 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cryo-ZSSR: multiple-image super-resolution based on deep internal learning
Nov 22, 2020

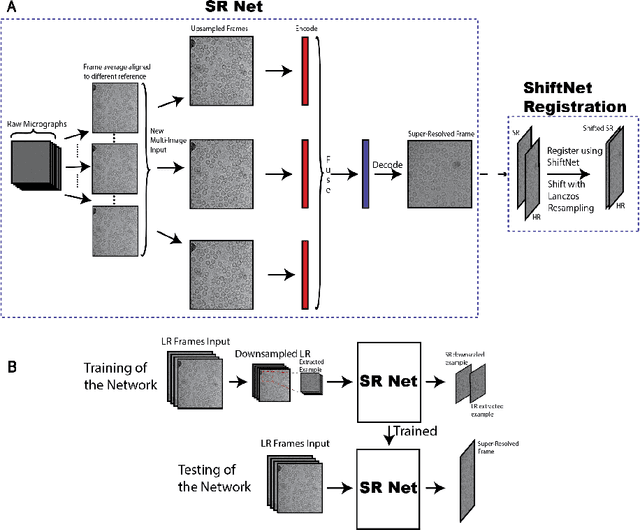
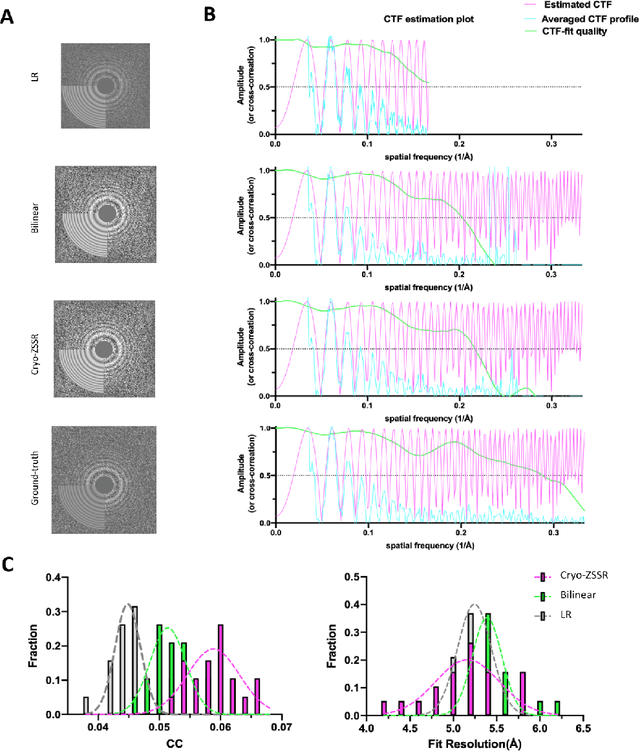
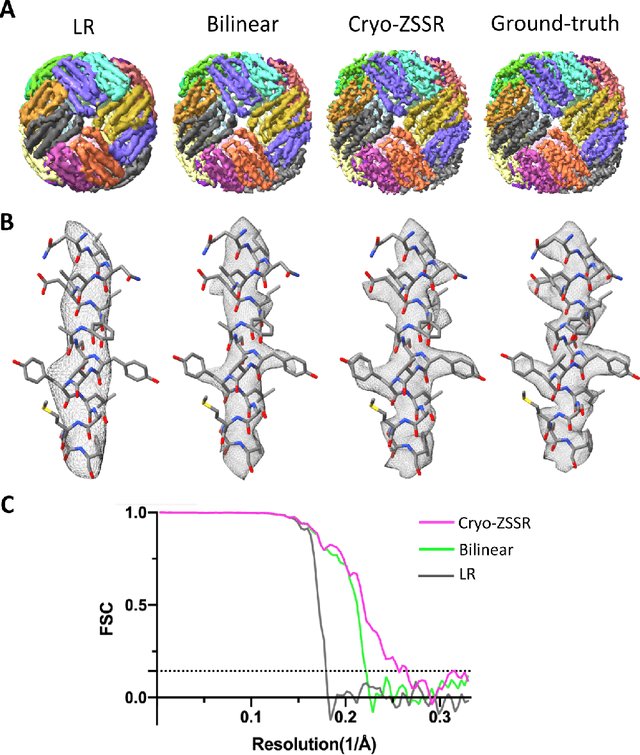
Single-particle cryo-electron microscopy (cryo-EM) is an emerging imaging modality capable of visualizing proteins and macro-molecular complexes at near-atomic resolution. The low electron-doses used to prevent sample radiation damage, result in images where the power of the noise is 100 times greater than the power of the signal. To overcome the low-SNRs, hundreds of thousands of particle projections acquired over several days of data collection are averaged in 3D to determine the structure of interest. Meanwhile, recent image super-resolution (SR) techniques based on neural networks have shown state of the art performance on natural images. Building on these advances, we present a multiple-image SR algorithm based on deep internal learning designed specifically to work under low-SNR conditions. Our approach leverages the internal image statistics of cryo-EM movies and does not require training on ground-truth data. When applied to a single-particle dataset of apoferritin, we show that the resolution of 3D structures obtained from SR micrographs can surpass the limits imposed by the imaging system. Our results indicate that the combination of low magnification imaging with image SR has the potential to accelerate cryo-EM data collection without sacrificing resolution.
Domain Generalization via Shuffled Style Assembly for Face Anti-Spoofing
Mar 10, 2022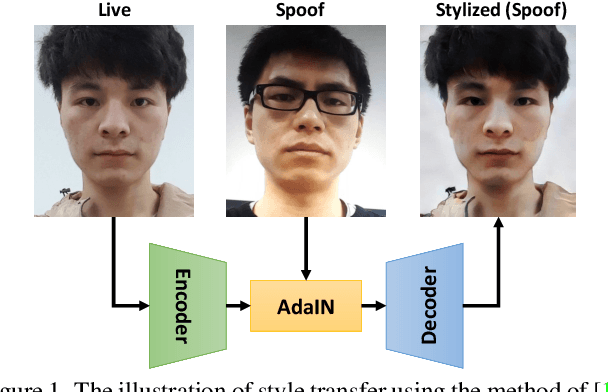
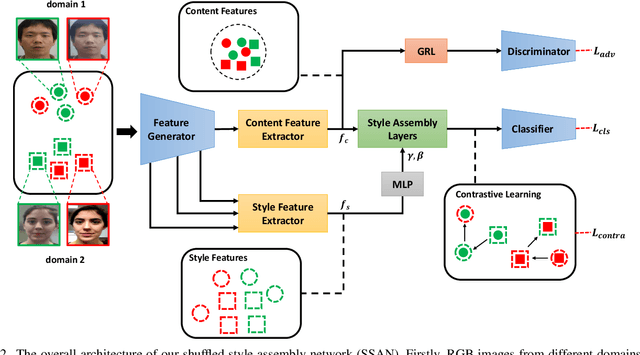
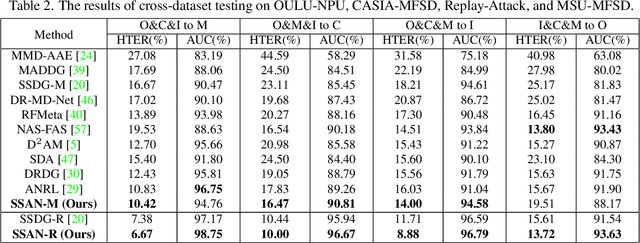
With diverse presentation attacks emerging continually, generalizable face anti-spoofing (FAS) has drawn growing attention. Most existing methods implement domain generalization (DG) on the complete representations. However, different image statistics may have unique properties for the FAS tasks. In this work, we separate the complete representation into content and style ones. A novel Shuffled Style Assembly Network (SSAN) is proposed to extract and reassemble different content and style features for a stylized feature space. Then, to obtain a generalized representation, a contrastive learning strategy is developed to emphasize liveness-related style information while suppress the domain-specific one. Finally, the representations of the correct assemblies are used to distinguish between living and spoofing during the inferring. On the other hand, despite the decent performance, there still exists a gap between academia and industry, due to the difference in data quantity and distribution. Thus, a new large-scale benchmark for FAS is built up to further evaluate the performance of algorithms in reality. Both qualitative and quantitative results on existing and proposed benchmarks demonstrate the effectiveness of our methods. The codes will be available at https://github.com/wangzhuo2019/SSAN.
Patches Are All You Need?
Jan 24, 2022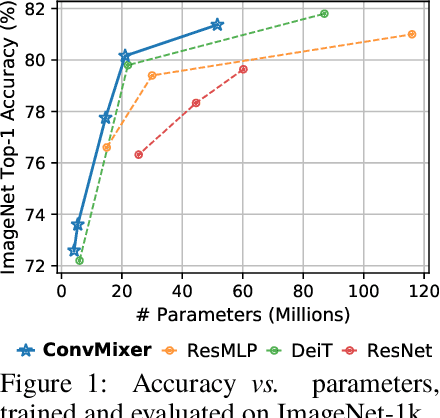
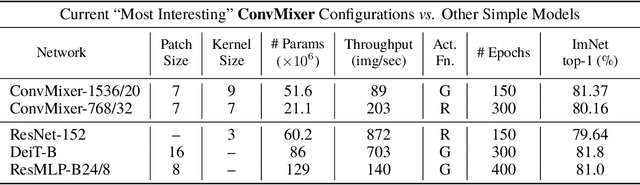
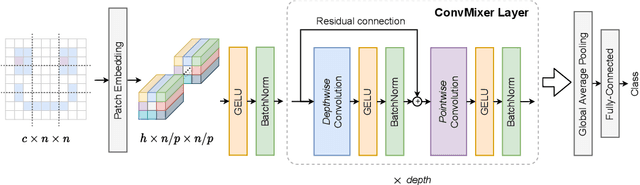
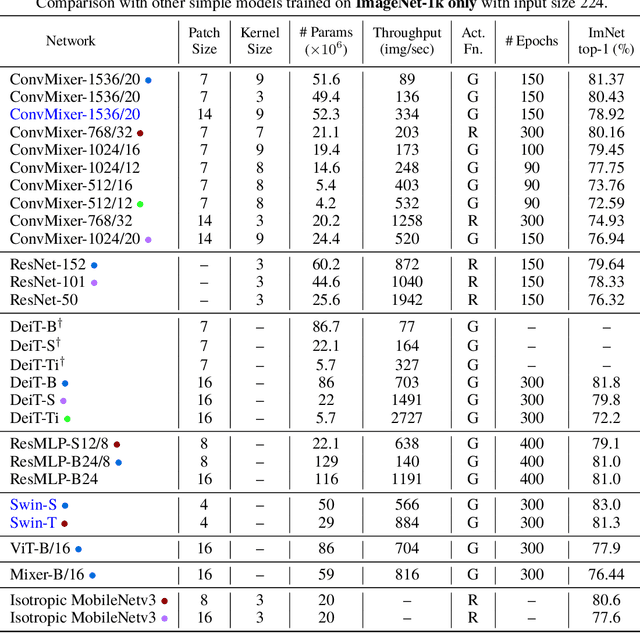
Although convolutional networks have been the dominant architecture for vision tasks for many years, recent experiments have shown that Transformer-based models, most notably the Vision Transformer (ViT), may exceed their performance in some settings. However, due to the quadratic runtime of the self-attention layers in Transformers, ViTs require the use of patch embeddings, which group together small regions of the image into single input features, in order to be applied to larger image sizes. This raises a question: Is the performance of ViTs due to the inherently-more-powerful Transformer architecture, or is it at least partly due to using patches as the input representation? In this paper, we present some evidence for the latter: specifically, we propose the ConvMixer, an extremely simple model that is similar in spirit to the ViT and the even-more-basic MLP-Mixer in that it operates directly on patches as input, separates the mixing of spatial and channel dimensions, and maintains equal size and resolution throughout the network. In contrast, however, the ConvMixer uses only standard convolutions to achieve the mixing steps. Despite its simplicity, we show that the ConvMixer outperforms the ViT, MLP-Mixer, and some of their variants for similar parameter counts and data set sizes, in addition to outperforming classical vision models such as the ResNet. Our code is available at https://github.com/locuslab/convmixer.
Class-Balanced Active Learning for Image Classification
Oct 09, 2021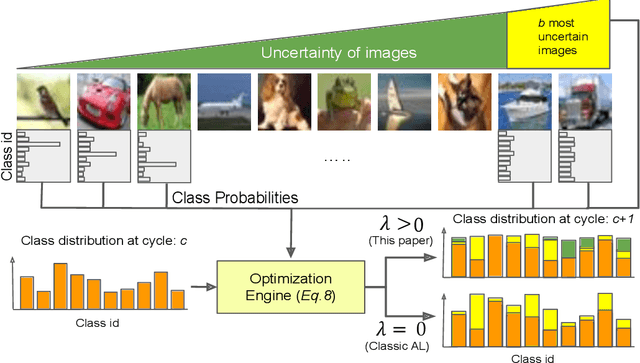
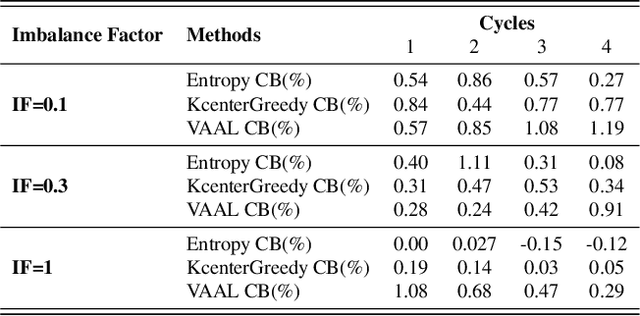
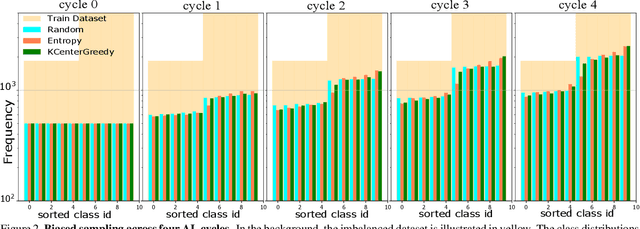
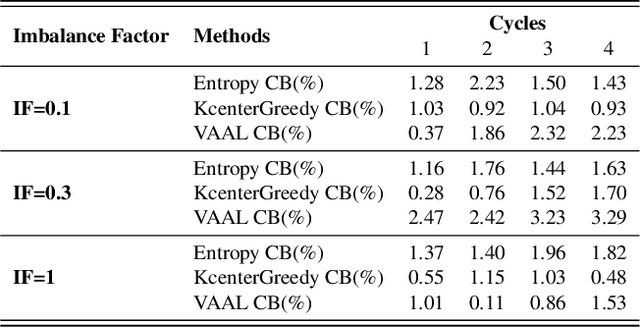
Active learning aims to reduce the labeling effort that is required to train algorithms by learning an acquisition function selecting the most relevant data for which a label should be requested from a large unlabeled data pool. Active learning is generally studied on balanced datasets where an equal amount of images per class is available. However, real-world datasets suffer from severe imbalanced classes, the so called long-tail distribution. We argue that this further complicates the active learning process, since the imbalanced data pool can result in suboptimal classifiers. To address this problem in the context of active learning, we proposed a general optimization framework that explicitly takes class-balancing into account. Results on three datasets showed that the method is general (it can be combined with most existing active learning algorithms) and can be effectively applied to boost the performance of both informative and representative-based active learning methods. In addition, we showed that also on balanced datasets our method generally results in a performance gain.
Local Gradient Hexa Pattern: A Descriptor for Face Recognition and Retrieval
Jan 03, 2022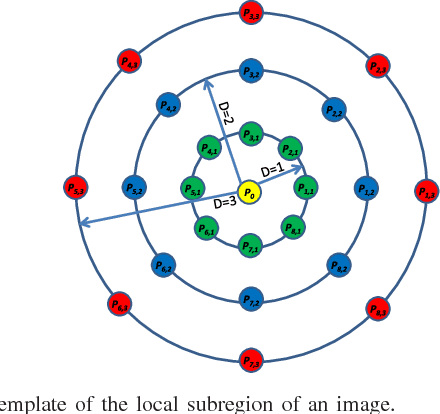
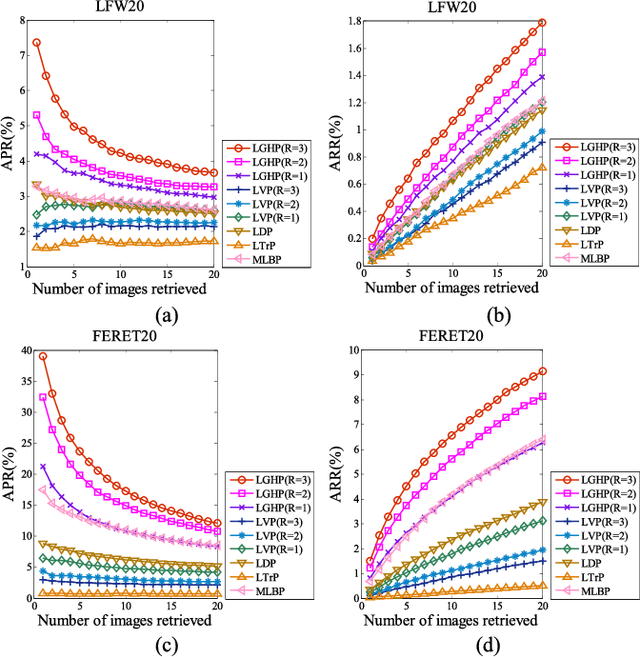
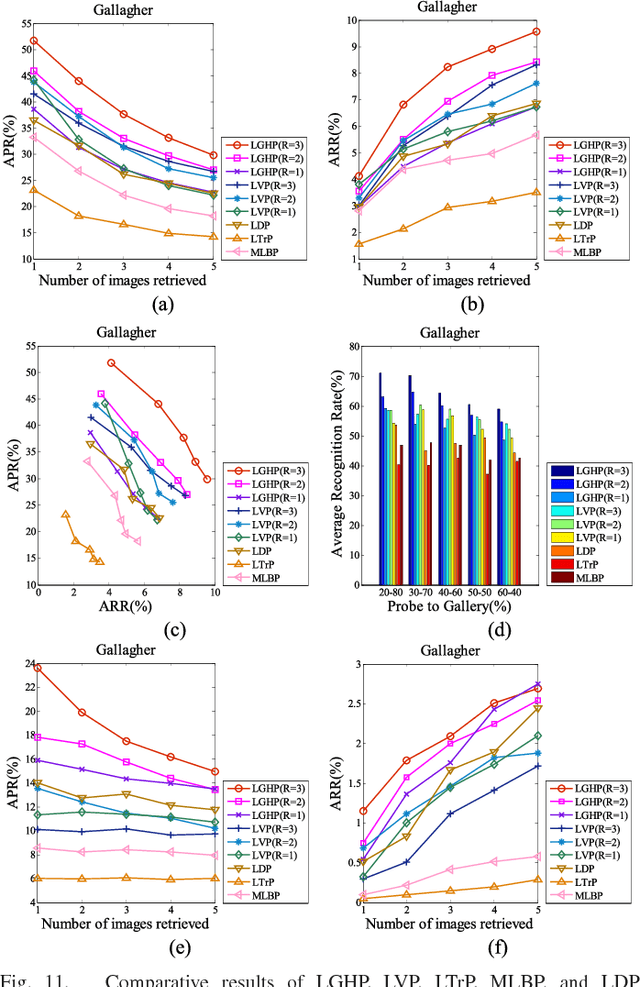
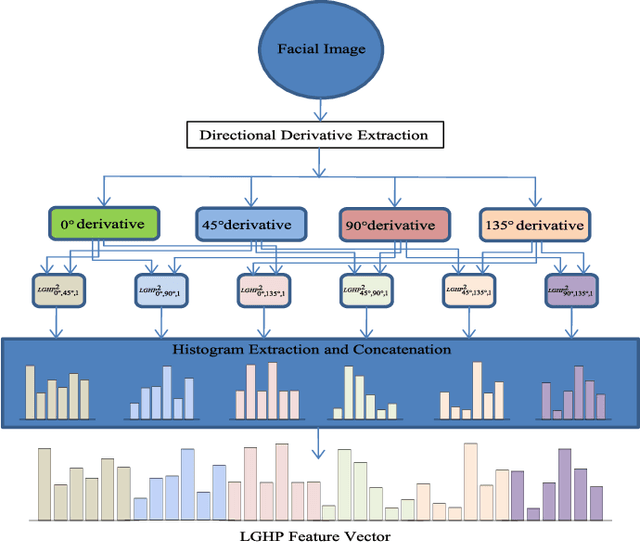
Local descriptors used in face recognition are robust in a sense that these descriptors perform well in varying pose, illumination and lighting conditions. Accuracy of these descriptors depends on the precision of mapping the relationship that exists in the local neighborhood of a facial image into microstructures. In this paper a local gradient hexa pattern (LGHP) is proposed that identifies the relationship amongst the reference pixel and its neighboring pixels at different distances across different derivative directions. Discriminative information exists in the local neighborhood as well as in different derivative directions. Proposed descriptor effectively transforms these relationships into binary micropatterns discriminating interclass facial images with optimal precision. Recognition and retrieval performance of the proposed descriptor has been compared with state-of-the-art descriptors namely LDP and LVP over the most challenging and benchmark facial image databases, i.e. Cropped Extended Yale-B, CMU-PIE, color-FERET, and LFW. The proposed descriptor has better recognition as well as retrieval rates compared to state-of-the-art descriptors.
Image De-Quantization Using Generative Models as Priors
Jul 15, 2020
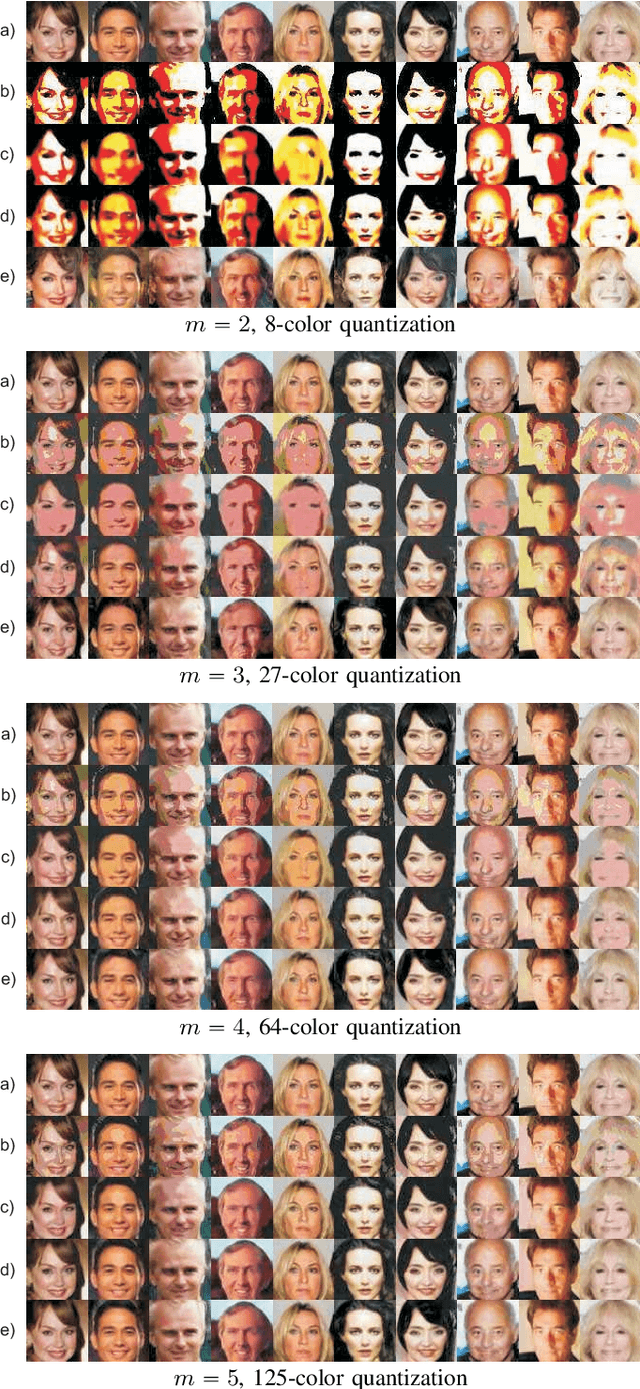


Image quantization is used in several applications aiming in reducing the number of available colors in an image and therefore its size. De-quantization is the task of reversing the quantization effect and recovering the original multi-chromatic level image. Existing techniques achieve de-quantization by imposing suitable constraints on the ideal image in order to make the recovery problem feasible since it is otherwise ill-posed. Our goal in this work is to develop a de-quantization mechanism through a rigorous mathematical analysis which is based on the classical statistical estimation theory. In this effort we incorporate generative modeling of the ideal image as a suitable prior information. The resulting technique is simple and capable of de-quantizing successfully images that have experienced severe quantization effects. Interestingly, our method can recover images even if the quantization process is not exactly known and contains unknown parameters.
IBRNet: Learning Multi-View Image-Based Rendering
Feb 25, 2021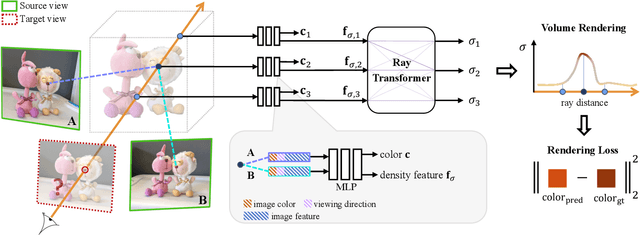
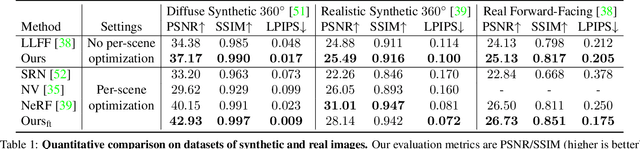
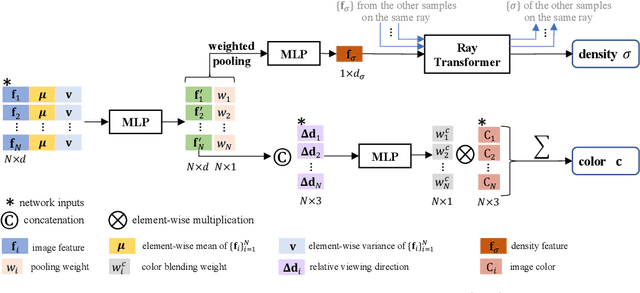
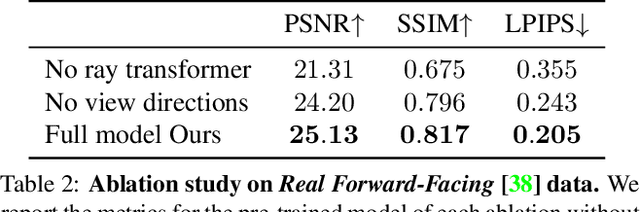
We present a method that synthesizes novel views of complex scenes by interpolating a sparse set of nearby views. The core of our method is a network architecture that includes a multilayer perceptron and a ray transformer that estimates radiance and volume density at continuous 5D locations (3D spatial locations and 2D viewing directions), drawing appearance information on the fly from multiple source views. By drawing on source views at render time, our method hearkens back to classic work on image-based rendering (IBR), and allows us to render high-resolution imagery. Unlike neural scene representation work that optimizes per-scene functions for rendering, we learn a generic view interpolation function that generalizes to novel scenes. We render images using classic volume rendering, which is fully differentiable and allows us to train using only multi-view posed images as supervision. Experiments show that our method outperforms recent novel view synthesis methods that also seek to generalize to novel scenes. Further, if fine-tuned on each scene, our method is competitive with state-of-the-art single-scene neural rendering methods.
See through Gradients: Image Batch Recovery via GradInversion
Apr 15, 2021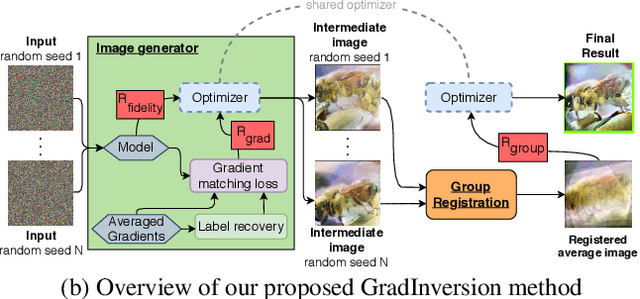
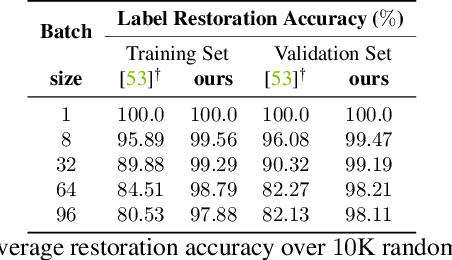

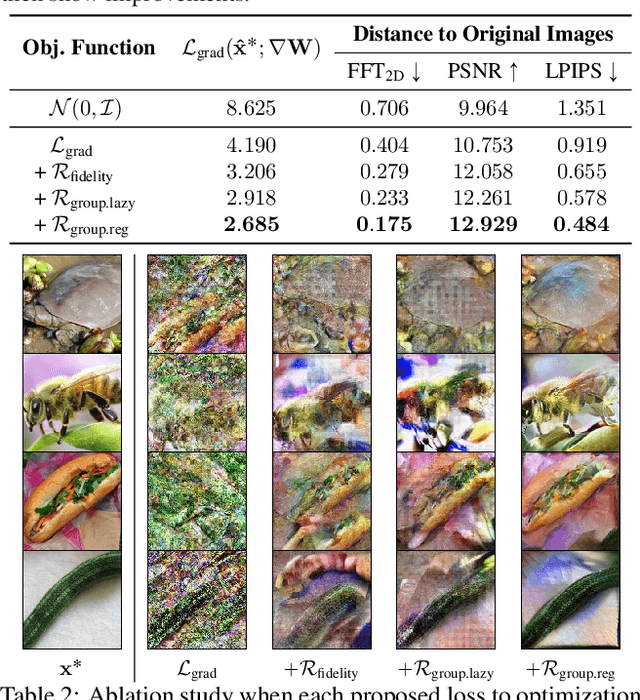
Training deep neural networks requires gradient estimation from data batches to update parameters. Gradients per parameter are averaged over a set of data and this has been presumed to be safe for privacy-preserving training in joint, collaborative, and federated learning applications. Prior work only showed the possibility of recovering input data given gradients under very restrictive conditions - a single input point, or a network with no non-linearities, or a small 32x32 px input batch. Therefore, averaging gradients over larger batches was thought to be safe. In this work, we introduce GradInversion, using which input images from a larger batch (8 - 48 images) can also be recovered for large networks such as ResNets (50 layers), on complex datasets such as ImageNet (1000 classes, 224x224 px). We formulate an optimization task that converts random noise into natural images, matching gradients while regularizing image fidelity. We also propose an algorithm for target class label recovery given gradients. We further propose a group consistency regularization framework, where multiple agents starting from different random seeds work together to find an enhanced reconstruction of original data batch. We show that gradients encode a surprisingly large amount of information, such that all the individual images can be recovered with high fidelity via GradInversion, even for complex datasets, deep networks, and large batch sizes.
Task-Agnostic Robust Representation Learning
Mar 15, 2022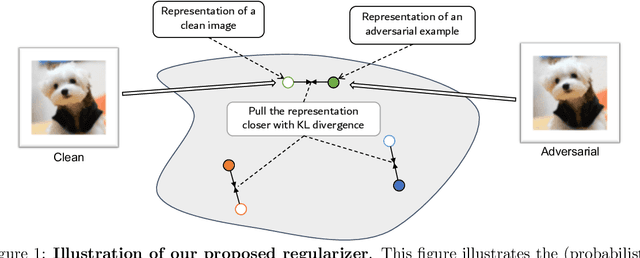
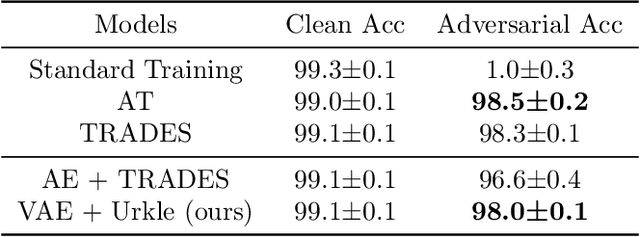

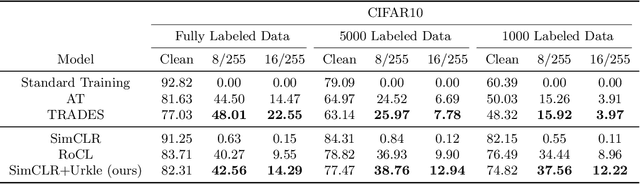
It has been reported that deep learning models are extremely vulnerable to small but intentionally chosen perturbations of its input. In particular, a deep network, despite its near-optimal accuracy on the clean images, often mis-classifies an image with a worst-case but humanly imperceptible perturbation (so-called adversarial examples). To tackle this problem, a great amount of research has been done to study the training procedure of a network to improve its robustness. However, most of the research so far has focused on the case of supervised learning. With the increasing popularity of self-supervised learning methods, it is also important to study and improve the robustness of their resulting representation on the downstream tasks. In this paper, we study the problem of robust representation learning with unlabeled data in a task-agnostic manner. Specifically, we first derive an upper bound on the adversarial loss of a prediction model (which is based on the learned representation) on any downstream task, using its loss on the clean data and a robustness regularizer. Moreover, the regularizer is task-independent, thus we propose to minimize it directly during the representation learning phase to make the downstream prediction model more robust. Extensive experiments show that our method achieves preferable adversarial performance compared to relevant baselines.
Reconstruction and Segmentation of Parallel MR Data using Image Domain DEEP-SLR
Feb 01, 2021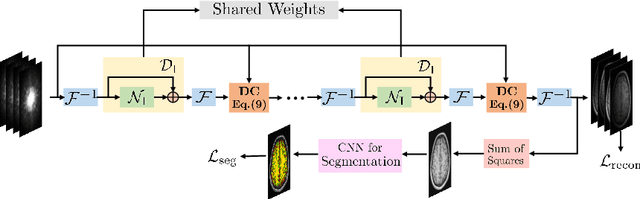
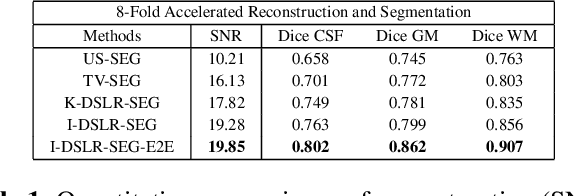
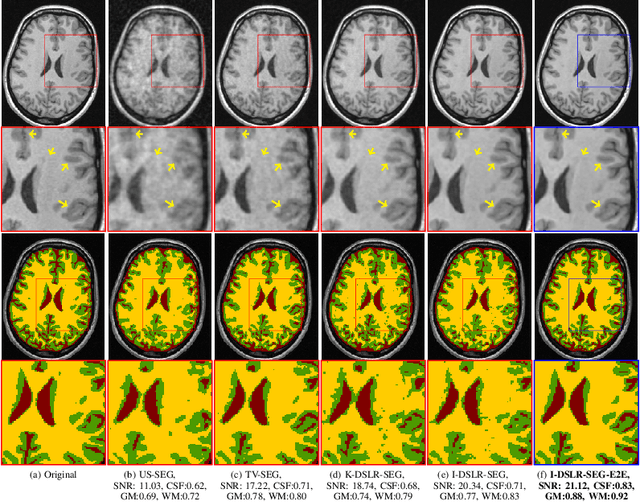
The main focus of this work is a novel framework for the joint reconstruction and segmentation of parallel MRI (PMRI) brain data. We introduce an image domain deep network for calibrationless recovery of undersampled PMRI data. The proposed approach is the deep-learning (DL) based generalization of local low-rank based approaches for uncalibrated PMRI recovery including CLEAR [6]. Since the image domain approach exploits additional annihilation relations compared to k-space based approaches, we expect it to offer improved performance. To minimize segmentation errors resulting from undersampling artifacts, we combined the proposed scheme with a segmentation network and trained it in an end-to-end fashion. In addition to reducing segmentation errors, this approach also offers improved reconstruction performance by reducing overfitting; the reconstructed images exhibit reduced blurring and sharper edges than independently trained reconstruction network.