entities. Finally, we introduce the NER-MIT-OpenCourseWare dataset, containing 45 hours of data from MIT courses for development and testing. On this dataset, our proposed technique achieves up to 30\% relative WER reduction for named entities.
Survey of End-to-End Multi-Speaker Automatic Speech Recognition for Monaural Audio
May 16, 2025Monaural multi-speaker automatic speech recognition (ASR) remains challenging due to data scarcity and the intrinsic difficulty of recognizing and attributing words to individual speakers, particularly in overlapping speech. Recent advances have driven the shift from cascade systems to end-to-end (E2E) architectures, which reduce error propagation and better exploit the synergy between speech content and speaker identity. Despite rapid progress in E2E multi-speaker ASR, the field lacks a comprehensive review of recent developments. This survey provides a systematic taxonomy of E2E neural approaches for multi-speaker ASR, highlighting recent advances and comparative analysis. Specifically, we analyze: (1) architectural paradigms (SIMO vs.~SISO) for pre-segmented audio, analyzing their distinct characteristics and trade-offs; (2) recent architectural and algorithmic improvements based on these two paradigms; (3) extensions to long-form speech, including segmentation strategy and speaker-consistent hypothesis stitching. Further, we (4) evaluate and compare methods across standard benchmarks. We conclude with a discussion of open challenges and future research directions towards building robust and scalable multi-speaker ASR.
Multi-modal Speech Transformer Decoders: When Do Multiple Modalities Improve Accuracy?
Sep 13, 2024



Decoder-only discrete-token language models have recently achieved significant success in automatic speech recognition. However, systematic analyses of how different modalities impact performance in specific scenarios remain limited. In this paper, we investigate the effects of multiple modalities on recognition accuracy on both synthetic and real-world datasets. Our experiments suggest that: (1) Integrating more modalities can increase accuracy; in particular, our paper is, to our best knowledge, the first to show the benefit of combining audio, image context, and lip information; (2) Images as a supplementary modality for speech recognition provide the greatest benefit at moderate noise levels, moreover, they exhibit a different trend compared to inherently synchronized modalities like lip movements; (3) Performance improves on both synthetic and real-world datasets when the most relevant visual information is filtered as a preprocessing step.
Discrete Multimodal Transformers with a Pretrained Large Language Model for Mixed-Supervision Speech Processing
Jun 04, 2024Recent work on discrete speech tokenization has paved the way for models that can seamlessly perform multiple tasks across modalities, e.g., speech recognition, text to speech, speech to speech translation. Moreover, large language models (LLMs) pretrained from vast text corpora contain rich linguistic information that can improve accuracy in a variety of tasks. In this paper, we present a decoder-only Discrete Multimodal Language Model (DMLM), which can be flexibly applied to multiple tasks (ASR, T2S, S2TT, etc.) and modalities (text, speech, vision). We explore several critical aspects of discrete multi-modal models, including the loss function, weight initialization, mixed training supervision, and codebook. Our results show that DMLM benefits significantly, across multiple tasks and datasets, from a combination of supervised and unsupervised training. Moreover, for ASR, it benefits from initializing DMLM from a pretrained LLM, and from a codebook derived from Whisper activations.
Automated Evaluation of Classroom Instructional Support with LLMs and BoWs: Connecting Global Predictions to Specific Feedback
Oct 02, 2023



With the aim to provide teachers with more specific, frequent, and actionable feedback about their teaching, we explore how Large Language Models (LLMs) can be used to estimate ``Instructional Support'' domain scores of the CLassroom Assessment Scoring System (CLASS), a widely used observation protocol. We design a machine learning architecture that uses either zero-shot prompting of Meta's Llama2, and/or a classic Bag of Words (BoW) model, to classify individual utterances of teachers' speech (transcribed automatically using OpenAI's Whisper) for the presence of 11 behavioral indicators of Instructional Support. Then, these utterance-level judgments are aggregated over an entire 15-min observation session to estimate a global CLASS score. Experiments on two CLASS-coded datasets of toddler and pre-kindergarten classrooms indicate that (1) automatic CLASS Instructional Support estimation accuracy using the proposed method (Pearson $R$ up to $0.46$) approaches human inter-rater reliability (up to $R=0.55$); (2) LLMs yield slightly greater accuracy than BoW for this task; and (3) the best models often combined features extracted from both LLM and BoW. Finally, (4) we illustrate how the model's outputs can be visualized at the utterance level to provide teachers with explainable feedback on which utterances were most positively or negatively correlated with specific CLASS dimensions.
Compositional Affinity Propagation: When Clusters Have Compositional Structure
Sep 09, 2021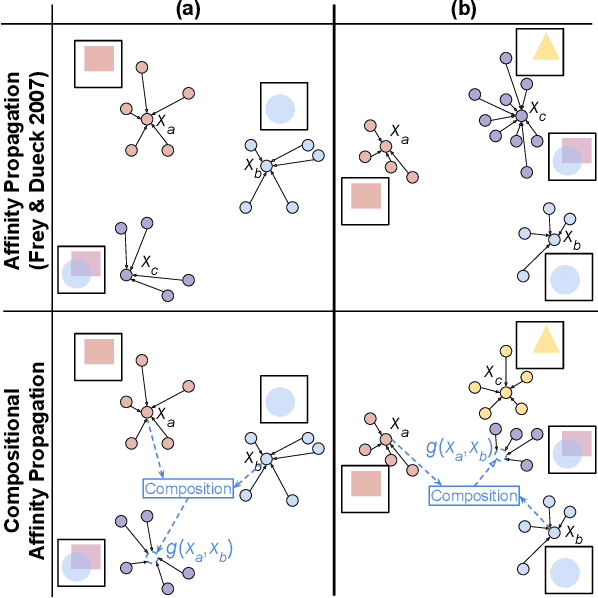
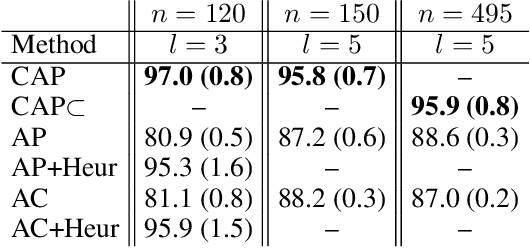
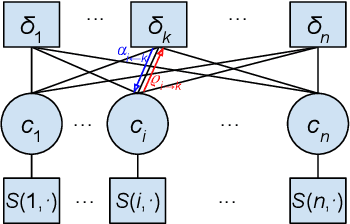
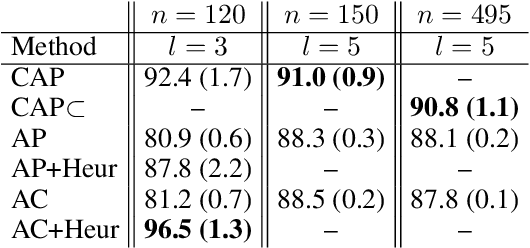
We consider a new kind of clustering problem in which clusters need not be independent of each other, but rather can have compositional relationships with other clusters (e.g., an image set consists of rectangles, circles, as well as combinations of rectangles and circles). This task is motivated by recent work in few-shot learning on compositional embedding models that structure the embedding space to distinguish the label sets, not just the individual labels, assigned to the examples. To tackle this clustering problem, we propose a new algorithm called Compositional Affinity Propagation (CAP). In contrast to standard Affinity Propagation as well as other algorithms for multi-view and hierarchical clustering, CAP can deduce compositionality among clusters automatically. We show promising results, compared to several existing clustering algorithms, on the MultiMNIST, OmniGlot, and LibriSpeech datasets. Our work has applications to multi-object image recognition and speaker diarization with simultaneous speech from multiple speakers.
Harnessing Geometric Constraints from Auxiliary Labels to Improve Embedding Functions for One-Shot Learning
Mar 05, 2021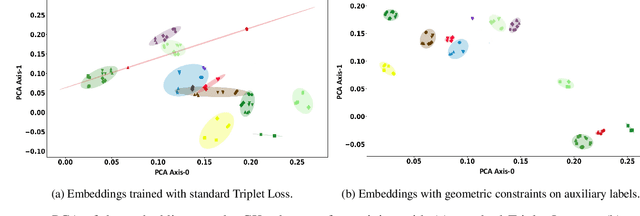
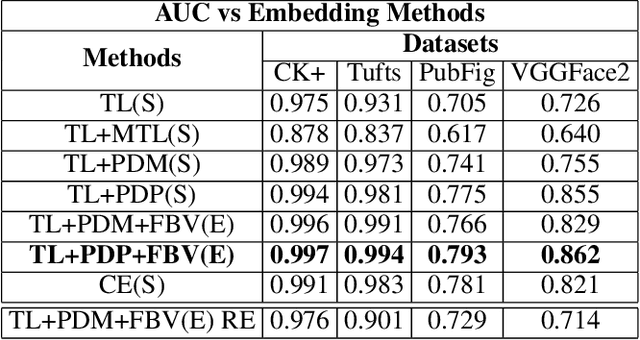

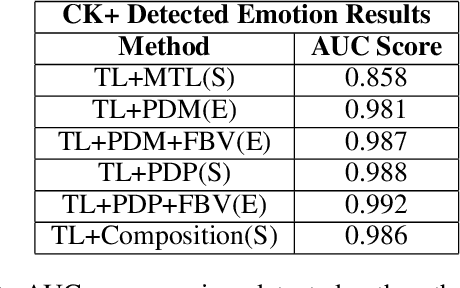
We explore the utility of harnessing auxiliary labels (e.g., facial expression) to impose geometric structure when training embedding models for one-shot learning (e.g., for face verification). We introduce novel geometric constraints on the embedding space learned by a deep model using either manually annotated or automatically detected auxiliary labels. We contrast their performances (AUC) on four different face datasets(CK+, VGGFace-2, Tufts Face, and PubFig). Due to the additional structure encoded in the embedding space, our methods provide a higher verification accuracy (99.7, 86.2, 99.4, and 79.3% with our proposed TL+PDP+FBV loss, versus 97.5, 72.6, 93.1, and 70.5% using a standard Triplet Loss on the four datasets, respectively). Our method is implemented purely in terms of the loss function. It does not require any changes to the backbone of the embedding functions.