 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Evolving parametrized Loss for Image Classification Learning on Small Datasets
Mar 15, 2021
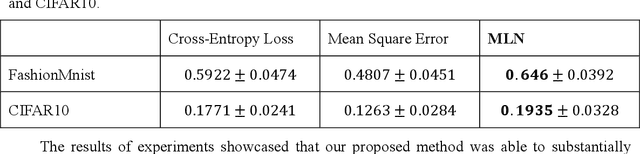
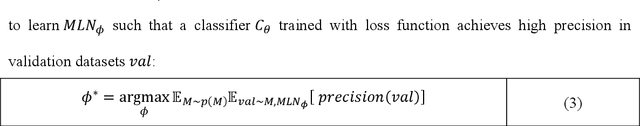
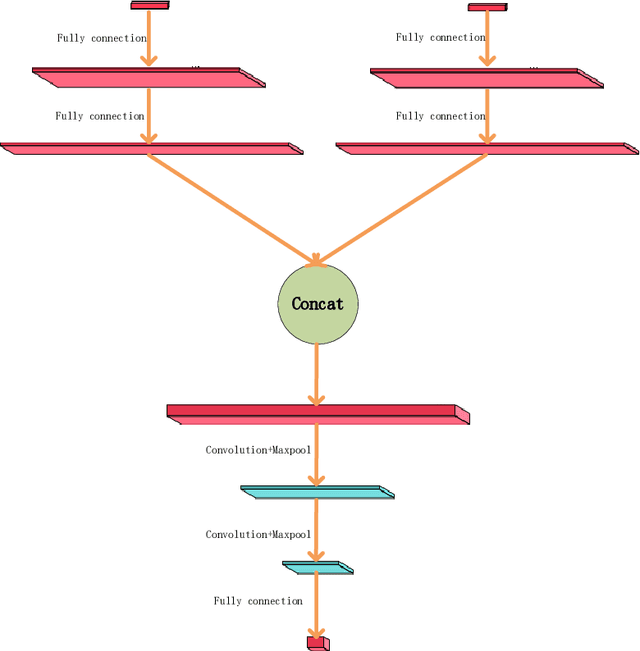
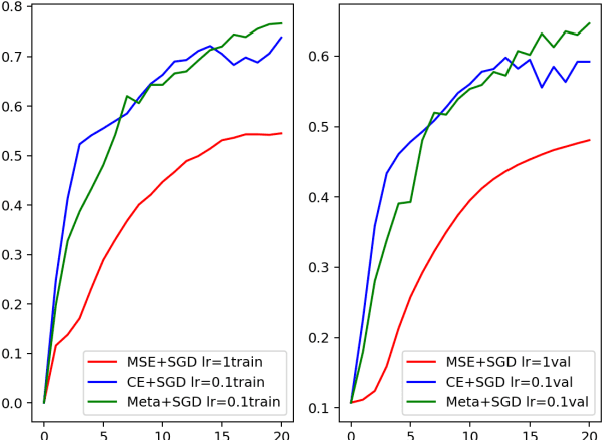
This paper proposes a meta-learning approach to evolving a parametrized loss function, which is called Meta-Loss Network (MLN), for training the image classification learning on small datasets. In our approach, the MLN is embedded in the framework of classification learning as a differentiable objective function. The MLN is evolved with the Evolutionary Strategy algorithm (ES) to an optimized loss function, such that a classifier, which optimized to minimize this loss, will achieve a good generalization effect. A classifier learns on a small training dataset to minimize MLN with Stochastic Gradient Descent (SGD), and then the MLN is evolved with the precision of the small-dataset-updated classifier on a large validation dataset. In order to evaluate our approach, the MLN is trained with a large number of small sample learning tasks sampled from FashionMNIST and tested on validation tasks sampled from FashionMNIST and CIFAR10. Experiment results demonstrate that the MLN effectively improved generalization compared to classical cross-entropy error and mean squared error.
EfficientDeRain: Learning Pixel-wise Dilation Filtering for High-Efficiency Single-Image Deraining
Sep 19, 2020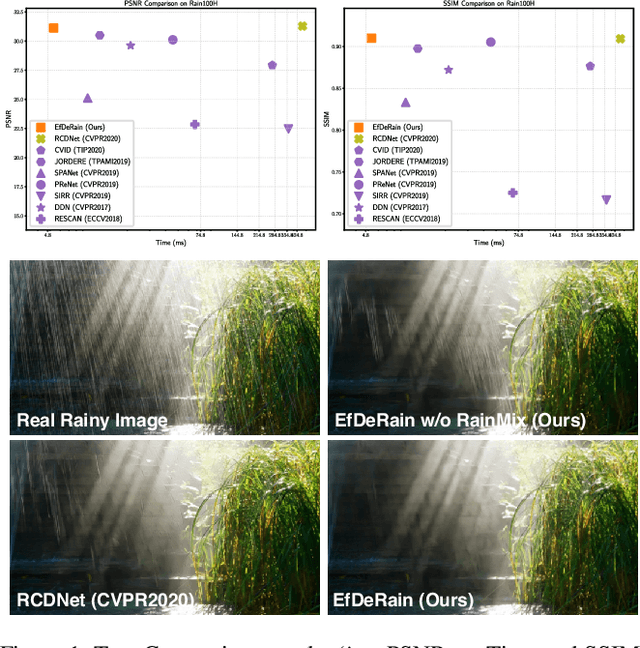

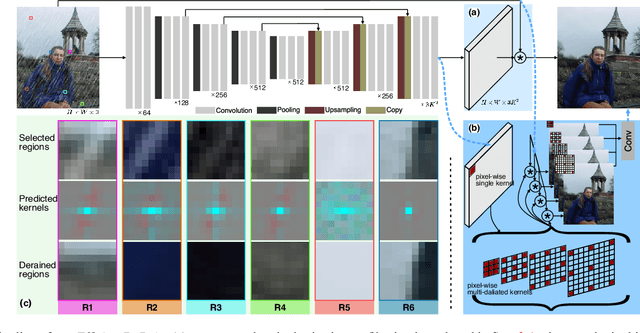

Single-image deraining is rather challenging due to the unknown rain model. Existing methods often make specific assumptions of the rain model, which can hardly cover many diverse circumstances in the real world, making them have to employ complex optimization or progressive refinement. This, however, significantly affects these methods' efficiency and effectiveness for many efficiency-critical applications. To fill this gap, in this paper, we regard the single-image deraining as a general image-enhancing problem and originally propose a model-free deraining method, i.e., EfficientDeRain, which is able to process a rainy image within 10~ms (i.e., around 6~ms on average), over 80 times faster than the state-of-the-art method (i.e., RCDNet), while achieving similar de-rain effects. We first propose the novel pixel-wise dilation filtering. In particular, a rainy image is filtered with the pixel-wise kernels estimated from a kernel prediction network, by which suitable multi-scale kernels for each pixel can be efficiently predicted. Then, to eliminate the gap between synthetic and real data, we further propose an effective data augmentation method (i.e., RainMix) that helps to train network for real rainy image handling.We perform comprehensive evaluation on both synthetic and real-world rainy datasets to demonstrate the effectiveness and efficiency of our method. We release the model and code in https://github.com/tsingqguo/efficientderain.git.
Artificial Intelligence for Suicide Assessment using Audiovisual Cues: A Review
Jan 22, 2022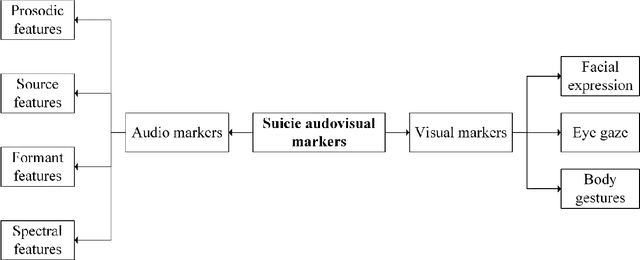
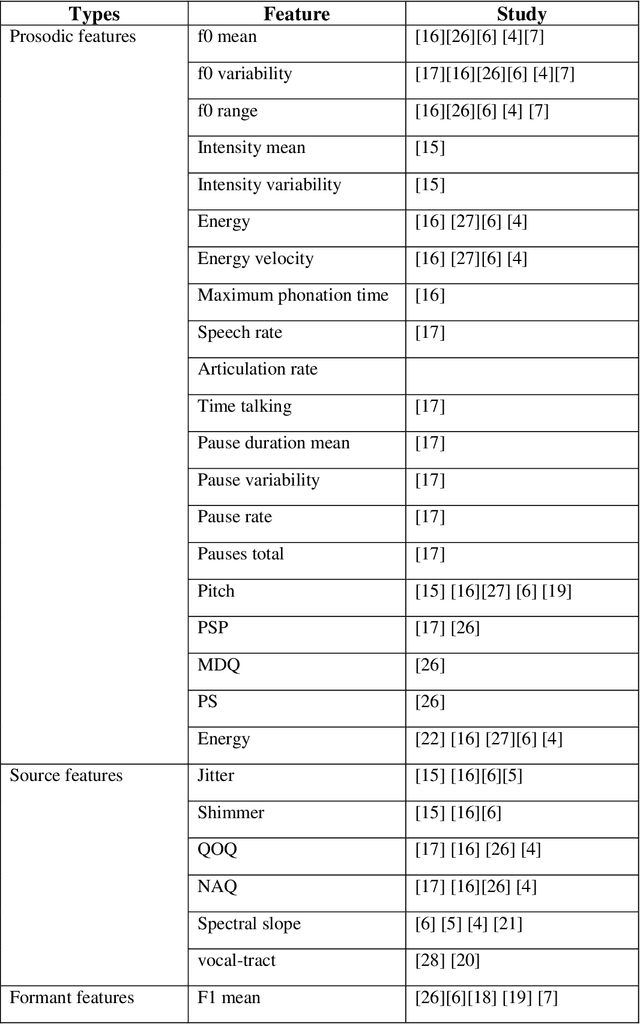
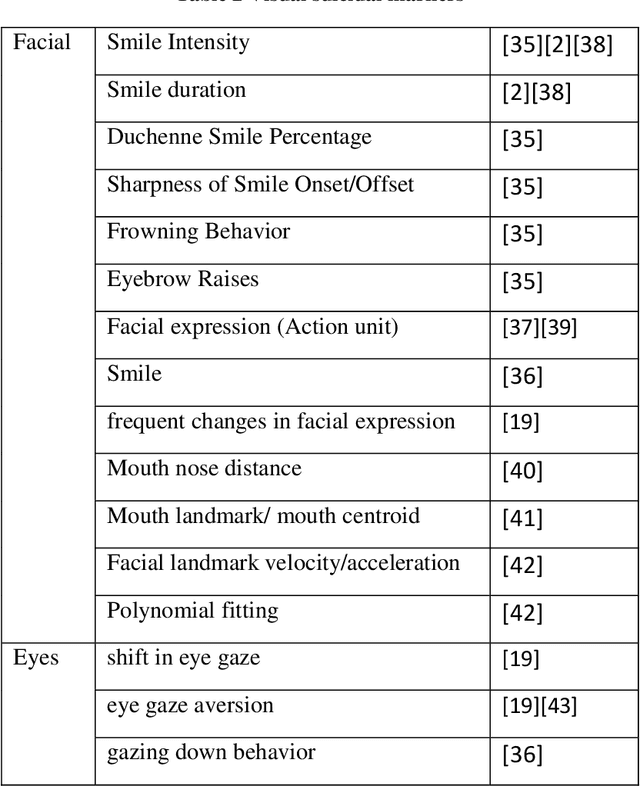
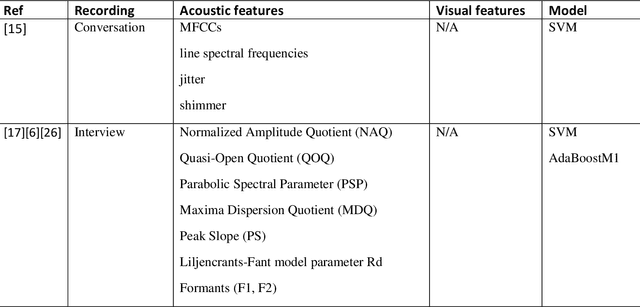
Death by suicide is the seventh of the leading death cause worldwide. The recent advancement in Artificial Intelligence (AI), specifically AI application in image and voice processing, has created a promising opportunity to revolutionize suicide risk assessment. Subsequently, we have witnessed fast-growing literature of researches that applies AI to extract audiovisual non-verbal cues for mental illness assessment. However, the majority of the recent works focus on depression, despite the evident difference between depression signs and suicidal behavior non-verbal cues. In this paper, we review the recent works that study suicide ideation and suicide behavior detection through audiovisual feature analysis, mainly suicidal voice/speech acoustic features analysis and suicidal visual cues.
Modeling Lost Information in Lossy Image Compression
Jul 08, 2020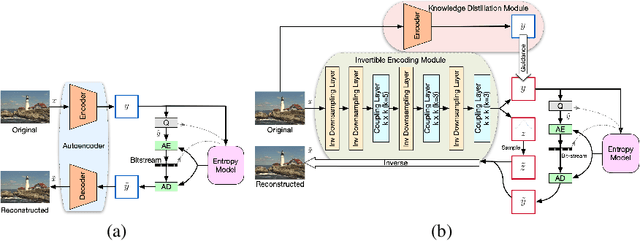
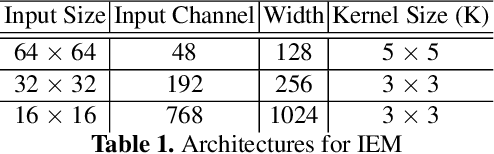

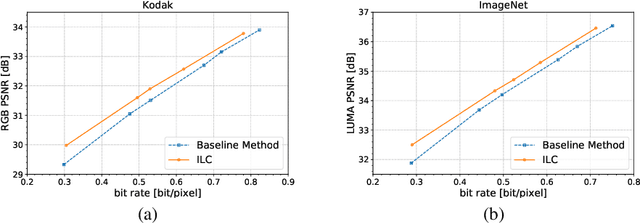
Lossy image compression is one of the most commonly used operators for digital images. Most recently proposed deep-learning-based image compression methods leverage the auto-encoder structure, and reach a series of promising results in this field. The images are encoded into low dimensional latent features first, and entropy coded subsequently by exploiting the statistical redundancy. However, the information lost during encoding is unfortunately inevitable, which poses a significant challenge to the decoder to reconstruct the original images. In this work, we propose a novel invertible framework called Invertible Lossy Compression (ILC) to largely mitigate the information loss problem. Specifically, ILC introduces an invertible encoding module to replace the encoder-decoder structure to produce the low dimensional informative latent representation, meanwhile, transform the lost information into an auxiliary latent variable that won't be further coded or stored. The latent representation is quantized and encoded into bit-stream, and the latent variable is forced to follow a specified distribution, i.e. isotropic Gaussian distribution. In this way, recovering the original image is made tractable by easily drawing a surrogate latent variable and applying the inverse pass of the module with the sampled variable and decoded latent features. Experimental results demonstrate that with a new component replacing the auto-encoder in image compression methods, ILC can significantly outperform the baseline method on extensive benchmark datasets by combining with the existing compression algorithms.
A Color Elastica Model for Vector-Valued Image Regularization
Aug 19, 2020

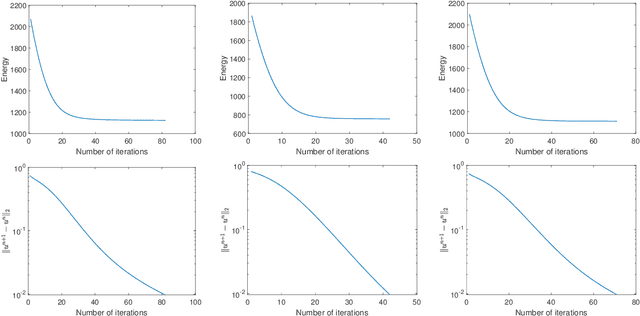

Models related to the Euler's Elastica energy have proven to be very useful for many applications, including image processing and high energy physics. Extending the Elastica models to color images and multi-channel data is challenging, as numerical solvers for these geometric models are difficult to find. In the past, the Polyakov action from high energy physics has been successfully applied for color image processing. Like the single channel Euler's elastica model and the total variation (TV) models, measures that require high order derivatives could help when considering image formation models that minimize elastic properties, in one way or another. Here, we introduce an addition to the Polyakov action for color images that minimizes the color manifold curvature, that is computed by applying of the Laplace-Beltrami operator to the color image channels. When applied to gray scale images, while selecting appropriate scaling between space and color, the proposed model reduces to minimizing the Euler's Elastica operating on the image level sets. Finding a minimizer for the proposed nonlinear geometric model is the challenge we address in this paper. Specifically, we present an operator-splitting method to minimize the proposed functional. The nonlinearity is decoupled by introducing three vector-valued and matrix-valued variables. The problem is then converted into solving for the steady state of an associated initial-value problem. The initial-value problem is time-split into three fractional steps, such that each sub-problem has a closed form solution, or can be solved by fast algorithms. The efficiency, and robustness of the proposed method are demonstrated by systematic numerical experiments.
Iterative regularization algorithms for image denoising with the TV-Stokes model
Sep 24, 2020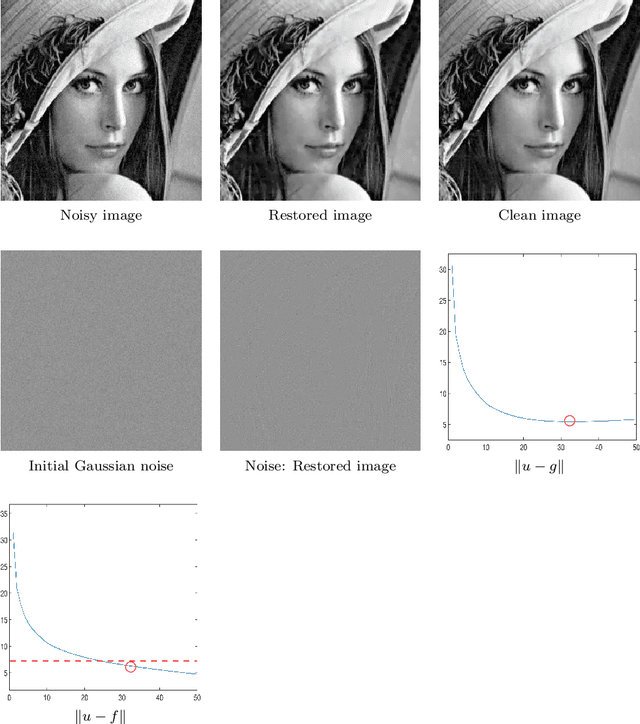

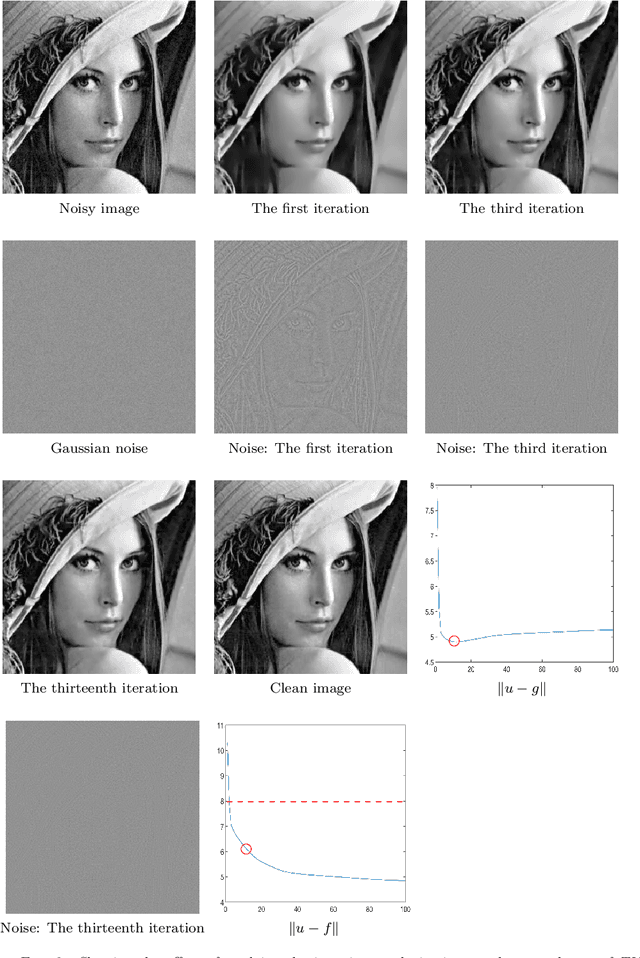
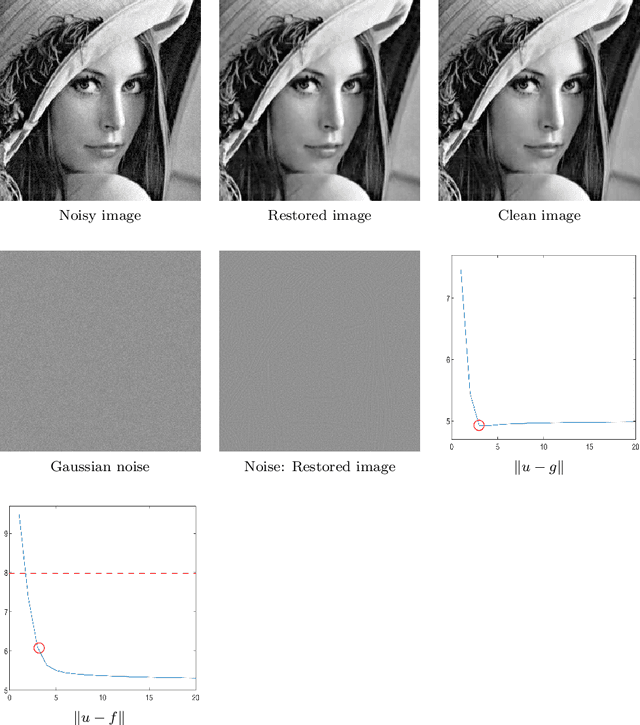
We propose a set of iterative regularization algorithms for the TV-Stokes model to restore images from noisy images with Gaussian noise. These are some extensions of the iterative regularization algorithm proposed for the classical Rudin-Osher-Fatemi (ROF) model for image reconstruction, a single step model involving a scalar field smoothing, to the TV-Stokes model for image reconstruction, a two steps model involving a vector field smoothing in the first and a scalar field smoothing in the second. The iterative regularization algorithms proposed here are Richardson's iteration like. We have experimental results that show improvement over the original method in the quality of the restored image. Convergence analysis and numerical experiments are presented.
Stacked U-Nets with Self-Assisted Priors Towards Robust Correction of Rigid Motion Artifact in Brain MRI
Nov 11, 2021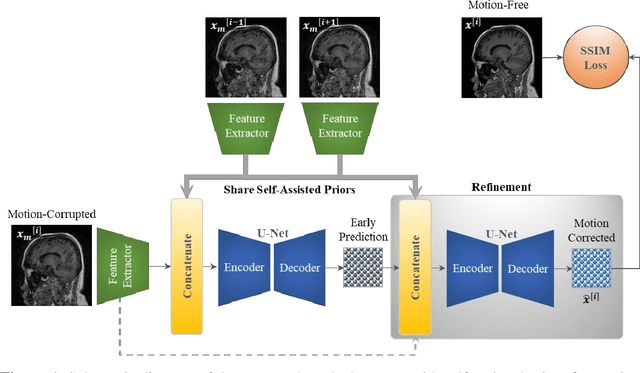

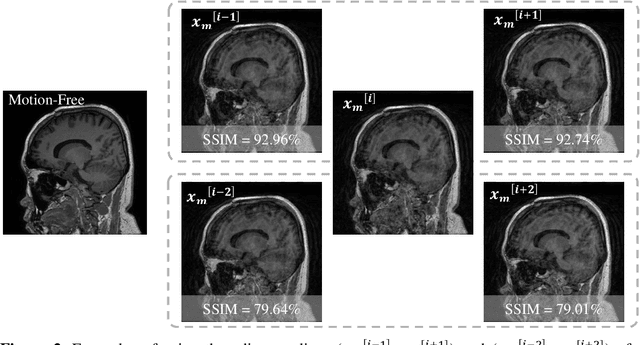
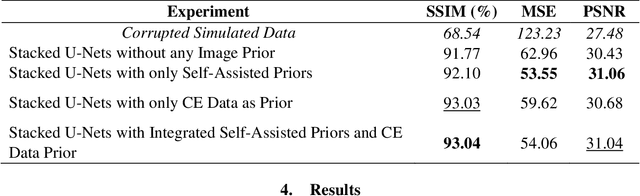
In this paper, we develop an efficient retrospective deep learning method called stacked U-Nets with self-assisted priors to address the problem of rigid motion artifacts in MRI. The proposed work exploits the usage of additional knowledge priors from the corrupted images themselves without the need for additional contrast data. The proposed network learns missed structural details through sharing auxiliary information from the contiguous slices of the same distorted subject. We further design a refinement stacked U-Nets that facilitates preserving of the image spatial details and hence improves the pixel-to-pixel dependency. To perform network training, simulation of MRI motion artifacts is inevitable. We present an intensive analysis using various types of image priors: the proposed self-assisted priors and priors from other image contrast of the same subject. The experimental analysis proves the effectiveness and feasibility of our self-assisted priors since it does not require any further data scans.
Painting Outside as Inside: Edge Guided Image Outpainting via Bidirectional Rearrangement with Step-By-Step Learning
Oct 05, 2020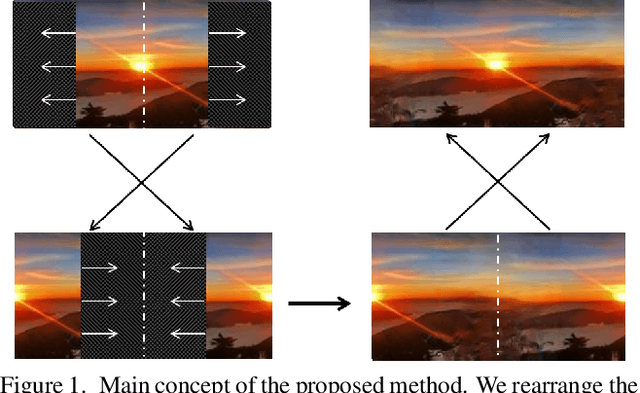
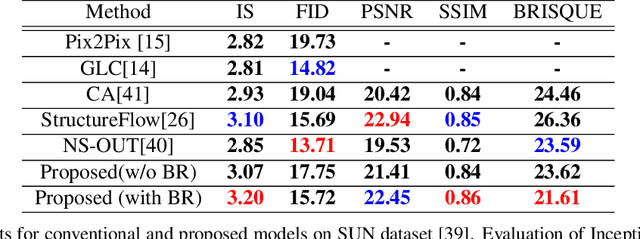
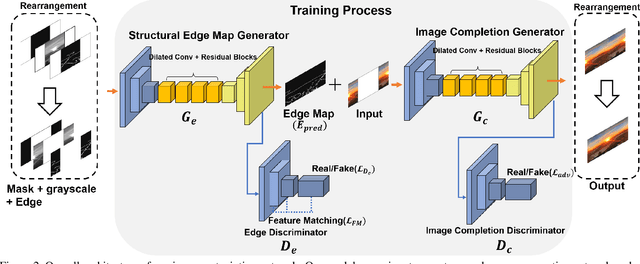
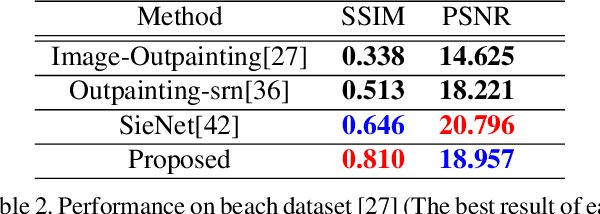
Image outpainting is a very intriguing problem as the outside of a given image can be continuously filled by considering as the context of the image. This task has two main challenges. The first is to maintain the spatial consistency in contents of generated regions and the original input. The second is to generate a high-quality large image with a small amount of adjacent information. Conventional image outpainting methods generate inconsistent, blurry, and repeated pixels. To alleviate the difficulty of an outpainting problem, we propose a novel image outpainting method using bidirectional boundary region rearrangement. We rearrange the image to benefit from the image inpainting task by reflecting more directional information. The bidirectional boundary region rearrangement enables the generation of the missing region using bidirectional information similar to that of the image inpainting task, thereby generating the higher quality than the conventional methods using unidirectional information. Moreover, we use the edge map generator that considers images as original input with structural information and hallucinates the edges of unknown regions to generate the image. Our proposed method is compared with other state-of-the-art outpainting and inpainting methods both qualitatively and quantitatively. We further compared and evaluated them using BRISQUE, one of the No-Reference image quality assessment (IQA) metrics, to evaluate the naturalness of the output. The experimental results demonstrate that our method outperforms other methods and generates new images with 360{\deg}panoramic characteristics.
Contextual road lane and symbol generation for autonomous driving
Jan 18, 2022
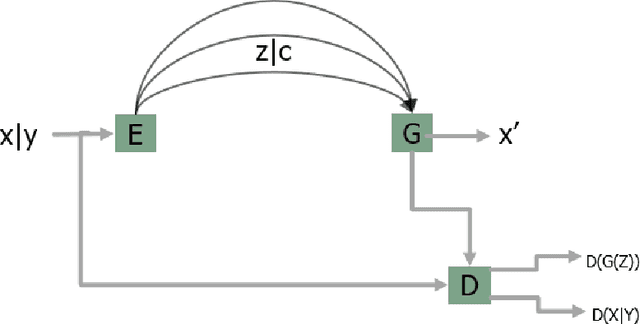
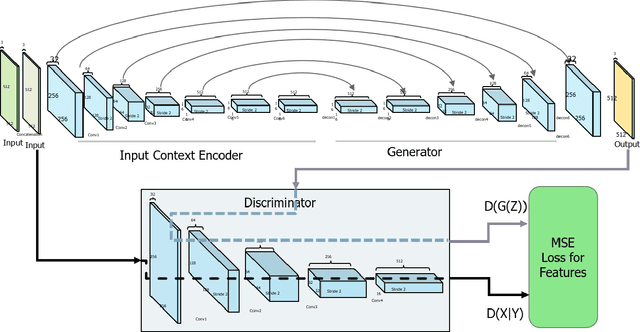

In this paper we present a novel approach for lane detection and segmentation using generative models. Traditionally discriminative models have been employed to classify pixels semantically on a road. We model the probability distribution of lanes and road symbols by training a generative adversarial network. Based on the learned probability distribution, context-aware lanes and road signs are generated for a given image which are further quantized for nearest class label. Proposed method has been tested on BDD100K and Baidu ApolloScape datasets and performs better than state of the art and exhibits robustness to adverse conditions by generating lanes in faded out and occluded scenarios.
VICTR: Visual Information Captured Text Representation for Text-to-Image Multimodal Tasks
Oct 14, 2020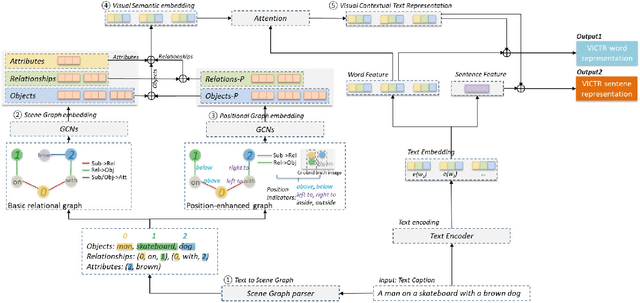
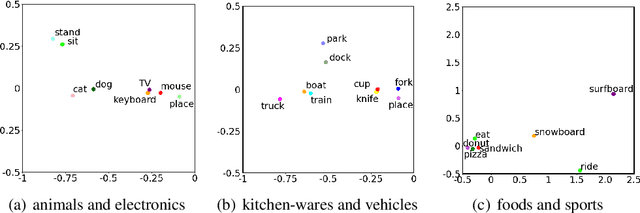
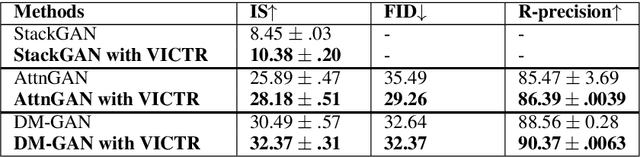
Text-to-image multimodal tasks, generating/retrieving an image from a given text description, are extremely challenging tasks since raw text descriptions cover quite limited information in order to fully describe visually realistic images. We propose a new visual contextual text representation for text-to-image multimodal tasks, VICTR, which captures rich visual semantic information of objects from the text input. First, we use the text description as initial input and conduct dependency parsing to extract the syntactic structure and analyse the semantic aspect, including object quantities, to extract the scene graph. Then, we train the extracted objects, attributes, and relations in the scene graph and the corresponding geometric relation information using Graph Convolutional Networks, and it generates text representation which integrates textual and visual semantic information. The text representation is aggregated with word-level and sentence-level embedding to generate both visual contextual word and sentence representation. For the evaluation, we attached VICTR to the state-of-the-art models in text-to-image generation.VICTR is easily added to existing models and improves across both quantitative and qualitative aspects.