 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Conditional Prompt Learning for Vision-Language Models
Mar 10, 2022
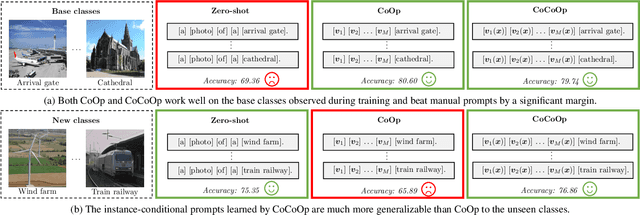
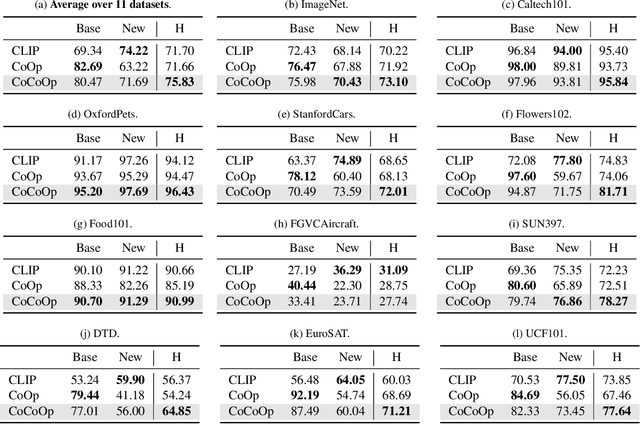
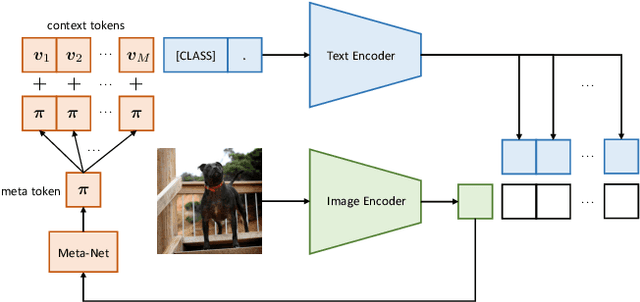
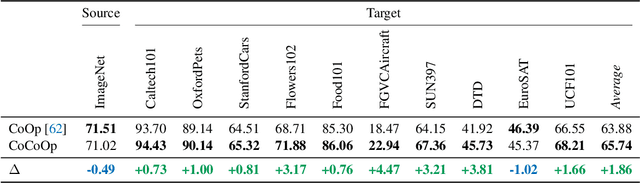
With the rise of powerful pre-trained vision-language models like CLIP, it becomes essential to investigate ways to adapt these models to downstream datasets. A recently proposed method named Context Optimization (CoOp) introduces the concept of prompt learning -- a recent trend in NLP -- to the vision domain for adapting pre-trained vision-language models. Specifically, CoOp turns context words in a prompt into a set of learnable vectors and, with only a few labeled images for learning, can achieve huge improvements over intensively-tuned manual prompts. In our study we identify a critical problem of CoOp: the learned context is not generalizable to wider unseen classes within the same dataset, suggesting that CoOp overfits base classes observed during training. To address the problem, we propose Conditional Context Optimization (CoCoOp), which extends CoOp by further learning a lightweight neural network to generate for each image an input-conditional token (vector). Compared to CoOp's static prompts, our dynamic prompts adapt to each instance and are thus less sensitive to class shift. Extensive experiments show that CoCoOp generalizes much better than CoOp to unseen classes, even showing promising transferability beyond a single dataset; and yields stronger domain generalization performance as well. Code is available at https://github.com/KaiyangZhou/CoOp.
In-Line Image Transformations for Imbalanced, Multiclass Computer Vision Classification of Lung Chest X-Rays
Apr 06, 2021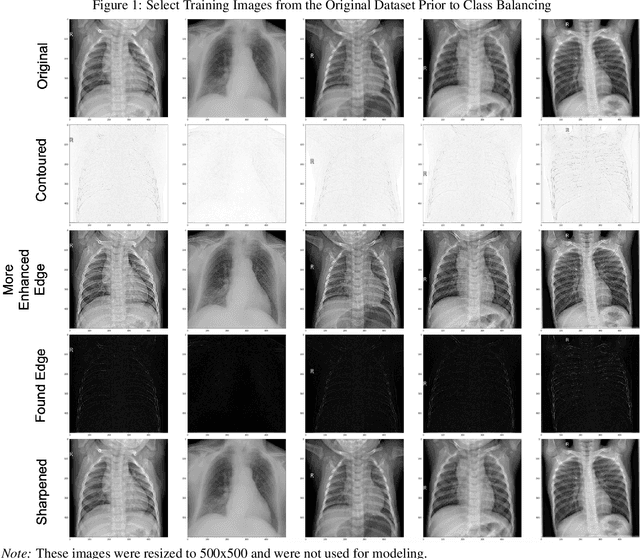
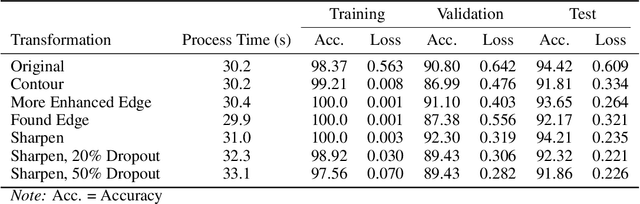
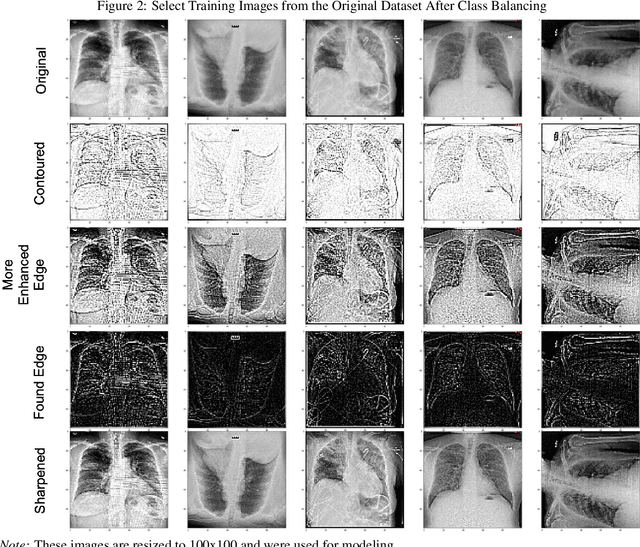
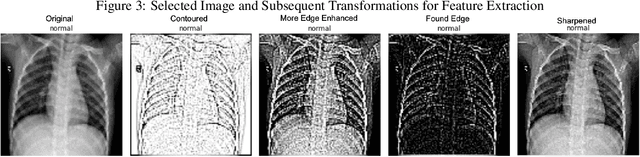
Artificial intelligence (AI) is disrupting the medical field as advances in modern technology allow common household computers to learn anatomical and pathological features that distinguish between healthy and disease with the accuracy of highly specialized, trained physicians. Computer vision AI applications use medical imaging, such as lung chest X-Rays (LCXRs), to facilitate diagnoses by providing second-opinions in addition to a physician's or radiologist's interpretation. Considering the advent of the current Coronavirus disease (COVID-19) pandemic, LCXRs may provide rapid insights to indirectly aid in infection containment, however generating a reliably labeled image dataset for a novel disease is not an easy feat, nor is it of highest priority when combating a global pandemic. Deep learning techniques such as convolutional neural networks (CNNs) are able to select features that distinguish between healthy and disease states for other lung pathologies; this study aims to leverage that body of literature in order to apply image transformations that would serve to balance the lack of COVID-19 LCXR data. Furthermore, this study utilizes a simple CNN architecture for high-performance multiclass LCXR classification at 94 percent accuracy.
Grounded Situation Recognition with Transformers
Nov 19, 2021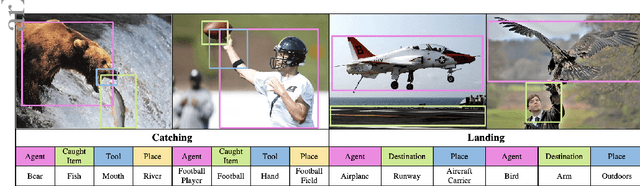
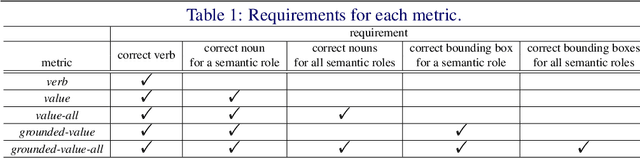
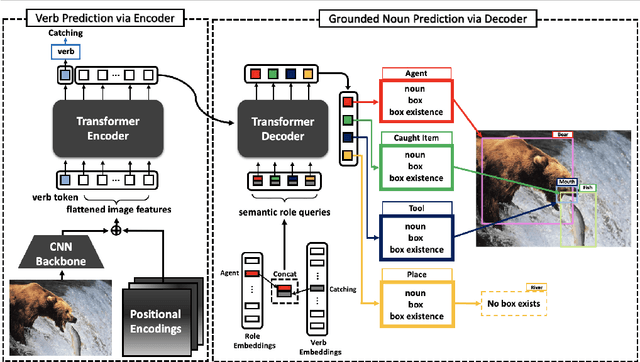
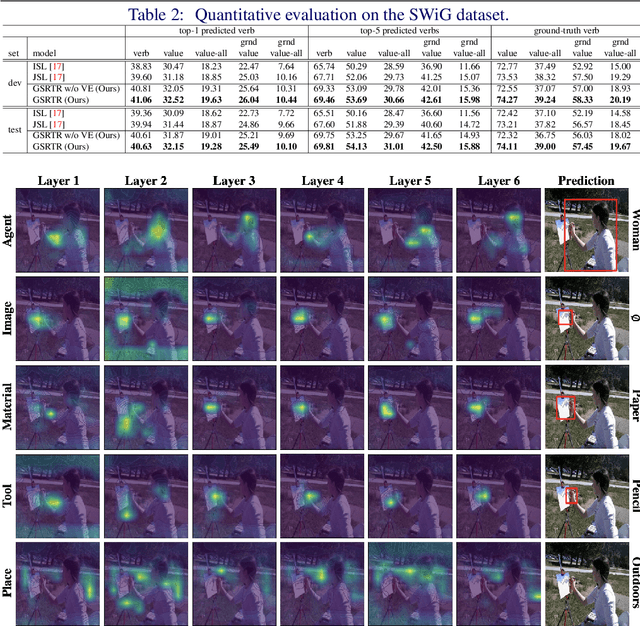
Grounded Situation Recognition (GSR) is the task that not only classifies a salient action (verb), but also predicts entities (nouns) associated with semantic roles and their locations in the given image. Inspired by the remarkable success of Transformers in vision tasks, we propose a GSR model based on a Transformer encoder-decoder architecture. The attention mechanism of our model enables accurate verb classification by capturing high-level semantic feature of an image effectively, and allows the model to flexibly deal with the complicated and image-dependent relations between entities for improved noun classification and localization. Our model is the first Transformer architecture for GSR, and achieves the state of the art in every evaluation metric on the SWiG benchmark. Our code is available at https://github.com/jhcho99/gsrtr .
Indiscriminate Poisoning Attacks on Unsupervised Contrastive Learning
Feb 22, 2022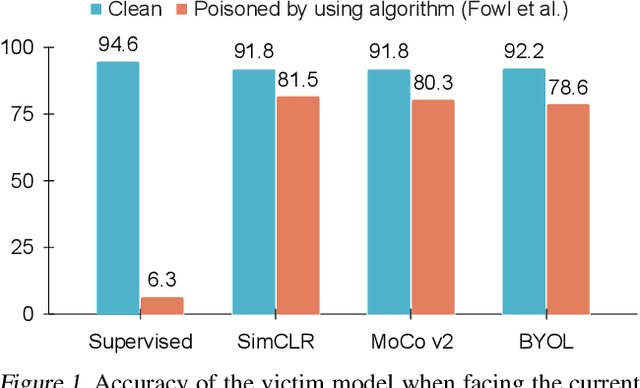
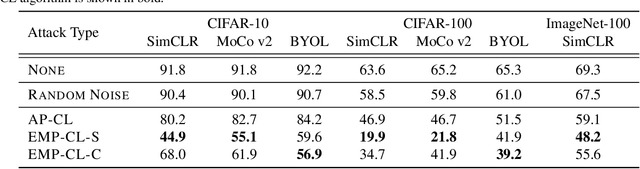
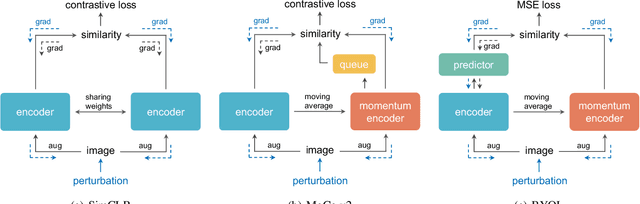
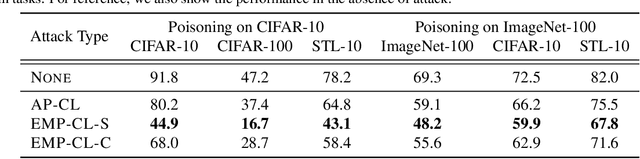
Indiscriminate data poisoning attacks are quite effective against supervised learning. However, not much is known about their impact on unsupervised contrastive learning (CL). This paper is the first to consider indiscriminate data poisoning attacks on contrastive learning, demonstrating the feasibility of such attacks, and their differences from indiscriminate poisoning of supervised learning. We also highlight differences between contrastive learning algorithms, and show that some algorithms (e.g., SimCLR) are more vulnerable than others (e.g., MoCo). We differentiate between two types of data poisoning attacks: sample-wise attacks, which add specific noise to each image, cause the largest drop in accuracy, but do not transfer well across SimCLR, MoCo, and BYOL. In contrast, attacks that use class-wise noise, though cause a smaller drop in accuracy, transfer well across different CL algorithms. Finally, we show that a new data augmentation based on matrix completion can be highly effective in countering data poisoning attacks on unsupervised contrastive learning.
Locally Shifted Attention With Early Global Integration
Dec 22, 2021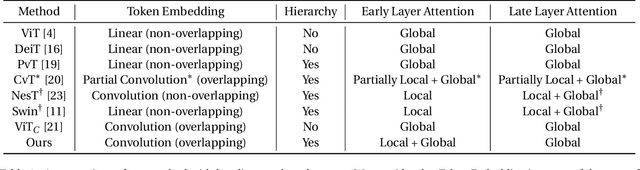

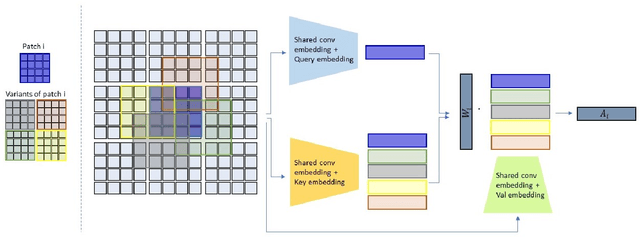
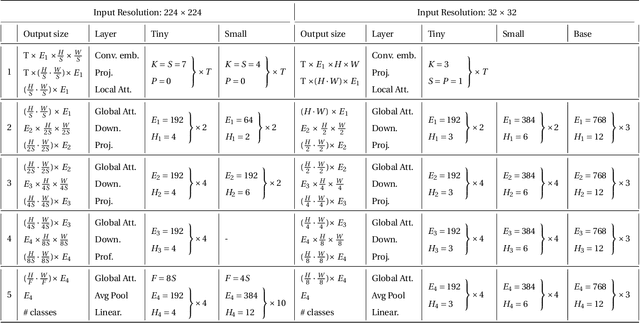
Recent work has shown the potential of transformers for computer vision applications. An image is first partitioned into patches, which are then used as input tokens for the attention mechanism. Due to the expensive quadratic cost of the attention mechanism, either a large patch size is used, resulting in coarse-grained global interactions, or alternatively, attention is applied only on a local region of the image, at the expense of long-range interactions. In this work, we propose an approach that allows for both coarse global interactions and fine-grained local interactions already at early layers of a vision transformer. At the core of our method is the application of local and global attention layers. In the local attention layer, we apply attention to each patch and its local shifts, resulting in virtually located local patches, which are not bound to a single, specific location. These virtually located patches are then used in a global attention layer. The separation of the attention layer into local and global counterparts allows for a low computational cost in the number of patches, while still supporting data-dependent localization already at the first layer, as opposed to the static positioning in other visual transformers. Our method is shown to be superior to both convolutional and transformer-based methods for image classification on CIFAR10, CIFAR100, and ImageNet. Code is available at: https://github.com/shellysheynin/Locally-SAG-Transformer.
Semantic Photo Manipulation with a Generative Image Prior
May 15, 2020

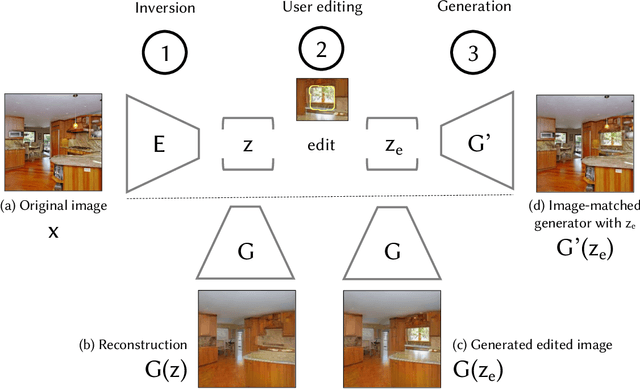
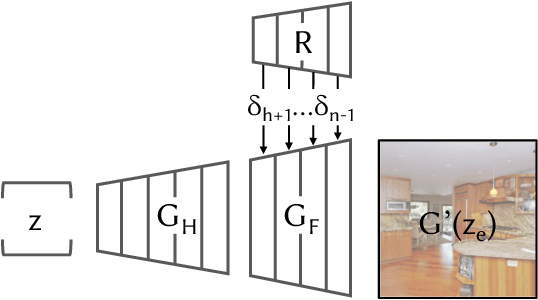
Despite the recent success of GANs in synthesizing images conditioned on inputs such as a user sketch, text, or semantic labels, manipulating the high-level attributes of an existing natural photograph with GANs is challenging for two reasons. First, it is hard for GANs to precisely reproduce an input image. Second, after manipulation, the newly synthesized pixels often do not fit the original image. In this paper, we address these issues by adapting the image prior learned by GANs to image statistics of an individual image. Our method can accurately reconstruct the input image and synthesize new content, consistent with the appearance of the input image. We demonstrate our interactive system on several semantic image editing tasks, including synthesizing new objects consistent with background, removing unwanted objects, and changing the appearance of an object. Quantitative and qualitative comparisons against several existing methods demonstrate the effectiveness of our method.
* SIGGRAPH 2019
CLIP meets GamePhysics: Towards bug identification in gameplay videos using zero-shot transfer learning
Mar 22, 2022
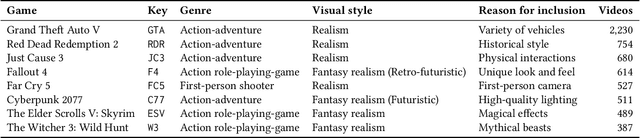

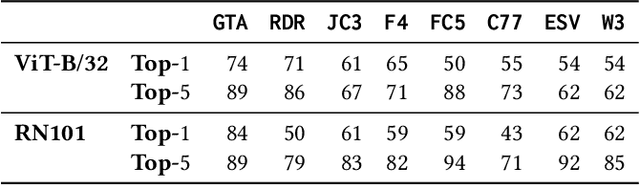
Gameplay videos contain rich information about how players interact with the game and how the game responds. Sharing gameplay videos on social media platforms, such as Reddit, has become a common practice for many players. Often, players will share gameplay videos that showcase video game bugs. Such gameplay videos are software artifacts that can be utilized for game testing, as they provide insight for bug analysis. Although large repositories of gameplay videos exist, parsing and mining them in an effective and structured fashion has still remained a big challenge. In this paper, we propose a search method that accepts any English text query as input to retrieve relevant videos from large repositories of gameplay videos. Our approach does not rely on any external information (such as video metadata); it works solely based on the content of the video. By leveraging the zero-shot transfer capabilities of the Contrastive Language-Image Pre-Training (CLIP) model, our approach does not require any data labeling or training. To evaluate our approach, we present the $\texttt{GamePhysics}$ dataset consisting of 26,954 videos from 1,873 games, that were collected from the GamePhysics section on the Reddit website. Our approach shows promising results in our extensive analysis of simple queries, compound queries, and bug queries, indicating that our approach is useful for object and event detection in gameplay videos. An example application of our approach is as a gameplay video search engine to aid in reproducing video game bugs. Please visit the following link for the code and the data: https://asgaardlab.github.io/CLIPxGamePhysics/
Few-Shot Microscopy Image Cell Segmentation
Jun 29, 2020


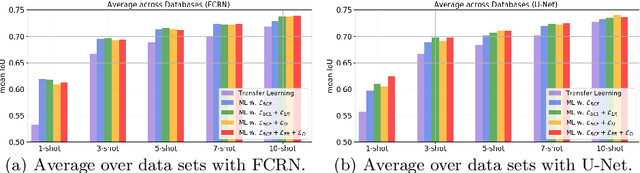
Automatic cell segmentation in microscopy images works well with the support of deep neural networks trained with full supervision. Collecting and annotating images, though, is not a sustainable solution for every new microscopy database and cell type. Instead, we assume that we can access a plethora of annotated image data sets from different domains (sources) and a limited number of annotated image data sets from the domain of interest (target), where each domain denotes not only different image appearance but also a different type of cell segmentation problem. We pose this problem as meta-learning where the goal is to learn a generic and adaptable few-shot learning model from the available source domain data sets and cell segmentation tasks. The model can be afterwards fine-tuned on the few annotated images of the target domain that contains different image appearance and different cell type. In our meta-learning training, we propose the combination of three objective functions to segment the cells, move the segmentation results away from the classification boundary using cross-domain tasks, and learn an invariant representation between tasks of the source domains. Our experiments on five public databases show promising results from 1- to 10-shot meta-learning using standard segmentation neural network architectures.
Deep neural networks-based denoising models for CT imaging and their efficacy
Nov 18, 2021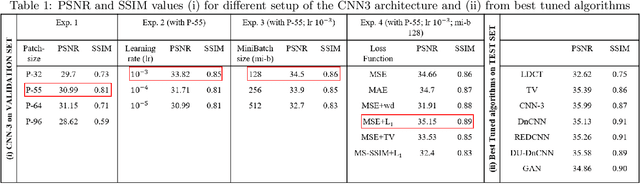
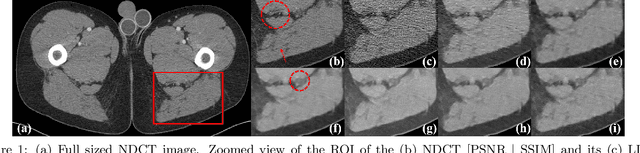
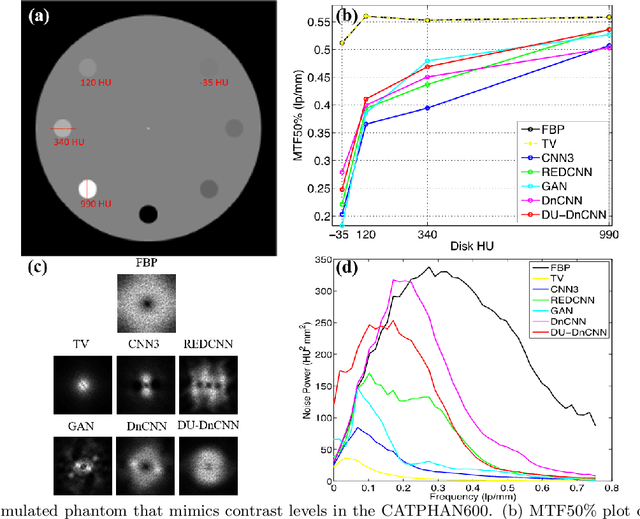
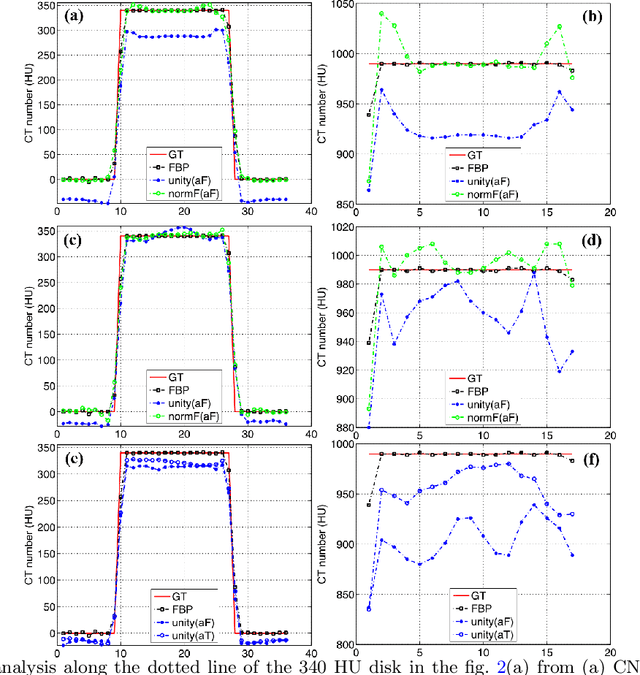
Most of the Deep Neural Networks (DNNs) based CT image denoising literature shows that DNNs outperform traditional iterative methods in terms of metrics such as the RMSE, the PSNR and the SSIM. In many instances, using the same metrics, the DNN results from low-dose inputs are also shown to be comparable to their high-dose counterparts. However, these metrics do not reveal if the DNN results preserve the visibility of subtle lesions or if they alter the CT image properties such as the noise texture. Accordingly, in this work, we seek to examine the image quality of the DNN results from a holistic viewpoint for low-dose CT image denoising. First, we build a library of advanced DNN denoising architectures. This library is comprised of denoising architectures such as the DnCNN, U-Net, Red-Net, GAN, etc. Next, each network is modeled, as well as trained, such that it yields its best performance in terms of the PSNR and SSIM. As such, data inputs (e.g. training patch-size, reconstruction kernel) and numeric-optimizer inputs (e.g. minibatch size, learning rate, loss function) are accordingly tuned. Finally, outputs from thus trained networks are further subjected to a series of CT bench testing metrics such as the contrast-dependent MTF, the NPS and the HU accuracy. These metrics are employed to perform a more nuanced study of the resolution of the DNN outputs' low-contrast features, their noise textures, and their CT number accuracy to better understand the impact each DNN algorithm has on these underlying attributes of image quality.
* 13 pages, 9 figures, SPIE proceeding
High-Accuracy RGB-D Face Recognition via Segmentation-Aware Face Depth Estimation and Mask-Guided Attention Network
Dec 22, 2021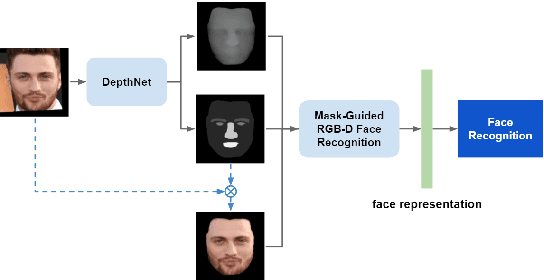
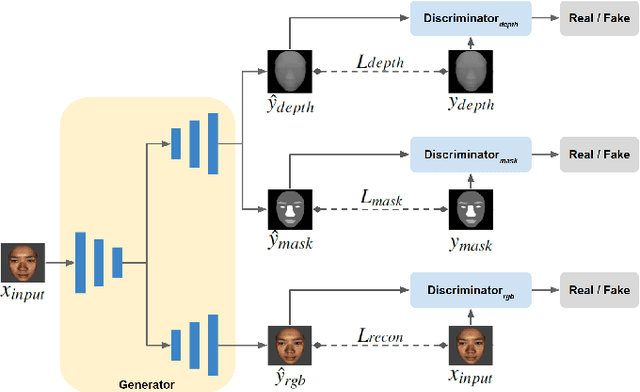
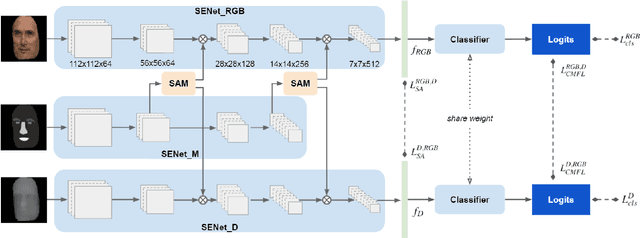

Deep learning approaches have achieved highly accurate face recognition by training the models with very large face image datasets. Unlike the availability of large 2D face image datasets, there is a lack of large 3D face datasets available to the public. Existing public 3D face datasets were usually collected with few subjects, leading to the over-fitting problem. This paper proposes two CNN models to improve the RGB-D face recognition task. The first is a segmentation-aware depth estimation network, called DepthNet, which estimates depth maps from RGB face images by including semantic segmentation information for more accurate face region localization. The other is a novel mask-guided RGB-D face recognition model that contains an RGB recognition branch, a depth map recognition branch, and an auxiliary segmentation mask branch with a spatial attention module. Our DepthNet is used to augment a large 2D face image dataset to a large RGB-D face dataset, which is used for training an accurate RGB-D face recognition model. Furthermore, the proposed mask-guided RGB-D face recognition model can fully exploit the depth map and segmentation mask information and is more robust against pose variation than previous methods. Our experimental results show that DepthNet can produce more reliable depth maps from face images with the segmentation mask. Our mask-guided face recognition model outperforms state-of-the-art methods on several public 3D face datasets.