 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multimodal Integration of Human-Like Attention in Visual Question Answering
Sep 27, 2021
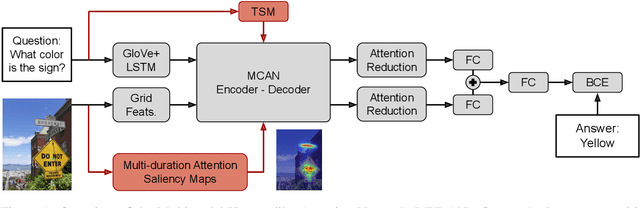
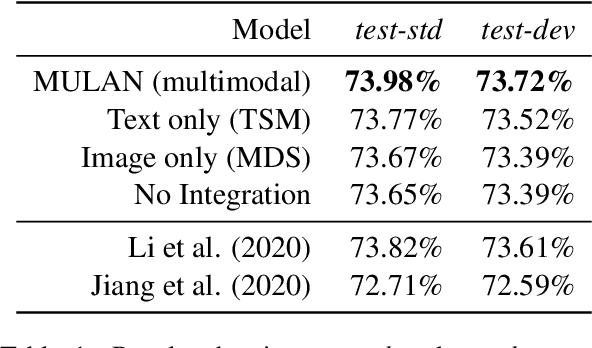
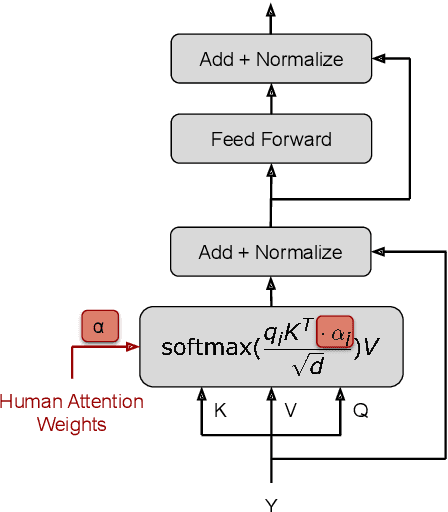
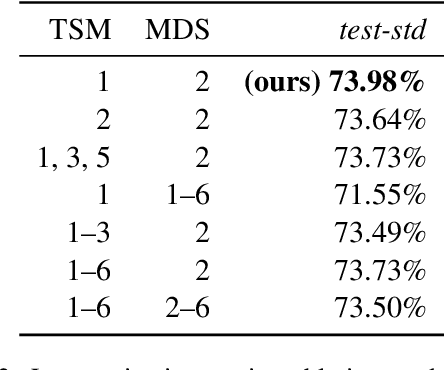
Human-like attention as a supervisory signal to guide neural attention has shown significant promise but is currently limited to uni-modal integration - even for inherently multimodal tasks such as visual question answering (VQA). We present the Multimodal Human-like Attention Network (MULAN) - the first method for multimodal integration of human-like attention on image and text during training of VQA models. MULAN integrates attention predictions from two state-of-the-art text and image saliency models into neural self-attention layers of a recent transformer-based VQA model. Through evaluations on the challenging VQAv2 dataset, we show that MULAN achieves a new state-of-the-art performance of 73.98% accuracy on test-std and 73.72% on test-dev and, at the same time, has approximately 80% fewer trainable parameters than prior work. Overall, our work underlines the potential of integrating multimodal human-like and neural attention for VQA
Leveraging Scale-Invariance and Uncertainity with Self-Supervised Domain Adaptation for Semantic Segmentation of Foggy Scenes
Jan 07, 2022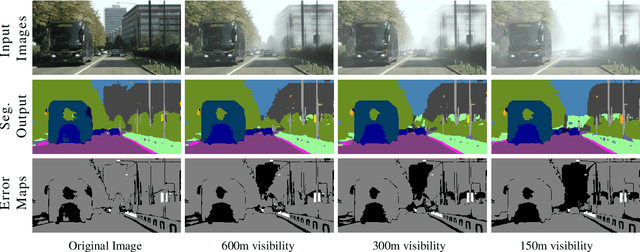

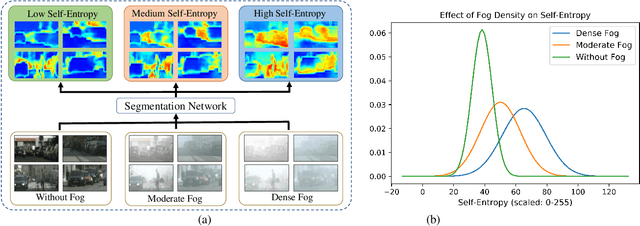
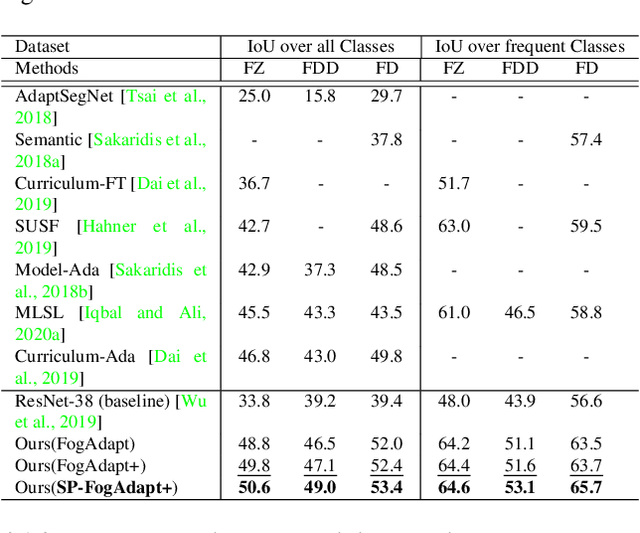
This paper presents FogAdapt, a novel approach for domain adaptation of semantic segmentation for dense foggy scenes. Although significant research has been directed to reduce the domain shift in semantic segmentation, adaptation to scenes with adverse weather conditions remains an open question. Large variations in the visibility of the scene due to weather conditions, such as fog, smog, and haze, exacerbate the domain shift, thus making unsupervised adaptation in such scenarios challenging. We propose a self-entropy and multi-scale information augmented self-supervised domain adaptation method (FogAdapt) to minimize the domain shift in foggy scenes segmentation. Supported by the empirical evidence that an increase in fog density results in high self-entropy for segmentation probabilities, we introduce a self-entropy based loss function to guide the adaptation method. Furthermore, inferences obtained at different image scales are combined and weighted by the uncertainty to generate scale-invariant pseudo-labels for the target domain. These scale-invariant pseudo-labels are robust to visibility and scale variations. We evaluate the proposed model on real clear-weather scenes to real foggy scenes adaptation and synthetic non-foggy images to real foggy scenes adaptation scenarios. Our experiments demonstrate that FogAdapt significantly outperforms the current state-of-the-art in semantic segmentation of foggy images. Specifically, by considering the standard settings compared to state-of-the-art (SOTA) methods, FogAdapt gains 3.8% on Foggy Zurich, 6.0% on Foggy Driving-dense, and 3.6% on Foggy Driving in mIoU when adapted from Cityscapes to Foggy Zurich.
The Second Place Solution for ICCV2021 VIPriors Instance Segmentation Challenge
Dec 02, 2021

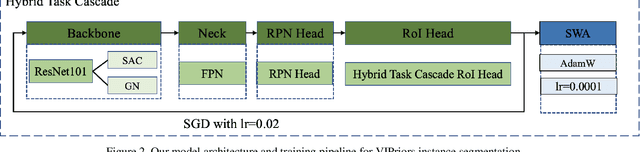
The Visual Inductive Priors(VIPriors) for Data-Efficient Computer Vision challenges ask competitors to train models from scratch in a data-deficient setting. In this paper, we introduce the technical details of our submission to the ICCV2021 VIPriors instance segmentation challenge. Firstly, we designed an effective data augmentation method to improve the problem of data-deficient. Secondly, we conducted some experiments to select a proper model and made some improvements for this task. Thirdly, we proposed an effective training strategy which can improve the performance. Experimental results demonstrate that our approach can achieve a competitive result on the test set. According to the competition rules, we do not use any external image or video data and pre-trained weights. The implementation details above are described in section 2 and section 3. Finally, our approach can achieve 40.2\%AP@0.50:0.95 on the test set of ICCV2021 VIPriors instance segmentation challenge.
Learning Target-aware Representation for Visual Tracking via Informative Interactions
Jan 07, 2022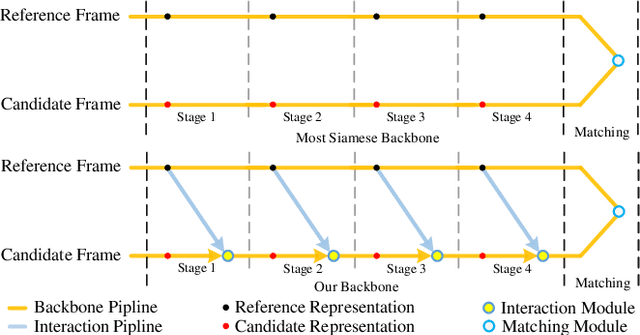
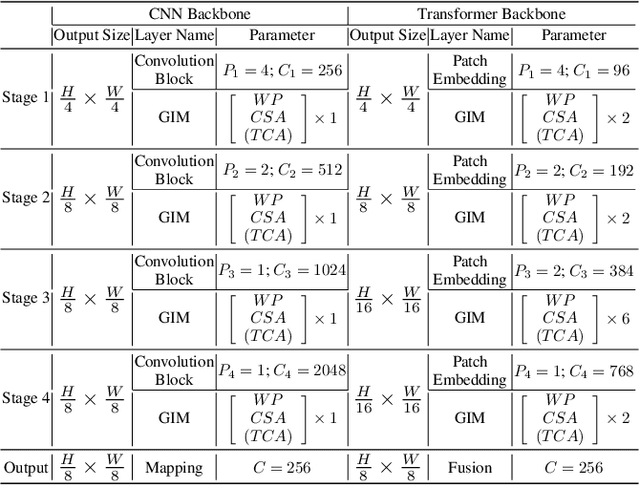
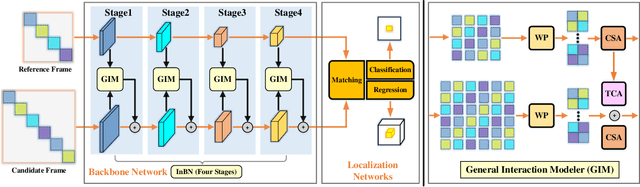
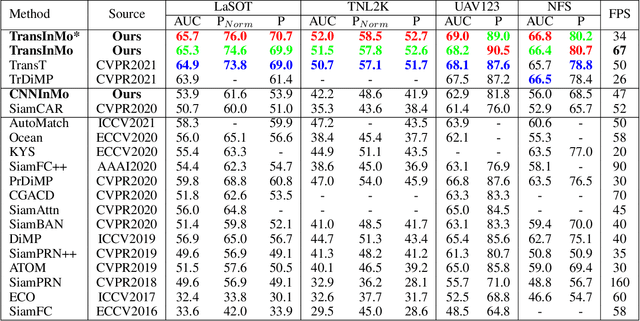
We introduce a novel backbone architecture to improve target-perception ability of feature representation for tracking. Specifically, having observed that de facto frameworks perform feature matching simply using the outputs from backbone for target localization, there is no direct feedback from the matching module to the backbone network, especially the shallow layers. More concretely, only the matching module can directly access the target information (in the reference frame), while the representation learning of candidate frame is blind to the reference target. As a consequence, the accumulation effect of target-irrelevant interference in the shallow stages may degrade the feature quality of deeper layers. In this paper, we approach the problem from a different angle by conducting multiple branch-wise interactions inside the Siamese-like backbone networks (InBN). At the core of InBN is a general interaction modeler (GIM) that injects the prior knowledge of reference image to different stages of the backbone network, leading to better target-perception and robust distractor-resistance of candidate feature representation with negligible computation cost. The proposed GIM module and InBN mechanism are general and applicable to different backbone types including CNN and Transformer for improvements, as evidenced by our extensive experiments on multiple benchmarks. In particular, the CNN version (based on SiamCAR) improves the baseline with 3.2/6.9 absolute gains of SUC on LaSOT/TNL2K, respectively. The Transformer version obtains SUC scores of 65.7/52.0 on LaSOT/TNL2K, which are on par with recent state of the arts. Code and models will be released.
LDDMM meets GANs: Generative Adversarial Networks for diffeomorphic registration
Nov 24, 2021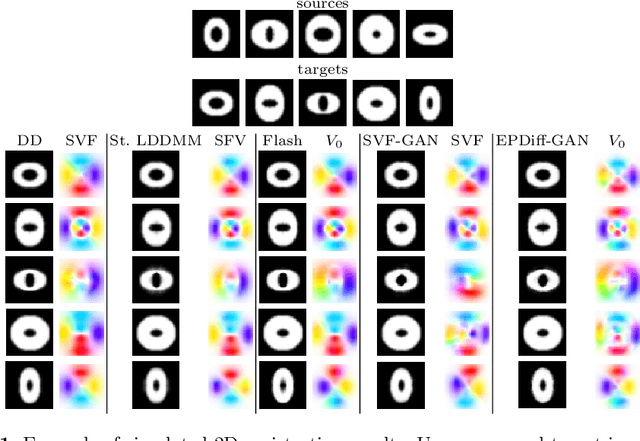
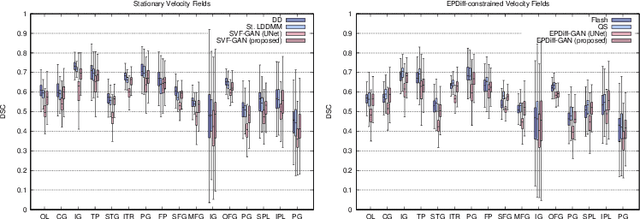
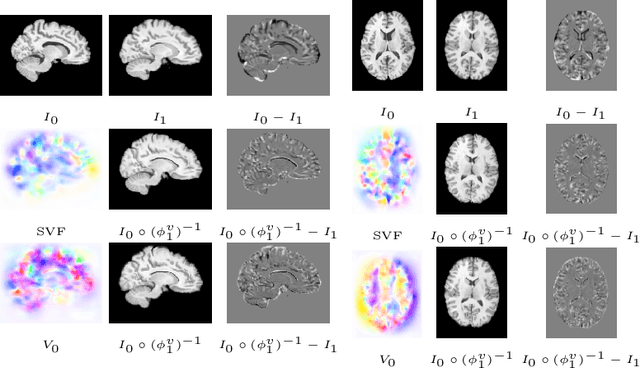
The purpose of this work is to contribute to the state of the art of deep-learning methods for diffeomorphic registration. We propose an adversarial learning LDDMM method for pairs of 3D mono-modal images based on Generative Adversarial Networks. The method is inspired by the recent literature for deformable image registration with adversarial learning. We combine the best performing generative, discriminative, and adversarial ingredients from the state of the art within the LDDMM paradigm. We have successfully implemented two models with the stationary and the EPDiff-constrained non-stationary parameterizations of diffeomorphisms. Our unsupervised and data-hungry approach has shown a competitive performance with respect to a benchmark supervised and rich-data approach. In addition, our method has shown similar results to model-based methods with a computational time under one second.
Extracting Triangular 3D Models, Materials, and Lighting From Images
Nov 24, 2021
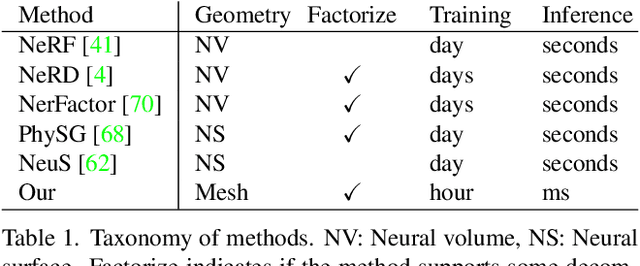

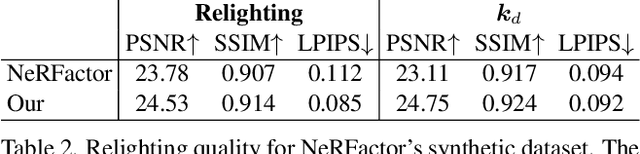
We present an efficient method for joint optimization of topology, materials and lighting from multi-view image observations. Unlike recent multi-view reconstruction approaches, which typically produce entangled 3D representations encoded in neural networks, we output triangle meshes with spatially-varying materials and environment lighting that can be deployed in any traditional graphics engine unmodified. We leverage recent work in differentiable rendering, coordinate-based networks to compactly represent volumetric texturing, alongside differentiable marching tetrahedrons to enable gradient-based optimization directly on the surface mesh. Finally, we introduce a differentiable formulation of the split sum approximation of environment lighting to efficiently recover all-frequency lighting. Experiments show our extracted models used in advanced scene editing, material decomposition, and high quality view interpolation, all running at interactive rates in triangle-based renderers (rasterizers and path tracers).
Learning Query Expansion over the Nearest Neighbor Graph
Dec 05, 2021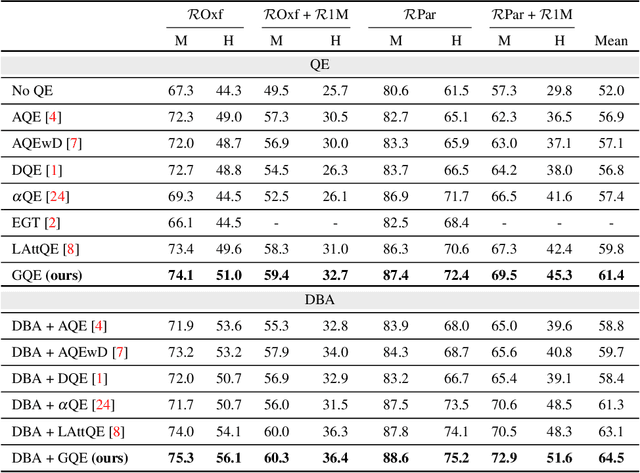
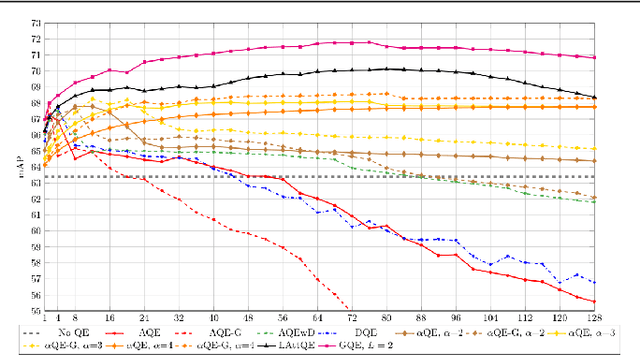
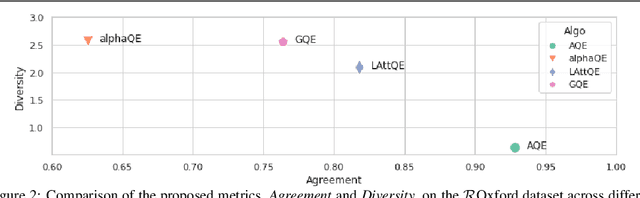
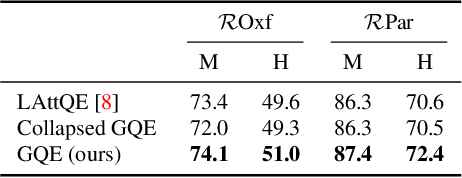
Query Expansion (QE) is a well established method for improving retrieval metrics in image search applications. When using QE, the search is conducted on a new query vector, constructed using an aggregation function over the query and images from the database. Recent works gave rise to QE techniques in which the aggregation function is learned, whereas previous techniques were based on hand-crafted aggregation functions, e.g., taking the mean of the query's nearest neighbors. However, most QE methods have focused on aggregation functions that work directly over the query and its immediate nearest neighbors. In this work, a hierarchical model, Graph Query Expansion (GQE), is presented, which is learned in a supervised manner and performs aggregation over an extended neighborhood of the query, thus increasing the information used from the database when computing the query expansion, and using the structure of the nearest neighbors graph. The technique achieves state-of-the-art results over known benchmarks.
Incremental Learning for Animal Pose Estimation using RBF k-DPP
Oct 26, 2021



Pose estimation is the task of locating keypoints for an object of interest in an image. Animal Pose estimation is more challenging than estimating human pose due to high inter and intra class variability in animals. Existing works solve this problem for a fixed set of predefined animal categories. Models trained on such sets usually do not work well with new animal categories. Retraining the model on new categories makes the model overfit and leads to catastrophic forgetting. Thus, in this work, we propose a novel problem of "Incremental Learning for Animal Pose Estimation". Our method uses an exemplar memory, sampled using Determinantal Point Processes (DPP) to continually adapt to new animal categories without forgetting the old ones. We further propose a new variant of k-DPP that uses RBF kernel (termed as "RBF k-DPP") which gives more gain in performance over traditional k-DPP. Due to memory constraints, the limited number of exemplars along with new class data can lead to class imbalance. We mitigate it by performing image warping as an augmentation technique. This helps in crafting diverse poses, which reduces overfitting and yields further improvement in performance. The efficacy of our proposed approach is demonstrated via extensive experiments and ablations where we obtain significant improvements over state-of-the-art baseline methods.
RegQCNET: Deep Quality Control for Image-to-template Brain MRI Registration
May 14, 2020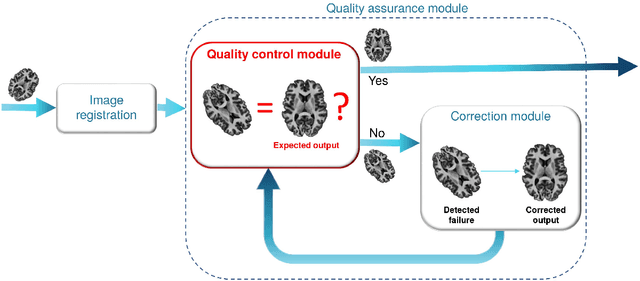
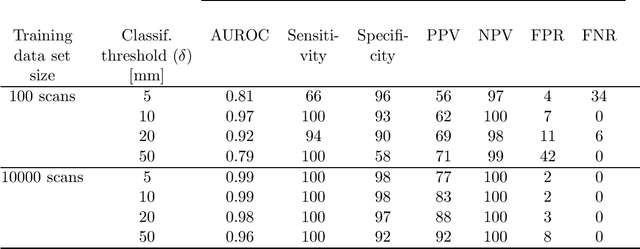
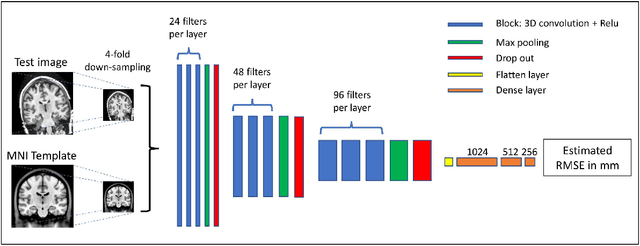
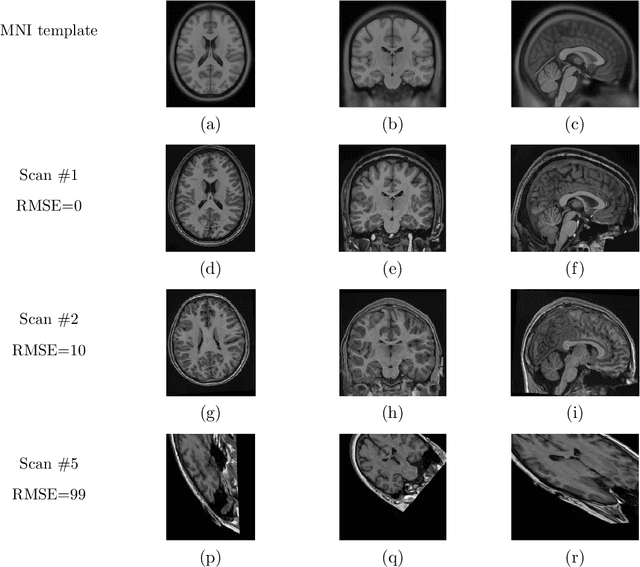
Registration of one or several brain image(s) onto a common reference space defined by a template is a necessary prerequisite for many image processing tasks, such as brain structure segmentation or functional MRI study. Manual assessment of registration quality is a tedious and time-consuming task, especially when a large amount of data is involved. An automated and reliable quality control (QC) is thus mandatory. Moreover, the computation time of the QC must be also compatible with the processing of massive datasets. Therefore, deep neural network approaches appear as a method of choice to automatically assess registration quality. In the current study, a compact 3D CNN, referred to as RegQCNET, is introduced to quantitatively predict the amplitude of a registration mismatch between the registered image and the reference template. This quantitative estimation of registration error is expressed using metric unit system. Therefore, a meaningful task-specific threshold can be manually or automatically defined in order to distinguish usable and non-usable images. The robustness of the proposed RegQCNET is first analyzed on lifespan brain images undergoing various simulated spatial transformations and intensity variations between training and testing. Secondly, the potential of RegQCNET to classify images as usable or non-usable is evaluated using both manual and automatic thresholds. The latters were estimated using several computer-assisted classification models through cross-validation. To this end we used expert's visual quality control estimated on a lifespan cohort of 3953 brains. Finally, the RegQCNET accuracy is compared to usual image features such as image correlation coefficient and mutual information. Results show that the proposed deep learning QC is robust, fast and accurate to estimate registration error in processing pipeline.
MovingFashion: a Benchmark for the Video-to-Shop Challenge
Oct 14, 2021
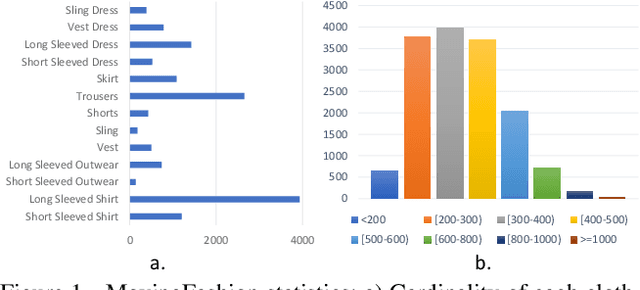

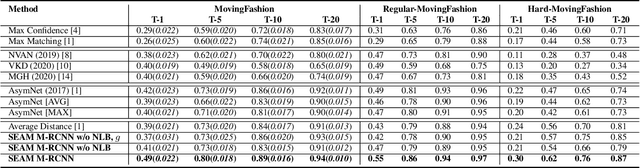
Retrieving clothes which are worn in social media videos (Instagram, TikTok) is the latest frontier of e-fashion, referred to as "video-to-shop" in the computer vision literature. In this paper we present MovingFashion, the first publicly available dataset to cope with this challenge. MovingFashion is composed of 14855 social videos, each one of them associated to e-commerce "shop" images where the corresponding clothing items are clearly portrayed. In addition, we present a network for retrieving the shop images in this scenario, dubbed SEAM Match-RCNN. The model is trained by image-to-video domain adaptation, allowing to use video sequences where only their association with a shop image is given, eliminating the need of millions of annotated bounding boxes. SEAM Match-RCNN builds an embedding, where an attention-based weighted sum of few frames (10) of a social video is enough to individuate the correct product within the first 5 retrieved items in a 14K+ shop element gallery with an accuracy of 80%. This provides the best performance on MovingFashion, comparing exhaustively against the related state-of-the-art approaches and alternative baselines.