 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Sentiment Analysis of Plastic Surgery Social Media Posts
Jul 05, 2023The massive collection of user posts across social media platforms is primarily untapped for artificial intelligence (AI) use cases based on the sheer volume and velocity of textual data. Natural language processing (NLP) is a subfield of AI that leverages bodies of documents, known as corpora, to train computers in human-like language understanding. Using a word ranking method, term frequency-inverse document frequency (TF-IDF), to create features across documents, it is possible to perform unsupervised analytics, machine learning (ML) that can group the documents without a human manually labeling the data. For large datasets with thousands of features, t-distributed stochastic neighbor embedding (t-SNE), k-means clustering and Latent Dirichlet allocation (LDA) are employed to learn top words and generate topics for a Reddit and Twitter combined corpus. Using extremely simple deep learning models, this study demonstrates that the applied results of unsupervised analysis allow a computer to predict either negative, positive, or neutral user sentiment towards plastic surgery based on a tweet or subreddit post with almost 90% accuracy. Furthermore, the model is capable of achieving higher accuracy on the unsupervised sentiment task than on a rudimentary supervised document classification task. Therefore, unsupervised learning may be considered a viable option in labeling social media documents for NLP tasks.
In-Line Image Transformations for Imbalanced, Multiclass Computer Vision Classification of Lung Chest X-Rays
Apr 06, 2021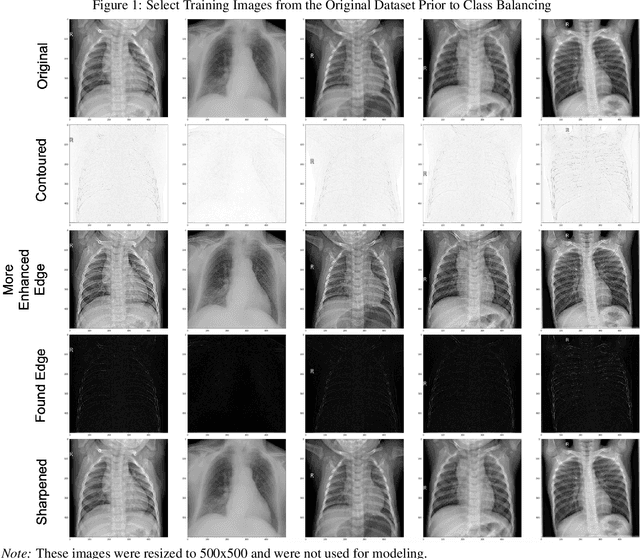
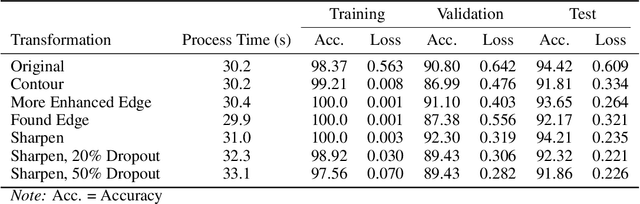
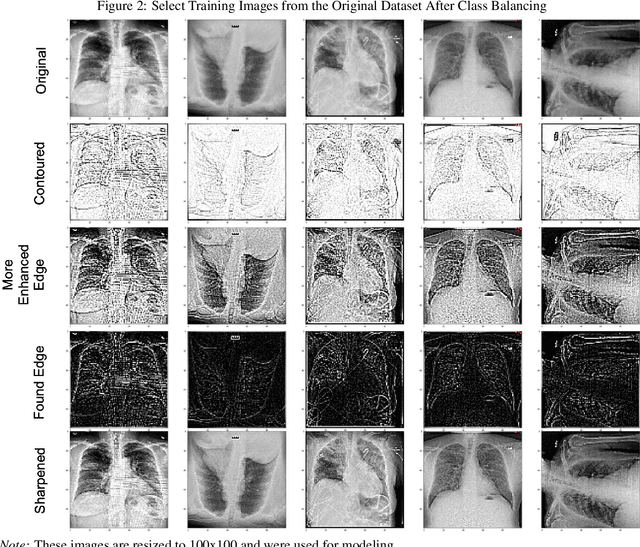
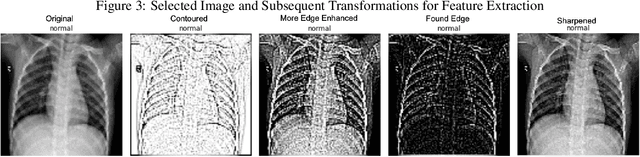
Artificial intelligence (AI) is disrupting the medical field as advances in modern technology allow common household computers to learn anatomical and pathological features that distinguish between healthy and disease with the accuracy of highly specialized, trained physicians. Computer vision AI applications use medical imaging, such as lung chest X-Rays (LCXRs), to facilitate diagnoses by providing second-opinions in addition to a physician's or radiologist's interpretation. Considering the advent of the current Coronavirus disease (COVID-19) pandemic, LCXRs may provide rapid insights to indirectly aid in infection containment, however generating a reliably labeled image dataset for a novel disease is not an easy feat, nor is it of highest priority when combating a global pandemic. Deep learning techniques such as convolutional neural networks (CNNs) are able to select features that distinguish between healthy and disease states for other lung pathologies; this study aims to leverage that body of literature in order to apply image transformations that would serve to balance the lack of COVID-19 LCXR data. Furthermore, this study utilizes a simple CNN architecture for high-performance multiclass LCXR classification at 94 percent accuracy.