 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ADOP: Approximate Differentiable One-Pixel Point Rendering
Oct 15, 2021



We present a novel point-based, differentiable neural rendering pipeline for scene refinement and novel view synthesis. The input are an initial estimate of the point cloud and the camera parameters. The output are synthesized images from arbitrary camera poses. The point cloud rendering is performed by a differentiable renderer using multi-resolution one-pixel point rasterization. Spatial gradients of the discrete rasterization are approximated by the novel concept of ghost geometry. After rendering, the neural image pyramid is passed through a deep neural network for shading calculations and hole-filling. A differentiable, physically-based tonemapper then converts the intermediate output to the target image. Since all stages of the pipeline are differentiable, we optimize all of the scene's parameters i.e. camera model, camera pose, point position, point color, environment map, rendering network weights, vignetting, camera response function, per image exposure, and per image white balance. We show that our system is able to synthesize sharper and more consistent novel views than existing approaches because the initial reconstruction is refined during training. The efficient one-pixel point rasterization allows us to use arbitrary camera models and display scenes with well over 100M points in real time.
On the Robustness and Generalization of Deep Learning Driven Full Waveform Inversion
Nov 28, 2021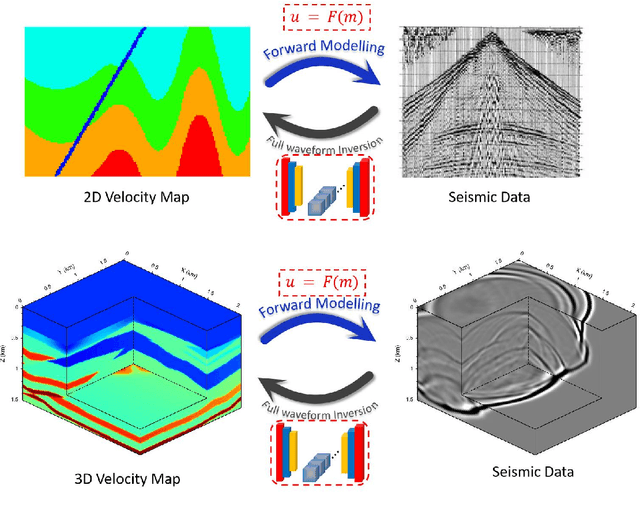
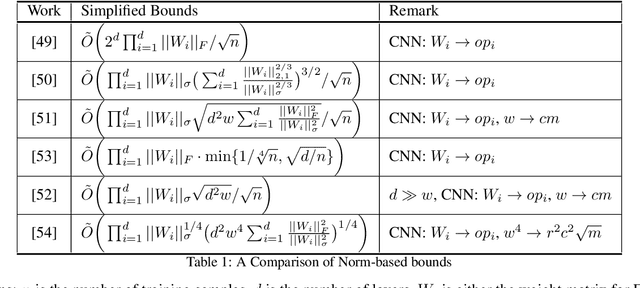
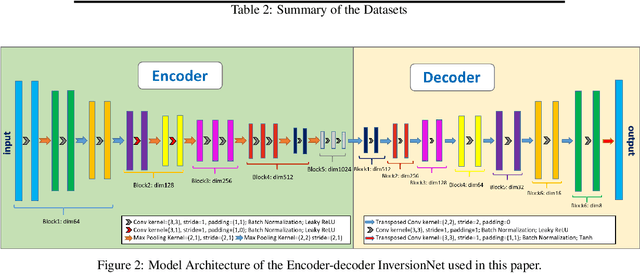
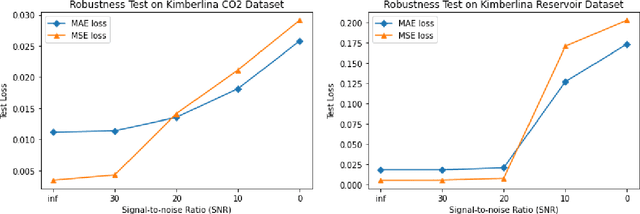
The data-driven approach has been demonstrated as a promising technique to solve complicated scientific problems. Full Waveform Inversion (FWI) is commonly epitomized as an image-to-image translation task, which motivates the use of deep neural networks as an end-to-end solution. Despite being trained with synthetic data, the deep learning-driven FWI is expected to perform well when evaluated with sufficient real-world data. In this paper, we study such properties by asking: how robust are these deep neural networks and how do they generalize? For robustness, we prove the upper bounds of the deviation between the predictions from clean and noisy data. Moreover, we demonstrate an interplay between the noise level and the additional gain of loss. For generalization, we prove a norm-based generalization error upper bound via a stability-generalization framework. Experimental results on seismic FWI datasets corroborate with the theoretical results, shedding light on a better understanding of utilizing Deep Learning for complicated scientific applications.
Feels Bad Man: Dissecting Automated Hateful Meme Detection Through the Lens of Facebook's Challenge
Feb 17, 2022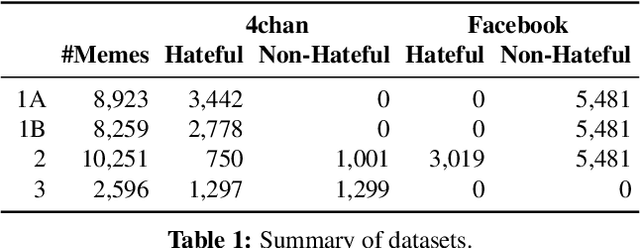
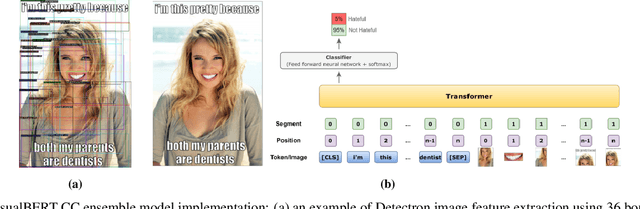

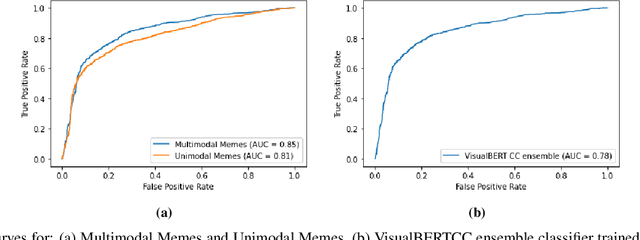
Internet memes have become a dominant method of communication; at the same time, however, they are also increasingly being used to advocate extremism and foster derogatory beliefs. Nonetheless, we do not have a firm understanding as to which perceptual aspects of memes cause this phenomenon. In this work, we assess the efficacy of current state-of-the-art multimodal machine learning models toward hateful meme detection, and in particular with respect to their generalizability across platforms. We use two benchmark datasets comprising 12,140 and 10,567 images from 4chan's "Politically Incorrect" board (/pol/) and Facebook's Hateful Memes Challenge dataset to train the competition's top-ranking machine learning models for the discovery of the most prominent features that distinguish viral hateful memes from benign ones. We conduct three experiments to determine the importance of multimodality on classification performance, the influential capacity of fringe Web communities on mainstream social platforms and vice versa, and the models' learning transferability on 4chan memes. Our experiments show that memes' image characteristics provide a greater wealth of information than its textual content. We also find that current systems developed for online detection of hate speech in memes necessitate further concentration on its visual elements to improve their interpretation of underlying cultural connotations, implying that multimodal models fail to adequately grasp the intricacies of hate speech in memes and generalize across social media platforms.
Conditional Image Retrieval
Jul 14, 2020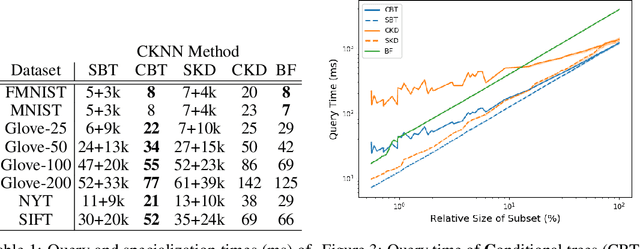
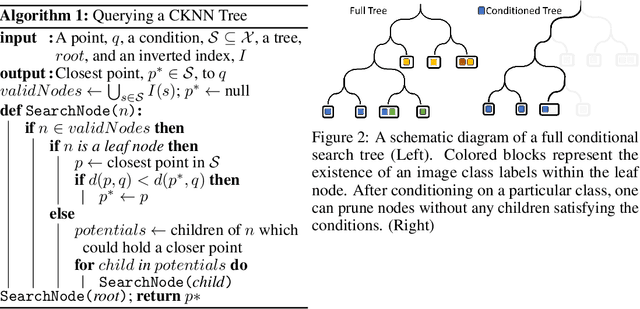
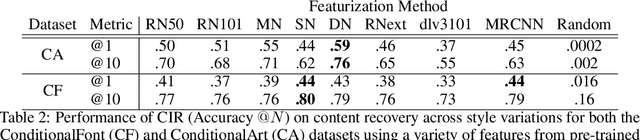
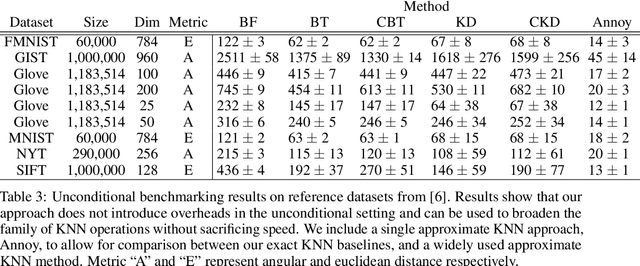
This work introduces Conditional Image Retrieval (CIR) systems: IR methods that can efficiently specialize to specific subsets of images on the fly. These systems broaden the class of queries IR systems support, and eliminate the need for expensive re-fitting to specific subsets of data. Specifically, we adapt tree-based K-Nearest Neighbor (KNN) data-structures to the conditional setting by introducing additional inverted-index data-structures. This speeds conditional queries and does not slow queries without conditioning. We present two new datasets for evaluating the performance of CIR systems and evaluate a variety of design choices. As a motivating application, we present an algorithm that can explore shared semantic content between works of art of vastly different media and cultural origin. Finally, we demonstrate that CIR data-structures can identify Generative Adversarial Network (GAN) ``blind spots'': areas where GANs fail to properly model the true data distribution.
NTIRE 2020 Challenge on Image and Video Deblurring
May 10, 2020
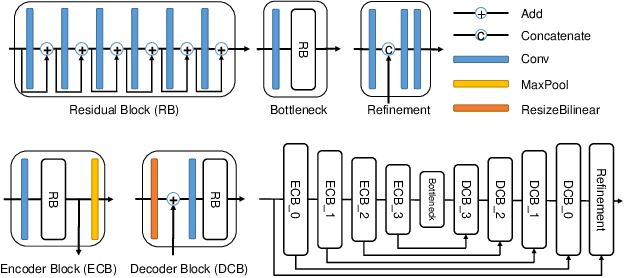
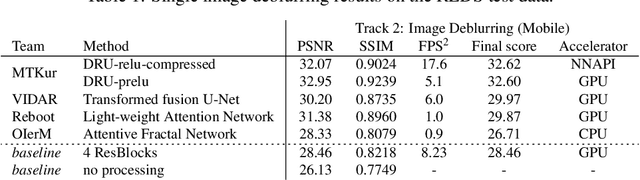
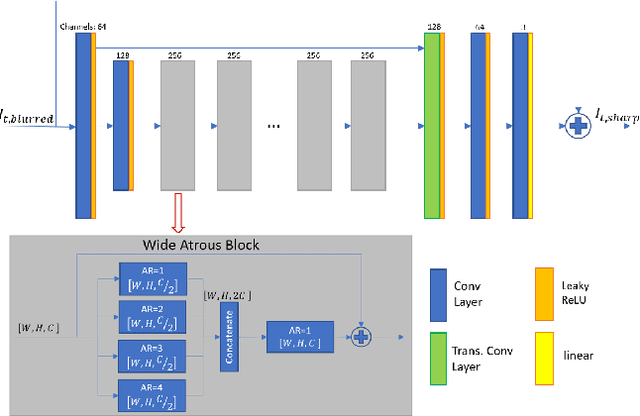
Motion blur is one of the most common degradation artifacts in dynamic scene photography. This paper reviews the NTIRE 2020 Challenge on Image and Video Deblurring. In this challenge, we present the evaluation results from 3 competition tracks as well as the proposed solutions. Track 1 aims to develop single-image deblurring methods focusing on restoration quality. On Track 2, the image deblurring methods are executed on a mobile platform to find the balance of the running speed and the restoration accuracy. Track 3 targets developing video deblurring methods that exploit the temporal relation between input frames. In each competition, there were 163, 135, and 102 registered participants and in the final testing phase, 9, 4, and 7 teams competed. The winning methods demonstrate the state-ofthe-art performance on image and video deblurring tasks.
Adaptation and Attention for Neural Video Coding
Dec 16, 2021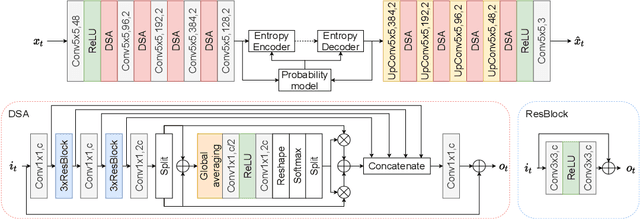
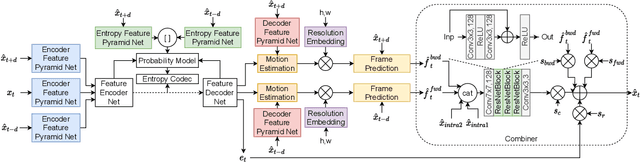
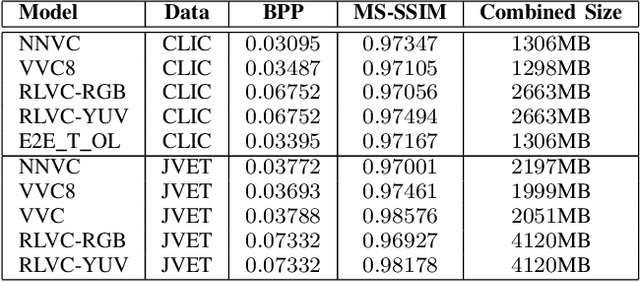
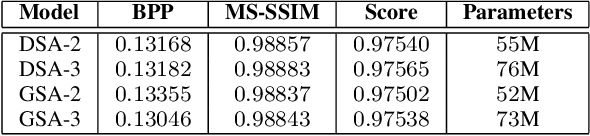
Neural image coding represents now the state-of-the-art image compression approach. However, a lot of work is still to be done in the video domain. In this work, we propose an end-to-end learned video codec that introduces several architectural novelties as well as training novelties, revolving around the concepts of adaptation and attention. Our codec is organized as an intra-frame codec paired with an inter-frame codec. As one architectural novelty, we propose to train the inter-frame codec model to adapt the motion estimation process based on the resolution of the input video. A second architectural novelty is a new neural block that combines concepts from split-attention based neural networks and from DenseNets. Finally, we propose to overfit a set of decoder-side multiplicative parameters at inference time. Through ablation studies and comparisons to prior art, we show the benefits of our proposed techniques in terms of coding gains. We compare our codec to VVC/H.266 and RLVC, which represent the state-of-the-art traditional and end-to-end learned codecs, respectively, and to the top performing end-to-end learned approach in 2021 CLIC competition, E2E_T_OL. Our codec clearly outperforms E2E_T_OL, and compare favorably to VVC and RLVC in some settings.
A Comprehensive Evaluation on Multi-channel Biometric Face Presentation Attack Detection
Feb 21, 2022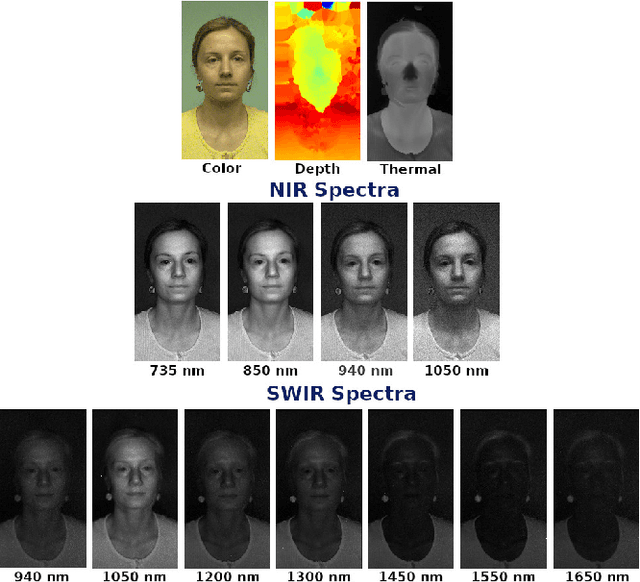

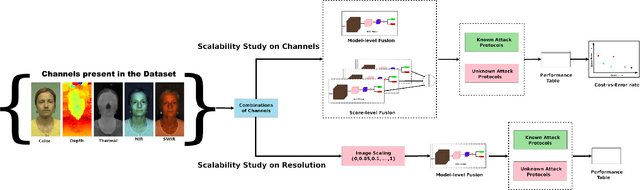
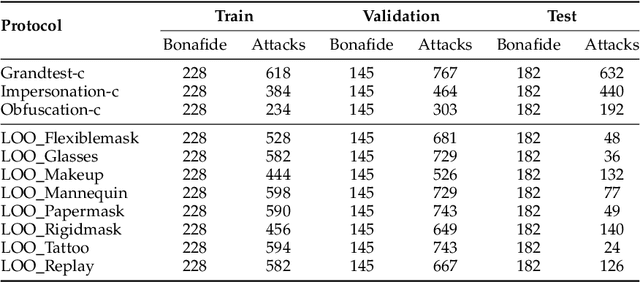
The vulnerability against presentation attacks is a crucial problem undermining the wide-deployment of face recognition systems. Though presentation attack detection (PAD) systems try to address this problem, the lack of generalization and robustness continues to be a major concern. Several works have shown that using multi-channel PAD systems could alleviate this vulnerability and result in more robust systems. However, there is a wide selection of channels available for a PAD system such as RGB, Near Infrared, Shortwave Infrared, Depth, and Thermal sensors. Having a lot of sensors increases the cost of the system, and therefore an understanding of the performance of different sensors against a wide variety of attacks is necessary while selecting the modalities. In this work, we perform a comprehensive study to understand the effectiveness of various imaging modalities for PAD. The studies are performed on a multi-channel PAD dataset, collected with 14 different sensing modalities considering a wide range of 2D, 3D, and partial attacks. We used the multi-channel convolutional network-based architecture, which uses pixel-wise binary supervision. The model has been evaluated with different combinations of channels, and different image qualities on a variety of challenging known and unknown attack protocols. The results reveal interesting trends and can act as pointers for sensor selection for safety-critical presentation attack detection systems. The source codes and protocols to reproduce the results are made available publicly making it possible to extend this work to other architectures.
Dual Attention on Pyramid Feature Maps for Image Captioning
Nov 02, 2020
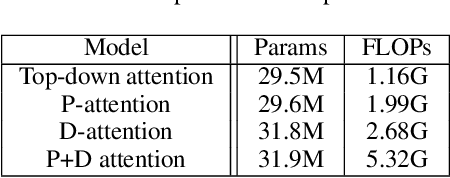
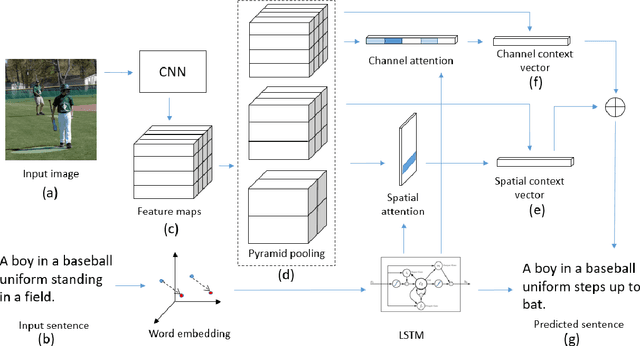
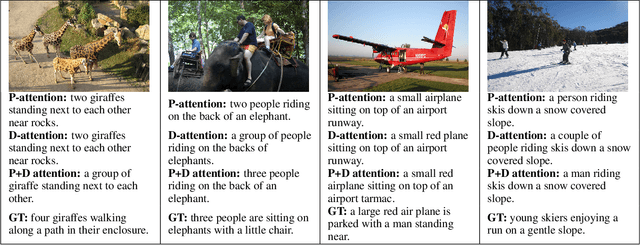
Generating natural sentences from images is a fundamental learning task for visual-semantic understanding in multimedia. In this paper, we propose to apply dual attention on pyramid image feature maps to fully explore the visual-semantic correlations and improve the quality of generated sentences. Specifically, with the full consideration of the contextual information provided by the hidden state of the RNN controller, the pyramid attention can better localize the visually indicative and semantically consistent regions in images. On the other hand, the contextual information can help re-calibrate the importance of feature components by learning the channel-wise dependencies, to improve the discriminative power of visual features for better content description. We conducted comprehensive experiments on three well-known datasets: Flickr8K, Flickr30K and MS COCO, which achieved impressive results in generating descriptive and smooth natural sentences from images. Using either convolution visual features or more informative bottom-up attention features, our composite captioning model achieves very promising performance in a single-model mode. The proposed pyramid attention and dual attention methods are highly modular, which can be inserted into various image captioning modules to further improve the performance.
Delivery Issues Identification from Customer Feedback Data
Dec 26, 2021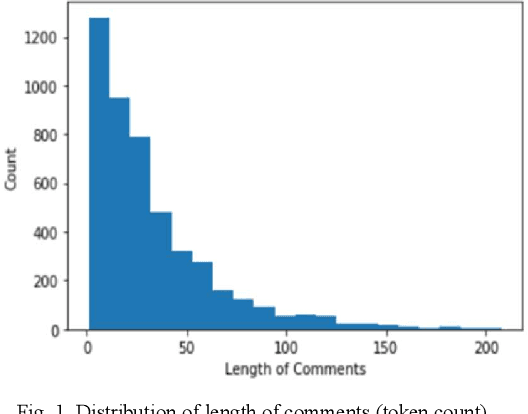

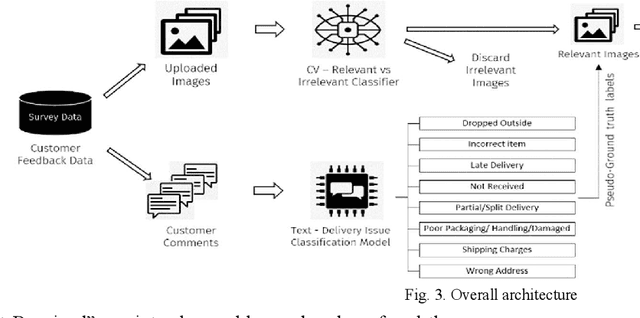

Millions of packages are delivered successfully by online and local retail stores across the world every day. The proper delivery of packages is needed to ensure high customer satisfaction and repeat purchases. These deliveries suffer various problems despite the best efforts from the stores. These issues happen not only due to the large volume and high demand for low turnaround time but also due to mechanical operations and natural factors. These issues range from receiving wrong items in the package to delayed shipment to damaged packages because of mishandling during transportation. Finding solutions to various delivery issues faced by both sending and receiving parties plays a vital role in increasing the efficiency of the entire process. This paper shows how to find these issues using customer feedback from the text comments and uploaded images. We used transfer learning for both Text and Image models to minimize the demand for thousands of labeled examples. The results show that the model can find different issues. Furthermore, it can also be used for tasks like bottleneck identification, process improvement, automating refunds, etc. Compared with the existing process, the ensemble of text and image models proposed in this paper ensures the identification of several types of delivery issues, which is more suitable for the real-life scenarios of delivery of items in retail businesses. This method can supply a new idea of issue detection for the delivery of packages in similar industries.
Bubble identification from images with machine learning methods
Feb 07, 2022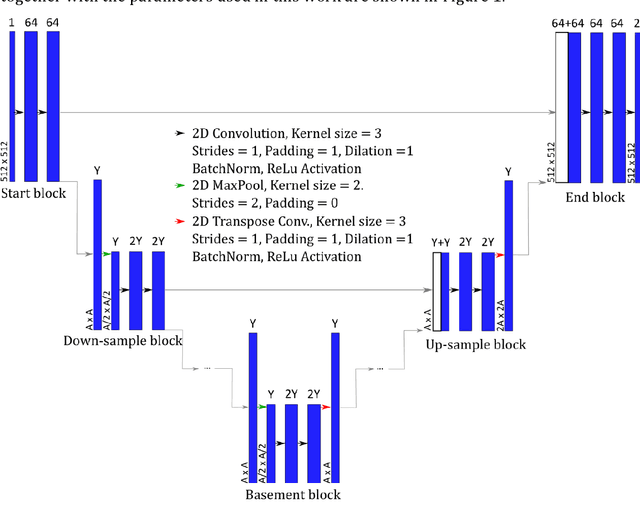
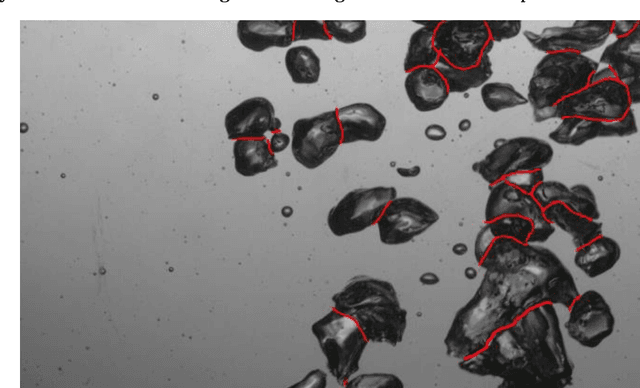
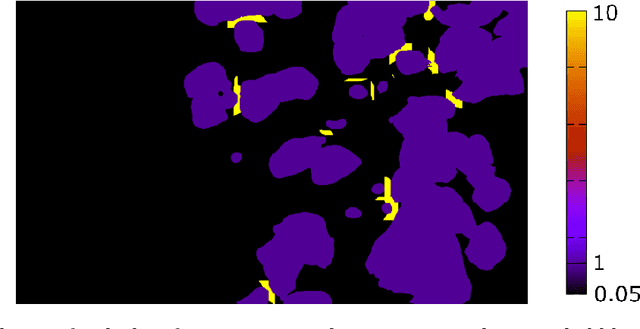
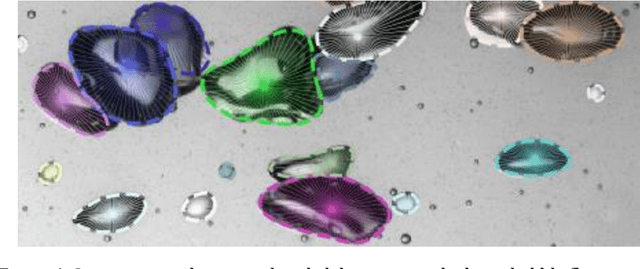
An automated and reliable processing of bubbly flow images is highly needed to analyse large data sets of comprehensive experimental series. A particular difficulty arises due to overlapping bubble projections in recorded images, which highly complicates the identification of individual bubbles. Recent approaches focus on the use of deep learning algorithms for this task and have already proven the high potential of such techniques. The main difficulties are the capability to handle different image conditions, higher gas volume fractions and a proper reconstruction of the hidden segment of a partly occluded bubble. In the present work, we try to tackle these points by testing three different methods based on Convolutional Neural Networks (CNNs) for the two former and two individual approaches that can be used subsequently to address the latter. To validate our methodology, we created test data sets with synthetic images that further demonstrate the capabilities as well as limitations of our combined approach. The generated data, code and trained models are made accessible to facilitate the use as well as further developments in the research field of bubble recognition in experimental images.