 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SNR-adaptive deep joint source-channel coding for wireless image transmission
Feb 02, 2021
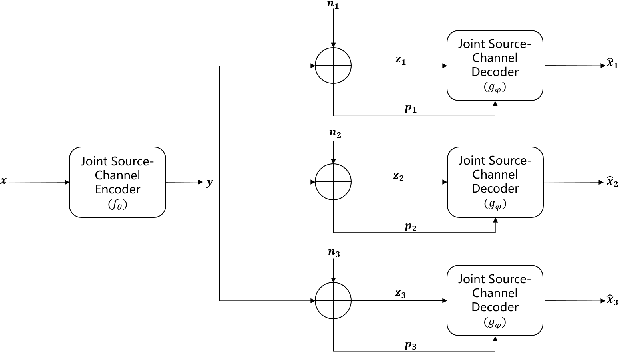
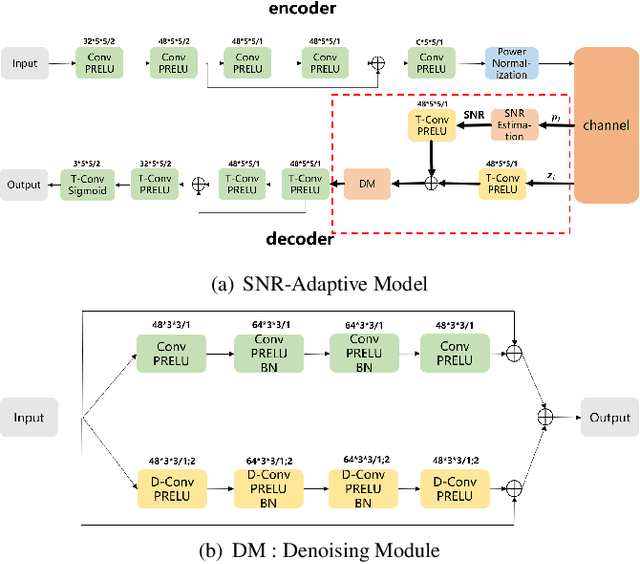
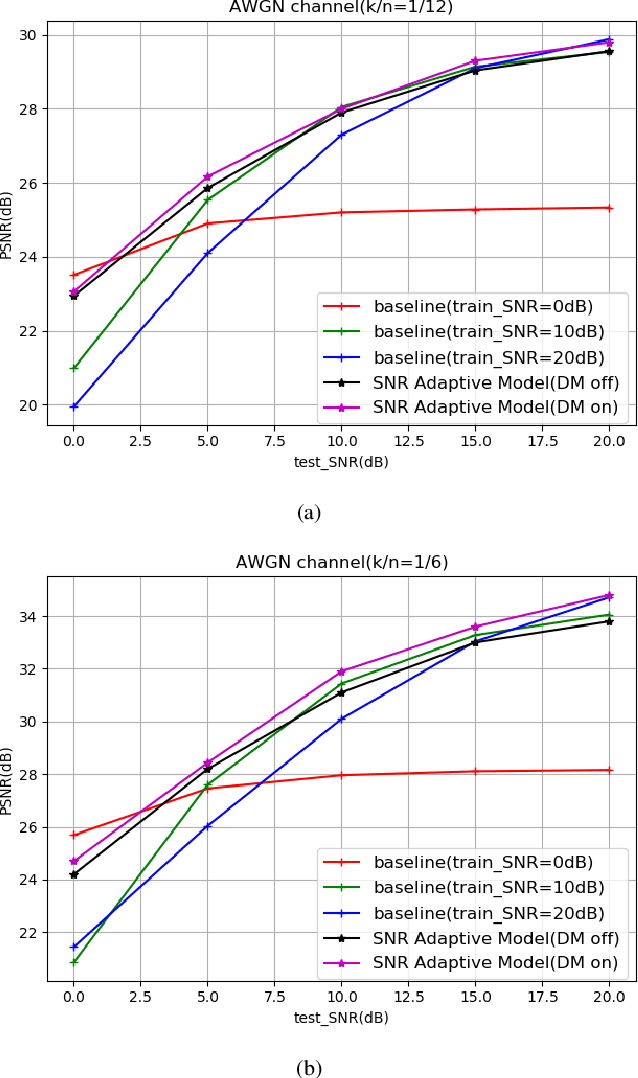
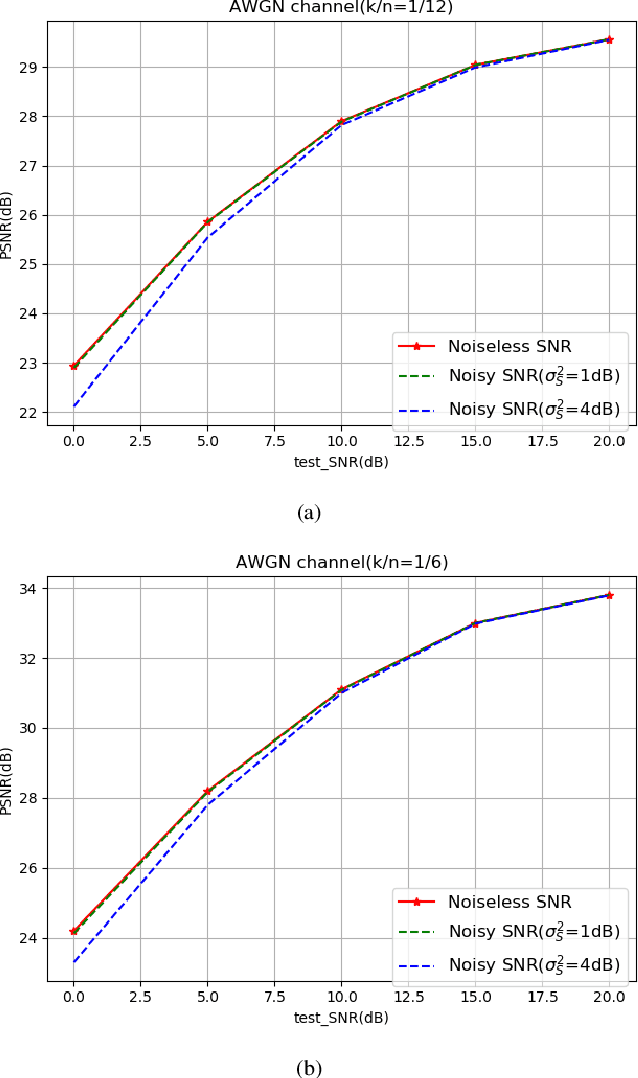
Considering the problem of joint source-channel coding (JSCC) for multi-user transmission of images over noisy channels, an autoencoder-based novel deep joint source-channel coding scheme is proposed in this paper. In the proposed JSCC scheme, the decoder can estimate the signal-to-noise ratio (SNR) and use it to adaptively decode the transmitted image. Experiments demonstrate that the proposed scheme achieves impressive results in adaptability for different SNRs and is robust to the decoder's estimation error of the SNR. To the best of our knowledge, this is the first deep JSCC scheme that focuses on the adaptability for different SNRs and can be applied to multi-user scenarios.
Localized Super Resolution for Foreground Images using U-Net and MR-CNN
Oct 27, 2021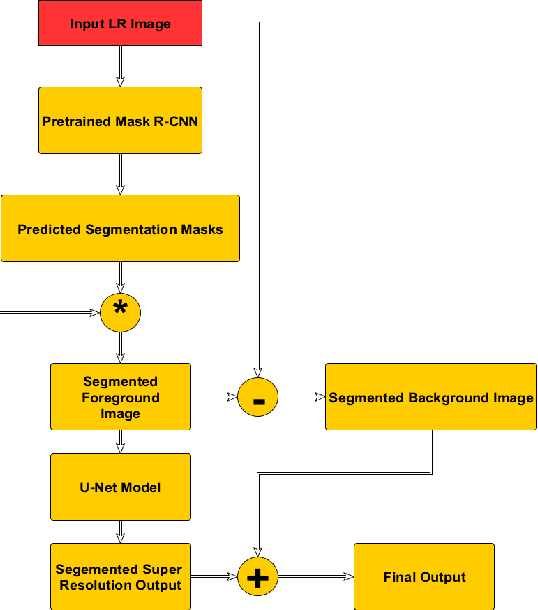
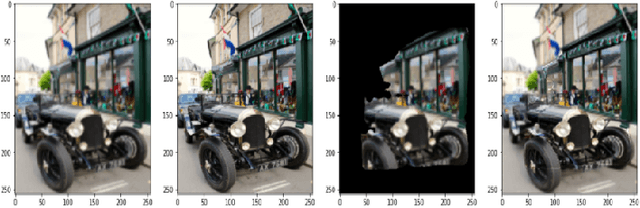
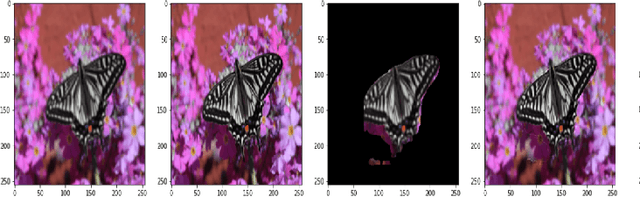
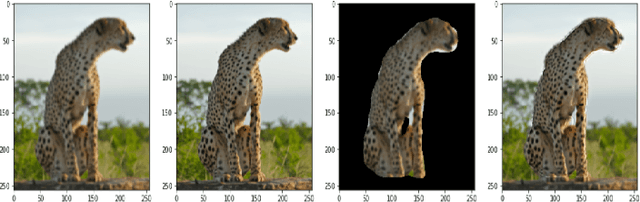
Images play a vital role in understanding data through visual representation. It gives a clear representation of the object in context. But if this image is not clear it might not be of much use. Thus, the topic of Image Super Resolution arose and many researchers have been working towards applying Computer Vision and Deep Learning Techniques to increase the quality of images. One of the applications of Super Resolution is to increase the quality of Portrait Images. Portrait Images are images which mainly focus on capturing the essence of the main object in the frame, where the object in context is highlighted whereas the background is occluded. When performing Super Resolution the model tries to increase the overall resolution of the image. But in portrait images the foreground resolution is more important than that of the background. In this paper, the performance of a Convolutional Neural Network (CNN) architecture known as U-Net for Super Resolution combined with Mask Region Based CNN (MR-CNN) for foreground super resolution is analysed. This analysis is carried out based on Localized Super Resolution i.e. We pass the LR Images to a pre-trained Image Segmentation model (MR-CNN) and perform super resolution inference on the foreground or Segmented Images and compute the Structural Similarity Index (SSIM) and Peak Signal-to-Noise Ratio (PSNR) metrics for comparisons.
A Spectral-Spatial-Dependent Global Learning Framework for Insufficient and Imbalanced Hyperspectral Image Classification
May 29, 2021
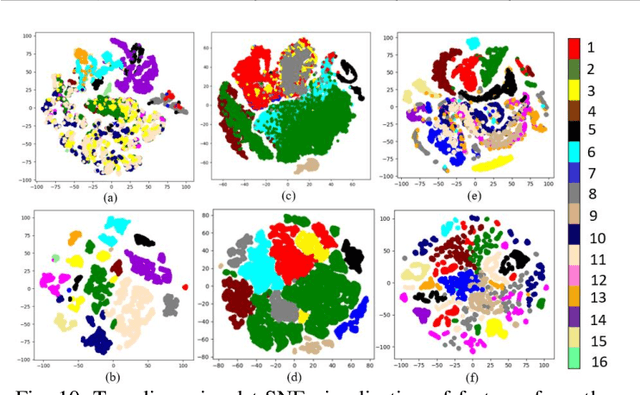
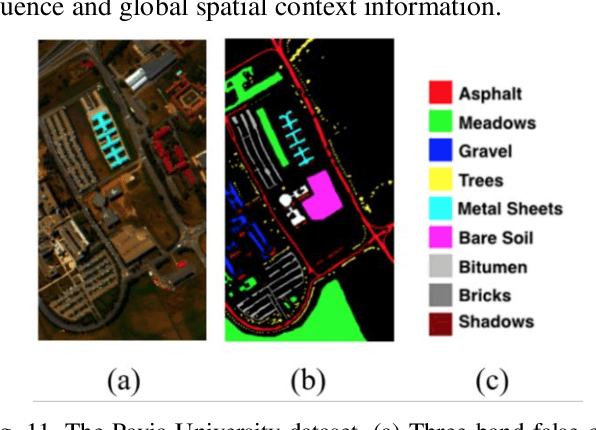

Deep learning techniques have been widely applied to hyperspectral image (HSI) classification and have achieved great success. However, the deep neural network model has a large parameter space and requires a large number of labeled data. Deep learning methods for HSI classification usually follow a patchwise learning framework. Recently, a fast patch-free global learning (FPGA) architecture was proposed for HSI classification according to global spatial context information. However, FPGA has difficulty extracting the most discriminative features when the sample data is imbalanced. In this paper, a spectral-spatial dependent global learning (SSDGL) framework based on global convolutional long short-term memory (GCL) and global joint attention mechanism (GJAM) is proposed for insufficient and imbalanced HSI classification. In SSDGL, the hierarchically balanced (H-B) sampling strategy and the weighted softmax loss are proposed to address the imbalanced sample problem. To effectively distinguish similar spectral characteristics of land cover types, the GCL module is introduced to extract the long short-term dependency of spectral features. To learn the most discriminative feature representations, the GJAM module is proposed to extract attention areas. The experimental results obtained with three public HSI datasets show that the SSDGL has powerful performance in insufficient and imbalanced sample problems and is superior to other state-of-the-art methods. Code can be obtained at: https://github.com/dengweihuan/SSDGL.
PrivFair: a Library for Privacy-Preserving Fairness Auditing
Feb 09, 2022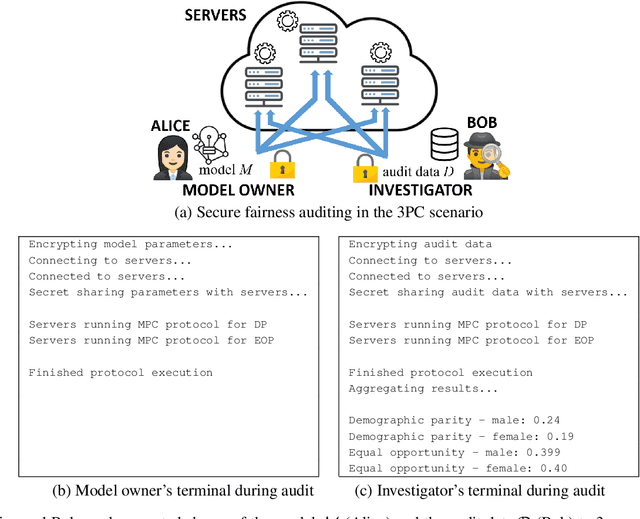

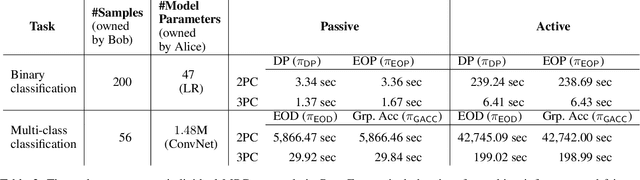
Machine learning (ML) has become prominent in applications that directly affect people's quality of life, including in healthcare, justice, and finance. ML models have been found to exhibit discrimination based on sensitive attributes such as gender, race, or disability. Assessing if an ML model is free of bias remains challenging to date, and by definition has to be done with sensitive user characteristics that are subject of anti-discrimination and data protection law. Existing libraries for fairness auditing of ML models offer no mechanism to protect the privacy of the audit data. We present PrivFair, a library for privacy-preserving fairness audits of ML models. Through the use of Secure Multiparty Computation (MPC), PrivFair protects the confidentiality of the model under audit and the sensitive data used for the audit, hence it supports scenarios in which a proprietary classifier owned by a company is audited using sensitive audit data from an external investigator. We demonstrate the use of PrivFair for group fairness auditing with tabular data or image data, without requiring the investigator to disclose their data to anyone in an unencrypted manner, or the model owner to reveal their model parameters to anyone in plaintext.
Main Product Detection with Graph Networks for Fashion
Jan 25, 2022Computer vision has established a foothold in the online fashion retail industry. Main product detection is a crucial step of vision-based fashion product feed parsing pipelines, focused in identifying the bounding boxes that contain the product being sold in the gallery of images of the product page. The current state-of-the-art approach does not leverage the relations between regions in the image, and treats images of the same product independently, therefore not fully exploiting visual and product contextual information. In this paper we propose a model that incorporates Graph Convolutional Networks (GCN) that jointly represent all detected bounding boxes in the gallery as nodes. We show that the proposed method is better than the state-of-the-art, especially, when we consider the scenario where title-input is missing at inference time and for cross-dataset evaluation, our method outperforms previous approaches by a large margin.
URIE: Universal Image Enhancement for Visual Recognition in the Wild
Jul 17, 2020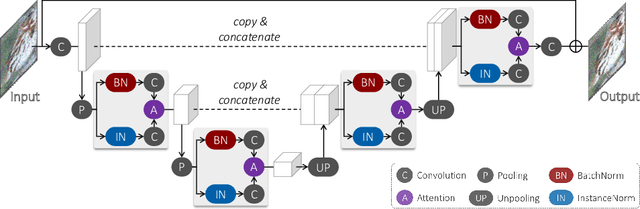

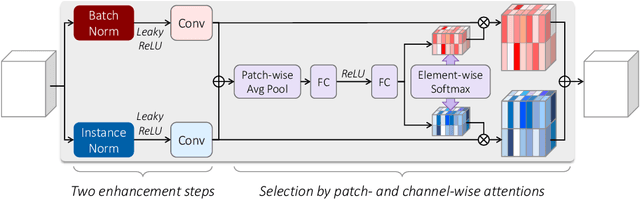

Despite the great advances in visual recognition, it has been witnessed that recognition models trained on clean images of common datasets are not robust against distorted images in the real world. To tackle this issue, we present a Universal and Recognition-friendly Image Enhancement network, dubbed URIE, which is attached in front of existing recognition models and enhances distorted input to improve their performance without retraining them. URIE is universal in that it aims to handle various factors of image degradation and to be incorporated with any arbitrary recognition models. Also, it is recognition-friendly since it is optimized to improve the robustness of following recognition models, instead of perceptual quality of output image. Our experiments demonstrate that URIE can handle various and latent image distortions and improve the performance of existing models for five diverse recognition tasks when input images are degraded.
CSI2Image: Image Reconstruction from Channel State Information Using Generative Adversarial Networks
Sep 16, 2020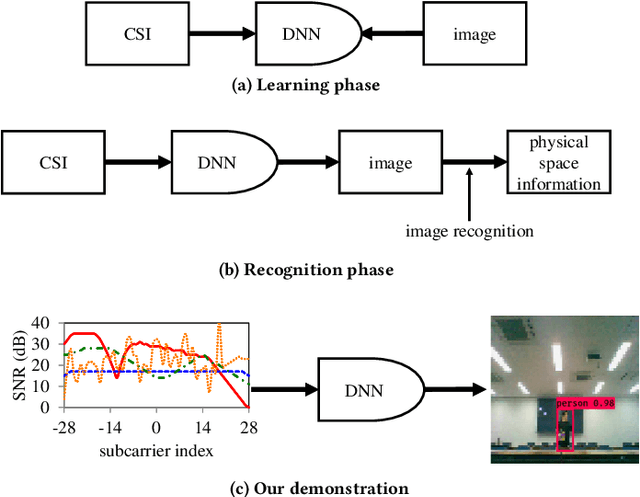


This study aims to find the upper limit of the wireless sensing capability of acquiring physical space information. This is a challenging objective, because at present, wireless sensing studies continue to succeed in acquiring novel phenomena. Thus, although a complete answer cannot be obtained yet, a step is taken towards it here. To achieve this, CSI2Image, a novel channel-state-information (CSI)-to-image conversion method based on generative adversarial networks (GANs), is proposed. The type of physical information acquired using wireless sensing can be estimated by checking wheth\-er the reconstructed image captures the desired physical space information. Three types of learning methods are demonstrated: gen\-er\-a\-tor-only learning, GAN-only learning, and hybrid learning. Evaluating the performance of CSI2Image is difficult, because both the clarity of the image and the presence of the desired physical space information must be evaluated. To solve this problem, a quantitative evaluation methodology using an object detection library is also proposed. CSI2Image was implemented using IEEE 802.11ac compressed CSI, and the evaluation results show that the image was successfully reconstructed. The results demonstrate that gen\-er\-a\-tor-only learning is sufficient for simple wireless sensing problems, but in complex wireless sensing problems, GANs are important for reconstructing generalized images with more accurate physical space information.
Distribution Estimation to Automate Transformation Policies for Self-Supervision
Nov 24, 2021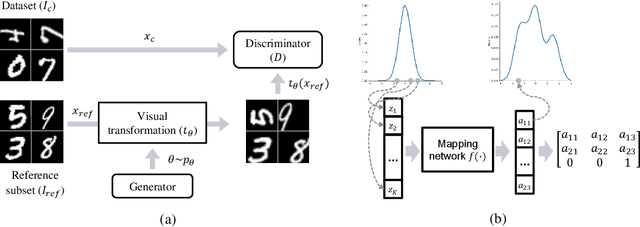
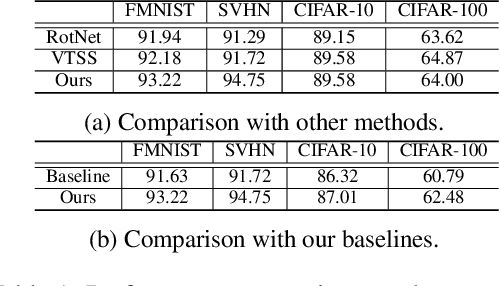
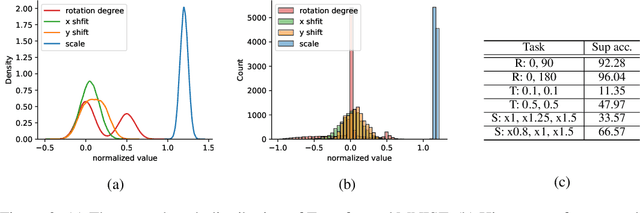
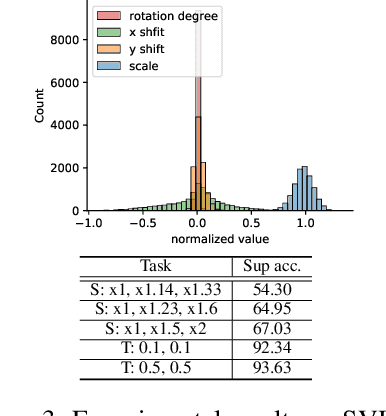
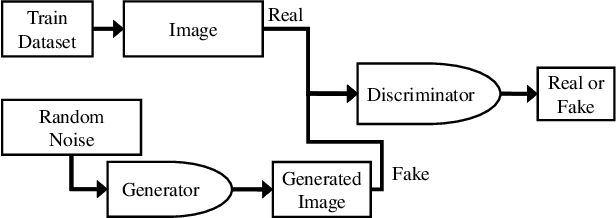
In recent visual self-supervision works, an imitated classification objective, called pretext task, is established by assigning labels to transformed or augmented input images. The goal of pretext can be predicting what transformations are applied to the image. However, it is observed that image transformations already present in the dataset might be less effective in learning such self-supervised representations. Building on this observation, we propose a framework based on generative adversarial network to automatically find the transformations which are not present in the input dataset and thus effective for the self-supervised learning. This automated policy allows to estimate the transformation distribution of a dataset and also construct its complementary distribution from which training pairs are sampled for the pretext task. We evaluated our framework using several visual recognition datasets to show the efficacy of our automated transformation policy.
SA-Net: A deep spectral analysis network for image clustering
Sep 11, 2020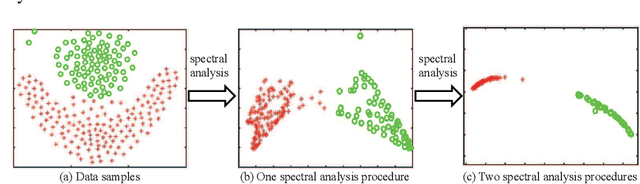
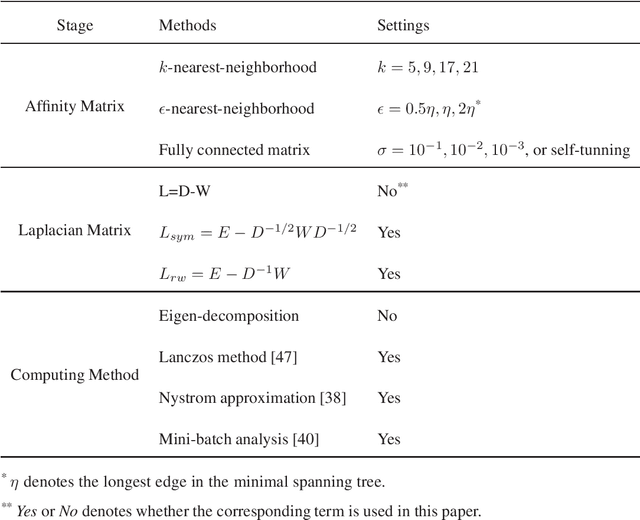

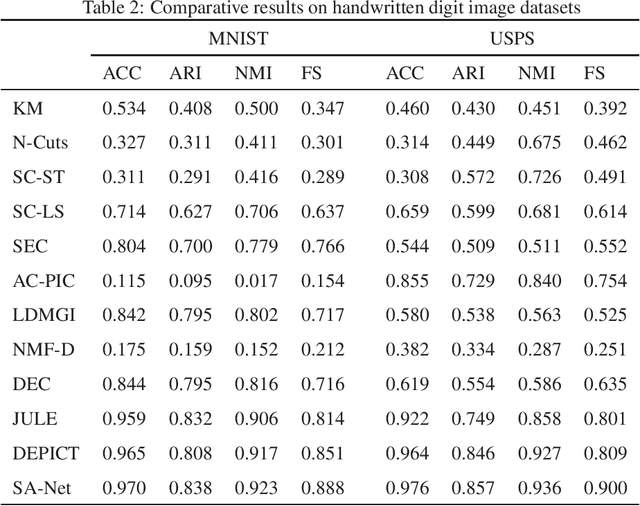
Although supervised deep representation learning has attracted enormous attentions across areas of pattern recognition and computer vision, little progress has been made towards unsupervised deep representation learning for image clustering. In this paper, we propose a deep spectral analysis network for unsupervised representation learning and image clustering. While spectral analysis is established with solid theoretical foundations and has been widely applied to unsupervised data mining, its essential weakness lies in the fact that it is difficult to construct a proper affinity matrix and determine the involving Laplacian matrix for a given dataset. In this paper, we propose a SA-Net to overcome these weaknesses and achieve improved image clustering by extending the spectral analysis procedure into a deep learning framework with multiple layers. The SA-Net has the capability to learn deep representations and reveal deep correlations among data samples. Compared with the existing spectral analysis, the SA-Net achieves two advantages: (i) Given the fact that one spectral analysis procedure can only deal with one subset of the given dataset, our proposed SA-Net elegantly integrates multiple parallel and consecutive spectral analysis procedures together to enable interactive learning across different units towards a coordinated clustering model; (ii) Our SA-Net can identify the local similarities among different images at patch level and hence achieves a higher level of robustness against occlusions. Extensive experiments on a number of popular datasets support that our proposed SA-Net outperforms 11 benchmarks across a number of image clustering applications.
* arXiv admin note: text overlap with arXiv:2009.05235
A Photogrammetry-based Framework to Facilitate Image-based Modeling and Automatic Camera Tracking
Dec 02, 2020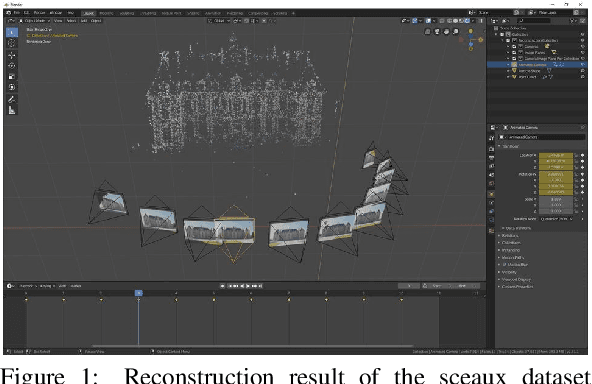
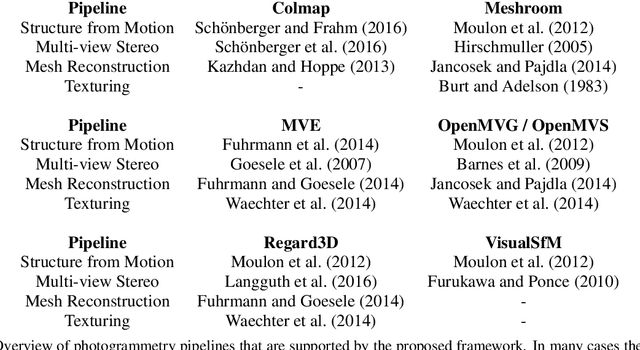
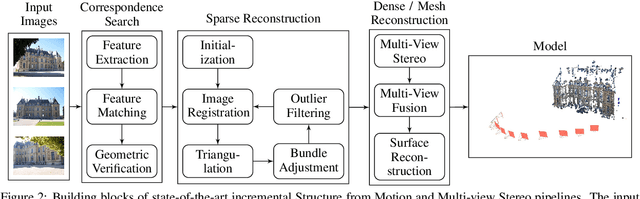

We propose a framework that extends Blender to exploit Structure from Motion (SfM) and Multi-View Stereo (MVS) techniques for image-based modeling tasks such as sculpting or camera and motion tracking. Applying SfM allows us to determine camera motions without manually defining feature tracks or calibrating the cameras used to capture the image data. With MVS we are able to automatically compute dense scene models, which is not feasible with the built-in tools of Blender. Currently, our framework supports several state-of-the-art SfM and MVS pipelines. The modular system design enables us to integrate further approaches without additional effort. The framework is publicly available as an open source software package.